Задача, которая перед нами стоит — скачивание музыкальных произведений с сайта предоставляющего такую возможность. Использовать будем язык-программирования Python.
Для осуществления этого нам будут необходимы знания о парсинге сайта и работе с медиа файлами.
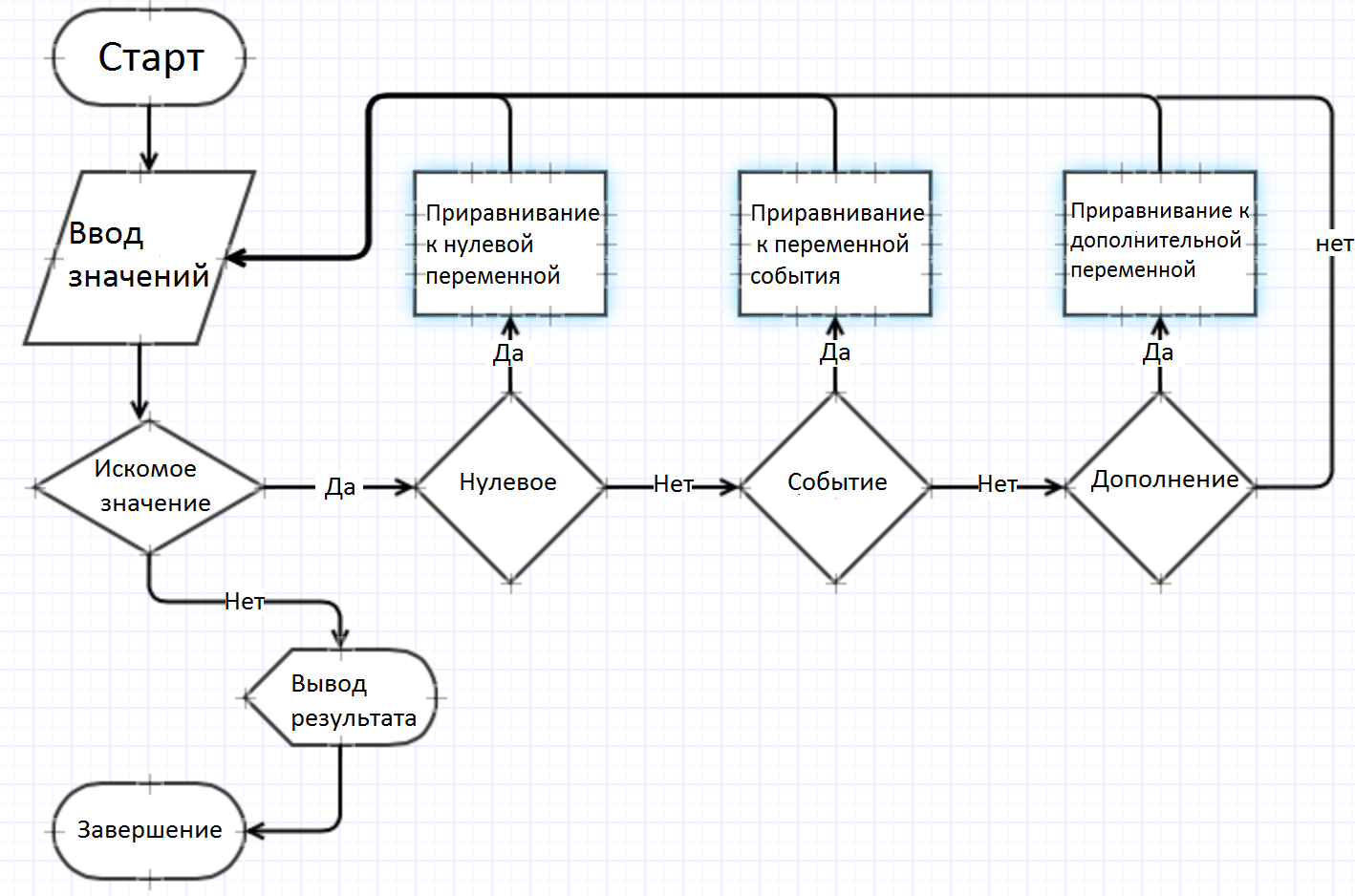
На рисунке выше изображен общий алгоритм парсинга сатов. Парсинг будем осуществлять с помощью модулей BeautifulSoup и request, а для работы с текстом нам будет достаточно модуля re.
Импорт
import requests #осуществляет работу с HTTP-запросами import urllib.request #библиотека HTTP from bs4 import BeautifulSoup #осуществляет синтаксический разбор документов HTML import re #осуществляет работу с регулярными выражениями
Объявление переменных и основная процедура
Нам будет необходимо всего два массива и одна переменная для хранения информации:
page_count = [] #массив для хранения страниц сайта, содержащих музыку perehod = '' #сайт перенаправляет на новую страницу для скачивания, здесь мы будем хранить эту ссылку download = [] #массив для поочередного хранения готовых ссылок для скачивания и имени файла
Пишем процедуру, где первым делом считаем все страницы на сайте, содержащие нужные нам песни.
if __name__ == '__main__': #условие для запуска процедуры u = str(input('Впишите группу для скачивания:\n')) #input - ввод данных с клавиатуры в программу. Эта переменная будет содержать название группы исполнителей, которую мы скачивем base_url = 'http://go.mail.ru/zaycev?sbmt=1486991736446&q='+u #переменная содержит http сайта, который мы парсим count=0 #объявляем переменную и приравниваем ее к нулю для дальнейшего создания счетчика page_count = [base_url] #в массив добавляем ссылку первой страницы, остальные будем помещать в цикле print('Поиск станиц. Подождите...') #print - осуществляем вывод указанного текста while True: #запускаем цикл try: #try обработчик исключительных ситуаций. То есть, программа будет выполнять цикл и когда встретит ошибку, которую мы укажем в условии except, начнет выполнять условие в нем page_count = page_count+[get_page_count(get_html(page_count[count]),page_count)] #к массиву прибавляем переменную, получаемую в функции get_page_count, куда мы также передаем переменную page_count для дальнейшего заполнения. Внутри этой переменной выполняется функция get_html (для получения http) от page_count[count], где count изначально равен нулю. Проще говоря, программа будет брать первый элемент в массиве - первый раз, и на единицу больше - каждый последующий проход цикла count = count + 1 #счетчик, позволяющий нам перебирать элементы в массиве except TypeError: #когда закончатся страницы на сайте, возникнет ошибка TypeError. Воспользуемся ею break #оператор break прекращает выполнение цикла и переводит выполнение программы на строку следующую после цикла print("Всего страниц найдено - ",len(page_count)) #в желании вывести количество найденных страниц нам поможет оператор len, который считает количество элементов в массиве
Получение HTTP-страниц
Для жизнедеятельности ранее написанного, необходимо написать две функции, первая — будет получать http и передавать этот параметр во вторую, которая в свою очередь будет получать данные с этой ссылки по средству парсинга.
def get_html(url): #объявление функции и передача в нее переменной url, которая является page_count[count] response = urllib.request.urlopen(url) #это надстройка над «низкоуровневой» библиотекой httplib, то есть, функция обрабатывает переменную для дальнейшего взаимодействия с самим железом return response.read() #возвращаем полученную переменную с заданным параметром read для корректного отображения
Следующая функция будет представлять сам парсинг. Главное, что нам необходимо для получения информации о построении сайта — это просмотреть его html верстку. Для этого заходим на сайт, нажимаем Shift+Ctrl+C и получаем исходный код, где отображены все имена виджетов.
def get_page_count(html,page_count): #в функцию мы передаем две переменные page_count (о ней мы говорили ранее) и html эта переменная нам также встречалась, просто в более сложном виде: get_html(page_count[count]) soup = BeautifulSoup(html, "html.parser") #объявляем новую переменную с полным html-кодом страницы href = soup.find('a', text = 'Вперед') #теперь из страницы находим нужный нам виджет - это кнопка с текстом "Вперед". "а" - это блочный элемент, которому принадлежит данная кнопка. Убедиться в этом можно описанным выше способом(Shift+Ctrl+C). base_url = 'http://go.mail.ru' #как видим, это лишь часть урла сайта. Берем лишь часть для дальнейшего соединения с частью, содержащей порядковый номер страницы сайта page_count = base_url + href['href'] #теперь крепим недостающую часть. Так как нам нужен лишь адрес из переменной href, а не весь html-код, принадлежащий кнопке, то с помощью функции ['href'] мы получим ссылку следующей страницы (также можно получить и иные части html-кода). return page_count #возвращаем значение переменной в процедуру
Важно! Все данные, получаемые с использованием BeautifulSoup, имеют не строковой тип данных, а отдельный «красивый суп» тип данных.
Очередная задача — получение нового адреса для скачивания при нажатии «Скачать» на каждой из страниц. Заметим, что не станем использовать массив, так как в этом случае нам придется заполнять его полностью и лишь затем начинать скачивание, что сильно замедлит работоспособность программы. Будем брать каждый раз новую ссылку и работать непосредственно с ней. Для этого пишем вторую функцию и добавляем в процедуру:
print('Скачивание') #выводим надпись 'Скачивание' пока идет скачивание музыки try: #запускаем обработчик исключительных ситуаций for i in page_count: #перебираем каждый элемент в массиве perehod = parsing1(get_html(i),perehod) #приравниваем переменную к функции, получающей url кнопки для скачивания. В эту функцию передаем две переменные - саму приравниваемую переменную и каждый раз меняющийся url except TypeError: #ошибка, которая нас потревожит TypeError (функция применяется к объекту несовместимого типа) print('Скачивание окончено') #выводим надпись 'Скачивание окончено' по окончанию будущего скачивания
В третьей функции встретимся с использованием re.findall(Шаблон, строка)- осуществляет поиск по заданному шаблону в строковой переменной.
def parsing1(html,perehod): #объявляем функцию soup = BeautifulSoup(html, "html.parser") #получаем полный html-код страницы perehod = [] #необходимо каждый раз обнулять массив, так как данные с предыдущих страниц нам не нужны for row in soup.find_all('a'): #создаем цикл, перебирая каждую найденную кнопку отдельно (на сайте, как мы можем убедится, их примерно 20) для занесения ее в массив if re.findall(r'Скачать', str(row)): #вот нам и пригодился импорт re, мы будем проверять в полученном html-коде, есть ли данные, связанные с кнопкой, так как сейчас переменная row, из-за особенности сайта (блок "a" имеет и иные классы, кроме самих кнопок), содержит много лишнего perehod=perehod+[row['href']] #теперь просто прибавляем к массиву проверенную переменную, предварительно получив из нее лишь свойство тега return perehod #возвращаем переменную
Теперь процедура берет каждый раз новую ссылку с каждой страницы и нам необходимо находить адрес новой страницы, где находится новая кнопка с текстовым полем «Скачать», с конечным адресом для скачивания. В главную процедуру пишем:
for y in perehod: #цикл с перебором значений в массиве со ссылками на новую страницу download = parsing2(get_html(y),download #download - массив для хранения двух параметров - название песни и ссылка на ее скачивание
Получение HTTP для прямого скачивания
В последней функции мы найдем ссылки для прямого скачивания. Здесь мы будем использовать две новые процедуры:
- re.sub(Шаблон, Новым фрагмент, Строка для замены) ищет все совпадения с шаблоном и заменяет их указанным значением. В качестве первого параметра можно указать ссылку на функцию.
- text — получает текст из html-кода (только из результата поиска BeautifulSoup, строковой тип данных не подойдет).
def parsing2(html,download): #объявляем функцию soup = BeautifulSoup(html, "html.parser") #объявляем новую переменную с полным html страницы table = soup.find('a', {'id':'audiotrack-download-link'}) #в html страницы ищем блок "a" с его "id". В нем и будут храниться данные - название и ссылка на прямое скачивание href='' #переменная хранения адреса песни name='' #переменная хранения названия песни if table != None: #условие: если данные найдены не были, то выполнить условие else row = soup.find('h1', {'class':"block__header block__header_audiotrack"}) #для записи имени находим блок "h1" с его классом и передаем данные в последующую name = re.sub(r'\n\t\t\t\t\t\t','',row.text) #в названии нам будут мешать лишние символы - заменим их на пустую строку. Строковым значением выступит текст от html-кода переменной row href=table.get('href') #в этот раз я использовал .get('href') вместо ['href'] - они идентичны download=[href]+[name] #массив, который мы передавали в функцию, теперь заполняем двумя переменными return download #возвращаем массив else: #условие ответвления не станет вносить изменения в массив download return download #возвращаем пустой массив
Запись файла
Нам остается скачать и записать файл.
- Процедура get позволяет отправлять HTTP-запрос, который позже проверим процедурой req.status_code: это список кодов состояния HTTP (список можно найти в Интеренете, статус <200> означает удачный вход).
- Процедура open открывает и закрывает файл для записи в двоичном формате, wb — создает файл с именем, если такового не существует.
if download != []: #условие, проверяющее, не равен ли массив пустому множеству req = requests.get(download[0],stream = True) #переменную приравниваем отправленному запросу от нашей ссылки для скачивания и задаем обязательный параметр stream равного True if req.status_code == requests.codes.ok: #условие проверяет статус http и если он удачен, то продолжить with open(download[1]+'.mp3', 'wb') as a: #открываем файл с присвоением имени a.write(req.content) #запись в файл осуществляется с помощью метода write
Используя всего два модуля BeautifulSoup и request можно достигать решений практически любых поставленных задач, связанных с парсингом сайта. С помощью полученных знаний можно адаптировать программу для скачивания иных данных даже с других сайтов. Желаю удачи в вашей работе!

