В жизни любого DevOps-инженера возникает необходимость создать playground для команды разработки. Как всегда он должен быть умным, шустрым и потреблять минимальное количество ресурсов. В этой статье я хочу рассказать о том, как решал проблему создания такого зверя для микросервисного приложения на kubernetes.

Немного о том, что представляет из себя система для которой необходимо было создать playground:
Требования, которые мы смогли сформулировать при активном общении с тимлидом:
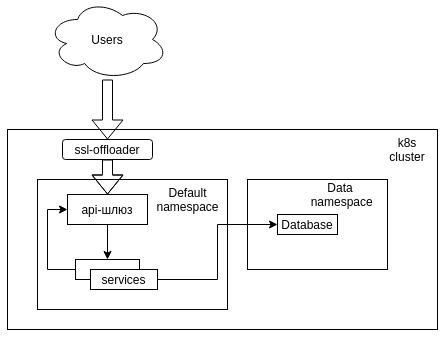
С самого начала было ясно, что наиболее логичным для создания параллельных пространств в k8s логичнее всего использовать родной инструмент виртуальных кластеров, или в терминологии k8s — namespaces. Задачу, так же, упрощает тот факт, что все взаимодействия внутри кластера производятся по коротким именам предоставляемым kube-dns, что означало, что запуск структуры можно произвести в отдельном namespace без потери связности.
У данного решения есть только одна проблема — необходимость разворачивать в namespace все имеющиеся сервисы, что долго, неудобно и потребляет большое количество ресурсов.
При создании любого сервиса k8s создаёт DNS-запись вида <service-name>.<namespace-name>.svc.cluster.local. Данный механизм позволяет общение через короткие имена внутри одного namespace благодаря изменениям вносимым в resolv.conf каждого запускаемого контейнера.
В обычном состоянии он выглядит вот так:
Т.е к сервису в том же namespace можно обратится по имени <service-name>, в соседних namespace по имени <service-name>.<namespace-name>
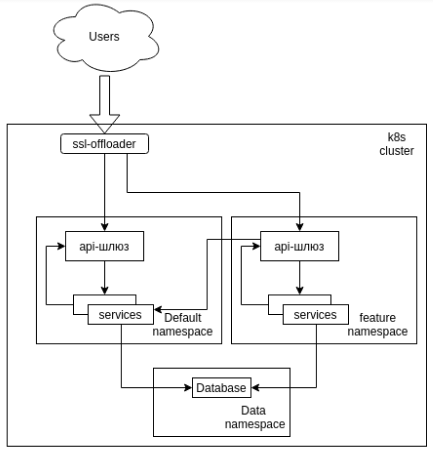
В этот момент в голову приходит простая мысль "База общая, маршрутизацией запросов к сервисам занимается api-шлюз, почему бы не заставить его ходить сначала к сервису в своём namespace, а в случае его отсутствия в default?"
Да, подобное решение можно было организовать настройками namespace (мы же помним, что это nginx), но подобное решение вызовет разницу в настройках на pg и на прочих кластерах, что неудобно и может вызвать ряд проблем.
Так что, был выбран метод замены строки
На
Такой подход обеспечит автоматический переход в namespace default при отсутствии необходимого сервиса в своём namespace.
Подобного результата можно добиться в кластере следующим образом. Kubelet добавляет параметры search в контейнер из resolve.conf хост-машины, так что достаточно просто дописать в /etc/resolv.conf каждой ноды строку:
Если же вы не желаете, чтобы ноды ресолвили адреса сервисов, то можно использовать параметр --resolv-conf при запуске kubelet, что позволит указать любой другой файл вместо /etc/resolv.conf. Например файл /etc/k8s/resolv.conf с той же строкой.
Дальнейшее решение достаточно просто, нужно, только, принять следующие соглашения:
Конфиг nginx для перенаправления запросов к api-gw в соответствующих namespace
Для автоматизации процесса развёртывания используется плагин Jenkins Pipeline Multibranch Plugin.
В настройках проекта указываем собирать только ветки соответствующие шаблону play/* И добавляем Jenkinsfile в корень всех проектов, с которыми будет работать сборщик.
Для обработки используется groovy-скрипт, целиком приводить его не буду, только пара примеров. Остальной деплой принципиально ничем не отличается от обычного.
Получение имени ветки:
Минимальная конфигурация namespace требует развёрнутого api-шлюза, поэтому добавляем вызов проекта создающего namespace и разворачивающего в него api-шлюз:
Серебряной пули не существует, но мне так и не удалось найти не только best practices, но и описаний того, как организованы песочницы у других, поэтому решил поделиться методом, который использовал при создании песочницы на базе k8s. Возможно это не идеальный способ, так что с радостью приму замечания или рассказы о том, как данная проблема решена у вас.
Входящие условия и требования
Немного о том, что представляет из себя система для которой необходимо было создать playground:
- Kubernetes, bare-metal кластер;
- Простой api-шлюз на базе nginx;
- MongoDB в качестве БД;
- Jenkins в качестве CI-сервера;
- Git на Bitbucket;
- Два десятка микросервисов, которые могут общаться между собой (через api-шлюз), с базой и с пользователем.
Требования, которые мы смогли сформулировать при активном общении с тимлидом:
- Минимизация потребления ресурсов;
- Минимизация изменений в коде сервисов для работы на playground;
- Возможность параллельной разработки нескольких сервисов;
- Возможность разработки нескольких сервисов в одном пространстве;
- Возможность демонстрации изменений заказчикам до деплоя на staging;
- Все разрабатываемые сервисы могут работать с одной БД;
- Минимизация усилий разработчика для разворачивания тестируемого кода.
Размышления на тему
С самого начала было ясно, что наиболее логичным для создания параллельных пространств в k8s логичнее всего использовать родной инструмент виртуальных кластеров, или в терминологии k8s — namespaces. Задачу, так же, упрощает тот факт, что все взаимодействия внутри кластера производятся по коротким именам предоставляемым kube-dns, что означало, что запуск структуры можно произвести в отдельном namespace без потери связности.
У данного решения есть только одна проблема — необходимость разворачивать в namespace все имеющиеся сервисы, что долго, неудобно и потребляет большое количество ресурсов.
Namespace и DNS
При создании любого сервиса k8s создаёт DNS-запись вида <service-name>.<namespace-name>.svc.cluster.local. Данный механизм позволяет общение через короткие имена внутри одного namespace благодаря изменениям вносимым в resolv.conf каждого запускаемого контейнера.
В обычном состоянии он выглядит вот так:
search <namespace-name>.svc.cluster.local svc.cluster.local cluster.local
nameserver 192.168.0.2
options ndots:5Т.е к сервису в том же namespace можно обратится по имени <service-name>, в соседних namespace по имени <service-name>.<namespace-name>
Обходим систему
В этот момент в голову приходит простая мысль "База общая, маршрутизацией запросов к сервисам занимается api-шлюз, почему бы не заставить его ходить сначала к сервису в своём namespace, а в случае его отсутствия в default?"
Да, подобное решение можно было организовать настройками namespace (мы же помним, что это nginx), но подобное решение вызовет разницу в настройках на pg и на прочих кластерах, что неудобно и может вызвать ряд проблем.
Так что, был выбран метод замены строки
search <namespace-name>.svc.cluster.local svc.cluster.local cluster.local На
search <namespace-name>.svc.cluster.local svc.cluster.local cluster.local default.svc.cluster.localТакой подход обеспечит автоматический переход в namespace default при отсутствии необходимого сервиса в своём namespace.
Подобного результата можно добиться в кластере следующим образом. Kubelet добавляет параметры search в контейнер из resolve.conf хост-машины, так что достаточно просто дописать в /etc/resolv.conf каждой ноды строку:
search default.svc.cluster.localЕсли же вы не желаете, чтобы ноды ресолвили адреса сервисов, то можно использовать параметр --resolv-conf при запуске kubelet, что позволит указать любой другой файл вместо /etc/resolv.conf. Например файл /etc/k8s/resolv.conf с той же строкой.
Дело техники
Дальнейшее решение достаточно просто, нужно, только, принять следующие соглашения:
- Новые фичи разрабатываются в отдельных ветках вида play/<feature-name>
- Для работы с несколькими сервисами в рамках одной фичи названия веток должны совпадать в репозиториях всех задействованных сервисов.
- Всю работу по деплою выполняет Jenkins автоматически
- Для тестов фича-ветки доступны по адресу <feature-name>.cluster.local
Настройки ssl-offloader
Конфиг nginx для перенаправления запросов к api-gw в соответствующих namespace
server_name ~^(?<namespace>.+)\.cluster\.local; location / { resolver 192.168.0.2; proxy_pass http://api-gw.$namespace.svc.cluster.local; }
Jenkins
Для автоматизации процесса развёртывания используется плагин Jenkins Pipeline Multibranch Plugin.
В настройках проекта указываем собирать только ветки соответствующие шаблону play/* И добавляем Jenkinsfile в корень всех проектов, с которыми будет работать сборщик.
Для обработки используется groovy-скрипт, целиком приводить его не буду, только пара примеров. Остальной деплой принципиально ничем не отличается от обычного.
Получение имени ветки:
def BranchName() { def Name = "${env.BRANCH_NAME}" =~ "play[/]?(.*)" Name ? Name[0][1] : null }
Минимальная конфигурация namespace требует развёрнутого api-шлюза, поэтому добавляем вызов проекта создающего namespace и разворачивающего в него api-шлюз:
def K8S_NAMESPACE = BranchName() build job: 'Create NS', parameters: [[$class: 'StringParameterValue', name: 'K8S_NAMESPACE', value: "${K8S_NAMESPACE}"]] build job: 'Create api-gw', parameters: [[$class: 'StringParameterValue', name: 'K8S_NAMESPACE', value: "${K8S_NAMESPACE}"]]
Заключение
Серебряной пули не существует, но мне так и не удалось найти не только best practices, но и описаний того, как организованы песочницы у других, поэтому решил поделиться методом, который использовал при создании песочницы на базе k8s. Возможно это не идеальный способ, так что с радостью приму замечания или рассказы о том, как данная проблема решена у вас.

