
Хабр Курсы для всех
РЕКЛАМА
Практикум, Хекслет, SkyPro, авторские курсы — собрали всех и попросили скидки. Осталось выбрать!
При использовании нескольких процессов GIL'а нет
А треды, где GIL есть, использовать не особо и нужно
Можно бы было сделать пул из тредов и по ним распределять нагрузку, при этом используя ивентлуп.
А смысл? При классическом подходе, пул тредов создаётся как раз чтобы обрабатывать I/O операции. Асинхронность решает эту проблему гораздо эффективнее без тредов.
Единственная возможность это делать pickle
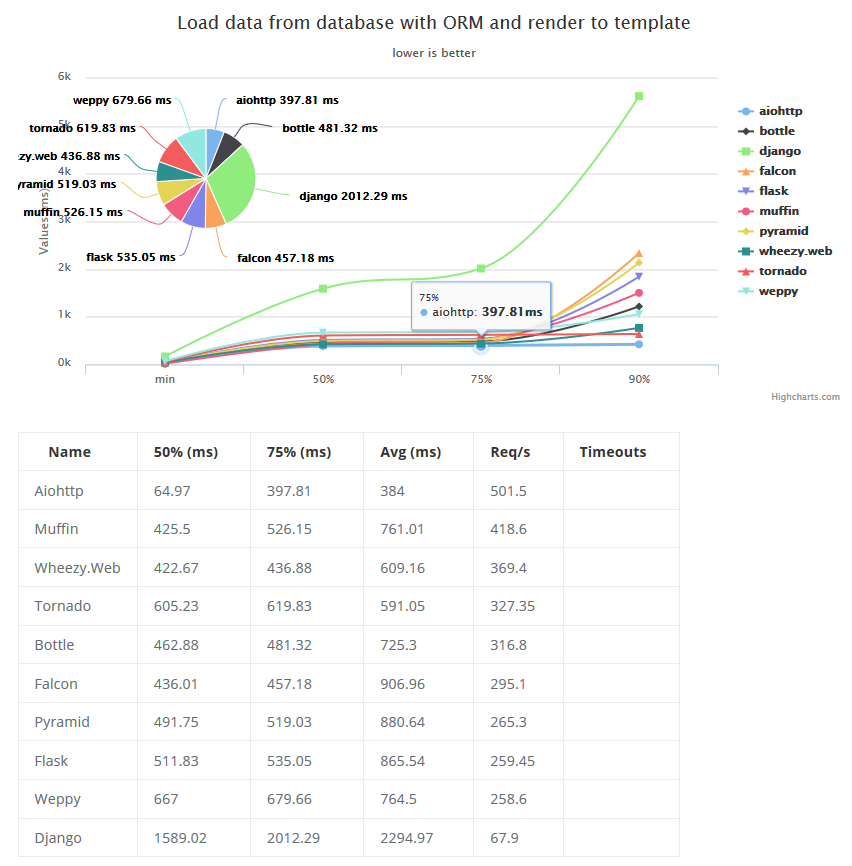
В чем суть вопроса?
Один вопрос — действительно ли это нужно?
Есть идеи как написать бенчмарк?М… можно попробовать поднять какой-нибудь hi-perf DNS-сервер вроде Knot DNS и подолбить его запросами.
2. Вопрос с синхронным dns-резолвером в asyncio/aiohttp все еще открытый
from contextlib import suppress
from io import BytesIO
import asyncio as aio
import aiohttp
import pycurl
import atexit
# Curl event loop:
class CurlLoop:
class Error(Exception): pass
_multi = pycurl.CurlMulti()
atexit.register(_multi.close)
_futures = {}
@classmethod
async def handler_ready(cls, ch):
cls._futures[ch] = aio.Future()
cls._multi.add_handle(ch)
try:
return await cls._futures[ch]
finally:
cls._multi.remove_handle(ch)
@classmethod
def perform(cls):
if cls._futures:
while True:
status, num_active = cls._multi.perform()
if status != pycurl.E_CALL_MULTI_PERFORM:
break
while True:
num_ready, success, fail = cls._multi.info_read()
for ch in success:
cls._futures.pop(ch).set_result('')
for ch, err_num, err_msg in fail:
cls._futures.pop(ch).set_exception(CurlLoop.Error(err_msg))
if num_ready == 0:
break
# Single curl request:
async def request(url, timeout=5):
ch = pycurl.Curl()
try:
ch.setopt(pycurl.URL, url.encode('utf-8'))
ch.setopt(pycurl.FOLLOWLOCATION, 1)
ch.setopt(pycurl.MAXREDIRS, 5)
raw_text_buf = BytesIO()
ch.setopt(pycurl.WRITEFUNCTION, raw_text_buf.write)
with aiohttp.Timeout(timeout):
await CurlLoop.handler_ready(ch)
return raw_text_buf.getvalue().decode('utf-8', 'ignore')
finally:
ch.close()
# Asyncio event loop + CurlLoop:
def run_until_complete(coro):
async def main_task():
pycurl_task = aio.ensure_future(_pycurl_loop())
try:
await coro
finally:
pycurl_task.cancel()
with suppress(aio.CancelledError):
await pycurl_task
# Run asyncio event loop:
loop = aio.get_event_loop()
loop.run_until_complete(main_task())
async def _pycurl_loop():
while True:
await aio.sleep(0)
CurlLoop.perform()
# Test it:
async def main():
url = 'http://httpbin.org/delay/3'
res = await aio.gather(
request(url),
request(url),
request(url),
request(url),
request(url),
)
print(res[0]) # to see result
if __name__ == "__main__":
run_until_complete(main())
@classmethod
def perform(cls):
if cls._futures:
status, num_active = cls._multi.perform()
_, success, fail = cls._multi.info_read()
for ch in success:
cls._futures.pop(ch).set_result('')
for ch, err_num, err_msg in fail:
cls._futures.pop(ch).set_exception(CurlLoop.Error(err_msg))
while True:
status, num_active = cls._multi.perform()
if status != pycurl.E_CALL_MULTI_PERFORM:
break
import redis
import ujson as json
client = redis.Redis()
def application(env, start_response):
start_response('200 OK', [('Content-Type', 'application/json')])
count = client.get("KEY") or 0
return [json.dumps({"result": count}).encode("utf-8")]
Вышел uvloop — продвинутая реализация цикла событий для asyncio в Python