
Слева кадр из игры Labyrinth, в которой обучается агент искусственного интеллекта UNREAL. Программа фантазирует, как взять яблоко (+1 очко) и пирамидку (+10 очков), после чего произойдёт респаун в другом месте карты
Исследователи из британской компании DeepMind (собственность Google) опубликовали вчера интересную научную работу, в которой описывают неординарный метод обучения нейросети с подкреплением. Оказалось, что если в процессе самообучения нейросеть начинает «мечтать» о различных вариантах будущего, то тогда обучается гораздо быстрее. Сотрудники DeepMind подтвердили это экспериментально.
В научной статье объясняется работа интеллектуального агента Unsupervised Reinforcement and Auxiliary Learning (UNREAL). Он самостоятельно обучается проходить 3D-лабиринт Labyrinth в 10 раз быстрее, чем самое лучшее программное обеспечение типа ИИ на сегодняшний день. Эта игра отдалённо напоминает уровни первых 3D-шутеров, только без монстров и фашистов, специально разработана для тренировки нейросетей.
Конструкция Labyrinth впервые описана в предыдущей научной работе коллег из компании DeepMind.
Labyrinth
Программа UNREAL может играть в эту игру лучше 87% игроков-людей, а это довольно высокий результат.
«Наш агент намного быстрее тренируется и требует гораздо меньше входных данных из окружающего мира для тренировки», — объясняют сотрудники DeepMind и авторы научной работы Макс Ядерберг (Max Jaderberg) и Володимир Мних (Volodymyr Mnih). Такую нейросеть можно применять в разных задачах, а за счёт выдающихся характеристик она позволит быстрее и эффективнее прорабатывать различные идеи, над которыми работают исследователи.
Самообучение ИИ в играх — распространённая практика в разработке самообучаемых нейросетей с подкреплением.
ИИ от DeepMind учится играть в Atari Breakout
Это и понятно. Если ИИ научится хорошо играть в реалистичные компьютерные игры типа шутеров или симуляторов семейной жизни, то ему будет проще освоиться в реальном мире. В конце концов, в жизни человек тоже постоянно получает различные вознаграждения — улыбки окружающих, секс, деньги — и интеллектуально изменяет своё поведение, чтобы максимизировать количество вознаграждений. Также обучается и нейросеть с подкреплением.
Фантазии о будущем
Обучение нейросети с подкреплением происходит за счёт положительной обратной связи. Каждый раз при получении вознаграждения (в игре его роль выполняют яблоки) в нейросеть поступает положительный стимул. Эта игра отличается от многих других тем, что в ней частота вознаграждений относительно редкая, а агенту доступна только малая часть карты.
Как известно людям, редкие вознаграждения — именно то обстоятельство, которые объясняет положительное влияние мечты и фантазии.
Вот как объясняют работу UNREAL сами разработчики: «Рассмотрим ребёнка, который учится достигать максимального количества красного цвета в окружающем мире. Чтобы корректно предсказать оптимальное количество, ребёнок должен понимать, как увеличивать „красноту” в различных смыслах, включая манипуляции с красным объектом (приблизить его к глазам), собственное движение (приблизиться к красному объекту) и коммуникации (плакать, пока родители не принесут красный объект). Эти типы поведения вполне могут повториться во многих других ситуациях, с которыми столкнётся ребёнок».
Для агента UNREAL попытались реализовать примерно такую же схему достижения заданных целей, какая есть у описанного выше ребёнка. ИИ использует обучение с подкреплением для выработки оптимальной стратегии и оптимального значения целевой функции для многих псевдо-вознаграждений. Делаются другие дополнительные предсказания, чтобы обратить внимание агента на важные аспектах задачи. Среди этих предсказаний — долгосрочная задача предсказания общего вознаграждения и краткосрочная задача предсказания текущего вознаграждения. В игре Labyrinth это общее количество собранных яблок в игре и получение одного конкретного ближайшего яблока. Для более эффективного обучения при этом агенты используют механизм воспроизведения уже полученного опыта. «Как животные более часто мечтают о положительных или отрицательных вознаграждающих событиях, так и наши агенты предпочтительно заново воспроизводят последовательности, которые содержат вознаграждающие события».
Другими словами, иногда агенту ИИ даже не требуется заново проходить лабиринт, чтобы получить новые знания. Он просто использует свою память — и применяет новые стратегии как бы в своём воображении. Это и есть то самое, что исследователи называют фантазией.
Общая конструкция агента UNREAL изображена на иллюстрации. На ней изображён маленький буфер для хранения опыта (Replay Buffer), откуда берётся информация для генерации фантазий по краткосрочным и долгосрочным целям (Reward Prediction и Value Function Replay).
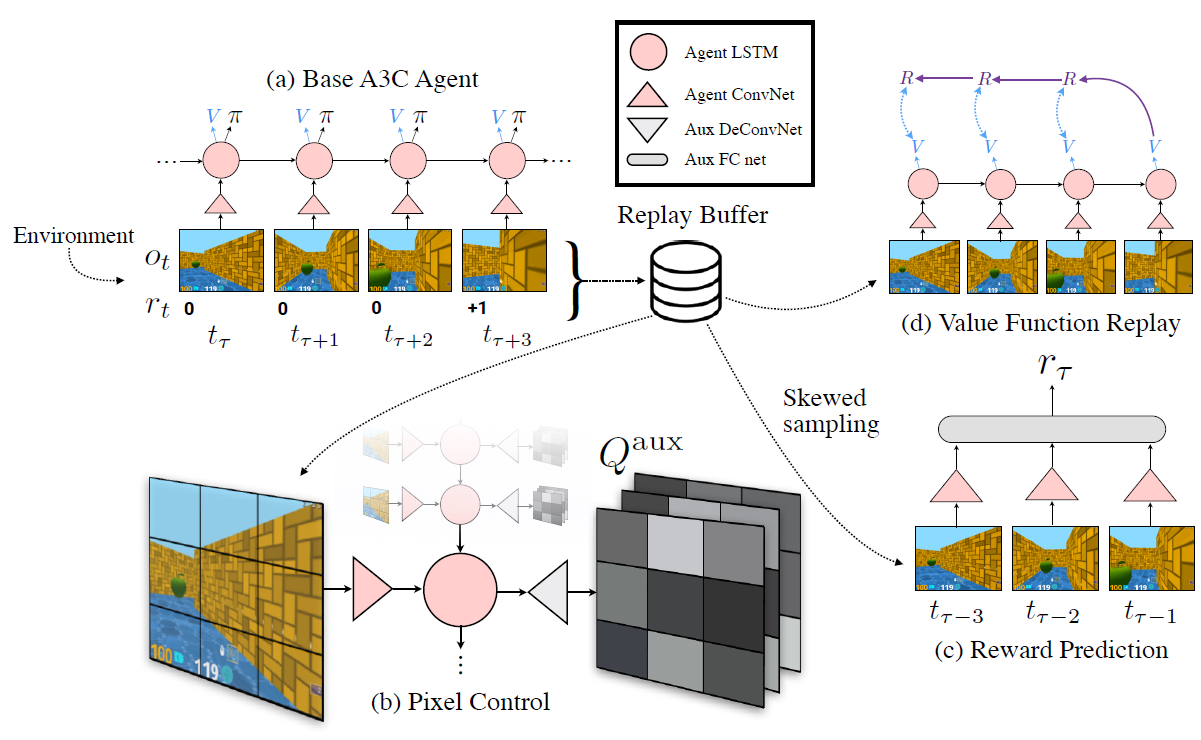
Фантазия (Reward Prediction) агента заключается в том, что по трём последним известным кадрам нейросеть должна предсказать вознаграждение, которое она получит на четвёртом неизвестном временном интервале.
На следующем видео показаны действия агента UNREAL в игре Labyrinth (зелёное яблоко даёт 1 очко, а красный объект — 10 очков; цель агента собрать 10 очков, после чего он переносится в другое место).
Кроме игры Labyrinth, агент UNREAL научился играть ещё в 57 винтажных игр Atari, такие как Breakout, намного быстрее и лучше, чем любые созданные ранее агенты. Скажем, прошлый чемпион среди агентов ИИ показывал результат примерно на 853% лучше топовых игроков-людей, а новый ИИ — на 880% лучше.
Результаты UNREAL во всех уровнях игры Labyrinth и Atari представлены на диаграммах. Аббревиатуры RP и VR соответствуют модулям фантазирования о краткосрочных и долгосрочных целях, а PC — модулю пиксельного контроля. UNREAL включает в себя все три модуля RP, VR и PC, а из остальных графиков мы можем понять вклад каждого модуля в общий успех агента.

Скептики
Несмотря на многочисленные научные исследования и успехи глубинного обучения нейросетей, находятся и скептики, которые сомневаются в перспективах этого направления для разработки ИИ. Например, бывший сотрудник компании IBM Сергей Карелов в телеграм-заметке «Снова о шарлатантстве в маркетинге науки и технологий» пишет:
Подход «данные на входе – действия на выходе», скорее всего, принципиально ошибочен для сколь-нибудь адекватного научного описания феномена человеческого сознания и всех связанных с ним понятий (интуиция и т.д.).
Первым это обосновал еще Джефф Хокинс в замечательной книге «Об интеллекте» (очень рекомендую всем, кто не любит разводилово про ИИ, но хочет понимать его реальные перспективы).
А сегодня к такому заключению склоняются все больше ученых мирового уровня, сфокусированных на изучении этой мульти-дисциплинарной области науки. Профессионально и не очень популярно (но здорово интересно) про это можно посмотреть тут.
К сожалению, Сергей Карелов не сказал, какой подход следует использовать учёным вместо той ерунды, которой они занимаются сейчас. Возможно, разработчики из компании DeepMind тоже хотят это знать.

