В данной статье я попытаюсь подробно рассказать об использовании протокола OSSI для взаимодействия с АТС Avaya Communication Manager. В открытом доступе очень мало информации по данной теме, а уж в русском сегменте все ограничивается поверхностной статьей на Хабре за 2013 год. Необходимо данную несправедливость устранять.
Протокол OSSI (Operations Support Systems Interface) используется в продуктах Avaya для взаимодействия различных дополнительных модулей с основным модулем АТС, в данном случае Communication Manager. Получить к нему доступ можно простым выбором корректного типа терминала во время подключения к серверу.
Основного внимания заслуживают два типа терминала: ossi и ossimt. Первый тип используется для непосредственной работы с CM, получением информации и внесением изменений в настройку АТС. Второй тип используется для сопоставления идентификатора поля, использующегося в первом типе, с фактическим его назначением. Это нужно, т.к. в разных версиях CM используются разные идентификаторы и заранее узнать что к чему нельзя.
Стандартный вывод терминала ossi:
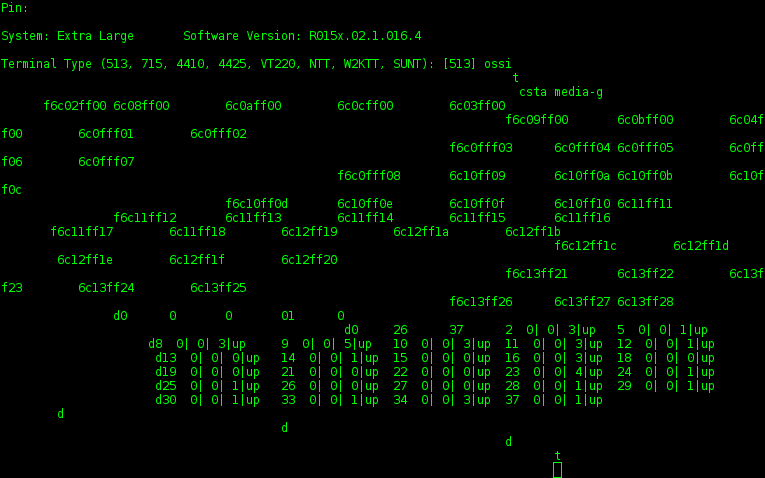
Для данного типа характерно то, что набранные в терминале символы не отображаются и не удаляются.
Стандартный вывод терминала ossimt:
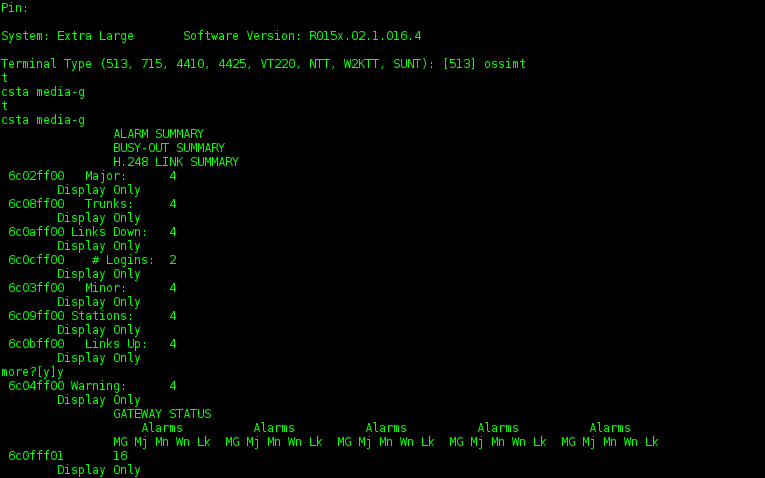
Взаимодействие по протоколу производится путем передачи строк определенного типа. Тип строки определяется указателем, подставляемым в начало строки. Список этих указателей:
Ввод и вывод информации в терминале производится в следующем формате:
Т.е. каждая строка завершается символом перевода строки (нажатие Enter) а внутри строк типа field и data элементы разделяются символом табуляции (нажатие Tab).
Рассмотрим подробнее первые 3 типа строк:
В данной строке должна содержаться команда для выполнения. В общем случае, команды идентичны командам, используемым при стандартном администрировании в терминале. Вызвать весь список доступных команд можно набрав:
В данной строке перечисляются идентификаторы полей для введеной команды. Разделение между полями осуществляется символом табуляции. Данные идентификаторы записаны в HEX-формате и чтобы понять какое поле чему соответствует, необходимо обращаться к ossimt. Строк данного типа может быть несколько, в зависимости от количества информации передаваемой командой.
В данной строке перечисляются данные, относящиеся соответствующим полям, указанным в строке предыдущего типа. Данные также разделяются табуляцией. Следует учитывать, что количество строк данного типа должно быть кратно количеству строк типа field.
Строки типа field и data в основном используются при выводе информации после ввода команды, но кроме этого их можно использовать при внесении изменений в систему (напр. change station XXXX), либо выводе команды, принимающей дополнительные параметры (напр. display alarms). Достаточно только после строки command добавить эти строки, указав в них соответствующие поля и данные, которые требуется изменить.
К примеру, набрав в терминале:
Мы изменим для внутреннего номера 1000 отображаемое имя на I.C. Wiener.
Строго говоря, терминалов типа ossi несколько. Мне известно по крайней мере 3: ossi, ossi3, ossis. Особой разницы между ними нет. Из видимых особенностей только то, что ossis при выводе результата команды не возвращает строку с самой командой.
Все описанное, конечно, хорошо. Но как можно использовать данный протокол во благо? Ну, например, можно сделать некое подобие мониторинга. Рассмотрим для примера мониторинг медиа-шлюзов.
В этом нам поможет обычная команда status media-gateways и Python.
Шаг 1: подключиться и получить информацию.
Теперь у нас есть информация в виде строки, с которой мы можем творить всякое.
Шаг 2: парсим полученную информацию.
Имеющуюся информацию нам нужно разделить в зависимости от обозначенных выше типов строк. Т.к. количество строк одного типа может быть несколько, нам необходимо учесть их последовательность.
В результате этих действий получим такую переменную parse:
Шаг 3: сопоставляем поля и данные.
Наконец, нам нужно сопоставить идентификатор поля конкретному значению из данных.
В итоге получаем словарь, в котором в качестве ключа стоит идентификатор поля, а в качестве значения — данные, соответствующие этому полю.
Финал: PROFIT
Итак, у нас есть словарь, в котором есть вся информация по статусу медиа-шлюзов. Нам остается только выяснить какой идентификатор что обозначает. Делается это, как мы помним, с помощью ossimt. К примеру, полям major alarms, minor alarms, warnings соответствуют идентификаторы 6c02ff00, 6c03ff00, 6c04ff00. Ищем их в нашем словаре и понимаем что у нас нет ни одной серьезной ошибки и «всего» 40 предупреждений. Жить можно.
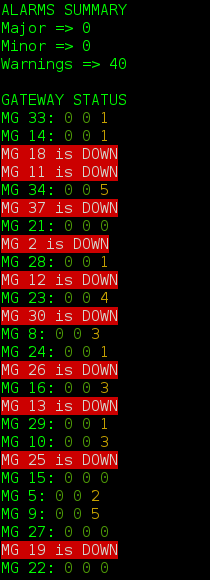
Немного поработав с полученными данными, можно получить вполне годный мониторинг медиа-шлюзов доступный прямо из терминала. К примеру, мы можем получить такую картину:

А если не повезет, то и такую:
Для удобства работы, разработал небольшой класс для работы с данным протоколом, посмотреть можно тут.
Теория
Протокол OSSI (Operations Support Systems Interface) используется в продуктах Avaya для взаимодействия различных дополнительных модулей с основным модулем АТС, в данном случае Communication Manager. Получить к нему доступ можно простым выбором корректного типа терминала во время подключения к серверу.
Основного внимания заслуживают два типа терминала: ossi и ossimt. Первый тип используется для непосредственной работы с CM, получением информации и внесением изменений в настройку АТС. Второй тип используется для сопоставления идентификатора поля, использующегося в первом типе, с фактическим его назначением. Это нужно, т.к. в разных версиях CM используются разные идентификаторы и заранее узнать что к чему нельзя.
Стандартный вывод терминала ossi:
Для данного типа характерно то, что набранные в терминале символы не отображаются и не удаляются.
Стандартный вывод терминала ossimt:
Взаимодействие по протоколу производится путем передачи строк определенного типа. Тип строки определяется указателем, подставляемым в начало строки. Список этих указателей:
- c (command) — указатель строки содержащей исполняемую команду;
- f (field) — указатель строки, содержащей идентификаторы полей;
- d (data) — указатель строки, содержащей данные, в соответствии с полем;
- e (error) — указатель строки, содержащей сообщение об ошибке;
- t (terminate) — указатель окончания ввода/вывода информации
Ввод и вывод информации в терминале производится в следующем формате:
с<команда>[RETURN]
f<поле 1>[TAB]<поле 2>[TAB]<поле 3>[RETURN]
d<данные 1>[TAB]<данные 2>[TAB]<данные 3>[RETURN]
t[RETURN]
Т.е. каждая строка завершается символом перевода строки (нажатие Enter) а внутри строк типа field и data элементы разделяются символом табуляции (нажатие Tab).
Рассмотрим подробнее первые 3 типа строк:
c (command)
В данной строке должна содержаться команда для выполнения. В общем случае, команды идентичны командам, используемым при стандартном администрировании в терминале. Вызвать весь список доступных команд можно набрав:
chelp
t
f (field)
В данной строке перечисляются идентификаторы полей для введеной команды. Разделение между полями осуществляется символом табуляции. Данные идентификаторы записаны в HEX-формате и чтобы понять какое поле чему соответствует, необходимо обращаться к ossimt. Строк данного типа может быть несколько, в зависимости от количества информации передаваемой командой.
d (data)
В данной строке перечисляются данные, относящиеся соответствующим полям, указанным в строке предыдущего типа. Данные также разделяются табуляцией. Следует учитывать, что количество строк данного типа должно быть кратно количеству строк типа field.
Строки типа field и data в основном используются при выводе информации после ввода команды, но кроме этого их можно использовать при внесении изменений в систему (напр. change station XXXX), либо выводе команды, принимающей дополнительные параметры (напр. display alarms). Достаточно только после строки command добавить эти строки, указав в них соответствующие поля и данные, которые требуется изменить.
К примеру, набрав в терминале:
сcha st 1000
f8003ff00
dI.C. Wiener
t
Мы изменим для внутреннего номера 1000 отображаемое имя на I.C. Wiener.
Строго говоря, терминалов типа ossi несколько. Мне известно по крайней мере 3: ossi, ossi3, ossis. Особой разницы между ними нет. Из видимых особенностей только то, что ossis при выводе результата команды не возвращает строку с самой командой.
Практика
Все описанное, конечно, хорошо. Но как можно использовать данный протокол во благо? Ну, например, можно сделать некое подобие мониторинга. Рассмотрим для примера мониторинг медиа-шлюзов.
В этом нам поможет обычная команда status media-gateways и Python.
Шаг 1: подключиться и получить информацию.
import telnetlib tn = telnetlib.Telnet('127.0.0.1', '5023') # Подключаемся по телнету на стандартный порт 5023 tn.read_until('login'.encode()) # Ждем прихода строки с вводом логина tn.write('username\n'.encode()) tn.read_until('Password'.encode()) # Ждем прихода строки с вводом пароля tn.write('password\n'.encode()) tn.read_until('Pin'.encode()) # Ждем прихода строки с вводом пин-кода tn.write('pin\n'.encode()) tn.read_until('Terminal'.encode()) # Ждем прихода строки с вводом типа терминала tn.write('ossi\n'.encode()) tn.read_until('t\n'.encode()) # Ждем прихода строки с идентификатором окончания ввода\вывода # Как только идентификатор пришел, можно слать команду tn.write('csta media-g\n'.encode()) # Строка типа command tn.write('t\n'.encode()) # Строка типа terminate output = tn.read_until('t\n'.encode()) # Записываем всю информацию, пока не придет terminate. output = output.decode('utf-8') # Конвертируем пришедшие байты в строку
Теперь у нас есть информация в виде строки, с которой мы можем творить всякое.
output
'\ncsta media-g\nf6c02ff00\t6c08ff00\t6c0aff00\t6c0cff00\t6c03ff00\nf6c09ff00\t6c0bff00\t6c04ff00\t6c0fff01\t6c0fff02\nf6c0fff03\t6c0fff04\t6c0fff05\t6c0fff06\t6c0fff07\nf6c0fff08\t6c10ff09\t6c10ff0a\t6c10ff0b\t6c10ff0c\nf6c10ff0d\t6c10ff0e\t6c10ff0f\t6c10ff10\t6c11ff11\nf6c11ff12\t6c11ff13\t6c11ff14\t6c11ff15\t6c11ff16\nf6c11ff17\t6c11ff18\t6c12ff19\t6c12ff1a\t6c12ff1b\nf6c12ff1c\t6c12ff1d\t6c12ff1e\t6c12ff1f\t6c12ff20\nf6c13ff21\t6c13ff22\t6c13ff23\t6c13ff24\t6c13ff25\nf6c13ff26\t6c13ff27\t6c13ff28\nd0\t0\t0\t01\t0\nd0\t26\t40\t2 0| 0| 3|up\t5 0| 0| 2|up\nd8 0| 0| 3|up\t9 0| 0| 5|up\t10 0| 0| 3|up\t11 0| 0| 3|up\t12 0| 0| 1|up\nd13 0| 0| 0|up\t14 0| 0| 1|up\t15 0| 0| 0|up\t16 0| 0| 3|up\t180| 0| 0|up\nd19 0| 0| 0|up\t21 0| 0| 0|up\t22 0| 0| 0|up\t23 0| 0| 4|up\t24 0| 0| 1|up\nd25 0| 0| 1|up\t26 0| 0| 0|up\t27 0| 0| 0|up\t28 0| 0| 1|up\t29 0| 0| 1|up\nd30 0| 0| 1|up\t33 0| 0| 1|up\t34 0| 0| 5|up\t37 0| 0| 1|up\t\nd\t\t\t\t\nd\t\t\t\t\nd\t\t\nt\n'
Шаг 2: парсим полученную информацию.
Имеющуюся информацию нам нужно разделить в зависимости от обозначенных выше типов строк. Т.к. количество строк одного типа может быть несколько, нам необходимо учесть их последовательность.
fields = {} # словарь для хранения полей data = {} # словарь для хранения данных lines = output.split('\n') # разделяем построчно for line in lines: # проходимся по строкам и заносим в соответствующий словарь if line.startswith('d'): # строка типа data data.update({ len(data): line[1:] # Ключом словаря делаем номер строки }) elif line.startswith('f'): # строка типа field fields.update({ len(fields): line[1:] }) elif line.startswith('t'): # строка terminate break else: # остальные типа строк нам не интересны pass parse = { 'fields': fields, 'data': data, }
В результате этих действий получим такую переменную parse:
parse
{ 'fields': { 0: '6c02ff00\t6c08ff00\t6c0aff00\t6c0cff00\t6c03ff00', 1: '6c09ff00\t6c0bff00\t6c04ff00\t6c0fff01\t6c0fff02', 2: '6c0fff03\t6c0fff04\t6c0fff05\t6c0fff06\t6c0fff07', 3: '6c0fff08\t6c10ff09\t6c10ff0a\t6c10ff0b\t6c10ff0c', 4: '6c10ff0d\t6c10ff0e\t6c10ff0f\t6c10ff10\t6c11ff11', 5: '6c11ff12\t6c11ff13\t6c11ff14\t6c11ff15\t6c11ff16', 6: '6c11ff17\t6c11ff18\t6c12ff19\t6c12ff1a\t6c12ff1b', 7: '6c12ff1c\t6c12ff1d\t6c12ff1e\t6c12ff1f\t6c12ff20', 8: '6c13ff21\t6c13ff22\t6c13ff23\t6c13ff24\t6c13ff25', 9: '6c13ff26\t6c13ff27\t6c13ff28' }, 'data': { 0: '0\t0\t0\t01\t0', 1: '0\t26\t40\t2 0| 0| 3|up\t5 0| 0| 2|up', 2: '8 0| 0| 3|up\t9 0|0| 5|up\t10 0| 0| 3|up\t11 0| 0| 3|up\t12 0| 0| 1|up', 3: '13 0| 0| 0|up\t14 0| 0| 1|up\t15 0| 0| 0|up\t16 0| 0| 3|up\t18 0| 0| 0|up', 4: '19 0| 0| 0|up\t21 0| 0| 0|up\t22 0| 0| 0|up\t23 0| 0| 4|up\t24 0| 0| 1|up', 5: '25 0| 0| 1|up\t26 0| 0| 0|up\t27 0| 0| 0|up\t28 0| 0| 1|up\t29 0| 0|1|up', 6: '30 0| 0| 1|up\t33 0| 0| 1|up\t34 0| 0| 5|up\t37 0| 0| 1|up\t', 7: '\t\t\t\t', 8: '\t\t\t\t', 9: '\t\t' } }
Шаг 3: сопоставляем поля и данные.
Наконец, нам нужно сопоставить идентификатор поля конкретному значению из данных.
result = {} # Сюда будем сохранять результат for i in range(len(parse['fields'])): # считаем количество строк и проходимся по ним fids = parse['fields'][i].split('\t') # разделяем строку на элементы data = parse['data'][i].split('\t') for i in range(len(fids)): result.update({ fids[i]: data[i] # сопоставляем поле соответствующим данным })
В итоге получаем словарь, в котором в качестве ключа стоит идентификатор поля, а в качестве значения — данные, соответствующие этому полю.
result
{ '6c10ff0e': '21 0| 0| 0|up', '6c11ff16': '29 0| 0| 1|up', '6c13ff22': '', '6c0fff01': '2 0| 0| 3|up', '6c10ff0c': '18 0| 0| 0|up', '6c11ff15': '28 0| 0| 1|up', '6c10ff0d': '19 0| 0| 0|up', '6c12ff20': '', '6c10ff09': '14 0| 0| 1|up', '6c0fff03': '8 0| 0| 3|up', '6c10ff0f': '22 0| 0| 0|up', '6c11ff14': '27 0| 0| 0|up', '6c04ff00': '40', '6c13ff26': '', '6c10ff0b': '16 0| 0| 3|up', '6c10ff0a': '15 0| 0| 0|up', '6c0fff08': '13 0| 0| 0|up', '6c13ff25': '', '6c0cff00': '01', '6c12ff1f': '', '6c11ff18': '33 0| 0| 1|up', '6c13ff27': '', '6c11ff12': '25 0| 0| 1|up', '6c0fff06': '11 0| 0| 3|up', '6c0bff00': '26', '6c03ff00': '0', '6c11ff11': '24 0| 0| 1|up', '6c0aff00': '0', '6c10ff10': '23 0| 0| 4|up', '6c13ff28': '', '6c0fff07': '12 0| 0| 1|up', '6c12ff1b': '', '6c02ff00': '0', '6c0fff05': '10 0| 0| 3|up', '6c13ff23': '', '6c12ff1e': '', '6c08ff00': '0', '6c12ff1d': '', '6c12ff1a': '37 0| 0| 1|up', '6c11ff13': '26 0| 0| 0|up', '6c12ff1c': '', '6c13ff24': '', '6c13ff21': '', '6c0fff02': '5 0| 0| 2|up', '6c09ff00': '0', '6c12ff19': '34 0| 0| 5|up', '6c0fff04': '9 0| 0| 5|up', '6c11ff17': '30 0| 0| 1|up' }
Финал: PROFIT
Итак, у нас есть словарь, в котором есть вся информация по статусу медиа-шлюзов. Нам остается только выяснить какой идентификатор что обозначает. Делается это, как мы помним, с помощью ossimt. К примеру, полям major alarms, minor alarms, warnings соответствуют идентификаторы 6c02ff00, 6c03ff00, 6c04ff00. Ищем их в нашем словаре и понимаем что у нас нет ни одной серьезной ошибки и «всего» 40 предупреждений. Жить можно.
Немного поработав с полученными данными, можно получить вполне годный мониторинг медиа-шлюзов доступный прямо из терминала. К примеру, мы можем получить такую картину:
А если не повезет, то и такую:
Для удобства работы, разработал небольшой класс для работы с данным протоколом, посмотреть можно тут.

