
Хабр Курсы для всех
РЕКЛАМА
Практикум, Хекслет, SkyPro, авторские курсы — собрали всех и попросили скидки. Осталось выбрать!
3) Названия сервисов имеют в своем составе более одного слова, то человек может просто не помнить, в каком именно порядке они идут.
Пожалуйста :)
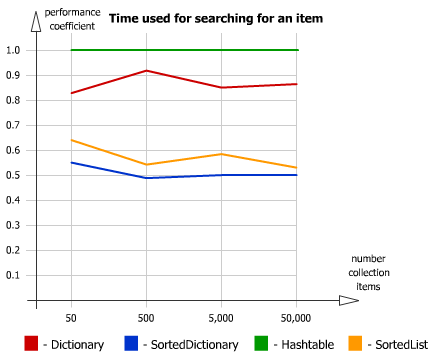
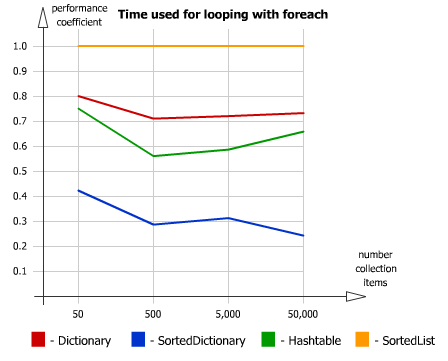
Производительность в консоле при 1000 наименований была в пределах 1 секунды, что меня вполне устроило, а на большее энтузиазма не хватило.
3 часть начинается со слов:
Со словами, как и поисковой единицей, вроде разобрались, теперь переходим к фразам.
Не пробовал. Вечером ради интереса посмотрю. Но тут на первый план выходит адекватность данных.
Алгоритм предназначен для поиска по названиям, а не по текстам.
То такие поисковые запросы можно отсекать до попытки поиска на них.
Тут я еще не поднял вопрос о том как отсекать результаты при выводы на странице "со всеми совпадениями". И вот на эту тему можно похолеварить.:)
А для русского я составлю сам по наитию:
«ыий», «эе», «ая», «оёе», «ую», «шщ», «оа», «йо»
Группа "йо" взялась с транскрипций расскоязычных звуков. Буква ё разлогается на звук "йо". Но если подумать, то Вы правы. Перехода "й" в "о" я не смог придумаль или быстро нагуглить.
Одна буквы может входить в несколько груп например sxz и csz.
Просто так проще их обдумывать и править. И поэтому мы и преобразуем эти фонетические группы в новый справочник который и используем потом в коде
indexSearcher.Search(query, 1000)
потому что у люсьена максимальное расстояние левенштейна - 2, и всё, поэтому я попробовал но использовать не буду
Нечеткий поиск по названиям