Выбирая сервис для хранения моих данных, важной составляющей является то, как долго такой сервис будет жить. От него нужно, чтобы я смог хотя бы прочитать сохраненные данные даже если энтузиазм авторов проекта закончится вместе с деньгами для оплаты хостинга и базы данных. С таким подходом для своего проекта я искал сервисы баз данных, которые могли бы хранить пользовательские данные бесплатно. Многообещающим проектом был Parse.com, о котором я уже писал ранее в статье «Сайт без бекенда». Но в январе 2016 мы узнали, что Parse.com проживет только один год и будет закрыт. В связи с этим я решил перевести хранение данных пользователей в git-репозиторий, который опубликован на Github.
Схема работы сервиса
Пользователь <=> GitHub Pages <=> Отдельный API на платном VDS <=> git-репозиторий на SSD на том же VDS <=> репозиторий на GitHub
Существенным недостатком по вышеописанному критерию здесь является API на платном VDS, который однажды может стать недоступным навсегда. Но, благодаря всей цепочке, получить свои данные как в человеческом формате, так и в машиночитаемом можно будет на Github. Так как пользователь на Github Pages общается с API через javascript, то главная страница проекта будет по-прежнему доступна. В случае, если из звена нужно будет исключить Github по какой-либо причине, то можно перенести всю работу на другой хостинг репозиториев, например, Bitbucket.
Почему бы не использовать систему pull-request'ов вместо API? Я нашел 3 причины:
- Пользователи должны быть знакомы с git и с системой PR на Github.
- Нужно разрабатывать систему авторизации с проверкой, что пользователь в PR затронул только свои файлы.
- Всё равно Нужен отдельный сервер, который будет пересобирать markdown файлы. Не отказываться же от них.
В результате, я пришел к выводу, что решения с кодом на своём сервере не избежать. Общение такой серверной части с Github происходит только через git. Использование ssh-ключа для выталкивания на Github делает процесс простым.
Правомерность
Подумав об структуре таких данных, я изучил вопрос легитимности использования Github с такой целью. Рассмотрим подробнее пункты Terms of Service, которые напрямую касаются вопроса.
A. 2
You must be a human. Accounts registered by "bots" or other automated methods are not permitted.
Аккаунт для выталкивания репозитория на Github нужно создать вручную (при этом на действующую электронную почту).
A. 4
Your login may only be used by one person — i.e., a single login may not be shared by multiple people — except that a machine user's actions may be directed by multiple people. You may create separate logins for as many people as your plan allows.
A. 7
One person or legal entity may not maintain more than one free account, and one machine user account that is used exclusively for performing automated tasks.
Все действия по фиксации (commit) и выталкиванию (push) делаются от одного аккаунта. Но такие действия подходят под описание machine user, потому что они автоматизированы.
G. 12
If your bandwidth usage significantly exceeds the average bandwidth usage (as determined solely by GitHub) of other GitHub customers, we reserve the right to immediately disable your account or throttle your file hosting until you can reduce your bandwidth consumption.
В проекте используются текстовые файлы, а выталкивание происходит по расписанию в короткие промежутки времени. Практически, этот пункт не должен быть нарушен.
Прочие рекомендации
Github в некоторых материалах сообщает дополнительную информацию.
We recommend repositories be kept under 1GB each. This limit is easy to stay within if large files are kept out of the repository. If your repository exceeds 1GB, you might receive a polite email from GitHub Support requesting that you reduce the size of the repository to bring it back down.
In addition, we place a strict limit of files exceeding 100 MB in size.
Теоретически, эта часть может стать проблемой. За 2 года жизни сервиса учета прочитанных книг было сохранено около 8000 записей. При этом размер репозитория составляет около 7 МБ. Самый большой файл имеет размер около 500 КБ — это служебный файл с индексом записей. Учитывая, что в сервисе есть ограничения на длину передаваемых текстов, используя сервис по назначению, лимит будет превышен нескоро. В дальнейшем можно рассмотреть вариант шардирования.
Там же Github нам сообщает, что они не проектировались (как и сам git) как средство хранения резервных копий или средство хранения больших sql-файлов. Мы не будем использовать Github как средство хранения sql-файлов, у нас другая структура данных. А так как данные предполагаются быть читаемыми на самом Github не только машинами, но и людьми, то назвать такую структуру чистой резервной копией тоже нельзя.
Структура данных
Создать функциональную, но при этом не избыточную структуру данных, которую можно было бы хранить в git-репозитории, можно только в рамках конкретного проекта. Наверное, можно было бы описать какой-то универсальный подход к проектированию этого аспекта, но я опишу конечный вариант, оставив только самое необходимое.
Итак, для проекта Книгопись требуется хранить информацию о пользователе: id, псевдоним, дата последнего обновления и, главное, список прочитанных им книг. О прочитанной книге мы будем хранить: id, заголовок, автор, дата прочтения, примечания пользователя, дата последнего обновления. Задумка проекта в том, что пользователь указывает книгу свободным вводом, так, как ему это хочется. Это позволяет нам не использовать реестр всех существующих книг. Другими словами, каждая запись о книге имеет отношение только к пользователю, который её создал.
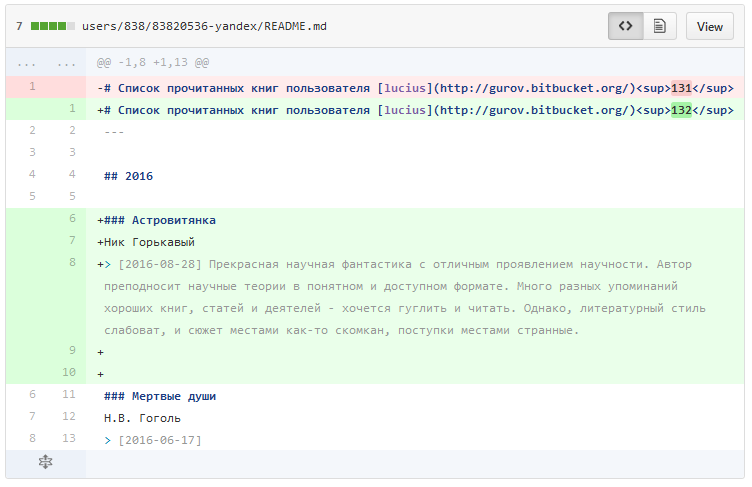
В качестве формата данных выбран json за свою неизбыточность и хорошую совместимость с идей git-хранилища. Если хранить каждое значение json в отдельной строчке, это позволит получить наглядный diff на Github.
Так как кроме пользователей и их книг нам пока ничего хранить не надо, мы создаем для каждого пользователя отдельную директорию с именем id пользователя. Внутри этой директории храним json-файл с базовой информацией о пользователе. Здесь же расположена директория books, и внутри неё хранятся отдельные json-файлы на каждую книгу с id книги в качестве имени файла.
Рассмотрим вспомогательные файлы. Несмотря на то, что каждая запись о прочитанной книги имеет отношение к конкретному пользователю, для API потребовалось быстрое получение книги по её id. Я пошел по пути создания вспомогательного файла — индекса книг. Это csv-файл, который содержит id и полный путь к записи о книге. Создания такого файла можно было бы избежать, если делать поиск книг в контексте конкретного пользователя (тогда потребовалось бы дополнительное время на поиск файла в директории пользователя), либо делать составной id, часть которого имел бы id пользователя (избыточность и неатомарность id).
Следующими вспомогательными файлами являются latest_books.json и latest_books_with_notes.json. Они хранят информацию о фиксированном количестве последних внесенных книгах, а также latest_users.json с фиксированным количеством последних зарегистрированных пользователей. Благодаря им, на сервисе можно показать последние добавленные книги с примечаниями и последних активных пользователей.
Так как мы используем Github, то некоторую информацию мы можем отобразить в самом репозитории, используя markdown. Для этого будем пересобирать при каждом внесении новой информации файлы README.md и отдельно latest_books_with_notes.md на основе вышеописанных json-файлов. А главное, мы можем пересобирать сами страницы пользователей со списком прочитанного ими.
Директории с пользователями мы сгруппировали по начальным символам id для избежания образования слишком большого количества объектов на одном уровне пути.
Аутентификация и авторизация
В отличии от Parse.com здесь нет возможности хранить пароли, но даже тогда я использовал uLogin для аутентификации, который объединяет десятки социальных сетей и сайтов, при этом не требует регистрации от пользователя. Работа с uLogin очень проста. Он передает токен доступа клиенту после успешного входа, этот токен нужно отправить на сервер, где сделать запрос к серверу uLogin для валидации токена и получения некоторой полезной информации, например, название сети-провайдера и id пользователя в ней. С помощью этой информации оказалось возможно привязать данные пользователя напрямую к его учетной записи в выбранной им социальной сети. Это означает, что в случае окончания работы uLogin, его можно будет заменить на аналогичный сервис (в том числе своим). Поэтому в качестве id пользователя я решил использовать комбинированный id вида id-provider, например, 83820536-yandex. Такой подход позволил избежать ограничения на хранение где-либо непубличных данных.
Планируя сервис я предусмотрел сценарий утраты пользователем доступа к социальной сети. Такой сценарий реализовался недавно в связи с блокировкой в РФ LinkedIn. Пользователь обратился с просьбой о помощи. В проекте появилась функция «скопировать записи из другой учетной записи». Так как все данные общедоступны, то нет никакого вреда от того, что хоть кто может скопировать себе список хоть кого. Разумно добавить некоторые ограничения, чтобы пользователь «не прострелил себе ногу». В итоге, пользователь воспользовался функцией копирования и получил доступ к своим записям, хотя и входит на сервис теперь через VK.
Теперь к вопросу авторизации пользователя при работе с API. На первых этапах разработки, я создавал случайный токен доступа, к которому привязывал пользовательский id после аутентификации (сама связь хранилась в кеше приложения), а токен возвращал клиенту. Предполагалось, что он должен будет включать его в каждый запрос к API. Но в дальнейшем я присмотрелся к привычному механизму сессий и кук (cookies). У cookies оказались неплохие преимущества. Во-первых, можно установить HttpOnly. Не сказать, что это преимущество исключило все XSS-атаки, но хотя бы на один сценарий стало меньше. Во-вторых, куки передаются автоматически, если клиент на js в браузере, а это как раз наш случай.
Много какой фреймворк для серверной части позволяет очень легко реализовать механизм «запомнить меня» с помощью долгоживущей куки. По ней он поднимает сессию пользователя. Дальнейшая процедура авторизации делается в рамках фреймворка. Нужно, конечно, определить сущности и механизмы сохранения данных в файловую систему, но это сильно зависит от структуры данных. Скажу лишь, что нужно предусмотреть подобие транзакций для git-фиксаций. Это позволит объединить изменение нескольких сущностей в один коммит.
Преимущества
Бесплатно
История всех изменений
Готовая система отката изменений
Возможность быстро получить полную копию всех данных
Можно получить фрагменты данных в обход API, используя raw-данные GitHub
- Предположительно, долговечность
Недостатки
Скорость чтения и записи. Хотя использование SSD на хостинге скрашивает ситуацию. Рекомендую ssd-хостинг DigitalOcean: реф. ссылка с бонусами.
Могут возникнуть сложности с масштабированием. Выталкивание и вытягивание не слишком быстрые операции, чтобы синхронизировать хранилище в реальном времени. Возможно, поможет шардинг по пользователям.
Вопрос поисковой оптимизации открыт. Проект на Github Pages + Angular, поисковые системы такое не видят. Возможно, markdown файлы попадут в индекс, либо будут проиндексированы страницы в социальных сетях, куда происходит экспорт записей.
Реализация поиска требует дополнительных усилий.
Поддержка локализации для markdown-страниц на Github отсутствует. Может помочь дублирование данных, но это не так красиво.
Нет привычных языков запроса. Получение и запись нужно реализовывать самостоятельно на довольно низком уровне.
Вывод
Проект с использованием Github в качестве хранилища данных удалось проверить временем. На дату публикации статьи он работает больше 3 месяцев. Возможно, всё не развалилось, потому что не было серьезных нагрузок или ушлых ребят. А возможно, идея жизнеспособна, хотя бы, для небольших проектов.
Если вы еще не знаете, где можно сохранить список прочитанных книг, но хотите составить по нему отчет за прошедший год, то добро пожаловать.
Исходные коды всех частей проекта:
- API для общения пользователей с хранилищем (копия с bitbucket, потому один коммит)
- Сайт-клиент
- Хранилище данных

