Как вы все уже наверное знаете, недавно были выложены дампы баз AshleyMadison. Я решил не упускать возможность и проанализировать реальные данные дейтинг платформы. Попробуем предсказать платежеспособность клиента по его характиристикам таким как возраст, рост, вес, привычки и т.д.

Попробуем?
В данном примере я буду пользоваться iPython notebook. Тем кто занимается анализом данных на Python и еще не использует iPython notebook — очень рекомендую!
Для построения модели будем использовать обезличенные данные.
1. Подготовка данных в MySQL
Для начала зальём дампы в MySQL и удалим всех пользователей с id < 35 000 000 для простоты дальнейшей обработки. Я взял таблицы member_details и aminno_member.
Заливка данных происходит не очень быстро, даже на сервере с SSD (некоторые таблицы весят около 10 Гигов)
Далее нам необходимо залить данные об оплатах из csv и получить сумму по каждому пользователю. В итоге получилась таблица pays c полями id и sum.
2. Загружаем данные в pandas
Джойним 3 таблицы по id юзера и получаем DataFrame для дальнейшей обработки. Берем только пользователей с фотографиями, я думаю что это является признаком хоть какой-то активности в системе:
Извлекаем год и месяц рождения:
Попробуем проанализировать зависит ли целевая переменная(платил/не платил) от характеристик пользователя? Есть ли смысл строить модель?
Разделим анализируемых пользователей на 2 части: df0 — те кто хоть сколько-то платил, df1 — ничего не платили.
Строим по 2 гистограммы для каждого из параметров пользователя. Красным — те кто платил, синим — не платившие.
Рассмотрим самые интересные:
Год рождения:
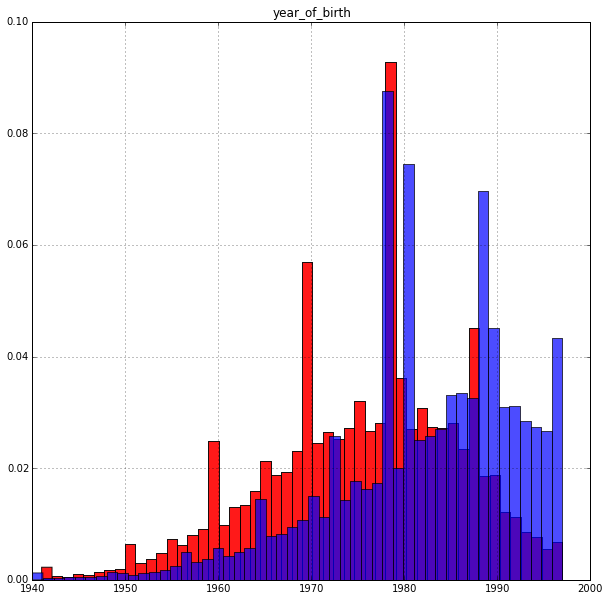
Результат вполне ожидаем: возраст влияет на целевую переменную. Старшие платят охотнее. Пик гистограммы у платящих приходится примерно на 35 лет.
Вес:
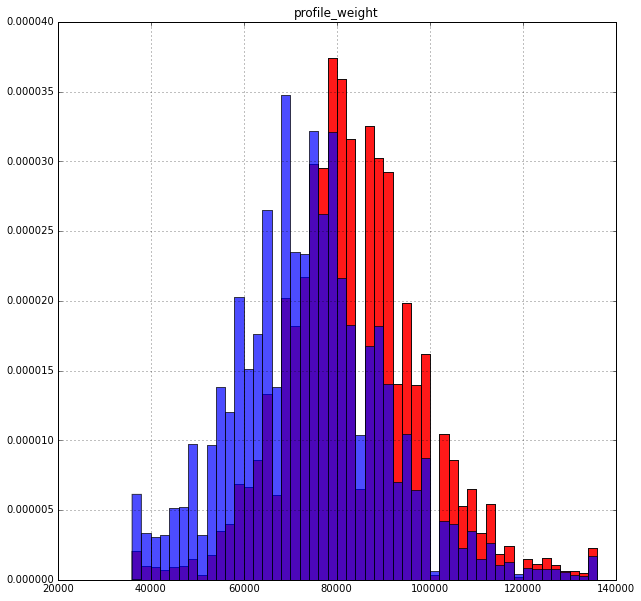
Тут интересней: охотнее платят те кто больше весит. Хотя тоже вполне логично
Рост:
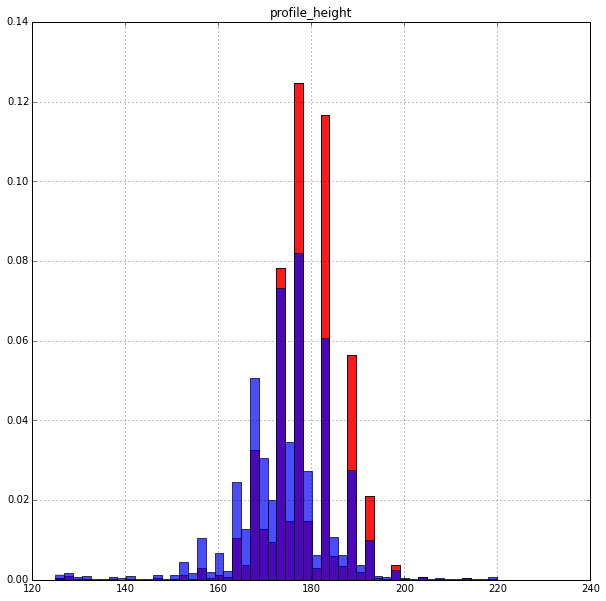
Высокие платят немного охотнее. Распределение очень неравномерное. Возможно рост на сайте задается не числом, а промежутком.
Курение:

К вопросу о заголовке статьи. Просматривается явная зависимость, вопрос — что означают значения 1,2,3,4?
Остальные параметры пользователя не дают такой интересной картины, хотя тоже имеют свой вклад. Здесь есть полный вариант данного notebook где можно ознакомиться со всеми гистограммами.
2. Предсказание вероятности оплаты
Для начала выделим целевую переменную (платил/не платил) которую и будем предсказывать:
Выделим категориальные признаки и проведем их бинаризацию:
Выделим метрические признаки и объединим их с результатом бинаризации:
Разбиваем выборку на 2 части 90% и 10%. На первой будем обучать и тюнить модель. На второй — оценивать точность полученной модели.
Тренируем классификатор RandomForest и подбираем оптимальные параметры.
Оценим значимость признаков:
Самые значимые (по уменьшению значимости): year_of_birth, profile_weight, profile_height.
Оцениваем качество модели на тестовой выборке и построим ROC кривую:
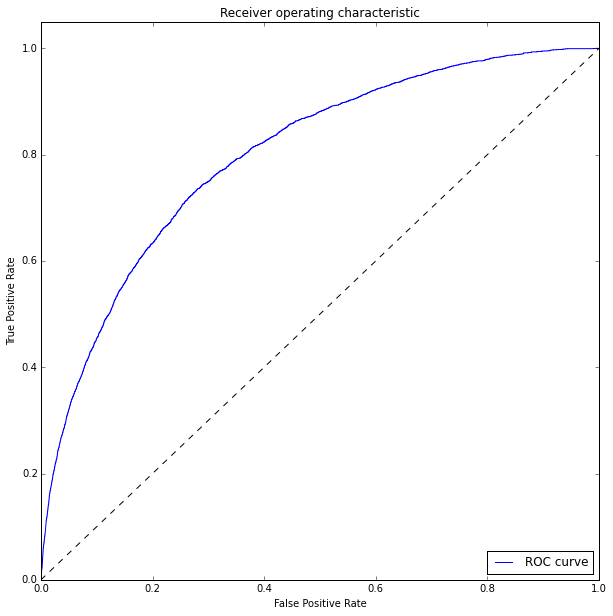
Для измерения качества классификатора будем использовать ROC_AUC score
ROC_AUC = 0.79926
Результаты
Предсказывать склонность пользователей к оплате услуг действительно можно. Точность не очень высокая (roc_auc = 0.8), но мы использовали только часть параметров и вообще не обращали внимания на поведенческие факторы (нет данных).
Что дальше?
UPD:
Для желающих поиграться с данными самостоятельно выкладываю дамп DataFrame
yadi.sk/d/YaNM8DTZj2ybn
И вперед!
Попробуем?
В данном примере я буду пользоваться iPython notebook. Тем кто занимается анализом данных на Python и еще не использует iPython notebook — очень рекомендую!
Для построения модели будем использовать обезличенные данные.
1. Подготовка данных в MySQL
Для начала зальём дампы в MySQL и удалим всех пользователей с id < 35 000 000 для простоты дальнейшей обработки. Я взял таблицы member_details и aminno_member.
Заливка данных происходит не очень быстро, даже на сервере с SSD (некоторые таблицы весят около 10 Гигов)
Далее нам необходимо залить данные об оплатах из csv и получить сумму по каждому пользователю. В итоге получилась таблица pays c полями id и sum.
2. Загружаем данные в pandas
Джойним 3 таблицы по id юзера и получаем DataFrame для дальнейшей обработки. Берем только пользователей с фотографиями, я думаю что это является признаком хоть какой-то активности в системе:
engine = create_engine('mysql://login:pass@localhost:3306/db') # Creating MySQL engine sql = """ SELECT md.pnum, p.sum, am.gender, am.photos_public, md.profile_weight, md.profile_height, md.eye_color, md.hair_color, md.dob, md.profile_smoke, md.profile_ethnicity, md.profile_bodytype, md.profile_initially_seeking FROM `member_details` AS md JOIN `aminno_member` AS am ON md.pnum = am.pnum LEFT JOIN pays AS p ON md.pnum = p.id WHERE md.dob is not null AND (am.photos_public > 0 OR p.sum is not NULL) """ df = pd.read_sql_query(sql, engine).fillna(0).set_index('pnum') #Reading data from mysql DB to pandas dataframe
Извлекаем год и месяц рождения:
df['month_of_birth'] = df['dob'].apply(lambda x:x.month) df['year_of_birth'] = df['dob'].apply(lambda x:x.year)
Попробуем проанализировать зависит ли целевая переменная(платил/не платил) от характеристик пользователя? Есть ли смысл строить модель?
Разделим анализируемых пользователей на 2 части: df0 — те кто хоть сколько-то платил, df1 — ничего не платили.
THRESHOLD = 0.0001 df0 = df[(df['sum'] > THRESHOLD)] df1 = df[(df['sum'] < THRESHOLD)]
Строим по 2 гистограммы для каждого из параметров пользователя. Красным — те кто платил, синим — не платившие.
cols = ['profile_weight','profile_height','year_of_birth','month_of_birth', 'eye_color', 'hair_color','profile_smoke', 'profile_ethnicity', 'profile_bodytype', 'profile_initially_seeking','gender'] for col in cols: plt.figure(figsize=(10,10)) df0[col].hist(bins=50, alpha=0.9, color = 'red', normed=1) df1[col].hist(bins=50, alpha=0.7, normed=1) plt.title(col) plt.show()
Рассмотрим самые интересные:
Год рождения:
Результат вполне ожидаем: возраст влияет на целевую переменную. Старшие платят охотнее. Пик гистограммы у платящих приходится примерно на 35 лет.
Вес:
Тут интересней: охотнее платят те кто больше весит. Хотя тоже вполне логично
Рост:
Высокие платят немного охотнее. Распределение очень неравномерное. Возможно рост на сайте задается не числом, а промежутком.
Курение:
К вопросу о заголовке статьи. Просматривается явная зависимость, вопрос — что означают значения 1,2,3,4?
Остальные параметры пользователя не дают такой интересной картины, хотя тоже имеют свой вклад. Здесь есть полный вариант данного notebook где можно ознакомиться со всеми гистограммами.
2. Предсказание вероятности оплаты
Для начала выделим целевую переменную (платил/не платил) которую и будем предсказывать:
y = (df['sum'] > THRESHOLD).astype(np.int32)
Выделим категориальные признаки и проведем их бинаризацию:
categorical = ['month_of_birth', 'eye_color', 'hair_color','profile_smoke', 'profile_ethnicity', 'profile_bodytype', 'profile_initially_seeking'] ohe = preprocessing.OneHotEncoder(dtype=np.float32) Xcategories = ohe.fit_transform(df[categorical]).todense()
Выделим метрические признаки и объединим их с результатом бинаризации:
numeric = ['gender','profile_weight','profile_height','year_of_birth'] Xnumeric = df[numeric].as_matrix() X = np.hstack((Xcategories,Xnumeric))
Разбиваем выборку на 2 части 90% и 10%. На первой будем обучать и тюнить модель. На второй — оценивать точность полученной модели.
X_train, X_test, y_train, y_test = cross_validation.train_test_split(X, y, test_size=0.1, random_state=7)
Тренируем классификатор RandomForest и подбираем оптимальные параметры.
from sklearn.preprocessing import StandardScaler from sklearn.ensemble import RandomForestClassifier from sklearn import decomposition, pipeline, metrics, grid_search rf = RandomForestClassifier(random_state=7, n_jobs=4) scl = StandardScaler() clf = pipeline.Pipeline([('scl', scl), ('rf', rf)]) param_grid = {'rf__n_estimators': (100,200), 'rf__max_depth': (10,20), } model = grid_search.GridSearchCV(estimator = clf, param_grid=param_grid, scoring='roc_auc', verbose=10, cv=3) model.fit(X_train, y_train) print("Best score: %0.3f" % model.best_score_) print("Best parameters set:") best_parameters = model.best_estimator_.get_params() for param_name in sorted(param_grid.keys()): print("\t%s: %r" % (param_name, best_parameters[param_name]))
Best score: 0.802 Best parameters set: rf__max_depth: 20 rf__n_estimators: 200
Оценим значимость признаков:
best = model.best_estimator_ print best.steps[1][1].feature_importances_
[ 0.01083346 0.00745737 0.00754652 0.00764087 0.0075468 0.00769951 0.00780227 0.0076059 0.00747405 0.00733789 0.00720822 0.00720196 0.01067164 0.00229657 0.00271315 0.00403617 0.00453246 0.00420906 0.01227852 0.00166965 0.00060406 0.00293115 0.00347255 0.00581456 0.00176878 0.00060611 0.00129565 0.06303697 0.00526695 0.00408359 0.04618295 0.03014204 0.00401634 0.00312768 0.0041792 0.00073294 0.00260749 0.00137382 0.00385419 0.03020433 0.00788376 0.01423438 0.00953692 0.01218361 0.00685376 0.00812187 0.00433835 0.00294894 0.01210143 0.00806778 0.00458055 0.01323813 0.01434638 0.0120177 0.03383968 0.1623351 0.11347244 0.2088358 ]
Самые значимые (по уменьшению значимости): year_of_birth, profile_weight, profile_height.
Оцениваем качество модели на тестовой выборке и построим ROC кривую:
from sklearn.metrics import roc_curve,roc_auc_score y_pred = best.predict_proba(X_test).T[1] print roc_auc_score(y_test, y_pred) fpr, tpr , thresholds = roc_curve(y_test, y_pred) plt.figure(figsize=(10,10)) plt.plot(fpr, tpr, label='ROC curve') plt.plot([0, 1], [0, 1], 'k--') plt.xlim([0.0, 1.0]) plt.ylim([0.0, 1.05]) plt.xlabel('False Positive Rate') plt.ylabel('True Positive Rate') plt.title('Receiver operating characteristic') plt.legend(loc="lower right") plt.show()
Для измерения качества классификатора будем использовать ROC_AUC score
ROC_AUC = 0.79926
Результаты
Предсказывать склонность пользователей к оплате услуг действительно можно. Точность не очень высокая (roc_auc = 0.8), но мы использовали только часть параметров и вообще не обращали внимания на поведенческие факторы (нет данных).
Что дальше?
- Можно попробовать предсказать что-то на основе вкусов/предпочтений. В базе есть поля 'pref_opento','pref_lookingfor' вида «12|17|58|97» — это ссылки на какой-то справочник которого нет. Построить модель можно и без него, а вот интерпретировать не получится.
- Попробовать регрессионную модель и предсказывать сумму, а не факт оплаты.
- Поиграться с алгоритмами, объемом выборки, параметрами выборки (я использовал photos_public > 0)
- Ваши предложения?
UPD:
Для желающих поиграться с данными самостоятельно выкладываю дамп DataFrame
yadi.sk/d/YaNM8DTZj2ybn
import joblib import pandas as pd df = joblib.load("1.pkl") print df
И вперед!

