
Свою рабочую станцию мне выдалось собирать, будучи студентом. Достаточно логично, что я отдавал предпочтение вычислительным решениям AMD. потому что это дешево выгодно по соотношению цена/качество. Я долго подбирал компоненты, в итоге уложился в 40к с комплектом из FX-8320 и RX-460 2GB. Сначала этот комплект казался идеальным! Мы с соседом по комнате слегка майнили Monero и мой набор показывал 650h/s против 550h/s на наборе из i5-85xx и Nvidia 1050Ti. Правда, от моего набора в комнате бывало слегка жарковато по ночам, но это решилось, когда я приобрел башенный кулер к CPU.
Сказка кончилась
Всё было как в сказке ровно до тех пор, пока я не увлекся машинным обучением в сфере компьютерного зрения. Даже точнее — до тех пор, пока мне не пришлось работать с входными изображениями разрешением больше 100х100px (до этого момента мой 8-ядерный FX резво справлялся). Первой сложностью оказалась задача определения эмоций. 4 слоя ResNet, входное изображение 100х100 и 3000 изображений в обучающей выборке. И вот — 9 часов обучения 150 эпох на CPU.
Конечно, из-за такой задержки страдает итеративный процесс разработки. На работе у нас стояла Nvidia 1060 6GB и обучение похожей структуры(правда, там обучалась регрессия для локализации объектов) на ней пролетало за 15-20 минут — 8 секунд на эпоху из 3.5к изображений. Когда у тебя такой контраст под носом, дышать становится еще труднее.
Что-ж, угадайте мой первый ход после всего этого? Да, я пошёл выторговывать 1050Ti у моего соседа. С аргументами о ненужности CUDA для него, с предложением обмена на мою карту с доплатой. Но всё тщетно. И вот я уже выкладываю свою RX 460 на Авито и рассматриваю заветную 1050Ti на сайтах Ситилинка и Технопоинта. Даже в случае успешной продажи карты мне пришлось бы найти еще 10к(я студент, пусть и работающий).
Гуглю
Окей. Я иду гуглить, как юзать Radeon под Tensorflow. Заведомо зная, что это экзотическая задача, я особо не надеялся найти что-то толковое. Собирать под Ubuntu, заведётся или нет, получить кирпич — фразы, выхваченные с форумов.
И вот я пошел другим путём — я гуглю не "Tensorflow AMD Radeon", а "Keras AMD Radeon". Меня моментально кидает на страничку PlaidML. Я завожу его за 15 минут(правда, пришлось сдаунгрейдить Keras до 2.0.5) и ставлю учиться сеть. Первое наблюдение — эпоха идет 35 сек вместо 200.
Лезу исследовать
Авторы PlaidML — vertex.ai, входящая в группу проектов Intel(!). Цель разработки — максимальная кроссплатформенность. Конечно, это добавляет уверенности в продукте. Их статья рассказывает, что PlaidML конкурентноспособен с Tensorflow 1.3 + cuDNN 6 за счет "тщательной оптимизации".
Однако, продолжим. Следующая статья в какой-то степени раскрывает нам внутреннее устройство библиотеки. Основное отличие от всех других фреймворков — это автоматическая генерация ядер вычислений(в нотации Tensorflow "ядро" — это полный процесс выполнения определенной операции в графе). Для автоматической генерации ядер в PlaidML очень важны точные размеры всех тензоров, константы, шаги, размеры сверток и граничные значения, с которыми далее придется работать. Например, утверждается, что дальнейшее создание эффективных ядер различается для батчсайзов 1 и 32 или для сверток размеров 3х3 и 7х7. Имея эти данные фреймворк сам сгенерирует максимально эффективный способ распараллеливания и исполнения всех операций для конкретного устройства с конкретными характеристиками. Если посмотреть на Tensorflow, то при создании новых операций нам необходимо реализовать и ядро для них — и реализации сильно различаются для однопоточных, многопоточных или CUDA-совместимых ядер. Т.е. в PlaidML явно больше гибкости.
Идем далее. Реализация написана на самописном языке Tile. Данный язык обладает следующими основными преимуществами — близость синтаксиса к математическим нотациям (да с ума же сойти!):
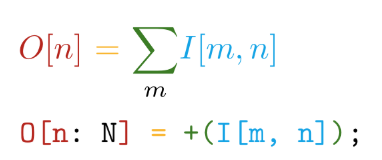
И автоматическая дифференциация всех объявляемых операций. Например, в TensorFlow при создании новой пользовательской операции настоятельно рекомендуется написать функцию для вычисления градиентов. Таким образом, при создании собственных операций на языке Tile нам нужно сказать лишь, ЧТО мы хотим посчитать, не задумываясь о том, КАК это считать в отношении аппаратных устройств.
Дополнительно производится оптимизация работы с DRAM и аналогом L1-кэша в GPU. Вспомним схематичное устройство:

Для оптимизации используются все доступные данные об оборудовании — размер кэша, ширина линии кэша, полоса пропускания DRAM и тд. Основные способы — обеспечение одновременного считывания достаточно больших блоков из DRAM(попытка избежать адресации в разные области) и достижение того, что данные, загруженные в кэш, используются несколько раз(попытка избежать перезагрузок одних и тех же данных несколько раз).
Все оптимизации проходят во время первой эпохи обучения, при этом сильно увеличивая время первого прогона:

Кроме того, стоит отметить, что данный фреймворк завязан на OpenCL. Главный плюс OpenCL в том, что это стандарт для гетерогенных систем и ничего не мешает Вам запустить kernel на CPU. Да, именно тут кроется один из главных секретов кроссплатформенности PlaidML.
Заключение
Конечно, обучение на RX 460 всё еще идет в 5-6 раз медленнее, чем на 1060, но вы сравните и ценовые категории видеокарт! Потом у меня появилась RX 580 8gb(мне одолжили!) и время прогона эпохи сократилось до 20 сек, что уже почти сопоставимо.
В блоге vertex.ai есть честные графики (больше — лучше):

Видно, что PlaidML конкурентноспособен по отношению к Tensorflow+CUDA, но точно не быстрее для актуальных версий. Но в такую открытую схватку разработчики PlaidML, вероятно, и не планируют вступать. Их цель — универсальность, кроссплатформенность.
Оставлю здесь и не совсем сравнительную таблицу со своими замерами производительности:
| Вычислительное устройство | Время прогона эпохи (батч — 16), с |
|---|---|
| AMD FX-8320 tf | 200 |
| RX 460 2GB plaid | 35 |
| RX 580 8 GB plaid | 20 |
| 1060 6GB tf | 8 |
| 1060 6GB plaid | 10 |
| Intel i7-2600 tf | 185 |
| Intel i7-2600 plaid | 240 |
| GT 640 plaid | 46 |
Последняя статья в блоге vertex.ai и последние правки в репозитории датированы маем 2018 года. Кажется, если разработчики данного инструмента не перестанут релизить новые версии и всё больше людей, обиженных Nvidia, будут ознакомлены с PlaidML, то про vertex.ai скоро будут говорить намного чаще.
Расчехляйте свои Radeon'ы!

