Я часто собеседую разработчиков и часто задаю им простой, как кувалда, вопрос — как внутри работает JOIN в SQL? В ответ я обычно слышу бессвязное мычание про волшебные деревья и индексы, которые быстрее. Когда-то мне казалось, что каждый программист специалист должен знать то, с чем работает. Впоследствии жизнь объяснила мне, что это не так. Но мне все еще не понятно, как можно годами теребить базёнку, даже не догадываясь, а что там у нее «под капотом»?
Давайте проведем ликбез и вместе посмотрим, как же работают эти джойны, и даже сами реализуем парочку алгоритмов.
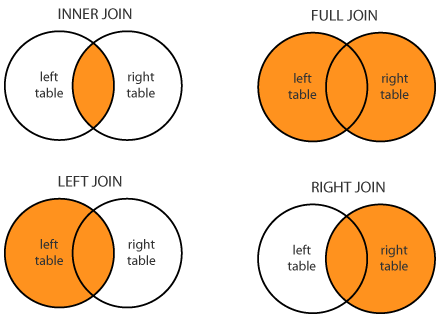
Людям, которые утверждают, что много и плотно работали с SQL, я задаю на собеседованиях вот такую задачу.
Есть SQL команда
Нужно выполнить то же самое на Java, т.е. реализовать метод
Я не прошу прям закодить реализацию, но жду хотя бы устного объяснения алгоритма.
Дополнительно я спрашиваю, что нужно изменить в сигнатуре и реализации, чтобы сделать вид, что мы работаем с индексами.
Давайте сначала разберемся, для чего нам вообще думать об устройстве джойнов?
Самый базовый алгоритм объединения двух списков сейчас проходят в школах. Суть очень простая — для каждого элемента первого списка пройдемся по всем элементам второго списка; если ключи элементов вдруг оказались равны — запишем совпадение в результирующую таблицу. Для реализации этого алгоритма достаточно двух вложенных циклов, именно поэтому он так и называется.
Основной плюс этого метода — полное безразличие к входным данным. Алгоритм работает для любых двух таблиц, не требует никаких индексов и перекладываний данных в памяти, а также прост в реализации. На практике это означает, что достаточно просто бежать по диску двумя курсорами и периодически выплёвывать в сокет совпадения.
Однако ж, фатальный минус алгоритма — высокая временная сложность O(N*M) (квадратичная асимптотика, если вы понимаете, о чем я). Например, для джойна пары небольших таблиц в 100к и 500к записей потребуется сделать аж 100.000 * 500.000 = 50.000.000.000 (50 млрд) операций сравнения. Запросы с таким джойном будут выполняться невежливо долго, часто именно они — причина беспощадных тормозов кривеньких самописных CMS’ок.
Современные РСУБД используют nested loops join в самых безнадежных случаях, когда не удается применить никакую оптимизацию.
UPD. zhekappp и potapuff поправляют, что nested loops эффективен для малого числа строк, когда разворачивать какую-либо оптимизацию выйдет дороже, чем просто пробежаться вложенным циклом. Есть класс систем, для которых это актуально.
Если размер одной из таблиц позволяет засунуть ее целиком в память, значит, на ее основе можно сделать хеш-таблицу и быстренько искать в ней нужные ключи. Проговорим чуть подробнее.
Проверим размер обоих списков. Возьмем меньший из списков, прочтем его полностью и загрузим в память, построив HashMap. Теперь вернемся к большему списку и пойдем по нему курсором с начала. Для каждого ключа проверим, нет ли такого же в хеш-таблице. Если есть — запишем совпадение в результирующую таблицу.
Временная сложность этого алгоритма падает до линейной O(N+M), но требуется дополнительная память.
Что важно, во времена динозавров считалось, что в память нужно загрузить правую таблицу, а итерироваться по левой. У нормальных РСУБД сейчас есть статистика cardinality, и они сами определяют порядок джойна, но если по какой-то причине статистика недоступна, то в память грузится именно правая таблица. Это важно помнить при работе с молодыми корявыми инструментами типа Cloudera Impala.
А теперь представим, что данные в обоих списках заранее отсортированы, например, по возрастанию. Так бывает, если у нас были индексы по этим таблицам, или же если мы отсортировали данные на предыдущих стадиях запроса. Как вы наверняка помните, два отсортированных списка можно склеить в один отсортированный за линейное время — именно на этом основан алгоритм сортировки слиянием. Здесь нам предстоит похожая задача, но вместо того, чтобы склеивать списки, мы будем искать в них общие элементы.
Итак, ставим по курсору в начало обоих списков. Если ключи под курсорами равны, записываем совпадение в результирующую таблицу. Если же нет, смотрим, под каким из курсоров ключ меньше. Двигаем курсор над меньшим ключом на один вперед, тем самым “догоняя” другой курсор.
Если данные отсортированы, то временная сложность алгоритма линейная O(M+N) и не требуется никакой дополнительной памяти. Если же данные не отсортированы, то нужно сначала их отсортировать. Из-за этого временная сложность возрастает до O(M log M + N log N), плюс появляются дополнительные требования к памяти.
Вы могли заметить, что написанный выше код имитирует только INNER JOIN, причем рассчитывает, что все ключи в обоих списках уникальные, т.е. встречаются не более, чем по одному разу. Я сделал так специально по двум причинам. Во-первых, так нагляднее — в коде содержится только логика самих джойнов и ничего лишнего. А во-вторых, мне очень хотелось спать. Но тем не менее, давайте хотя бы обсудим, что нужно изменить в коде, чтобы поддержать различные типы джойнов и неуникальные значения ключей.
Первая проблема — неуникальные, т.е. повторяющиеся ключи. Для повторяющихся ключей нужно порождать декартово произведение всех соответствющих им значений.
В Nested Loops Join почему-то это работает сразу.
В Hash Join придется заменить HashMap на MultiHashMap.
Для Merge Join ситуация гораздо более печальная — придется помнить, сколько элементов с одинаковым ключом мы видели.
Работа с неуникальными ключами увеличивает асимптотику до O(N*m+M*n), где n и m — среднее записей на ключ в таблицах. В вырожденном случае, когда n=N и m=M, операция превращается в CROSS JOIN.
Вторая проблема — надо следить за ключами, для которых не нашлось пары.
Для Merge Join ключ без пары видно сразу для всех направлений JOIN’а.
Для Hash Join сразу можно увидеть нехватку соответствующих ключей при джойне слева. Для того, чтобы фиксировать непарные ключи справа, придется завести отдельный флаг “есть пара!” для каждого элемента хеш-таблицы. После завершения основного джойна надо будет пройти по всей хеш-таблице и добавить в результат ключи без флага пары.
Для Nested Loops Join ситуация аналогичная, причем все настолько просто, что я даже осилил это закодить:
Если вы дочитали досюда, значит, статья показалась вам интересной. А значит, вы простите мне небольшую порцию нравоучений.
Я действительно считаю, что знания РСУБД на уровне SQL абсолютно не достаточно, чтобы считать себя профессиональным разработчиком ПО. Профессионал должен знать не только свой код, но и примерное устройство соседей по стеку, т.е. 3rd-party систем, которые он использует — баз данных, фреймворков, сетевых протоколов, файловых систем. Без этого разработчик вырождается до кодера или оператора ЭВМ, и в по настоящему сложных масштабных задачах становится бесполезен.
UPD. Несмотря на это послесловие, статья, на самом деле, про JOIN'ы.
Disclaimer: вообще-то, я обещал еще одну статью про Scalding, но предыдущая не вызвала большого интереса у публики. Из-за этого тему решено было сменить.
Давайте проведем ликбез и вместе посмотрим, как же работают эти джойны, и даже сами реализуем парочку алгоритмов.
Постановка задачи
Людям, которые утверждают, что много и плотно работали с SQL, я задаю на собеседованиях вот такую задачу.
Есть SQL команда
SELECT left.K, left.V1, right.V2 FROM left JOIN right ON left.K = right.K;
Нужно выполнить то же самое на Java, т.е. реализовать метод
<K, V1, V2> List<Triple<K, V1, V2>> join(List<Pair<K, V1>> left, List<Pair<K, V2>> right);
Я не прошу прям закодить реализацию, но жду хотя бы устного объяснения алгоритма.
Дополнительно я спрашиваю, что нужно изменить в сигнатуре и реализации, чтобы сделать вид, что мы работаем с индексами.
Давайте сначала разберемся, для чего нам вообще думать об устройстве джойнов?
- Знать теорию полезно из чисто познавательных соображений.
- Если вы различаете типы джойнов, то план выполнения запроса, который получается командой EXPLAIN, больше не выглядит для вас как набор непонятных английских слов. Вы можете видеть в плане потенциально медленные места и оптимизировать запрос переписыванием или хинтами.
- В новомодных аналитических инструментах поверх Hadoop планировщик запросов или малость туповат (см. Cloudera Impala), или его вообще нет (см. Twitter Scalding, Spark RDD). В последнем случае приходится собирать запрос вручную из примитивных операций.
Наконец, есть риск, что однажды вы попадете на собеседование ко мне или к другому зануде.Но на самом деле, статья не про собеседования, а про операцию JOIN.
Nested Loops Join
Самый базовый алгоритм объединения двух списков сейчас проходят в школах. Суть очень простая — для каждого элемента первого списка пройдемся по всем элементам второго списка; если ключи элементов вдруг оказались равны — запишем совпадение в результирующую таблицу. Для реализации этого алгоритма достаточно двух вложенных циклов, именно поэтому он так и называется.
public static <K, V1, V2> List<Triple<K, V1, V2>> nestedLoopsJoin(List<Pair<K, V1>> left, List<Pair<K, V2>> right) { List<Triple<K, V1, V2>> result = new ArrayList<>(); for (Pair<K, V1> leftPair: left) { for (Pair<K, V2> rightPair: right) { if (Objects.equals(leftPair.k, rightPair.k)) { result.add(new Triple<>(leftPair.k, leftPair.v, rightPair.v)); } } } return result; }
Основной плюс этого метода — полное безразличие к входным данным. Алгоритм работает для любых двух таблиц, не требует никаких индексов и перекладываний данных в памяти, а также прост в реализации. На практике это означает, что достаточно просто бежать по диску двумя курсорами и периодически выплёвывать в сокет совпадения.
Однако ж, фатальный минус алгоритма — высокая временная сложность O(N*M) (квадратичная асимптотика, если вы понимаете, о чем я). Например, для джойна пары небольших таблиц в 100к и 500к записей потребуется сделать аж 100.000 * 500.000 = 50.000.000.000 (50 млрд) операций сравнения. Запросы с таким джойном будут выполняться невежливо долго, часто именно они — причина беспощадных тормозов кривеньких самописных CMS’ок.
Современные РСУБД используют nested loops join в самых безнадежных случаях, когда не удается применить никакую оптимизацию.
UPD. zhekappp и potapuff поправляют, что nested loops эффективен для малого числа строк, когда разворачивать какую-либо оптимизацию выйдет дороже, чем просто пробежаться вложенным циклом. Есть класс систем, для которых это актуально.
Hash Join
Если размер одной из таблиц позволяет засунуть ее целиком в память, значит, на ее основе можно сделать хеш-таблицу и быстренько искать в ней нужные ключи. Проговорим чуть подробнее.
Проверим размер обоих списков. Возьмем меньший из списков, прочтем его полностью и загрузим в память, построив HashMap. Теперь вернемся к большему списку и пойдем по нему курсором с начала. Для каждого ключа проверим, нет ли такого же в хеш-таблице. Если есть — запишем совпадение в результирующую таблицу.
Временная сложность этого алгоритма падает до линейной O(N+M), но требуется дополнительная память.
public static <K, V1, V2> List<Triple<K, V1, V2>> hashJoin(List<Pair<K, V1>> left, List<Pair<K, V2>> right) { Map<K, V2> hash = new HashMap<>(right.size()); for (Pair<K, V2> rightPair: right) { hash.put(rightPair.k, rightPair.v); } List<Triple<K, V1, V2>> result = new ArrayList<>(); for (Pair<K, V1> leftPair: left) { if (hash.containsKey(leftPair.k)) { result.add(new Triple<>(leftPair.k, leftPair.v, hash.get(leftPair.k))); } } return result; }
Что важно, во времена динозавров считалось, что в память нужно загрузить правую таблицу, а итерироваться по левой. У нормальных РСУБД сейчас есть статистика cardinality, и они сами определяют порядок джойна, но если по какой-то причине статистика недоступна, то в память грузится именно правая таблица. Это важно помнить при работе с молодыми корявыми инструментами типа Cloudera Impala.
Merge Join
А теперь представим, что данные в обоих списках заранее отсортированы, например, по возрастанию. Так бывает, если у нас были индексы по этим таблицам, или же если мы отсортировали данные на предыдущих стадиях запроса. Как вы наверняка помните, два отсортированных списка можно склеить в один отсортированный за линейное время — именно на этом основан алгоритм сортировки слиянием. Здесь нам предстоит похожая задача, но вместо того, чтобы склеивать списки, мы будем искать в них общие элементы.
Итак, ставим по курсору в начало обоих списков. Если ключи под курсорами равны, записываем совпадение в результирующую таблицу. Если же нет, смотрим, под каким из курсоров ключ меньше. Двигаем курсор над меньшим ключом на один вперед, тем самым “догоняя” другой курсор.
public static <K extends Comparable<K>, V1, V2> List<Triple<K, V1, V2>> mergeJoin( List<Pair<K, V1>> left, List<Pair<K, V2>> right ) { List<Triple<K, V1, V2>> result = new ArrayList<>(); Iterator<Pair<K, V1>> leftIter = left.listIterator(); Iterator<Pair<K, V2>> rightIter = right.listIterator(); Pair<K, V1> leftPair = leftIter.next(); Pair<K, V2> rightPair = rightIter.next(); while (true) { int compare = leftPair.k.compareTo(rightPair.k); if (compare < 0) { if (leftIter.hasNext()) { leftPair = leftIter.next(); } else { break; } } else if (compare > 0) { if (rightIter.hasNext()) { rightPair = rightIter.next(); } else { break; } } else { result.add(new Triple<>(leftPair.k, leftPair.v, rightPair.v)); if (leftIter.hasNext() && rightIter.hasNext()) { leftPair = leftIter.next(); rightPair = rightIter.next(); } else { break; } } } return result; }
Если данные отсортированы, то временная сложность алгоритма линейная O(M+N) и не требуется никакой дополнительной памяти. Если же данные не отсортированы, то нужно сначала их отсортировать. Из-за этого временная сложность возрастает до O(M log M + N log N), плюс появляются дополнительные требования к памяти.
Outer Joins
Вы могли заметить, что написанный выше код имитирует только INNER JOIN, причем рассчитывает, что все ключи в обоих списках уникальные, т.е. встречаются не более, чем по одному разу. Я сделал так специально по двум причинам. Во-первых, так нагляднее — в коде содержится только логика самих джойнов и ничего лишнего. А во-вторых, мне очень хотелось спать. Но тем не менее, давайте хотя бы обсудим, что нужно изменить в коде, чтобы поддержать различные типы джойнов и неуникальные значения ключей.
Первая проблема — неуникальные, т.е. повторяющиеся ключи. Для повторяющихся ключей нужно порождать декартово произведение всех соответствющих им значений.
В Nested Loops Join почему-то это работает сразу.
В Hash Join придется заменить HashMap на MultiHashMap.
Для Merge Join ситуация гораздо более печальная — придется помнить, сколько элементов с одинаковым ключом мы видели.
Работа с неуникальными ключами увеличивает асимптотику до O(N*m+M*n), где n и m — среднее записей на ключ в таблицах. В вырожденном случае, когда n=N и m=M, операция превращается в CROSS JOIN.
Вторая проблема — надо следить за ключами, для которых не нашлось пары.
Для Merge Join ключ без пары видно сразу для всех направлений JOIN’а.
Для Hash Join сразу можно увидеть нехватку соответствующих ключей при джойне слева. Для того, чтобы фиксировать непарные ключи справа, придется завести отдельный флаг “есть пара!” для каждого элемента хеш-таблицы. После завершения основного джойна надо будет пройти по всей хеш-таблице и добавить в результат ключи без флага пары.
Для Nested Loops Join ситуация аналогичная, причем все настолько просто, что я даже осилил это закодить:
public static <K, V1, V2> List<Triple<K, V1, V2>> nestedLoopsJoin( List<Pair<K, V1>> left, List<Pair<K, V2>> right, JoinType joinType ) { // Массив для обозначения ключей из правого списка, которым не нашлось пары в левом BitSet rightMatches = new BitSet(right.size()); List<Triple<K, V1, V2>> result = new ArrayList<>(); for (Pair<K, V1> leftPair: left) { // Флаг для обозначения ключей в левом списке, которым не нашлось пары в правом boolean match = false; for (ListIterator<Pair<K, V2>> iterator = right.listIterator(); iterator.hasNext(); ) { Pair<K, V2> rightPair = iterator.next(); if (Objects.equals(leftPair.k, rightPair.k)) { result.add(new Triple<>(leftPair.k, leftPair.v, rightPair.v)); // Отмечаем пары match = true; rightMatches.set(iterator.previousIndex(), true); } } // Заполняем несоответствия в левом списке if ((joinType == JoinType.LEFT || joinType == JoinType.FULL) && !match) { result.add(new Triple<>(leftPair.k, leftPair.v, null)); } } // Заполняем несоответствия в правом списке if (joinType == JoinType.RIGHT || joinType == JoinType.FULL) { for (int i = 0; i < right.size(); ++i) { if (!rightMatches.get(i)) { Pair<K, V2> rightPair = right.get(i); result.add(new Triple<>(rightPair.k, null, rightPair.v)); } } } return result; }
Морализаторское послесловие
Если вы дочитали досюда, значит, статья показалась вам интересной. А значит, вы простите мне небольшую порцию нравоучений.
Я действительно считаю, что знания РСУБД на уровне SQL абсолютно не достаточно, чтобы считать себя профессиональным разработчиком ПО. Профессионал должен знать не только свой код, но и примерное устройство соседей по стеку, т.е. 3rd-party систем, которые он использует — баз данных, фреймворков, сетевых протоколов, файловых систем. Без этого разработчик вырождается до кодера или оператора ЭВМ, и в по настоящему сложных масштабных задачах становится бесполезен.
UPD. Несмотря на это послесловие, статья, на самом деле, про JOIN'ы.
Дополнительные материалы
- Роскошная статья про устройство РСУБД
- Роскошная книга про алгоритмы. Полезно полистать перед собеседованием.
Disclaimer: вообще-то, я обещал еще одну статью про Scalding, но предыдущая не вызвала большого интереса у публики. Из-за этого тему решено было сменить.

