
Хабр Курсы для всех
РЕКЛАМА
Практикум, Хекслет, SkyPro, авторские курсы — собрали всех и попросили скидки. Осталось выбрать!
try! получается гораздо короче, чем использование try-catch блока в тех же сценариях. foo!. Это что-то вроде «будь внимателен, здесь происходит что-то необычное».try!, println!, format!, vec!, assert! и assert_eq!try. Например, что-то вроде foo(try bar()). Для остальных случаев есть более универсальная конструкция match, которая уже и так умеет все то, что в обычных языках умеет try-catch блок. Единственное отличие – match работает для каждого конкретного вызова, в то время как try-catch может оборачивать целый блок кода. Но я бы поспорил о том, что это недостаток для языка программирования, который делает ставку на надежность.fn write_to_file_using_try() -> io::Result<()> {
let mut file = try!(File::create("my_best_friends.txt"));
try!(file.write_all(b"This is a list of my best friends."));
println!("I wrote to the file");
Ok(())
}
fn write_to_file_using_mdo() -> io::Result<()> {
mdo! {
mut file =<< File::create("my_best_friends.txt");
ign file.write_all(b"This is a list of my best friends.");
ign Ok(println!("I wrote to the file"));
ret Ok(())
}
}
Его размер здесь не важен, но если хотите, то вот цифры (это честные SLOC, без пробелов и комментариев)Вообще говоря важен, особенно не в абсолютных цифрах, а в степени вовлечённости в архитектуре. MaidSafe ещё не релизнулся, вы не компетентны если называете opens-source поделку до первого RC «продакшеном». 14000 LOC это смешно, у меня хобби-проект на Go за полтора месяца вышел на 8000. 14000 с учётом специфики задач это уровень концепта.
Redox — это активно разрабатываемая ОСЯ не буду вас ловить и проверять, насколько активно и какие там люди (больше, чем полтора ботана, надеюсь). По моему опыту разработки модулей и драйверов Linux — раст там вообще ничем не поможет. А до продакшена этой поделке лет 5 в лучшем случае, 20 в обычном.
больше, чем полтора ботана, надеюсьЛинус вон вообще один начинал, в чём проблема-то?
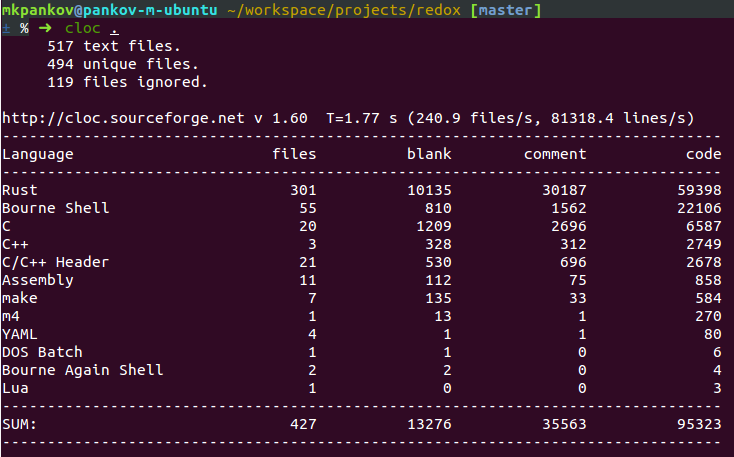
А до продакшена этой поделке лет 5 в лучшем случае, 20 в обычном.Сколько лет пройдёт до того, как махровая индустрия возьмёт на вооружение Rust обсуждать есть смысл только с учётом того, что Go появился на 3 года раньше Rust. Прямые сравнения неуместны.
продакшен это коммерчески успешные проекты, когда люди за свои ошибки отвечают жопами, а код прибывает по 10к в неделю минимум.
боевой код, который работает в реальных условиях — это productionтоварища mkpankov у вас вопросов нет? Или вы согласны, что он неадекват и интересуетесь именно этим определением? Что-ж почитайте вот jdevelop.blogspot.ru/2013/03/blog-post.html
Я например хочу написать веб приложение, что лучше использоватьRuby on Rails, потому что быстрее и проще, а узкие места переписать на Go всегда успеете. Всё равно их переписывать придётся.
История успеха — это Servo.
это не NodeJs со своей лапшей (Callbacki)
javascript es2015
150u8 + 150u8 паникует в случае переполнения (и корректно завершает поток).150u8.checked_add(150u8) возвращает Option<T> со значением None.150u8.saturating_add(150u8) возвращает граничное значение (255).150u8.wrapping_add(150u8) игнорирует переполнение (44).+ ведет себя аналогично wrapping_add.Некоторая потеря эффективностиЯ не могу понять, в чем потеря эффективности? Не сущесвует никакой возможности впихнуть тип «i32 или ничего» в 4 байта. По-любому нужен еще хотя-бы один бит, чтобы кодировать это «ничего». Как раз для этого необходим дискриминант. Никто вам не мешает возвращать из функции просто i32, размером в 4 байта.
Я не могу понять, в чем потеря эффективности? Не сущесвует никакой возможности впихнуть тип «i32 или ничего» в 4 байта.
hFile = CreateFile(...);
if (hFile == INVALID_NAHDLE_VALUE) ...Никто вам не мешает возвращать из функции просто i32, размером в 4 байта.
Если для этого нужно усложнять концепцию, вставив в описание Option ручное указание значения-исключения для NONE, такое усложение стоит выигрыша в скорости.Да, а вы как себе представляете решение этой проблемы без этого, но чтобы нельзя было забыть обработать ошибку?
Да, а вы как себе представляете решение этой проблемы без этого, но чтобы нельзя было забыть обработать ошибку?
Option<&T>. Такой тип занимает 4 байта (для 32-битной архитектуры), и значение 0 трактуется как None.как приведенный вами пример позволяет узнать причину ошибки?
Компилятор сообщает о синтаксической ошибке на «hello world», взятый из учебника.Какая ошибка у вас?
Компилятор Rust выдаёт не исполняемый код, а код в LLVM IR.Это не так, компилятор Rust как исполняемый файл rustc выдаёт исполняемый код. LLVM IR используется внутри и скрыто от пользователя. Visual C++ используется не здесь, а при компоновке с системными библиотеками и нужен если вам нужно MSVC ABI — из всего Visual C++ нужен лишь link.exe.
Вместо макроса try! можно использовать оператор ? для автоматического возврата ошибок
use std::fs::File;
use std::io::{self, Read};
use std::path::Path;
#[derive(Debug)]
enum CliError {
IoError(io::Error),
ParseError(std::num::ParseIntError),
}
impl From<io::Error> for CliError {
fn from(err: io::Error) -> CliError {
CliError::IoError(err)
}
}
impl From<std::num::ParseIntError> for CliError {
fn from(err: std::num::ParseIntError) -> CliError {
CliError::ParseError(err)
}
}
//fn file_double<P: AsRef<Path>>(file_path: P) -> Result<i32, CliError>
fn file_double(file_path: AsRef<Path>) -> Result<i32, CliError>{
let mut file = File::open(file_path)?;
let mut contents = String::new();
file.read_to_string(&mut contents)?;
let n: i32 = contents.trim().parse()?;
Ok(2 * n)
}
fn main() {
match file_double("path/to/your/file.txt") {
Ok(result) => println!("Result: {}", result),
Err(e) => eprintln!("Error: {:?}", e),
}
}Или даже так
fn file_double(file_path: AsRef<Path>) -> Result<i32, CliError>
File::open(file_path)?
.read_to_string(&mut String::new())?
.trim()
.parse::<i32>()
.map(|n| 2 * n)
Обработка ошибок в Rust