Думаю, что практически каждый реальный проект использует ту или иную форму реализации очереди поставщик-потребитель (producer-consumer queue). Идея проблемы довольно проста. Приложению нужно развязать производство некоторых данных от их обработки. Возьмем, к примеру, пул потоков в CLR: мы добавляем элемент на обработку путем вызова ThreadPool.QueueUserWorkItem, а пул потоков сам разбирается, какое число рабочих потоков наиболее оптимально и вызывает методы для обработки элементов с нужной степенью параллелизма.
Но использование стандартного пула потоков не всегда возможно и/или разумно. Несмотря на возможность указания минимального и максимального числа потоков, эта конфигурация глобальная и повлияет на приложение целиком, а не на нужные его части. Существует множество других способов решить задачу поставщика потребителя. Это может быть решение «в лоб», когда логика приложения смешивается с аспектами многопоточности, очередями и синхронизацией. Это может быть обертка над BlockingCollection с ручным управлением числа рабочих потоков или задач. Или же это может быть решение на основе полностью готового решения, такого как ActionBlock<T> из TPL DataFlow.
Сегодня мы рассмотрим внутреннее устройство класса ActionBlock, обсудим дизайн-решения, которые были приняты его авторами и узнаем, почему нам все это нужно знать, чтобы обойти некоторые проблемы при его использовании. Готовы? Ну тогда поехали!
На моем текущем проекте у нас есть ряд случаев, когда нам нужно решить проблему поставщика-потребителя. Одна из них выглядит так: у нас есть кастомный парсер и интерпретатор для языка, очень похожего на TypeScript. Не вдаваясь глубоко в детали, мы можем сказать, что нам нужно пропарсить набор файлов и получить, так называемое «транзитивное замыкание» всех зависимостей. После чего их н��жно преобразовать в представление, пригодное для исполнения и выполнить.
Логика парсинга выглядит примерно так:
Довольно просто, не так ли? Так и есть. Вот как будет выглядеть несколько упрощенная реализация на основе TPL Dataflow и класса ActionBlock<T>:
Давайте посмотрим, что тут происходит. Для простоты вся ��сновная логика находится в методе Main. Переменная numberOfProcessedFiles используется для проверки корректности логики и содержит общее число обработанных файлов. Основная работа делается в делегате processFile, который затем передается конструктору ActionBlock. Этот делегат играет одновременно роль «потребителя» и «поставщика»: он принимает путь к файлу через аргумент path, парсит файл, находит его зависимости и отправляет новые файлы в очередь путем вызова метода actionBlock.SendAsync. Затем идет проверка количества элементов в очереди на обработку, и если новых элементов нет, то вся операция завершается путем вызова actionBlock.Complete() (*). Затем, метод Main создает экземпляр ActionBlock, запускает обработку первого файла и дожидается окончания всего процесса.
Метод ParseFileAsync эмулирует процесс разбора файла и вычисляет зависимости с помощью следующей примитивной логики: файл ‘foo.ts’ зависит от ‘fo.ts’, который зависит от ‘f.ts’. Т.е. каждый файл зависит от файла с более коротким именем. Это малореальная логика, но она позволяет показать основную идею вычисления транзитивного замыкания файлов.
Класс ActionBlock управляет конкурентность (concurrency) за вас. Правда нужно учитывать, что по умолчанию «уровень параллелизма» (degree of parallelism) равен 1 и чтобы изменить это, нужно передать экземпляр класса ExecutionDataflowBlockOptions в конструкторе ActionBlock. Если свойство MaxDegreeOfParallelism будет больше 1, то ActionBlock будет вызывать делегат обратного вызова из разных потоков (на самом деле, из разных задач) для параллельной обработки элементов очереди.
Каждый, кто хотя бы раз пытался самостоятельно решить задачу поставщика-потребителя сталкивался с проблемой: что делать, когда поток входных данных превосходит возможности потребителей в обработке? Как «троттлить» (throttle) поток входных данных? Просто хранить все входные элементы в памяти? Генерировать исключение? Возвращать false в методе добавления элемента? Использовать циклический буфер и отбрасывать старые элементы? Или блокировать выполнение этого метода, пока в очереди не появится местечко?
Для решения этой задачи, авторы ActionBlock решили воспользоваться следующим общеприн��тым подходом:
В нашем предыдущем примере, мы не задавали размер очереди. А это значит, что если новые элементы будут добавляться быстрее, чем обрабатываться, то приложение рано или поздно упадет с OutOfMemoryException. Но давайте попробуем исправить эту ситуацию. И зададим очереди очень маленький размер, например, в 1 элемент.
Теперь, если мы запустим этот код, то получим … дедлок!
Давайте подумаем о проблеме потребителя-поставщика с точки зрения проектирования. Мы пишем свою собственную очередь, которая принимает метод обратного вызова для обработки элементов. Нам нужно решить, должна ли она поддерживать ограничение числа элементов или нет. Если нам нужна «конечная» (bounded) очередь, то мы наверняка придем к дизайну очень похожему на дизайн класса ActionBlock: мы добавим синхронный метод для добавления элементов, который вернет false, если очередь заполнена, и асинхронный метод, который вернет задачу. В случае полной очереди у клиента нашего класса будет возможность решить, что делать: обрабатывать «переполнение» самостоятельно путем вызова синхронной версии добавления элементов или «ожидать» (await) появления свободного места в очереди с помощью асинхронной версии.
Затем вам нужно будет решить, когда вызывать метод обратного вызова. В результате, вы можете прийти к следующей логике: если очередь не пуста, то берется первый элемент, вызывается метод обратного вызова, ожидается завершение обработки, после чего элемент из очереди удаляется. (Реальная реализация будет существенно сложнее, чем кажется, просто потому, что она должна учитывать всевозможные гонки). Очередь может решить удалять элемент до вызова метода обратного вызова, но, как мы вскоре увидим, это не повлияет на возможность получения дедлока.
Мы пришли к простому и элегантному дизайну, но он легко может привести к проблеме. Предположим, что очередь заполнена и сейчас идет вызов обратного вызова для обработки одного из элементов. Но что если, вместо того, чтобы быстро «вернуть» очереди управления, хендлер пытается добавить еще один элемент путем вызова await SendAsync:

Очередь заполнена и не может принять новые элементы, поскольку метод обратного вызова еще не завершен. Но этот метод тоже застрял на ожидании завершения await SendAsync и не может двигаться дальше, пока в очереди не освободится местечко. Классический дедлок!
Ок, мы получаем дедлок, поскольку ActionBlock удаляет элемент из очереди *после* завершения метода обратного вызова. Но давайте рассмотрим альтернативный сценарий: что будет, если ActionBlock будет удалять элемент *до* вызова метода обратного вызова? На самом деле, ничего не изменится. Дедлок все еще будет возможен.
Представим, что размер очереди равен одному, а степень параллелизма – двум.

Получается, что удаление элемента из очереди до обработки не поможет. Более того, это лишь усугубит проблему, поскольку вероятность дедлока существенно уменьшится (нужно, чтобы при степени параллелизма, равного N, все N методов обратного вызова попытались одновременно добавить новые элементы в очередь).
Другой недостаток менее очевиден. ActionBlock все же не является решением общего назначения. Этот класс реализует интерфейс ITargetSource и может использоваться для обработки элементов в сложных dataflow сценариях. Например, у нас может быть BufferBlock с несколькими «целевыми» блоками для параллельной обработки элементов. В текущей реализации баллансировка обработчиков реализуется тривиальным образом. Как только приемник (в нашем случае ActionBlock) заполнен, он перестает принимать новые элементы на вход. А это дает возможность другим блокам в цепочке обработать элемент вместо него.
Если элемент будет удаляться лишь после того, как он будет обработан, то ActionBlock станет более жадным и будет принимать больше элементов, чем может обработать в данный момент. В этом случае размер (bounded capacity) каждого блока станет равна ‘BoundedCapaciy’ + ‘MaxDegreeOfParallelism’.
Боюсь, что никак. Если одновременно нужно ограничивать число элементов в очереди и метод обратного вызова может добавлять новые элементы, то от ActionBlock придется отказаться. Альтернативой может быть решение на основе BlockingCollection и «ручного» управления числа рабочих потоков, например, с помощью таск-пула или Parallel.Invoke.
В отличие от примитивов из TPL, все блоки из TPL Dataflow, по умолчанию являются однопоточными. Т.е. ActionBlock, TransformerBlock и прочие, вызывают метод обратного вызова по одному за раз. Авторы TPL Dataflow посчитали, что простота важнее возможных выигрышей в производительности. Думать о датафлоу графах вообще довольно сложно, а параллельная обработка данных всеми блоками сделает этот процесс еще сложнее.
Для изменения степени параллелизма, блоку нужно передать ExecutionDataflowBlockOptions и установить свойству MaxDegreeOfParallelism значение большее 1. Кстати, если этому свойству установить значение -1, то все поступающие элементы будут обрабатываться новой задачей и параллелизм будет ограничен лишь возможностями используемого планировщика задач (объекта TaskScheduler), который также может быть передан через ExecutionDataflowBlockOptions.
Проектирование простых в использовании компонентов является сложной задачей. Проектировании простых в использовании компонентов, которые решают вопросы параллелизма – сложнее вдвойне. Чтобы использовать подобные компоненты правильно, вам нужно знать, как они реализованы и какие ограничения держали в голове их разработчики.
Класс ActionBlock<T> — это отличная штука, которая существенно упрощает реализацию паттерна поставщик-потребитель. Но даже в этом случае, вы должны знать о некоторых аспектах TPL Dataflow, как степень параллелизма и поведение блоков в случае переполнения.
— (*) Данный пример не является потокобезопасным и полноценная реализация не должна использовать actionBlock.InputCount. А вы видите проблему?
(**) Метод Post возвращает false в одном из двух случаев: очередь заполнена или уже завершена (вызван метод Complete). Этот аспект может затруднить использование этого метода, поскольку отличить эти два случая нельзя. Метод SendAsync, с другой стороны, ведет себя несколько иначе: метод возвращает объект Task<bool>, который будет в незавершенном состоянии пока очередь заполнена, а если же очередь уже завершена и не в состоянии принимать новые элементы, то task.Result будет равен false.
Но использование стандартного пула потоков не всегда возможно и/или разумно. Несмотря на возможность указания минимального и максимального числа потоков, эта конфигурация глобальная и повлияет на приложение целиком, а не на нужные его части. Существует множество других способов решить задачу поставщика потребителя. Это может быть решение «в лоб», когда логика приложения смешивается с аспектами многопоточности, очередями и синхронизацией. Это может быть обертка над BlockingCollection с ручным управлением числа рабочих потоков или задач. Или же это может быть решение на основе полностью готового решения, такого как ActionBlock<T> из TPL DataFlow.
Сегодня мы рассмотрим внутреннее устройство класса ActionBlock, обсудим дизайн-решения, которые были приняты его авторами и узнаем, почему нам все это нужно знать, чтобы обойти некоторые проблемы при его использовании. Готовы? Ну тогда поехали!
На моем текущем проекте у нас есть ряд случаев, когда нам нужно решить проблему поставщика-потребителя. Одна из них выглядит так: у нас есть кастомный парсер и интерпретатор для языка, очень похожего на TypeScript. Не вдаваясь глубоко в детали, мы можем сказать, что нам нужно пропарсить набор файлов и получить, так называемое «транзитивное замыкание» всех зависимостей. После чего их н��жно преобразовать в представление, пригодное для исполнения и выполнить.
Логика парсинга выглядит примерно так:
- Парсим файл.
- Анализируем его содержимое и ищем его зависимости (путем анализа всех ‘import * from’, ‘require’ и подобных конструкций).
- Вычисляем зависимости (т.е. находим набор файлов, которые требуются текущему файлу для нормальной работы).
- Добавляем полученные файлы-зависимости в список для парсинга.
Довольно просто, не так ли? Так и есть. Вот как будет выглядеть несколько упрощенная реализация на основе TPL Dataflow и класса ActionBlock<T>:
private static Task<ParsedFile> ParseFileAsync(string path) { Console.WriteLine($"Parsing '{path}'. {{0}}", $"Thread Id - {Thread.CurrentThread.ManagedThreadId}"); Thread.Sleep(10); return Task.FromResult( new ParsedFile() { FileName = path, Dependencies = GetFileDependencies(path), }); } static void Main(string[] args) { long numberOfProcessedFiles = 0; ActionBlock<string> actionBlock = null; Func<string, Task> processFile = async path => { Interlocked.Increment(ref numberOfProcessedFiles); ParsedFile parsedFile = await ParseFileAsync(path); foreach (var dependency in parsedFile.Dependencies) { Console.WriteLine($"Sending '{dependency}' to the queue... {{0}}", $"Thread Id - {Thread.CurrentThread.ManagedThreadId}"); await actionBlock.SendAsync(dependency); } if (actionBlock.InputCount == 0) { // This is a marker that this is a last file and there // is nothing to process actionBlock.Complete(); } }; actionBlock = new ActionBlock<string>(processFile); actionBlock.SendAsync("FooBar.ts").GetAwaiter().GetResult(); Console.WriteLine("Waiting for an action block to finish..."); actionBlock.Completion.GetAwaiter().GetResult(); Console.WriteLine($"Done. Processed {numberOfProcessedFiles}"); Console.ReadLine(); }
Давайте посмотрим, что тут происходит. Для простоты вся ��сновная логика находится в методе Main. Переменная numberOfProcessedFiles используется для проверки корректности логики и содержит общее число обработанных файлов. Основная работа делается в делегате processFile, который затем передается конструктору ActionBlock. Этот делегат играет одновременно роль «потребителя» и «поставщика»: он принимает путь к файлу через аргумент path, парсит файл, находит его зависимости и отправляет новые файлы в очередь путем вызова метода actionBlock.SendAsync. Затем идет проверка количества элементов в очереди на обработку, и если новых элементов нет, то вся операция завершается путем вызова actionBlock.Complete() (*). Затем, метод Main создает экземпляр ActionBlock, запускает обработку первого файла и дожидается окончания всего процесса.
Метод ParseFileAsync эмулирует процесс разбора файла и вычисляет зависимости с помощью следующей примитивной логики: файл ‘foo.ts’ зависит от ‘fo.ts’, который зависит от ‘f.ts’. Т.е. каждый файл зависит от файла с более коротким именем. Это малореальная логика, но она позволяет показать основную идею вычисления транзитивного замыкания файлов.
Класс ActionBlock управляет конкурентность (concurrency) за вас. Правда нужно учитывать, что по умолчанию «уровень параллелизма» (degree of parallelism) равен 1 и чтобы изменить это, нужно передать экземпляр класса ExecutionDataflowBlockOptions в конструкторе ActionBlock. Если свойство MaxDegreeOfParallelism будет больше 1, то ActionBlock будет вызывать делегат обратного вызова из разных потоков (на самом деле, из разных задач) для параллельной обработки элементов очереди.
Post vs. SendAsync: что и когда использовать
Каждый, кто хотя бы раз пытался самостоятельно решить задачу поставщика-потребителя сталкивался с проблемой: что делать, когда поток входных данных превосходит возможности потребителей в обработке? Как «троттлить» (throttle) поток входных данных? Просто хранить все входные элементы в памяти? Генерировать исключение? Возвращать false в методе добавления элемента? Использовать циклический буфер и отбрасывать старые элементы? Или блокировать выполнение этого метода, пока в очереди не появится местечко?
Для решения этой задачи, авторы ActionBlock решили воспользоваться следующим общеприн��тым подходом:
- Клиент может задать размер очереди при создании объекта ActionBlock.
- Если очередь заполнена, то метод Post возвращает false, а метод расширения SendAsync возвращает задачу, которая будет завершена при появлении в очереди свободного места.
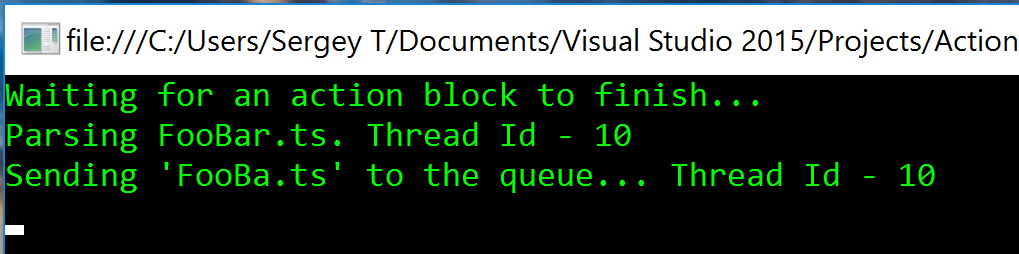
В нашем предыдущем примере, мы не задавали размер очереди. А это значит, что если новые элементы будут добавляться быстрее, чем обрабатываться, то приложение рано или поздно упадет с OutOfMemoryException. Но давайте попробуем исправить эту ситуацию. И зададим очереди очень маленький размер, например, в 1 элемент.
actionBlock = new ActionBlock<string>(processFile, new ExecutionDataflowBlockOptions() {BoundedCapacity = 1});
Теперь, если мы запустим этот код, то получим … дедлок!
Дедлок
Давайте подумаем о проблеме потребителя-поставщика с точки зрения проектирования. Мы пишем свою собственную очередь, которая принимает метод обратного вызова для обработки элементов. Нам нужно решить, должна ли она поддерживать ограничение числа элементов или нет. Если нам нужна «конечная» (bounded) очередь, то мы наверняка придем к дизайну очень похожему на дизайн класса ActionBlock: мы добавим синхронный метод для добавления элементов, который вернет false, если очередь заполнена, и асинхронный метод, который вернет задачу. В случае полной очереди у клиента нашего класса будет возможность решить, что делать: обрабатывать «переполнение» самостоятельно путем вызова синхронной версии добавления элементов или «ожидать» (await) появления свободного места в очереди с помощью асинхронной версии.
Затем вам нужно будет решить, когда вызывать метод обратного вызова. В результате, вы можете прийти к следующей логике: если очередь не пуста, то берется первый элемент, вызывается метод обратного вызова, ожидается завершение обработки, после чего элемент из очереди удаляется. (Реальная реализация будет существенно сложнее, чем кажется, просто потому, что она должна учитывать всевозможные гонки). Очередь может решить удалять элемент до вызова метода обратного вызова, но, как мы вскоре увидим, это не повлияет на возможность получения дедлока.
Мы пришли к простому и элегантному дизайну, но он легко может привести к проблеме. Предположим, что очередь заполнена и сейчас идет вызов обратного вызова для обработки одного из элементов. Но что если, вместо того, чтобы быстро «вернуть» очереди управления, хендлер пытается добавить еще один элемент путем вызова await SendAsync:
Очередь заполнена и не может принять новые элементы, поскольку метод обратного вызова еще не завершен. Но этот метод тоже застрял на ожидании завершения await SendAsync и не может двигаться дальше, пока в очереди не освободится местечко. Классический дедлок!
Ок, мы получаем дедлок, поскольку ActionBlock удаляет элемент из очереди *после* завершения метода обратного вызова. Но давайте рассмотрим альтернативный сценарий: что будет, если ActionBlock будет удалять элемент *до* вызова метода обратного вызова? На самом деле, ничего не изменится. Дедлок все еще будет возможен.
Представим, что размер очереди равен одному, а степень параллелизма – двум.
- Поток T1 добавляет элемент в очередь. ActionBlock достает элемент из очереди (уменьшая число элементов в очереди до 0) и вызывает метод обратного вызова.
- Поток T2 добавляет элемент в очередь. ActionBlock достает элемент из очереди (уменьшая число элементов в очереди до 0) и вызывает метод обратного вызова.
- Поток T1 добавляет элемент в очереди. ActionBlock не может вызвать обработчик нового элемента, поскольку уровень параллелизма – 2, и у нас уже есть два обработчика. Очередь заполнена.
- Первый обработчик во время обработки пробует добавить новый элемент в очереди, но залипает на вызове ‘await SendAsync’, поскольку очередь заполнена.
- Второй обработчик во время обработки пробует добавить новый элемент в очереди, но залипает на вызове ‘await SendAsync’, поскольку очередь заполнена.
Получается, что удаление элемента из очереди до обработки не поможет. Более того, это лишь усугубит проблему, поскольку вероятность дедлока существенно уменьшится (нужно, чтобы при степени параллелизма, равного N, все N методов обратного вызова попытались одновременно добавить новые элементы в очередь).
Другой недостаток менее очевиден. ActionBlock все же не является решением общего назначения. Этот класс реализует интерфейс ITargetSource и может использоваться для обработки элементов в сложных dataflow сценариях. Например, у нас может быть BufferBlock с несколькими «целевыми» блоками для параллельной обработки элементов. В текущей реализации баллансировка обработчиков реализуется тривиальным образом. Как только приемник (в нашем случае ActionBlock) заполнен, он перестает принимать новые элементы на вход. А это дает возможность другим блокам в цепочке обработать элемент вместо него.
Если элемент будет удаляться лишь после того, как он будет обработан, то ActionBlock станет более жадным и будет принимать больше элементов, чем может обработать в данный момент. В этом случае размер (bounded capacity) каждого блока станет равна ‘BoundedCapaciy’ + ‘MaxDegreeOfParallelism’.
Как решить проблему с дедлоком?
Боюсь, что никак. Если одновременно нужно ограничивать число элементов в очереди и метод обратного вызова может добавлять новые элементы, то от ActionBlock придется отказаться. Альтернативой может быть решение на основе BlockingCollection и «ручного» управления числа рабочих потоков, например, с помощью таск-пула или Parallel.Invoke.
Степень параллелизма (Degree of Parallelism)
В отличие от примитивов из TPL, все блоки из TPL Dataflow, по умолчанию являются однопоточными. Т.е. ActionBlock, TransformerBlock и прочие, вызывают метод обратного вызова по одному за раз. Авторы TPL Dataflow посчитали, что простота важнее возможных выигрышей в производительности. Думать о датафлоу графах вообще довольно сложно, а параллельная обработка данных всеми блоками сделает этот процесс еще сложнее.
Для изменения степени параллелизма, блоку нужно передать ExecutionDataflowBlockOptions и установить свойству MaxDegreeOfParallelism значение большее 1. Кстати, если этому свойству установить значение -1, то все поступающие элементы будут обрабатываться новой задачей и параллелизм будет ограничен лишь возможностями используемого планировщика задач (объекта TaskScheduler), который также может быть передан через ExecutionDataflowBlockOptions.
Заключение
Проектирование простых в использовании компонентов является сложной задачей. Проектировании простых в использовании компонентов, которые решают вопросы параллелизма – сложнее вдвойне. Чтобы использовать подобные компоненты правильно, вам нужно знать, как они реализованы и какие ограничения держали в голове их разработчики.
Класс ActionBlock<T> — это отличная штука, которая существенно упрощает реализацию паттерна поставщик-потребитель. Но даже в этом случае, вы должны знать о некоторых аспектах TPL Dataflow, как степень параллелизма и поведение блоков в случае переполнения.
— (*) Данный пример не является потокобезопасным и полноценная реализация не должна использовать actionBlock.InputCount. А вы видите проблему?
(**) Метод Post возвращает false в одном из двух случаев: очередь заполнена или уже завершена (вызван метод Complete). Этот аспект может затруднить использование этого метода, поскольку отличить эти два случая нельзя. Метод SendAsync, с другой стороны, ведет себя несколько иначе: метод возвращает объект Task<bool>, который будет в незавершенном состоянии пока очередь заполнена, а если же очередь уже завершена и не в состоянии принимать новые элементы, то task.Result будет равен false.

