
Хабр Курсы для всех
РЕКЛАМА
Практикум, Хекслет, SkyPro, авторские курсы — собрали всех и попросили скидки. Осталось выбрать!
(((x*x)**0.106)**2))
Как происходит мутация формул? Она затрагивает один из токенов, содержащихся в формуле, и может пойти тремя путями:
Как выбрать из двух претендентов, если они одинаково не отсортировали массив
итоги первого эксперимента заставили меня сильно усомниться в шансах на успех с сортировками
Кажется стоит допилить сокращения таких штук
Вообще операция возведения в степень неожиданно много проблем вызвала. Я даже задумывался о том, включать ли её вообще. Отчасти поэтому, когда работал над сокращениями, не учел работу с ней
А что если в качестве ещё одного вида мутации константам добавить округление
Это и происходит в случае shift: константа может поменять свой тип с Float на Int, и, таким образом, отбросить дробную часть.
Касательно сортировок. Да, согласен, оценка степени сортированности массива это первый из наиболее напрашивающихся критериев успеха. Но, повторюсь, неверные шаги сортировок искажают их до неузнаваемости. Тут можно провести аналогию с хеш-функцией, где решение это исходная строка, а результат оценивается по её хешу. Один символ в строке поменялся — хеш радикально преобразился.
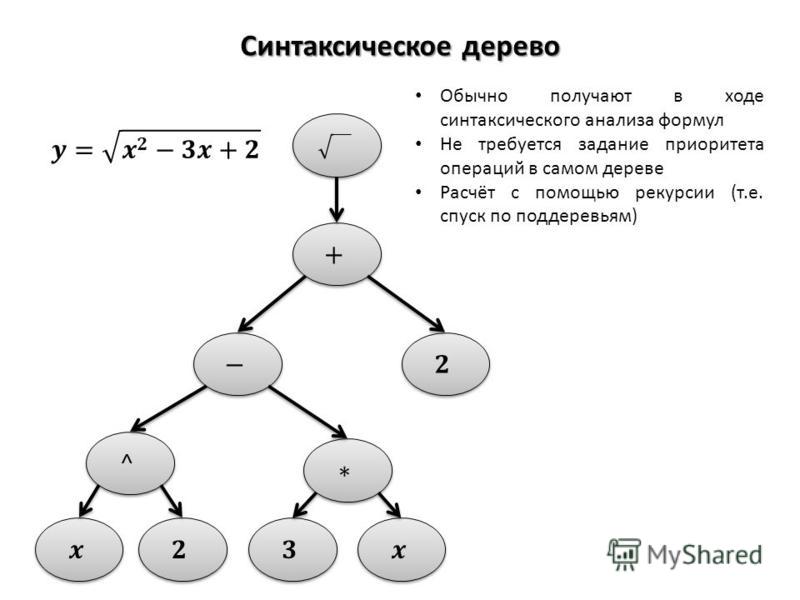
Ваша картинка:

Геном в первом эксперименте и представлен в виде дерева, например:
xp2 = Formula::PowerOperator.new(Formula::Variable.new(:x), Formula::IntConstant.new(2)) # (x**2)
xm3 = Formula::MultiplicationOperator.new(Formula::IntConstant.new(3), Formula::Variable.new(:x)) # (3*x)
xp_xm = Formula::SubtractionOperator.new(xp2, xm3) # ((x**2)-(3*x))
xpx = Formula::AdditionOperator.new(xp_xm, Formula::IntConstant.new(2)) # (((x**2)-(3*x))+2)
f = Formula::PowerOperator.new(xpx, Formula::FloatConstant.new(0.5)) # ((((x**2)-(3*x))+2)**0.500)Да, возможно имело смысл обратиться к готовым решениям по сокращениям.
Спасибо за наводки, ознакомлюсь.
Применение Генетического Алгоритма для упаковки 2D обьектов: https://github.com/Jack000/SVGnest
Вы, как человек, уже прочитавший серьезную литературу, не могли бы чуть более развернуто аргументировать свою позицию и привести доводы из указанного источника?
в том числе новомодные вроде нейросетей
Но ведь ИНС уже более 50 лет, и они многократно доказывали свою эффективность. Практически всё современные реализации распознавания образов работают на ИНС, и позволяют решать задачи, которые нам и не снились раньше.
В комментариях выше есть замечательные примеры практического применения концепции ГА.
Никто не говорит о данных методах как о панацее, "серебрянной пуле" и т.п. Но они реально небесполезны, и это факт. Непонятно, почему находятся те, кто с этим по-прежнему спорит.
Что касается примера, использованного в статье — что поделать, на прорыв в кибернетике он не тянет :) С другой стороны, на простом примере, "на пальцах", легче доносить мысли и что-то объяснять.
Точно! Вот о чем я забыл! Ещё в прошлом году, когда идея с генетическими алгоритмами была только в голове, в одном из экспериментов я планировал заново "изобрести" алгоритм быстого InvSqrt Кармака из Quake. Потом я, уже не помню почему, остановился на варианте с сортировками. А ведь InvSqrt действительно кажется более подходящей задачей для ГА.
Заметил в Вашем примере родословной, что нектороые синтксически разные деревья, на самом деле семантически одинаковы:
(((x-0)**2)/1)
((((x-0)**2)-0)/1)
(((x-0)**2)-0)
(((x-0)**2)-0.000)Некоторое время тому я тоже интересовался данной тематикой.
Чтобы уменьшить количество семантически одинаковых деревьев, я разбивал каждую итерацию Генетического Алгоритма на два этапа:
1) операции над синтаксическими деревьями (скрещивание и мутации)
2) оптимизация числовых коэффициентов каждого синтаксическогг дерева (опять же с использованием Генетического Алгоритма)
Дополнительная оптимизация: в случае, если поддерево не содержит переменных — оно заменяется на лист с единственным числовым значением.
Этот подход позволяет увеличить разнообразие синтаксических деревьев, которые различаются семантически.
Более подробоное описание можно найти в моём посте: https://habrahabr.ru/post/163195/ (правда у меня весь код реализован на Java, и в посте можно найти ссылку на GitHub)
Между ними всё же есть разница, на уровне генотипа, хоть и результат они выдают одинаковый. Я решил определять идентичность основываясь только на генотипе, иначе решения типа:
(x - x)
(0 / x)признавались бы дубликатами. Хотя разность между их генотипами достаточно существенна, и разбегание результатов с большой долей вероятности наступит уже в следующем поколении.
Операция оптимизации в моём случае называется сокращением, и вынесена как один из вариантов мутации, по тем же соображениям:
((4 - 2) * 3)
6Первое дерево может прийти ко второму за одну мутацию типа shift, применённую к операции верхнего уровня (умножению). Однако, пока это разные деревья, и у них, соответственно, разные возможные пути мутации.
{kind=link}
Генетическое программирование («Yet Another Велосипед» Edition)