Мы планируем опубликовать серию статей, посвященных технологиям распознавания объектов. В качестве вишенки на торте, мы рассмотрим живой кейс, для которого использовался мультиплатформенный движок для AR, но об этом позже.
В этой статье мы поговорим об основах, познакомимся со всеми действующими лицами процесса, немного повеселимся, вспомним любимые мемы и между делом сформируем необходимую картину знаний.
Итак:
+ декомпозиция кейса, чтобы показать как всё это связано.
Computer vision, как научная дисциплина появилась довольно давно — в 1950-х годах. Тогда ни о каком OpenCV и речи не шло, официальный релиз которого произошел лишь в 2000-м году.
В 1950-х были разработаны двумерные алгоритмы для распознавания статистических характеристик, а также использовались простейшие алгоритмы.

Затем, в 1980-х на основе теории Дж. Гибсона разработали математические модели для вычисления оптического потока по пиксельной основе.
Так, шаг за шагом, люди находили возможность всё лучше распознавать объекты. В определенный момент научились распознавать буквы на картинках, а затем обучили этой операции и компьютер.
В двух словах, OpenCV — это низкоуровневая библиотека, которая умеет распознавать цвета, формы и фигуры при помощимагии крови алгоритмов.

Библиотека адаптирована под разные платформы, посему является универсальной и применяется везде: от мобильных устройств до роботов на «Ардуино». OpenCV стара, как записки Заратустры, но тем не менее продолжает развиваться и вдохновлять жизнь в новые проекты. Чтобы не углубляться, советую обратиться вот сюда.
Люди обучили компьютеры распознавать объекты, а это Machine Learning. Затем оно плавно перетекло в Deep learning — грамотный ребрендинг машинного обучения, примерно как «нейронная сеть с несколькими слоями соответствия». Одним из гигантов deep learning в современном мире является Google.
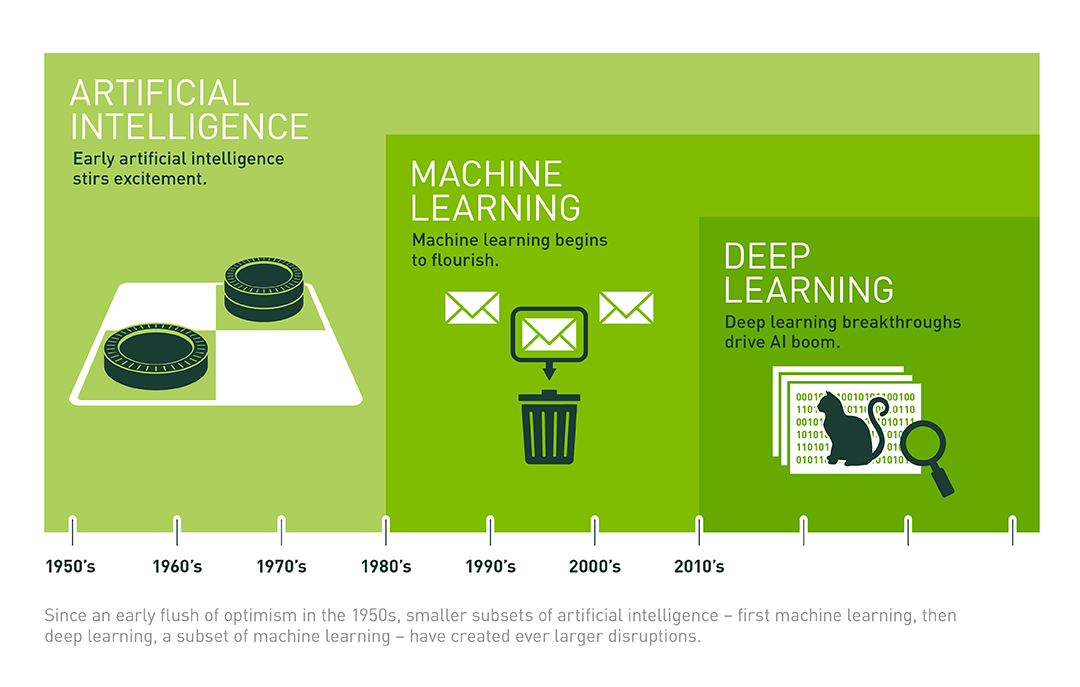
Как мы видим на картинке, всё началось с искусственного интеллекта, дальше перешло в машинное обучение и завершилось deep learning.
Нейронные сети — следующая веха развития машинного обучения, выход на новый уровень. Несмотря на то, что мой сосед по комнате с ником «40YearOldVirgin» прекрасно понимает всю математическую подноготную, мы оставим вещи в лучших традициях подходов к разработке.
А именно: keep it simple, stupid.

Взгляните на картинку, на ней описан состав нейронной сети и устройство работы.
На входе имеется пример, справедливость которого оценивается сетью и основывается на базе имеющегося опыта и накопленных данных.
Основной принцип предсказания: чем больше выборка, тем точнее данные — здесь обретает новый смысл… Чем дольше обучение, тем точнее предсказание. Любителям хардкора рекомендую почитать блог.

На картинке изображена последовательность действий, расположенных на разных слоях нейронной сети.
А в том, что с появлением на сцене Deep Learning всё смешалось в огромную кучу и границы размылись настолько, что никто не понимает как это работает.

Поэтому резюмируем:
Конечно, в данном случае можно обучать и без сторонней ML (machine learning), но это сложнее. Мы, а вернее наш ios разработчик, использовал каскады HAAR. Отличный пример того как это работает.
Нам надо при помощи хитрых алгоритмов распознать дорожный знак «ограничение скорости».
Пошаговое руководство для лентяев. Не будем вдаваться в детали реализации, проведём простую декомпозицию задачи, чтобы увидеть всё в перспективе.
Распознание объекта:
Понимание объекта:
Разберём вот такие случаи.
В обоих ситуациях для распознавания мы обращаемся к нейронной сети, которая на основе имеющегося опыта может предоставить результат. Например, «нейронка» с дорожными ограничителями видела различные варианты указателей: как с ограничением скорости, так и неподходящие для нашего кейса (без цифры или вовсе знак «кирпич»).
Чтобы не слать часто запросы в сеть, мы предположим, что если в 5 кадрах есть прямоугольник, который не сильно сместился от предыдущего кадра, то это есть один и тот же объект.
Это всё прекрасно, когда дело касается простого распознавания под одну платформу. Но мысли заказчика неисповедимы.
В следующем выпуске мы погрузимся в увлекательный мир 3D.

written by Виталий Зарубин, старший инженер-программист Reksoft
В этой статье мы поговорим об основах, познакомимся со всеми действующими лицами процесса, немного повеселимся, вспомним любимые мемы и между делом сформируем необходимую картину знаний.
Итак:
- Библиотека OpenCV.
- Принципы распознавания.
- История развития Computer vision.
+ декомпозиция кейса, чтобы показать как всё это связано.
Один немаловажный факт
Computer vision, как научная дисциплина появилась довольно давно — в 1950-х годах. Тогда ни о каком OpenCV и речи не шло, официальный релиз которого произошел лишь в 2000-м году.
В 1950-х были разработаны двумерные алгоритмы для распознавания статистических характеристик, а также использовались простейшие алгоритмы.
Затем, в 1980-х на основе теории Дж. Гибсона разработали математические модели для вычисления оптического потока по пиксельной основе.
Так, шаг за шагом, люди находили возможность всё лучше распознавать объекты. В определенный момент научились распознавать буквы на картинках, а затем обучили этой операции и компьютер.
Получается, всё началось давным–давно, в одной далекой–предалекой галактике…с OpenCV
В двух словах, OpenCV — это низкоуровневая библиотека, которая умеет распознавать цвета, формы и фигуры при помощи
Библиотека адаптирована под разные платформы, посему является универсальной и применяется везде: от мобильных устройств до роботов на «Ардуино». OpenCV стара, как записки Заратустры, но тем не менее продолжает развиваться и вдохновлять жизнь в новые проекты. Чтобы не углубляться, советую обратиться вот сюда.
Люди обучили компьютеры распознавать объекты, а это Machine Learning. Затем оно плавно перетекло в Deep learning — грамотный ребрендинг машинного обучения, примерно как «нейронная сеть с несколькими слоями соответствия». Одним из гигантов deep learning в современном мире является Google.
Как мы видим на картинке, всё началось с искусственного интеллекта, дальше перешло в машинное обучение и завершилось deep learning.
Пара слов о нейронных сетях
Нейронные сети — следующая веха развития машинного обучения, выход на новый уровень. Несмотря на то, что мой сосед по комнате с ником «40YearOldVirgin» прекрасно понимает всю математическую подноготную, мы оставим вещи в лучших традициях подходов к разработке.
А именно: keep it simple, stupid.
Взгляните на картинку, на ней описан состав нейронной сети и устройство работы.
На входе имеется пример, справедливость которого оценивается сетью и основывается на базе имеющегося опыта и накопленных данных.
Основной принцип предсказания: чем больше выборка, тем точнее данные — здесь обретает новый смысл… Чем дольше обучение, тем точнее предсказание. Любителям хардкора рекомендую почитать блог.
На картинке изображена последовательность действий, расположенных на разных слоях нейронной сети.
Итак, в чем же соль? — спросит читатель
А в том, что с появлением на сцене Deep Learning всё смешалось в огромную кучу и границы размылись настолько, что никто не понимает как это работает.
Поэтому резюмируем:
- OpenCV распознаёт объекты.
- Эти объекты скармливают в нейронку.
- Она анализирует слои на соответствие и отдает на выходе результат.
- Сама нейронная сеть обучается за счет полученного опыта.
Конечно, в данном случае можно обучать и без сторонней ML (machine learning), но это сложнее. Мы, а вернее наш ios разработчик, использовал каскады HAAR. Отличный пример того как это работает.
Давайте разберём-с кейс
Нам надо при помощи хитрых алгоритмов распознать дорожный знак «ограничение скорости».
Пошаговое руководство для лентяев. Не будем вдаваться в детали реализации, проведём простую декомпозицию задачи, чтобы увидеть всё в перспективе.
Распознание объекта:
- Создадим объект, который будет взаимодействовать с OpenCV, а если конкретнее, то он будет преобразовывать CVPixelBufferRef в cv::Mat и работать с ним, пусть его имя будет CV Manager;
- Используя библиотеку GPUImage пишем собственный фильтр, который с заданными промежутками (чтобы не нагружать полностью процессор) вытаскивает фреймы CVPixelBufferRef из видеопотока и отдает нашему CV Manager’у.
- Чтобы распознать в кадре какие-либо объекты мы будем использовать HAARcascades.
- На выходе мы получаем массив прямоугольников.
Понимание объекта:
Разберём вот такие случаи.
- Для распознавания дорожного знака «ограничение скорости» можно обучить нашу систему самостоятельно или найти уже обученную для распознавания систему;
- Для распознавания, например лица, используется сервис вроде FindFace. Мы можем отдать прямоугольник с предыдущего шага в API и получить ID лица;
В обоих ситуациях для распознавания мы обращаемся к нейронной сети, которая на основе имеющегося опыта может предоставить результат. Например, «нейронка» с дорожными ограничителями видела различные варианты указателей: как с ограничением скорости, так и неподходящие для нашего кейса (без цифры или вовсе знак «кирпич»).
Чтобы не слать часто запросы в сеть, мы предположим, что если в 5 кадрах есть прямоугольник, который не сильно сместился от предыдущего кадра, то это есть один и тот же объект.
Минусы подхода:
- Маленькая точность.
- Использование сети для распознавания.
- Проблемы при поворотах экрана (HAAR не может распознавать под углом).
- Как видите, всё довольно примитивно, по сути для каждого элемента мы берём всё готовое, вжух–вжух и в продакшн.
Это всё прекрасно, когда дело касается простого распознавания под одну платформу. Но мысли заказчика неисповедимы.
В следующем выпуске мы погрузимся в увлекательный мир 3D.
written by Виталий Зарубин, старший инженер-программист Reksoft

