
Хабр Курсы для всех
РЕКЛАМА
Практикум, Хекслет, SkyPro, авторские курсы — собрали всех и попросили скидки. Осталось выбрать!
Действительно, эти архитектуры во многом схожи, хотя разница в деталях.
Например здесь неплохой разбор Clean Architecture и представление ее в слоистой схеме.
Мне лично, не нравится этот способ представления. Как подметил автор:
Однако, можно заметить, что UI и Data Access компоненты расположены в одном слое
Кампоненты расположенные в одном слое должны иметь полный доступ друг к другу.
То есть UI имеет полное право обращаться к Data Access, что не правильно само по себе. И ни одна из схем не противоречит этому.
Понятно, что авторы подразумевали нечто другое, но это савсем не очевидно из схемы.
А вот схема слоистой архитектуры достаточно наглядно даёт понять невозможность взаимодействия UI и Data Access компонентов.
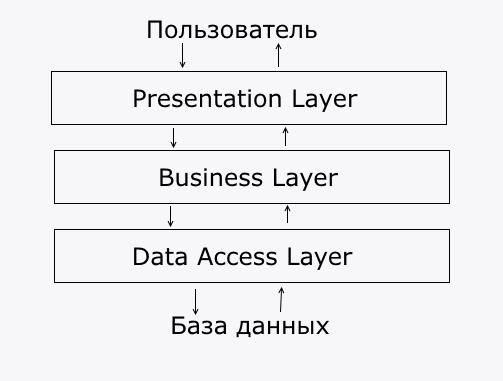
невозможность взаимодействия UI и Data Access компонентов.
простите, но цель же разделить их а не запретить взаимодействовать. Я не вижу ничего плохого в том, что для некоторых UI задач не нужно затрагивать слой бизнес логики (это даже я бы сказал логично).
Ну во первых, совершенно очевидно, что неопытный разработчик может трактовать это неправильно и начать писать SQL запросы в HTML шаблонах, от чего я и хочу предостеречь.
Опытный же разработчик понимает, что такое архитектурные шаблоны, как они работают, какие у них есть преимущества, недостатки и применяет тот или иной подход исходя из задачи, а не исходя из моды, хайпа и личных предпочтений. И для опытного разработчика не нужна ни эта статья ни мои комментарии.
Тут наверное стоит упомянуть о CQRS, который вы видимо подразумевали.
Да, в CQRS мы разделяем read и write потоки, но во первых это делается с целью оптимизации нагрузки и новички обычно этим не занимаются, а во вторых, все описанные архитектурные шаблоны (Слои, Луковицы, Гексогоны, Порты и Адаптеры) относятся к write потоку. То есть CQRS это скорей надстройка над архитектурой чем замена.
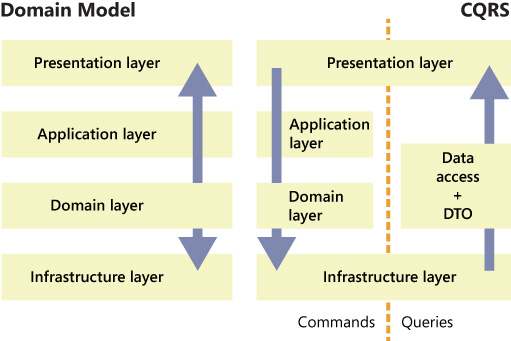
Исходя из этого я и хочу сделать акцент на том, что write поток в Data Access из UI в обход Domain должен быть ограничен, а read поток может идти в обход, но это уже совсем другая история.
И конечно, из любого правила бывают исключения. Бывает, что во write потоке, архитектура со всеми своими наворотами, просто не справляется с нагрузкой и тогда создают отдельный Front controller который без всяких фраймворков и прочего, тупо фигачит данные в хранилище (по сути микросервис).
начать писать SQL запросы в HTML шаблонах
в этом случае у нас нет разделения ответственности на отдельные слои. То есть в целом как слои не рисуй, они не появятся если их нет.
С другой стороны наивный читатель может вдруг вбить себе в голову идею что UI напрямую с persistence работать не должен и потому будет смешивать UI и бизнес логику. Ну то есть следует более простым языком тогда уж объяснять людям в чем смысл разделения ответственности и какие-то простые способы (пусть и не на 100%) их определения получить, а не слои рисовать.
Тут наверное стоит упомянуть о CQRS, который вы видимо подразумевали.
я ничего не подразумевал. Простой пример. У нас есть простое приложение гео-трекер. Когда приходит запрос "сохранить текущее положение" оно проходит через слой бизнес логики, делает разные штуки там, считает что ему надо и все. Но если приходит запрос "дай текущее положение" я не вижу смысла дергать для этого бизнес лэйер. Достаточно просто попросить слой хранилище предоставить координаты. Главное сохранить направления зависимостей и все.
То есть CQRS это скорей надстройка над архитектурой чем замена.
CQRS это паттерн, суть которого "на чтение и запись у нас есть два разных интерфейса". Там дальше про CQS можно вспомнить но в целом я повторюсь, я CQRS не имел ввиду.
все описанные архитектурные шаблоны (Слои, Луковицы, Гексогоны, Порты и Адаптеры) относятся к write потоку
Не совсем, они так же могут быть отнесены к read потоку. CQRS налагает только одно ограничение — читать и писать мы должны с помощью чуть разных штук. Но штуки эти могут иметь одинаковую структуру и разница будет только на уровне зависимостей.
"архитектура" портов и адаптеров — это лишь способ подчеркнуть важность инверсии зависимостей. Луковая архитектура появилась в спорах с Кокборном когда он называл эту архитектуру гексагональной (потому что ему было удобнее гексагонами рисовать схемки). Сколько там слоев, как оно все устроено — это детали.
(по сути микросервис).
больше базвордов богу базвордов. Раз речь зашла — рекомендую следующий видосик: Microservices and Rules Engines – a blast from the past — Udi Dahan
То есть UI имеет полное право обращаться к Data Access, что не правильно само по себе. И ни одна из схем не противоречит этому.
Пожалуй да. Можно подумать, что компоненты лежащие на одной грани не могут взаимодействовать с компонентами на другой грани, но на схеме нет явного разделения, что может привести к неоднозначному восприятию архитектуры.
Я сторонник "Явное лучше не явного" и слоистая архитектура на мой взгляд более явно демонстрирует разделение компонентов на слои.
Спасибо за перевод!
Особенно порадовало
Я не использовал названия Луковая Архитектура, Порты и Адаптеры в своей книге, потому что не знал о них в то время.
Не помню кто это сказал, но открытий было бы меньше, если бы читали больше
Слои, Луковицы, Гексогоны, Порты и Адаптеры — всё это об одном