Тем, кто занимается системами машинного обучения и компьютерным зрением, хорошо знакома такая библиотека как OpenBLAS (Basic Linear Algebra Subprograms). OpenBLAS написан на C и используется повсеместно там где нужна работа с матрицами. Так же у него есть несколько альтернативных реализаций таких как Eigen и двух закрытых имплементацией от Intel и Apple. Все они написаны на С\С++.
В настоящий момент OpenBLAS используется в матричных манипуляциях в таких языках как Julia и Python (NumPy). OpenBLAS крайне хорошо оптимизирована и значительная её часть вообще написана на ассемблере.
Однако так ли хорош для вычислений чистый C, как это принято считать?
Встречайте Mir GLAS! Нативная реализация библиотеки линейной алгебры на чисто D без единой вставки на ассемблере!
Для компиляции библиотеки Mir GLAS нам потребуется компилятор LDC (LLVM D Compiler). Компилятор DMD официально не поддерживается т.к. он не поддерживает инструкции AVX и AVX2.
Тестовая конфигурация будет состоять из:
» Код самого теста можно получить тут.
» Mir GLAS базируется на библиотеке mir.ndslice
Mir GLAS может быть легко использован в любом языке поддерживающим C ABI. Делается это элементарно:
Для сравнения в OpenBLAS потребуется написать следующий код:
При проведении теста установлено следующее значение переменных:
Eigen собран с флагами `EIGEN_TEST_AVX` и `EIGEN_TEST_FMA`:
Результаты (больше — лучше):

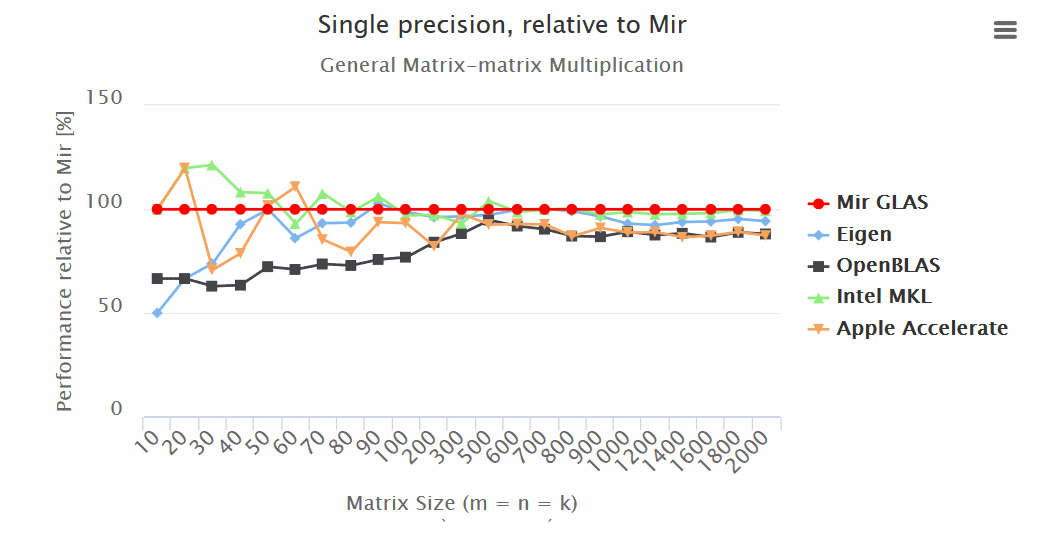

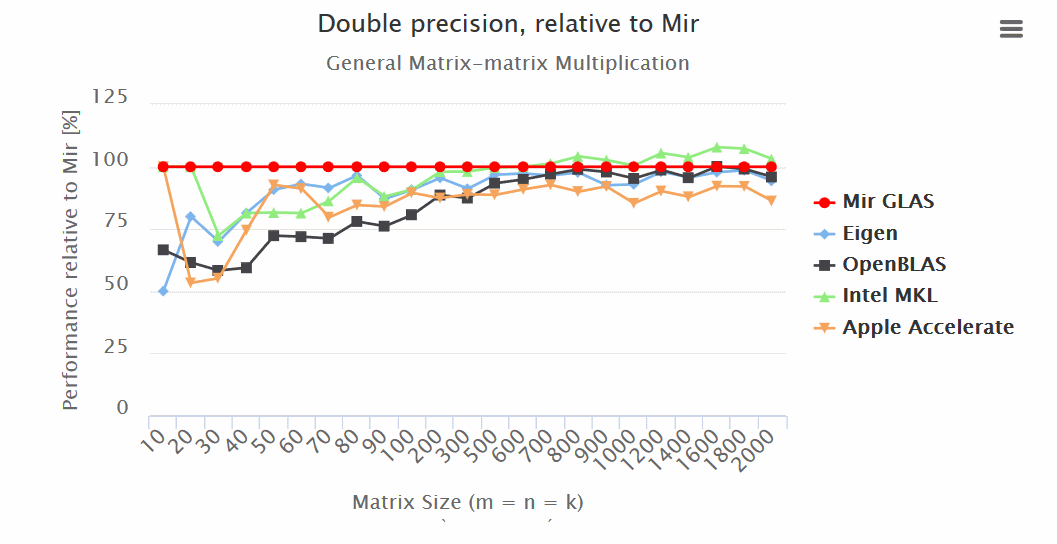



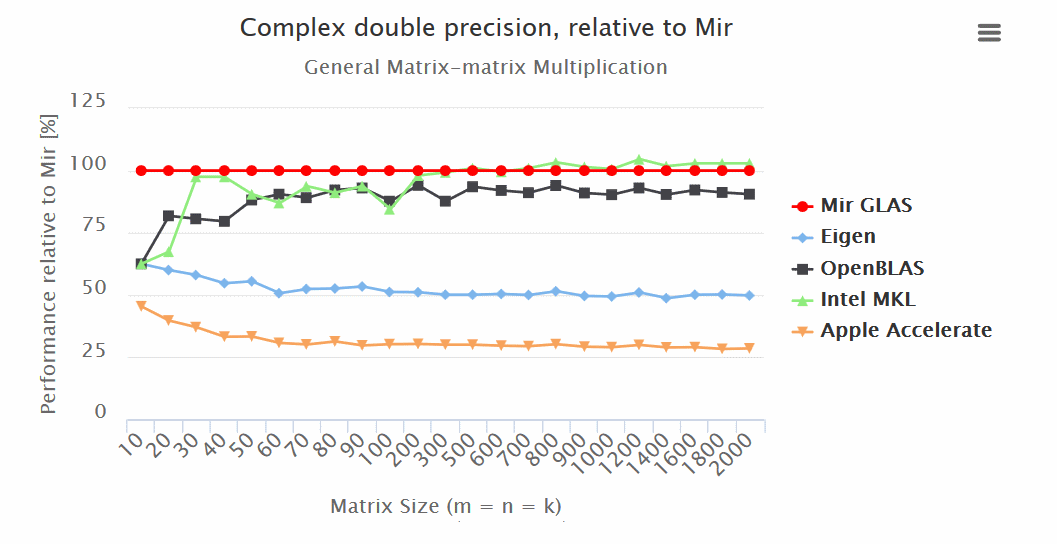
Итоги:
— Mir GLAS значительно опережает OpenBLAS и Apple Accelerate по всем показателям.
— Mir GLAS оказывается быстрее почти в два раза чем Eigen и Apple Accelerate при работе с матрицами.
— По скорости Mir GLAS оказывается сопоставим с проприетарным Intel MKL, который является самым быстрым в своем роде.
— Благодаря своему дизайну Mir GLAS легко может быть адаптирован для новых архитектур.
P.S. В настоящий момент на базе GLAS активно развивается система компьютерного зрения DCV.
P.P.S. Оригинальный автор присутствует в комментах под ником 9il
» Оригинальная статья расположена в блоге автора.
В настоящий момент OpenBLAS используется в матричных манипуляциях в таких языках как Julia и Python (NumPy). OpenBLAS крайне хорошо оптимизирована и значительная её часть вообще написана на ассемблере.
Однако так ли хорош для вычислений чистый C, как это принято считать?
Встречайте Mir GLAS! Нативная реализация библиотеки линейной алгебры на чисто D без единой вставки на ассемблере!
Для компиляции библиотеки Mir GLAS нам потребуется компилятор LDC (LLVM D Compiler). Компилятор DMD официально не поддерживается т.к. он не поддерживает инструкции AVX и AVX2.
Тестовая конфигурация будет состоять из:
| CPU | 2.2 GHz Core i7 (I7-4770HQ) |
| L3 Cache | 6 MB |
| RAM | 16 GB of 1600 MHz DDR3L SDRAM |
| Model Identifier | MacBookPro11,2 |
| OS | OS X 10.11.6 |
| Mir GLAS | 0.18.0, single thread |
| OpenBLAS | 0.2.18, single thread |
| Eigen | 3.3-rc1, single thread (sequential configurations) |
| Intel MKL | 2017.0.098, single thread (sequential configurations) |
| Apple Accelerate | OS X 10.11.6, single thread (sequential configurations) |
» Код самого теста можно получить тут.
» Mir GLAS базируется на библиотеке mir.ndslice
Mir GLAS может быть легко использован в любом языке поддерживающим C ABI. Делается это элементарно:
// Performs: c := alpha a x b + beta c // glas is a pointer to a GlasContext glas.gemm(alpha, a, b, beta, c);
Для сравнения в OpenBLAS потребуется написать следующий код:
void cblas_sgemm ( const CBLAS_LAYOUT layout, const CBLAS_TRANSPOSE TransA, const CBLAS_TRANSPOSE TransB, const int M, const int N, const int K, const float alpha, const float *A, const int lda, const float *B, const int ldb, const float beta, float *C, const int ldc)
При проведении теста установлено следующее значение переменных:
| openBLAS | OPENBLAS_NUM_THREADS=1 |
| Accelerate (Apple) | VECLIB_MAXIMUM_THREADS=1 |
| Intel MKL | MKL_NUM_THREADS=1 |
Eigen собран с флагами `EIGEN_TEST_AVX` и `EIGEN_TEST_FMA`:
mkdir build_dir cd build_dir cmake -DCMAKE_BUILD_TYPE=Release -DEIGEN_TEST_AVX=ON -DEIGEN_TEST_FMA=ON .. make OpenBLAS
Результаты (больше — лучше):
Итоги:
— Mir GLAS значительно опережает OpenBLAS и Apple Accelerate по всем показателям.
— Mir GLAS оказывается быстрее почти в два раза чем Eigen и Apple Accelerate при работе с матрицами.
— По скорости Mir GLAS оказывается сопоставим с проприетарным Intel MKL, который является самым быстрым в своем роде.
— Благодаря своему дизайну Mir GLAS легко может быть адаптирован для новых архитектур.
P.S. В настоящий момент на базе GLAS активно развивается система компьютерного зрения DCV.
P.P.S. Оригинальный автор присутствует в комментах под ником 9il
» Оригинальная статья расположена в блоге автора.

