Однажды я принял участие в конкурсе демо (программ, генерирующих аудио-визуальный ряд, основной особенностью которых является экстремально маленький размер — десятки или даже единицы кибибайт).
В процессе общего обсуждения кто-то предложил нестандартную для мира демо идею: написать программу на каком-либо скриптовом языке. Дело в том, что все демо сжимаются упаковщиком для уменьшения размера (а при исполнении распаковываются). И текст сжимается намного лучше бинарного кода. Если интерпретатор будет иметь очень маленький размер, это может дать существенное преимущество.
Из-за опыта работы во фронтенде мне сразу пришла мысль дополнительно минифицировать код — удалить пробелы и необязательные элементы, сократить длину идентификаторов. Ведь сжатие сохраняет всю информацию, а многие элементы синтаксиса не являются необходимостью.
Но даже так большинство существующих языков не предназначены для данной оптимизации — очевидно, они имеют множество элементов, которые нужны для понимания человеку, а не машине. А что, если разработать язык, специально рассчитанный на минификацию?
В том конкурсе, в итоге, участвовать я не стал. Однако, данная идея не покидала меня. Ведь она может быть полезна и для более практичных целей, чем демо — в мире фронтенда объём клиентских скриптов до сих пор крайне важен, если удастся сократить его, данное решение может оказаться оправданым хотя бы в некоторых случаях.
Я решил провести эксперимент — сделать прототип языка и посмотреть, что из этого выйдет.
Ключевые особенности
В свой язык я заложил следующие ключевые особенности: динамическая типизация, функциональная парадигма, отсутствие разделителей и классы идентификаторов.
Динамическую типизацию я выбрал, потому что для статической требуется описывать типы, что занимает драгоценное место.
Функциональную парадигму — потому что она более выразительна (позволяет меньшим объёмом кода выразить больше алгоритмов).
На двух остальных остановлюсь подробнее.
Отсутствие разделителей
Рассмотрим следующий код:
add(2, multiple(2, 2))
Число аргументов, которое ожидает каждая функция (арность функции), известно заранее. Скобки и запятые тут нужны исключительно для читаемости. Уберём их:
add 2 multiple 2 2
Точно так же можно поступить и с операторами, просто считая их функциями:
+ 2 * 2 2
При этом операторам не требуется иметь приоритет — порядок действий задаётся порядком записи, так как для вызова функции сначала требуется вычислить все её параметры. Так выражение выше вернёт значение 6. А чтобы получить 8, код потребуется записать так:
* 2 + 2 2
Классы идентификаторов
Так как операторы у меня являются обычными функциями, я решил расширить это и просто позволить использовать в идентификаторах любые символы пунктуации.
А затем мне пришла идея разделить все идентификаторы на два класса: буквенные и пунктуационные.
Дело в том, что в любом языке идентификаторы необходимо чем-то разделять — либо другими элементами синтаксиса, либо пробельными символами. Иначе будет неоднозначность: xy — это идентификатор xy или два идентификатора x и y?
Однако, имея два непересекающихся класса идентификаторов, я могу ослабить данное требование: идентификаторы разных классов можно писать слитно, неоднозначности не будет.
Более того, не даром у меня первый класс только буквенный — цифры в него не входят. Это позволяет записывать числа слитно с любым классом идентификаторов.
Для примера возьмём такое выражение:
foo($(5))
На моём языке его можно записать следующим образом:
foo$5
Решение проблем
В процессе разработки языка возникло несколько интересных проблем, которых я не ожидал, но всё-таки смог решить: вызов функций без аргументов и построение структуры кода (AST).
Вызов функций без аргументов
Так как для вызова функции у меня нет специального синтаксиса, как в других языках, функции без аргументов должны вызываться простым указанием их имени:
fn answer() 42 ; answer
Так оно и работало, но только на одном уровне вложенности. Что, если такая функция вернёт ещё одну такую же?
fn answer() fn() 42 ; ; answer
Тогда результатом будет замыкание, а не внутреннее значение. И как вызвать это замыкание? Ведь его имя мы уже и так указали.
Пришлось использовать подход из языка Clojure — trampoline: любые значения после их вычисления попадают в специальный цикл, который циклически вызывает замыкания, не требующие аргументов, до тех пор, пока результатом не будет что-то иное. Таким образом результатом второго примера выше так же будет 42, как и в первом.
Построение структуры кода
Для возможности осуществления минификации необходимо уметь определять структуру кода без его выполнения.
И когда мы знаем число аргументов всех функций, это несложно. Например, код:
add 2 multiple 2 2
Имеет следующую структуру:
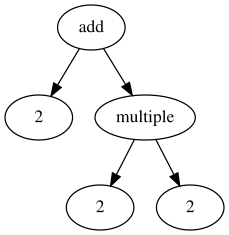
Однако, как только я начинаю возвращать замыкания, появляется неоднозначность:
fn add(x y) + x y ; fn increase(x) + x 1 ; fn foo(n) if == n 2 add increase ; foo x ...
Сколько надо передать аргументов результату вызова функции foo? Это возможно определить только во время исполнения кода, но никак не на стадии его разбора. И это делает невозможным осуществление минификации.
Чтобы решить данную проблему, я расширил типизацию до полустатической: типы требуется указывать только у функций, при этом в роли типа выступает указание только требуемого числа аргументов как для самой функции, так и для её результата, если тот является замыканием.
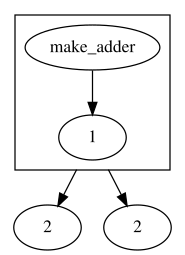
fn make_adder(bias):2 fn(x y) + bias + x y ; ; make_adder 1 2 2
В определении функции make_adder явно указано, что её результат является замыканием и ожидает два параметра. Поэтому легко построить структуру последнего вызова:
Общие возможности
Язык имеет следующие типы: nil, числа с плавающей запятой, списки, хеш-таблицы и замыкания. Строки реализованы на основе списков. Логические значения отсутствуют — определённые значения остальных типов считаются за ложь, а все остальные за истину.
Язык имеет набор встроенных функций: базовые математические функции и операции (в том числе для битовой арифметики), функции для работы со списками и хеш-таблицами, базовый ввод-вывод.
Язык поддерживает модульность через динамическую загрузку файлов исходного кода. Поддерживается кеширование, директория vendor и поиск в путях, указанных через специальную переменную окружения.
Язык имеет и небольшую стандартную библиотеку, содержащую модуль для работы со списками в функциональном стиле и модуль для юнит-тестирования.
Бенчмарк
Для оценки возможностей минификации я решил сравнить свой язык с JavaScript. Для этого я написал одну и ту же программу на обоих.
В качестве задачи выбрал алгоритм сравнения деревьев Virtual DOM. За основу взял эти статьи:
Однако, в них при сравнении сразу изменяется реальный DOM, я же просто генерировал список требуемых изменений с указанием адреса ноды, к которой они относятся.
function make_node(type, properties, ...children) { return { 'type': type, 'properties': properties || {}, 'children': children, } } function make_difference(path, action, ...parameters) { return { 'path': path, 'action': action, 'parameters': parameters, } } function is_different(node_1, node_2) { return typeof node_1 !== typeof node_2 || (typeof node_1 === 'object' ? node_1['type'] !== node_2['type'] : node_1 !== node_2) } function compare_property(path, name, old_value, new_value) { let difference if (!new_value) { difference = make_difference(path, 'remove_property', name) } else if (!old_value || new_value !== old_value) { difference = make_difference(path, 'set_property', name, new_value) } return difference } function compare_properties(path, old_properties, new_properties) { const properties = Object.assign({}, old_properties, new_properties) return Object.keys(properties) .map(name => compare_property(path, name, old_properties[name], new_properties[name])) .filter(difference => difference) } function compare_nodes(old_node, new_node, index=0, path=[]) { let differences = [] if (!old_node) { differences.push(make_difference(path, 'create', new_node)) } else if (!new_node) { differences.push(make_difference(path, 'remove', index)) } else if (is_different(old_node, new_node)) { differences.push(make_difference(path, 'replace', index, new_node)) } else if (old_node['type']) { const child_path = [...path, old_node['type']] const properties_differences = compare_properties(child_path, old_node['properties'], new_node['properties']) differences.push(...properties_differences) const maximal_children_length = Math.max(old_node['children'].length, new_node['children'].length) for (let i = 0; i < maximal_children_length; i++) { const child_differences = compare_nodes(old_node['children'][i], new_node['children'][i], i, child_path) differences.push(...child_differences) } } return differences } module['exports'] = { 'make_node': make_node, 'compare_nodes': compare_nodes, }
let map:2 load "std/list/map"; let filter:2 load "std/list/filter"; let zip_longest:3 load "std/list/zip_longest"; let reduce:3 load "std/list/reduce"; fn make_node(kind properties children) #"type" kind #"properties" properties #"children" children {}; fn make_difference(path action parameters) #"path" path #"action" action #"parameters" parameters {}; fn is_different(node_i node_ii) || != type node_i type node_ii fn() if == "hash" type node_i fn() != ."type"node_i ."type"node_ii; fn() != node_i node_ii; ; ; fn compare_property(path name old_value new_value) if !new_value fn() make_difference path "remove_property" ,name[]; fn() if || !old_value != new_value old_value fn() make_difference path "set_property" ,name,new_value[]; fn() nil; ; ; fn compare_properties(path old_properties new_properties) let properties + old_properties new_properties; let differences map keys properties fn(name) compare_property path name .name old_properties .name new_properties ;; filter differences fn(difference) difference ; ; fn compare_nodes(old_node new_node index path) if !old_node fn() , make_difference path "create" ,new_node[] []; fn() if !new_node fn() , make_difference path "remove" ,index[] []; fn() if is_different old_node new_node fn() , make_difference path "replace" ,index,new_node[] []; fn() if == "hash" type old_node fn() let child_path + path , ."type"old_node []; let properties_differences compare_properties child_path ."properties"old_node ."properties"new_node ; let children_pairs zip_longest ."children"old_node ."children"new_node fn(node_i node_ii) ,node_i,node_ii[] ; ; let children_differences let result reduce {} children_pairs fn(result children_pair) let index ?? ."index"result 0; let differences compare_nodes .0 children_pair .1 children_pair index child_path ; #"differences" + ?? ."differences"result [] differences #"index" ++ index {}; ; ?? ."differences"result [] ; + properties_differences children_differences ; fn() []; ; ; ; ; #"make_node" fn(kind properties children) make_node kind properties children ; #"compare_nodes" fn(old_node new_node index path) compare_nodes old_node new_node index path ; {}
Версию на JavaScript я минифицировал при помощи Google Closure Compiler (JavaScript-версии), версию на моём языке — вручную.
Результаты:
| Параметр | JavaScript | Мой язык |
|---|---|---|
| Объём полной версии | 2398 Б | 2827 Б |
| Объём минифицированной версии | 794 Б | 872 Б |
| Экономия объёма | 66.89% | 69.16% |
Итоги
Чтобы моя идея имела смысл, требовалось превзойти JavaScript по сжатию в несколько раз (ведь нужно место для самого интерпретатора). А результат оказался даже больше.
Таким образом эксперимент закончился неудачей. Идеи, которые я заложил в основу языка, не принесли ожидаемой выгоды.
Репозиторий
Исходный код интерпретатора (реализован на Python), стандартной библиотеки и примеров, а также документация доступны в репозитории под лицензией MIT.

