
Четыре года назад компания Google осознала реальный потенциал использования нейронных сетей в своих приложениях. Тогда же она начала внедрять их повсеместно — в перевод текстов, голосовой поиск с распознаванием речи и т. д. Но сразу стало понятно, что использование нейросетей сильно увеличивает нагрузку на серверы Google. Грубо говоря, если бы каждый человек осуществлял голосовой поиск на Android (или диктовал текст с распознаванием речи) всего три минуты в день, то Google пришлось бы увеличить количество дата-центров в два раза (!) просто чтобы нейросети обработали такое количество голосового трафика.
Надо было что-то предпринимать — и Google нашла решение. В 2015 году она разработала собственную аппаратную архитектуру для машинного обучения (Tensor Processing Unit, TPU), которая до 70 раз превосходит традиционные GPU и CPU по производительности и до 196 раз — по количеству вычислений на ватт. Под традиционными GPU/CPU имеются в виду процессоры общего назначения Xeon E5 v3 (Haswell) и графические процессоры Nvidia Tesla K80.
Впервые архитектура TPU описана на этой неделе в научной работе (pdf), которая будет представлена на 44-м международном симпозиуме по компьютерным архитектурам (ISCA), 26 июня 2017 года в Торонто. Ведущий автор из более 70 авторов этой научной работы, выдающийся инженер Норман Юппи (Norman Jouppi), известный как один из создателей процессора MIPS, в интервью изданию The Next Platform объяснил своими словами особенности уникальной архитектуры TPU, которая фактически представляет собой специализированный ASIC, то есть интегральную схему специального назначения.
В отличие от обычных FPGA или узкоспециализированных ASIC, модули TPU программируются точно так же, как GPU или CPU, это не аппаратура узкого назначения для единственной нейронной сети. Норман Юппи говорит, что TPU поддерживает CISC-инструкции для разных видов нейросетей: свёрточные нейросети, модели LSTM и большие, полностью соединённые модели. Так что она остаётся по-прежнему программируемой, только использует матрицу как примитив, а не векторные или скалярные примитивы.
Google подчёркивает, что в то время как другие разработчики оптимизируют свои микрочипы для свёрточных нейросетей, такие нейросети дают всего 5% нагрузки в дата-центрах Google. Основная часть приложений Google использует многослойные перцептроны Румельхарта, поэтому так важно было создать более универсальную архитектуру, не «заточенную» только под свёрточные нейросети.
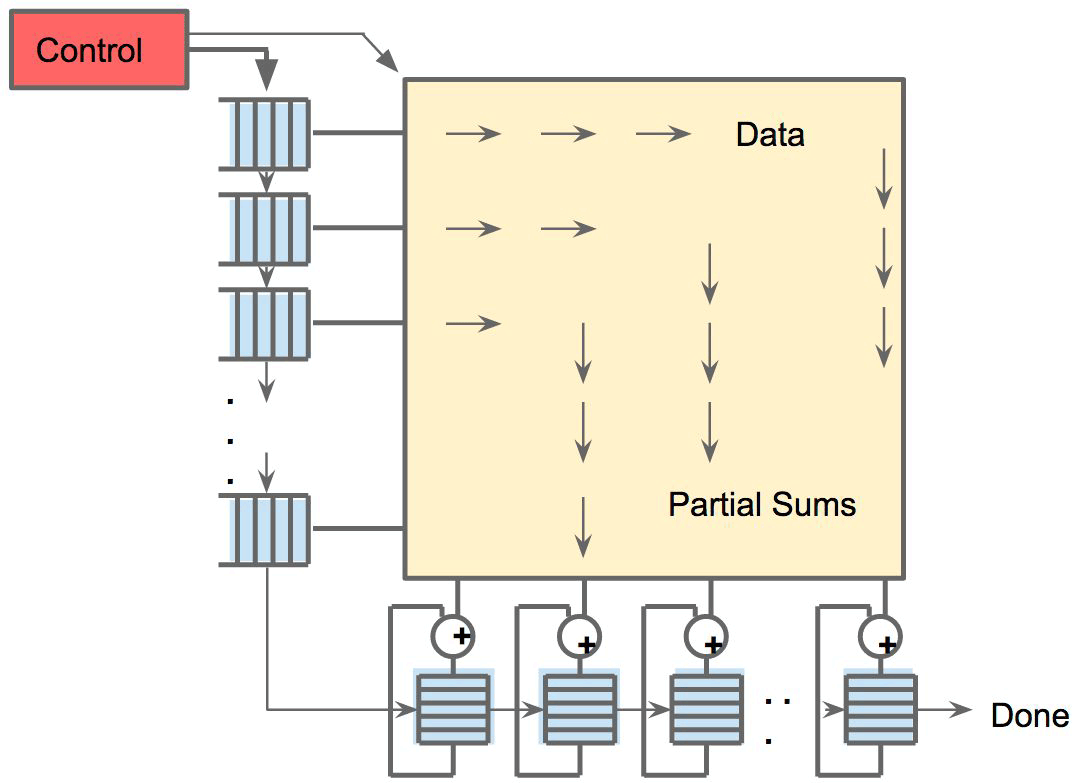
Один из элементов архитектуры — систолический движок потока данных, массив 256×256, в которую поступают активации (веса) от нейронов слева, а затем всё сдвигается шаг за шагом, умножаясь на веса в ячейке. Получается, что систолическая матрица производит 65 536 вычислений за цикл. Такая архитектура идеально подходит для нейросетей
По словам Юппи, архитектура TPU больше похожа на сопроцессор FPU, чем на обычный GPU, хотя многочисленные матрицы для умножения не хранят в себе никаких программ, они просто исполняют инструкции, полученные от хоста.
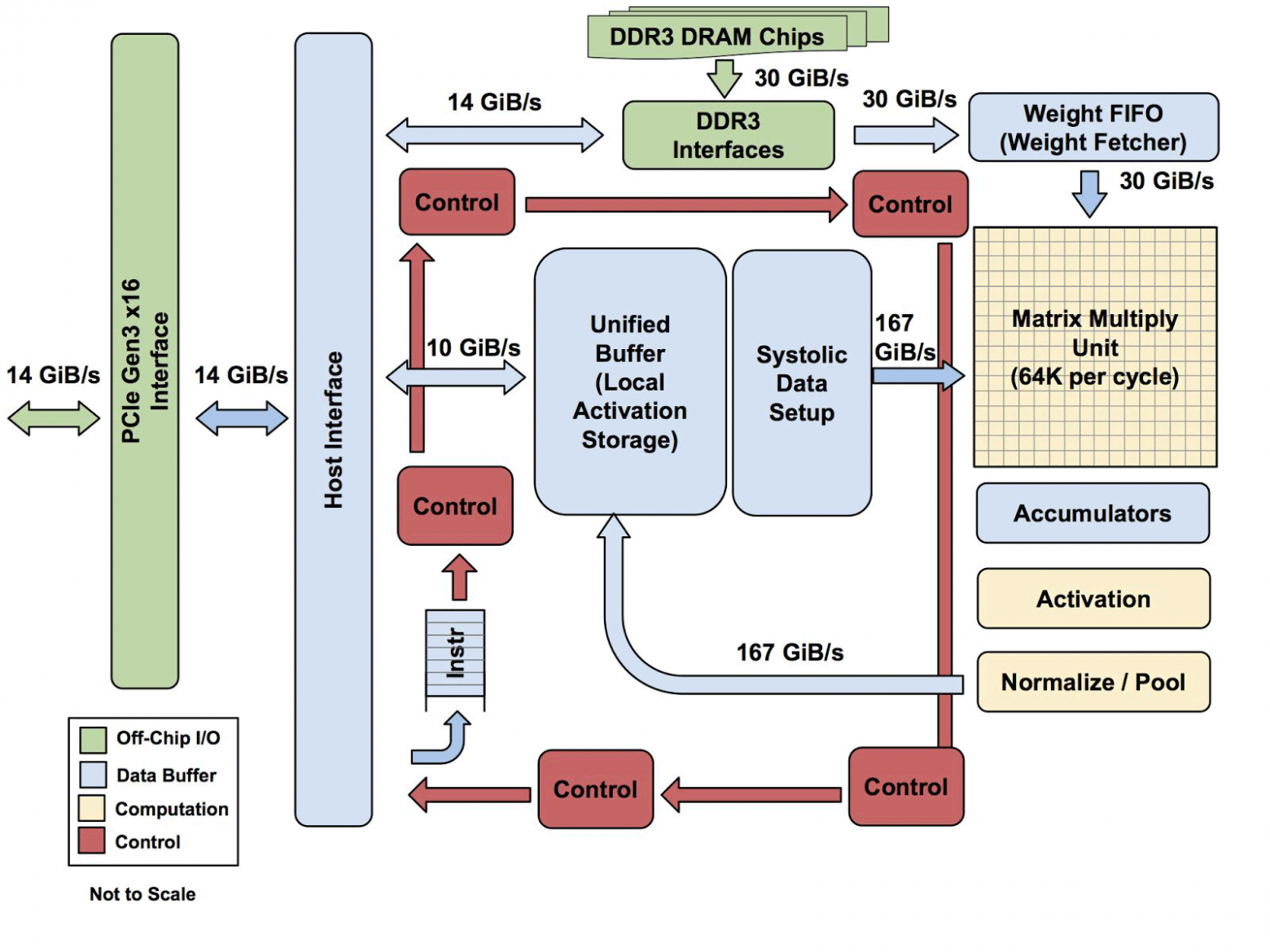
Вся архитектура TPU за исключением памяти DDR3. Инструкции отправляются с хоста (слева) в очередь. Затем управляющая логика, в зависимости от инструкции, может многократно запускать каждую из них
Пока неизвестно, насколько масштабируется такая архитектура. Юппи говорит, что в системе с такого рода хостом всегда будет некое бутылочное горлышко.
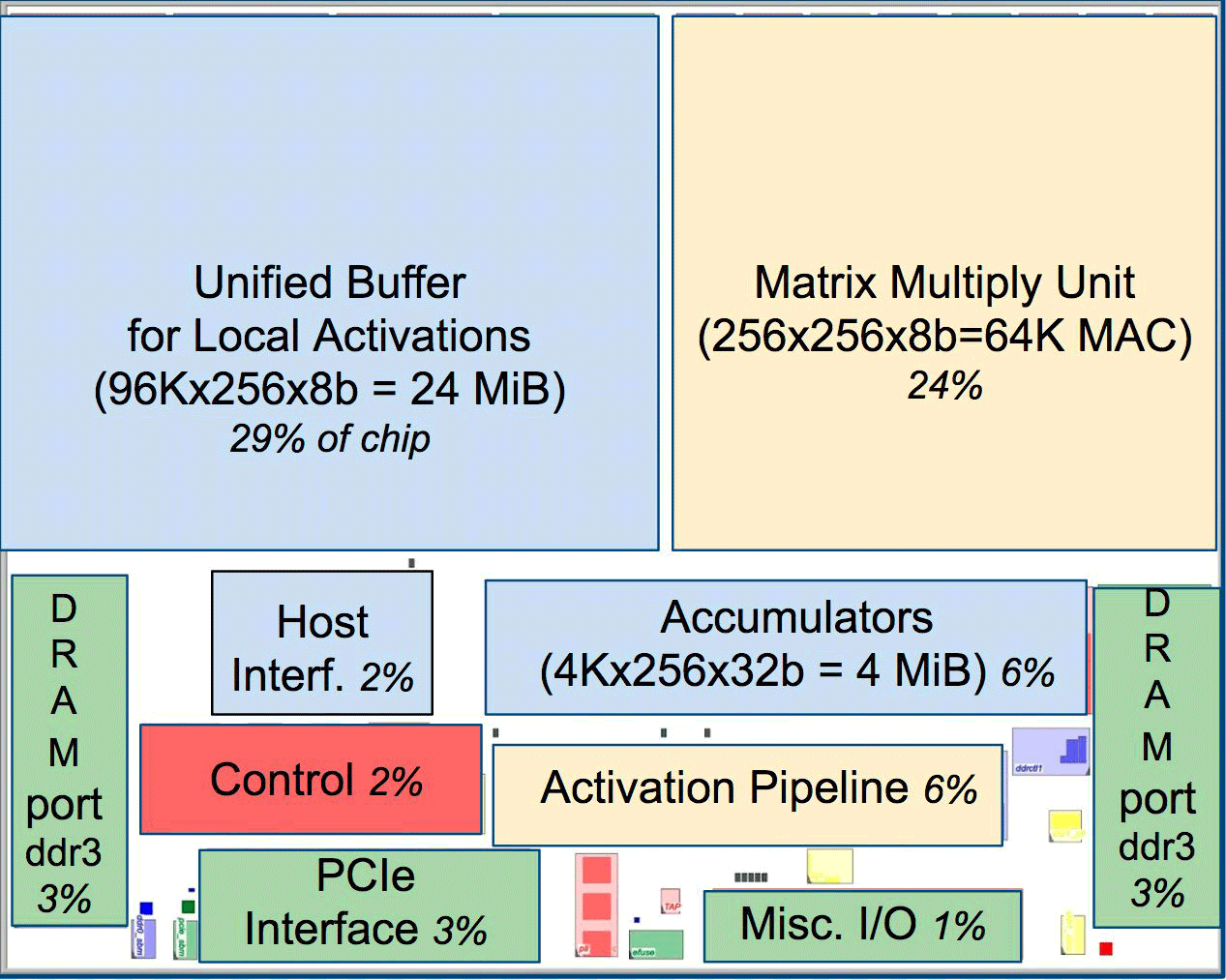
В сравнении с обычными CPU и GPU архитектура Google в машинном превосходит их в десятки раз. Для примера, процессор Haswell Xeon E5-2699 v3 с 18 ядрами на тактовой частоте 2,3 ГГц с 64-битной плавающей точкой выполняет 1,3 тера-операций в секунду (TOPS) и показывает скорость обмена с памятью 51 ГБ/с. При этом сам чип потребляет 145 Вт, а вся система на нём с 256 ГБ памяти — 455 Вт.
Для сравнения, TPU на 8-битных операциях с 256 ГБ внешней памяти и 32 ГБ собственной памяти демонстрирует скорость обмена с памятью 34 ГБ/с, но при этом карта выполняет 92 TOPS, то есть примерно в 71 раз больше, чем процессор Haswell. Энергопотребление сервера на TPU составляет 384 Вт.

На следующем графике сравнивается относительная производительность на один ватт сервера с GPU (синий столбец), сервера на TPU (красный) по отношению к серверу на CPU. Также сравнивается относительная производительность на один ватт сервера с TPU по отношению к серверу на GPU (оранжевым) и улучшенной версии TPU по отношению к серверу на CPU (зелёным) и серверу на GPU (сиреневым).
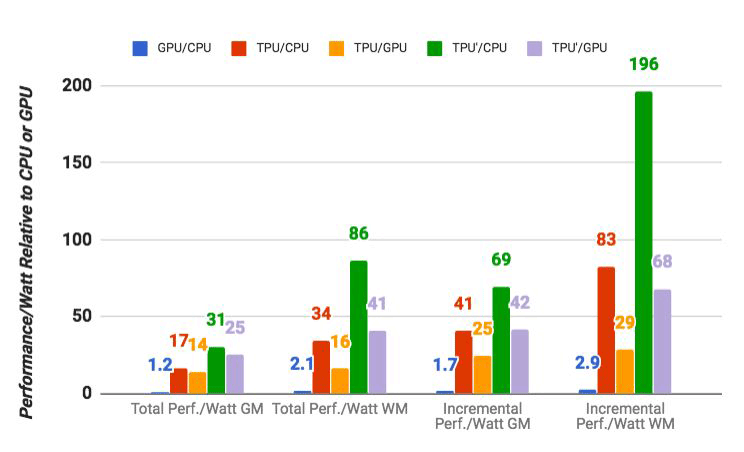
Нужно заметить, что Google проводила сравнения в тестах приложений на TensorFlow с относительной старой версией Haswell Xeon, в то время как в более новой версии Broadwell Xeon E5 v4 количество инструкций на цикл увеличилось на 5% благодаря архитектурным улучшениям, а в версии Skylake Xeon E5 v5, которая ожидается летом количество инструкций на цикл может увеличиться ещё на 9-10%. А с увеличением количества ядер с 18 до 28 в Skylake общие показатели процессоров Intel в тестах Google могут улучшиться на 80%. Но даже несмотря на это сохранится огромная разница в производительности с TPU. В версии теста с 32-битной плавающей точкой разница TPU с CPU сокращается примерно до 3,5 раз. Но большинство моделей отлично квантуются до 8 бит.
Google думала, как использовать GPU, FPGA и ASIC в своих дата-центрах с 2006 года, но не находила им применения до последнего времени, когда внедрила машинное обучение для ряда практических задач, и на эти нейросети начала расти нагрузка с миллиардами запросов от пользователей. Теперь у компании нет другого выхода, кроме как уходить от традиционных CPU.
Компания не планирует продавать свои процессоры кому-либо, но надеется, что научная работа с ASIC образца 2015 года позволит другим усовершенствовать архитектуру и создать улучшенные версии ASIC, которые «поднимут планку ещё выше». Сама Google уже наверняка работает над новой версией ASIC.

