Эта статья о трансляторе эзотерического языка на TurboAssembler'e (TASM).
P′′ — низкоуровневый язык программирования, созданный в 1964 году Коррадо Бёмом.
Этот язык разрабатывался для реализации циклов без использования оператора GOTO.
В данной статье демонстрируется создание некого транслятора на низком уровне, в котором обработка текста программы (строки) производится посредством условных и безусловных переходов, т.е. низкоуровневых эквивалентов оператора GOTO.
Вот здесь лежит форк визуализатора(visualizer), позволяющего выполнить отладку bf-программ в пошаговом режиме
Сперва напишем транслятор на каком-нибудь высокоуровневом языке, например, на Паскале.
Пусть массив data_arr представляет память данных (ленту Тьюринга), пусть строка str_arr содержит команды.
Напишем программу, выводящую символ, ascii-код которого соответствует количеству + (поэтому нам нужны будут только команды + и .)
bf-код +++++++++++++++++++++++++++++++++. выдаст ! (ascii-код символа ! равен 33 ).
Программу можно проверить в online ide ideone.com
Далее, заменим цикл for оператором goto и добавим команды
В конце будем выводить массив data_arr
Код выдаст 1 2 3 0 0 0 0 0 0 0
выдаст 1 2 3 0 0 0 0 0 0 0
Код выдаст 1 2 2 0 0 0 0 0 0 0
выдаст 1 2 2 0 0 0 0 0 0 0
ideone.com
Далее, добавим [ и ]
Добавим ещё одну переменную i_stor.
Если текущий элемент прошёл проверку на [, то проверяем текущий элемент массива data_arr на ноль, и, если элемент больше нуля, загружаем в i_stor значение из переменной i.
При обработке закрывающей скобки ], если data_arr не ноль, в переменную i из переменной i_stor загружаем адрес открывающей скобки [
Далее переходим к команде i:=i+1;
Если до этого в i было загружено значение из i_stor ( при проверке ] ), то после джампа мы окажемся за [ ( в противном случае мы окажемся за ] )
Код![$+++++[>+<-]$](https://habrastorage.org/getpro/habr//formulas/d95/d96/945/d95d96945850dd1884dd45caf25c4865.svg) переносит число 5 в соседнюю ячейку 0 5 0 0 0 0 0 0 0 0
переносит число 5 в соседнюю ячейку 0 5 0 0 0 0 0 0 0 0
ideone.com
Код HelloWorld выглядит так ideone.com
Чтобы организовать цикл (loop), необходимо поместить в регистр CX количество тактов цикла и поставить метку, на которую будет сделан переход по завершении такта (по команде loop).
Создадим массив команд str_arr, поместим туда
Создадим массив данных data_arr, (для наглядности) поместим туда 1,1,1,1,1,1,1,1,1,1
В цикле сравниваем текущий символ с символом и, если символы равны, увеличиваем значение в текущей ячейке на 1.
и, если символы равны, увеличиваем значение в текущей ячейке на 1.
Ассемблирование (трансляция) выполняется командой tasm.exe bf1.asm
Линковка выполняется командой tlink.exe bf1.obj
После выполнения программы в отладчике TurboDebagger видно, что начиная с адреса 0130 расположены команды
Далее идет массив данных, в котором мы изменили первый элемент, далее идет переменная i, которая после выполнения цикла стала равна 0Ah.

Добавим команды
Для того, чтобы вывести одиночный символ с помощью функции 02h прерывания int 21h, необходимо (перед вызовом прерывания) поместить код символа в регистр DL.
Напишем программу целиком

Цикл работает так:
если текущий элемент строки str_arr не то перепрыгиваем на метку next: (иначе выполняем )
если текущий элемент строки str_arr не то перепрыгиваем на метку next1:
то перепрыгиваем на метку next1:
если текущий элемент строки str_arr не то перепрыгиваем на метку next2:
то перепрыгиваем на метку next2:
если текущий элемент строки str_arr не то перепрыгиваем на метку next3:
то перепрыгиваем на метку next3:
если текущий элемент строки str_arr не то перепрыгиваем на метку next4:
то перепрыгиваем на метку next4:
После метки next4: увеличиваем индекс строки str_arr и прыгаем в начало цикла — на метку prev:
Далее, добавим [ и ]
Добавим переменную i_stor.
Если текущий элемент прошёл проверку на [, то проверяем текущий элемент массива data_arr на ноль, и, если элемент равен нулю, перепрыгиваем дальше (на следующую метку), в противном случае загружаем в i_stor значение из переменной i.
При обработке закрывающей скобки ], если data_arr не ноль, то в переменную i из переменной i_stor загружаем адрес открывающей скобки [
Проверим код

Добавим функцию ввода строки 3fh прерывания 21h
Выходить из цикла будем по достижении конца строки '$'.
Для этого будем сравнивать текущий символ с символом '$'
Заменим цикл loop командой jmp.
В процессе компиляции получаем ошибку
Дело в том, что команды je/jne могут перепрыгнуть только через несколько строчек программы (каждая строчка занимает в памяти от 1 до 5 байт).
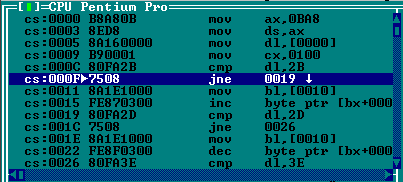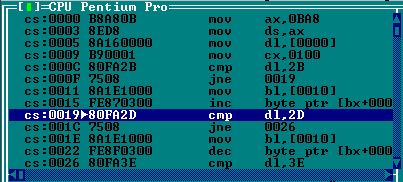
Длинные переходы в конец программы je/jne совершать не могут.
Поэтому заменим выражение
выражением
Итак, если текущий символ соответствует $, то переходим на метку exit_loop: командой jmp, иначе перепрыгиваем через команду jmp.
На метку команда jmp может делать внутрисегментный относительный короткий переход (переход меньше 128 байт, т.е. IP:=IP+i8) или внутрисегментный относительный длинный переход (переход меньше 32767 байт, т.е. IP:=IP+i16).
По умолчанию команда jmp делает относительный длинный переход, что нам и надо (а вообще вместо этого можно просто добавить директиву jumps в начало программы).
Добавим вывод массива data_arr (ленту машины Тьюринга) на экран.
Напишем программу, выводящую на экран элементы произвольного массива посредством функции 09h прерывания 21h
На экране мы увидим ascii-коды элементов массива data_arr DB 1,0,2,0,3,0,4,0,5,0,6,0,7,'$'

Для того, чтобы представить элементы массива в виде чисел, будем использовать опрератор div.
Команда div ЧИСЛО делит регистр AX на ЧИСЛО и помещает целую часть от деления в AL, а остаток от деления в AH (ЧИСЛОМ может быть либо область памяти, либо регистр общего назначения)
Выведем 1ый и 2ой элементы массива
Для того, чтобы вывести все элементы массива, будем использовать команду loop.
Поместим в регистр CX количество тактов, равное количеству элементов массива и на каждом такте будем прибавлять единицу к индексу массива i.
Далее, добавим цикл, отображающий элементы массива в виде чисел, в основную программу.
Теперь HelloWorld выглядит так

Поскольку мы не обрабатываем числа больше 99, то число 100 отображается некорректно, остальные числа отображаются корректно.
Для обработки вложенных скобок будем открывающие скобки помещать в стэк, а закрывающие извлекать из стека.
Напишем простую программу работы со стеком на Паскале.
Взял отсюда.
Проверить можно здесь или здесь.
Изменим процедуру push так, чтобы при size равном нулю мы получали ссылку на первый элемент.
Добавим «стэк» в основную программу.
ideone.com
Если мы встречаем открывающую скобку, то просто помещаем её адрес в стэк, когда мы встречаем закрывающую скобку, то извлекаем её адрес из стека, если при этом значение в текущей ячейке больше нуля, то возвращаемся на открывающую скобку.
Пример использования нормального/«стандартного» стэка показан в программе bf51_stack.pas
«Добавим» стэк к основной ассемблерной программе

Ссылка на github с листингами программ.
P′′ — низкоуровневый язык программирования, созданный в 1964 году Коррадо Бёмом.
Этот язык разрабатывался для реализации циклов без использования оператора GOTO.
В данной статье демонстрируется создание некого транслятора на низком уровне, в котором обработка текста программы (строки) производится посредством условных и безусловных переходов, т.е. низкоуровневых эквивалентов оператора GOTO.
Вот здесь лежит форк визуализатора(visualizer), позволяющего выполнить отладку bf-программ в пошаговом режиме
Машина, которой управляют команды транслятора, состоит из упорядоченного набора ячеек и указателя текущей ячейки, подобно тому, как организована машина Тьюринга. Кроме того, подразумевается устройство общения с внешним миром (см. команды. и ,) через поток ввода и поток вывода.
| > | перейти к следующей ячейке |
|---|---|
| < | перейти к предыдущей ячейке |
| + | увеличить значение в текущей ячейке на 1 |
| - | уменьшить значение в текущей ячейке на 1 |
| . | напечатать значение из текущей ячейки |
| , | ввести значение и сохранить в текущей ячейке |
| [ | если значение текущей ячейки ноль, перейти вперёд по тексту программы на символ, следующий за соответствующей ] (с учётом вложенности) |
| ] | если значение текущей ячейки не нуль, перейти назад по тексту программы на символ [ (с учётом вложенности) |
Сперва напишем транслятор на каком-нибудь высокоуровневом языке, например, на Паскале.
Пусть массив data_arr представляет память данных (ленту Тьюринга), пусть строка str_arr содержит команды.
Напишем программу, выводящую символ, ascii-код которого соответствует количеству + (поэтому нам нужны будут только команды + и .)
var data_arr:array[1..10] of integer; // массив данных str_arr: string; // команды i, j: integer; // индексы строки и массива begin j:=1; // нумерация элементов массива начинается с единицы readln(str_arr); //считываем строку for i:=1 to length(str_arr) do begin // в цикле обрабатываем строку if (str_arr[i]='+') then data_arr[j]:= data_arr[j]+1; if (str_arr[i]='.') then write(chr(data_arr[j])); end; end.
bf-код +++++++++++++++++++++++++++++++++. выдаст ! (ascii-код символа ! равен 33 ).
Программу можно проверить в online ide ideone.com
Далее, заменим цикл for оператором goto и добавим команды
В конце будем выводить массив data_arr
LABEL prev,next; var data_arr:array[1..10] of integer; // массив данных str_arr: string; // команды i,j,k: integer; // индексы строки и массива begin i:=1; j:=1; readln(str_arr); //считываем строку prev: if i>length(str_arr) then goto next; if (str_arr[i]='+') then data_arr[j]:= data_arr[j]+1; if (str_arr[i]='-') then data_arr[j]:= data_arr[j]-1; if (str_arr[i]='>') then j:=j+1; if (str_arr[i]='<') then j:=j-1; if (str_arr[i]='.') then write(chr(data_arr[j])); i:=i+1; goto prev; next: for k:=1 to 10 do begin write(data_arr[k]); write(' '); end; end.
Код
выдаст 1 2 3 0 0 0 0 0 0 0Код
выдаст 1 2 2 0 0 0 0 0 0 0ideone.com
Далее, добавим [ и ]
Добавим ещё одну переменную i_stor.
Если текущий элемент прошёл проверку на [, то проверяем текущий элемент массива data_arr на ноль, и, если элемент больше нуля, загружаем в i_stor значение из переменной i.
При обработке закрывающей скобки ], если data_arr не ноль, в переменную i из переменной i_stor загружаем адрес открывающей скобки [
Далее переходим к команде i:=i+1;
Если до этого в i было загружено значение из i_stor ( при проверке ] ), то после джампа мы окажемся за [ ( в противном случае мы окажемся за ] )
LABEL prev,next; var data_arr:array[1..10] of integer; // массив данных str_arr: string; // команды i,j,k: integer; // индексы строки и массива i_stor: integer; begin j:=1; i:=1; readln(str_arr); //считываем строку prev: if i>length(str_arr) then goto next; if (str_arr[i]='+') then data_arr[j]:= data_arr[j]+1; if (str_arr[i]='-') then data_arr[j]:= data_arr[j]-1; if (str_arr[i]='>') then j:=j+1; if (str_arr[i]='<') then j:=j-1; if (str_arr[i]='.') then write(chr(data_arr[j])); if (str_arr[i]='[') then begin if data_arr[j]>0 then i_stor:=i; end; if (str_arr[i]=']') then begin if data_arr[j]>0 then begin i:=i_stor; end; end; i:=i+1; goto prev; next: for k:=1 to 10 do begin write(data_arr[k]); write(' '); end; end.
Код
переносит число 5 в соседнюю ячейку 0 5 0 0 0 0 0 0 0 0ideone.com
Код HelloWorld выглядит так ideone.com
Перейдем к ассемблеру
Чтобы организовать цикл (loop), необходимо поместить в регистр CX количество тактов цикла и поставить метку, на которую будет сделан переход по завершении такта (по команде loop).
mov CX, 28h ; кол-во тактов цикла prev: ; метка цикла ; выполняем ; операции ; внутри цикла loop prev ; возвращаемся на метку prev
Создадим массив команд str_arr, поместим туда
Создадим массив данных data_arr, (для наглядности) поместим туда 1,1,1,1,1,1,1,1,1,1
В цикле сравниваем текущий символ с символом
и, если символы равны, увеличиваем значение в текущей ячейке на 1. text segment ; bf1.asm assume cs:text, ds:data, ss:stk begin: ;Подготовим все необходимое mov AX,data ; настраиваем сегмент данных mov DS,AX mov DL, str_arr ; загружаем в DL 1ую команду mov CX, 0Ah ; 10 тактов prev: cmp DL, 2Bh ; ячейка содержит + jne next ; нет, переходим на метку next mov BL, 00h ; загружаем в BL индекс inc data_arr[BX] ; да, увеличиваем значение в ячейке на 1 next: inc i ; переходим на следующий символ массива команд mov BL, i mov DL, str_arr [BX] loop prev mov AX, 4c00h ; завершение программы int 21h text ends data segment str_arr DB 2Bh,2Bh,2Bh,'$' ; код +++ data_arr DB 1,1,1,1,1,1,1,1,1,1,'$' ; данные i DB 0 ;индекс элемента массива команд data ends stk segment stack db 100h dup (0) ; резервируем 256 ячеек stk ends end begin
Ассемблирование (трансляция) выполняется командой tasm.exe bf1.asm
Линковка выполняется командой tlink.exe bf1.obj
После выполнения программы в отладчике TurboDebagger видно, что начиная с адреса 0130 расположены команды
Далее идет массив данных, в котором мы изменили первый элемент, далее идет переменная i, которая после выполнения цикла стала равна 0Ah.
Добавим команды
Для того, чтобы вывести одиночный символ с помощью функции 02h прерывания int 21h, необходимо (перед вызовом прерывания) поместить код символа в регистр DL.
mov AH,2 mov DL, код символа int 21h
Напишем программу целиком
text segment ; bf2.asm assume cs:text,ds:data, ss:stk begin: ;Подготовим все необходимое mov AX,data ; настраиваем сегмент данных mov DS,AX mov DL, str_arr ; загружаем в DL 1ую команду mov CX, 0Ah ; 10 тактов prev: cmp DL, 2Bh ; ячейка содержит + jne next ; нет, переходим на метку next mov BL, j ; загружаем в BL индекс данных inc data_arr[BX] ; да, увеличиваем значение в ячейке на 1 next: cmp DL, 2Dh ; ячейка содержит - jne next1 ; нет, переходим на метку next1 mov BL, j dec data_arr[BX] next1: cmp DL, 3Eh ; ячейка содержит > jne next2 ; нет, переходим на метку next2 inc j ; да, переходим на сдедующий элемент массива data_arr next2: cmp DL, 3Ch ; ячейка содержит < jne next3 ; нет, переходим на метку next3 dec j ; да, переходим на предыдущий элемент массива data_arr next3: cmp DL, 2Eh ; ячейка содержит . jne next4 ; нет, переходим на метку next4 mov AH,2 ; да, выводим содержимое ячейки mov BL, j mov DL, data_arr[BX] int 21h next4: inc i ; переходим на следующий символ массива команд mov BL, i mov DL, str_arr [BX] loop prev mov AX, 4c00h ; завершение программы int 21h text ends data segment str_arr DB 2Bh,3Eh,2Bh,2Bh,'$' ; код +>++ data_arr DB 0,0,0,0,0,0,0,0,0,0,'$' ; данные i DB 0, '$' ;индекс элемента массива команд j DB 0, '$' ;индекс элемента массива данных data ends stk segment stack db 100h dup (0) ; резервируем 256 ячеек stk ends end begin
Цикл работает так:
если текущий элемент строки str_arr не
то перепрыгиваем на метку next: (иначе выполняем )если текущий элемент строки str_arr не
то перепрыгиваем на метку next1:если текущий элемент строки str_arr не
то перепрыгиваем на метку next2:если текущий элемент строки str_arr не
то перепрыгиваем на метку next3:если текущий элемент строки str_arr не
то перепрыгиваем на метку next4:После метки next4: увеличиваем индекс строки str_arr и прыгаем в начало цикла — на метку prev:
Далее, добавим [ и ]
Добавим переменную i_stor.
Если текущий элемент прошёл проверку на [, то проверяем текущий элемент массива data_arr на ноль, и, если элемент равен нулю, перепрыгиваем дальше (на следующую метку), в противном случае загружаем в i_stor значение из переменной i.
next4: cmp DL, 5Bh ; ячейка содержит [ jne next5 ; нет, переходим на метку next5 mov BL, j mov DL, data_arr[BX] cmp DL, 00 ; да, проверяем текущий элемент data_arr на ноль jz next5 ; если ноль, прыгаем дальше mov DL, i ; иначе загружаем mov i_stor, Dl ; в i_stor значение переменной i next5:
При обработке закрывающей скобки ], если data_arr не ноль, то в переменную i из переменной i_stor загружаем адрес открывающей скобки [
next5: cmp DL, 5Dh ; ячейка содержит ] jne next6 ; нет, переходим на метку next6 mov BL, j mov DL, data_arr[BX] cmp DL, 00 ; да, проверяем текущий элемент data_arr на ноль jz next6 ; если ноль, прыгаем дальше mov DL, i_stor ; иначе загружаем mov i, Dl ; в i_stor значение переменной i next6:
Проверим код
text segment ; bf4.asm assume cs:text, ds:data, ss:stk begin: ;Подготовим все необходимое mov AX,data ; настраиваем сегмент данных mov DS,AX mov DL, str_arr ; загружаем в DL 1ую команду mov CX, 50h ; 80 тактов prev: cmp DL, 2Bh ; ячейка содержит + jne next ; нет, переходим на метку next mov BL, j ; загружаем в BL индекс данных inc data_arr[BX] ; да, увеличиваем значение в ячейке на 1 next: cmp DL, 2Dh ; ячейка содержит - jne next1 ; нет, переходим на метку next1 mov BL, j dec data_arr[BX] ;BX, но не Bl next1: cmp DL, 3Eh ; ячейка содержит > jne next2 ; нет, переходим на метку next2 inc j ; да, переходим на сдедующий элемент массива data_arr next2: cmp DL, 3Ch ; ячейка содержит < jne next3 ; нет, переходим на метку next3 dec j ; да, переходим на предыдущий элемент массива data_arr next3: cmp DL, 2Eh ; ячейка содержит . jne next4 ; нет, переходим на метку next4 mov AH,2 ; да, выводим содержимое ячейки mov BL, j mov DL, data_arr[BX] int 21h next4: cmp DL, 5Bh ; ячейка содержит [ jne next5 ; нет, переходим на метку next5 mov BL, j mov DL, data_arr[BX] cmp DL, 00 ; да, проверяем текущий элемент data_arr на ноль jz next5 ; если ноль, прыгаем дальше mov DL, i ; иначе загружаем mov i_stor, Dl ; в i_stor значение переменной i next5: cmp DL, 5Dh ; ячейка содержит ] jne next6 ; нет, переходим на метку next6 mov BL, j mov DL, data_arr[BX] cmp DL, 00 ; да, проверяем текущий элемент data_arr на ноль jz next6 ; если ноль, прыгаем дальше mov DL, i_stor ; иначе загружаем mov i, Dl ; в i_stor значение переменной i next6: inc i ; переходим к следующей команде mov BL, i mov DL, str_arr[BX] loop prev ; прыгаем на метку prev: mov AX, 4c00h ; завершение программы int 21h text ends data segment str_arr DB 2Bh,2Bh,2Bh,2Bh,5Bh, 3Eh,2Bh,3Ch,2Dh ,5Dh, '$' ; код ++++[>+<-] data_arr DB 0,0,0,0,0,0,0,0,0,0,'$' ; данные i DB 0,'$' ;индекс элемента массива команд j DB 0,'$' ;индекс элемента массива данных i_stor DB 0,'$' data ends stk segment stack db 100h dup (0) ; резервируем 256 ячеек stk ends end begin
Добавим функцию ввода строки 3fh прерывания 21h
mov ah, 3fh ; функция ввода mov cx, 100h ; 256 символов mov dx,OFFSET str_arr int 21h
Выходить из цикла будем по достижении конца строки '$'.
Для этого будем сравнивать текущий символ с символом '$'
cmp DL, 24h ; символ '$' je exit_loop
Заменим цикл loop командой jmp.
text segment assume cs:text,ds:data, ss: stk begin: ;Подготовим все необходимое mov AX,data ; настраиваем сегмент данных mov DS,AX ; функция ввода mov ah, 3fh mov cx, 100h ; 256 символов mov dx,OFFSET str_arr int 21h ; mov DL, str_arr ; загружаем в DL 1ую команду ;mov CX, 100h ; 256 тактов prev: cmp DL, 24h ; проверка на символ '$' je exit_loop cmp DL, 2Bh ; ячейка содержит + jne next ; нет, переходим на метку next mov BL, j ; загружаем в BL индекс данных inc data_arr[BX] ; да, увеличиваем значение в ячейке на 1 next: cmp DL, 2Dh ; ячейка содержит - jne next1 ; нет, переходим на метку next1 mov BL, j dec data_arr[BX] ;BX, но не Bl next1: cmp DL, 3Eh ; ячейка содержит > jne next2 ; нет, переходим на метку next2 inc j ; да, переходим на следующий элемент массива data_arr next2: cmp DL, 3Ch ; ячейка содержит < jne next3 ; нет, переходим на метку next3 dec j ; да, переходим на предыдущий элемент массива data_arr next3: cmp DL, 2Eh ; ячейка содержит . jne next4 ; нет, переходим на метку next4 mov AH,2 ; да, выводим содержимое ячейки mov BL, j mov DL, data_arr[BX] int 21h next4: cmp DL, 5Bh ; ячейка содержит [ jne next5 ; нет, переходим на метку next5 mov BL, j mov DL, data_arr[BX] cmp DL, 00 ; да, проверяем текущий элемент data_arr на ноль jz next5 ; если ноль, прыгаем дальше mov DL, i ; иначе загружаем mov i_stor, Dl ; в i_stor значение переменной i next5: cmp DL, 5Dh ; ячейка содержит ] jne next6 ; нет, переходим на метку next6 mov BL, j mov DL, data_arr[BX] cmp DL, 00 ; да, проверяем текущий элемент data_arr на ноль jz next6 ; если ноль, прыгаем дальше mov DL, i_stor ; иначе загружаем mov i, Dl ; в i_stor значение переменной i ; здесь должен быть переход на метку prev: next6: inc i ; переходим к следующей команде mov BL, i mov DL, str_arr[BX] ; loop prev ; прыгаем на метку prev: jmp prev exit_loop: MOV AH,2 ; переходим на новую строку MOV DL,0Ah INT 21h mov AX, 4c00h ; завершение программы int 21h text ends data segment str_arr DB 256h DUP('$') ; буфер на 256 символов data_arr DB 0,0,0,0,0,0,0,0,0,0,'$' ; данные i DB 0,'$' ;индекс элемента массива команд j DB 0,'$' ;индекс элемента массива данных i_stor DB 0,'$' data ends stk segment para stack db 100h dup (0) ; резервируем 256 ячеек stk ends end begin
В процессе компиляции получаем ошибку
Relative jump out of range by 0001h bytes
Дело в том, что команды je/jne могут перепрыгнуть только через несколько строчек программы (каждая строчка занимает в памяти от 1 до 5 байт).
Длинные переходы в конец программы je/jne совершать не могут.
Поэтому заменим выражение
cmp DL, 24h ; символ '$' je exit_loop ... exit_loop:
выражением
cmp DL, 24h ; символ '$' jne exit_ jmp exit_loop exit_ ... exit_loop:
Итак, если текущий символ соответствует $, то переходим на метку exit_loop: командой jmp, иначе перепрыгиваем через команду jmp.
На метку команда jmp может делать внутрисегментный относительный короткий переход (переход меньше 128 байт, т.е. IP:=IP+i8) или внутрисегментный относительный длинный переход (переход меньше 32767 байт, т.е. IP:=IP+i16).
По умолчанию команда jmp делает относительный длинный переход, что нам и надо (а вообще вместо этого можно просто добавить директиву jumps в начало программы).
;jumps text segment assume cs:text,ds:data, ss: stk begin: ;Подготовим все необходимое mov AX,data ; настраиваем сегмент данных mov DS,AX ;;; mov ah, 3fh ; функция ввода mov cx, 100h ; 256 символов mov dx,OFFSET str_arr int 21h ;;; mov DL, str_arr ; загружаем в DL 1ую команду ;mov CX, 100h ; 256 тактов prev: cmp DL, 24h ; символ '$' ;je exit_loop jne l1 jmp SHORT exit_loop l1: cmp DL, 2Bh ; ячейка содержит + jne next ; нет, переходим на метку next mov BL, j ; загружаем в BL индекс данных inc data_arr[BX] ; да, увеличиваем значение в ячейке на 1 next: cmp DL, 2Dh ; ячейка содержит - jne next1 ; нет, переходим на метку next1 mov BL, j dec data_arr[BX] ;BX, но не Bl next1: cmp DL, 3Eh ; ячейка содержит > jne next2 ; нет, переходим на метку next2 inc j ; да, переходим на следующий элемент массива data_arr next2: cmp DL, 3Ch ; ячейка содержит < jne next3 ; нет, переходим на метку next3 dec j ; да, переходим на предыдущий элемент массива data_arr next3: cmp DL, 2Eh ; ячейка содержит . jne next4 ; нет, переходим на метку next4 mov AH,2 ; да, выводим содержимое ячейки mov BL, j mov DL, data_arr[BX] int 21h next4: cmp DL, 5Bh ; ячейка содержит [ jne next5 ; нет, переходим на метку next5 mov BL, j mov DL, data_arr[BX] cmp DL, 00 ; да, проверяем текущий элемент data_arr на ноль jz next5 ; если ноль, прыгаем дальше mov DL, i ; иначе загружаем mov i_stor, Dl ; в i_stor значение переменной i next5: cmp DL, 5Dh ; ячейка содержит ] jne next6 ; нет, переходим на метку next6 mov BL, j mov DL, data_arr[BX] cmp DL, 00 ; да, проверяем текущий элемент data_arr на ноль jz next6 ; если ноль, прыгаем дальше mov DL, i_stor ; иначе загружаем mov i, Dl ; в i_stor значение переменной i ; здесь должен быть переход на метку prev: next6: inc i ; переходим к следующей команде mov BL, i mov DL, str_arr[BX] ; loop prev ; прыгаем на метку prev: jmp prev exit_loop: MOV AH,2 ; переходим на новую строку MOV DL,0Ah INT 21h mov AX, 4c00h ; завершение программы int 21h text ends data segment str_arr DB 256h DUP('$') ; буфер на 256 символов data_arr DB 0,0,0,0,0,0,0,0,0,0,'$' ; данные i DB 0,'$' ;индекс элемента массива команд j DB 0,'$' ;индекс элемента массива данных i_stor DB 0,'$' data ends stk segment para stack db 100h dup (0) ; резервируем 256 ячеек stk ends end begin
Вывод на экран.
Добавим вывод массива data_arr (ленту машины Тьюринга) на экран.
Напишем программу, выводящую на экран элементы произвольного массива посредством функции 09h прерывания 21h
.model tiny ; ascii-decoder.asm jumps .data data_arr DB 1,0,2,0,3,0,4,0,5,0,6,0,7,'$' ; данные .code ORG 100h start: ;Подготовим все необходимое mov AX, @data ; настраиваем сегмент данных mov DS,AX ;;;;;;;;;;;;;;;; MOV AH,2 ; переходим на новую строку MOV DL,0Ah INT 21h mov dx,offset data_arr ; указатель на массив символов mov ah,09h ; вывести строку int 21h ;;;;;;;;;; MOV AH,2 ; переходим на новую строку MOV DL,0Ah INT 21h mov AX, 4c00h ; завершение программы int 21h end start
На экране мы увидим ascii-коды элементов массива data_arr DB 1,0,2,0,3,0,4,0,5,0,6,0,7,'$'
Для того, чтобы представить элементы массива в виде чисел, будем использовать опрератор div.
Команда div ЧИСЛО делит регистр AX на ЧИСЛО и помещает целую часть от деления в AL, а остаток от деления в AH (ЧИСЛОМ может быть либо область памяти, либо регистр общего назначения)
Выведем 1ый и 2ой элементы массива
.model tiny ; ascii-decoder.asm jumps .data data_arr DB 10,12,0,0,0,0,0,0,0,0,'$' ; данные .code ORG 100h start: ;Подготовим все необходимое mov AX, @data ; настраиваем сегмент данных mov DS,AX ;;;;;;;;;;;;;;;; MOV AH,2 ; переходим на новую строку MOV DL,0Ah INT 21h ;mov dx,offset data_arr ; указатель на массив символов ;mov ah,09h ; вывести строку ;int 21h ;;выводим перое число sub AH, AH ; обнуляем AH mov AL, data_arr ; делимое mov BL, 10 ; делитель div BL ; теперь в AL=десятки, в AH=единицы mov BX,AX add BX,3030h mov AH,2 ; функция вывода символа прерывания 21h mov DL,BL ; выводим старший разряд int 21h mov DL, BH ; выводим младший разряд int 21h ;выводим второе число sub AH, AH ; обнуляем AH mov AL, data_arr+1 ; делимое mov BL, 10 ; делитель div BL ; теперь в AL=десятки, в AH=единицы mov BX,AX add BX,3030h mov AH,2 ; функция вывода символа прерывания 21h mov DL,BL ; выводим старший разряд int 21h mov DL, BH ; выводим младший разряд int 21h ;;;;;;;;;; MOV AH,2 ; переходим на новую строку MOV DL,0Ah INT 21h mov AX, 4c00h ; завершение программы int 21h end start
Для того, чтобы вывести все элементы массива, будем использовать команду loop.
Поместим в регистр CX количество тактов, равное количеству элементов массива и на каждом такте будем прибавлять единицу к индексу массива i.
.model tiny ; ascii-decoder1.asm jumps .data data_arr DB 3,5,6,7,0,11,12,13,0,20,'$' ; данные i DB 0,'$' .code ORG 100h start: ;Подготовим все необходимое mov AX, @data ; настраиваем сегмент данных mov DS,AX ;;;;;;;;;;;;;;;; MOV AH,2 ; переходим на новую строку MOV DL,0Ah INT 21h ;mov dx,offset data_arr ; указатель на массив символов ;mov ah,09h ; вывести строку ;int 21h mov CX, 0Ah _prev: ;;выводим число ; mov BL,i sub AH, AH ; обнуляем AH mov AL, data_arr[BX] ; делимое mov BL, 10 ; делитель div BL ; теперь в AL=десятки, в AH=единицы mov BX,AX add BX,3030h mov AH,2 ; функция вывода символа прерывания 21h mov DL,BL ; выводим старший разряд int 21h mov DL, BH ; выводим младший разряд int 21h ; выводим пустой символ sub DL, DL int 21h ;;; sub BX,BX inc i ; увеличиваем счётчик mov BL, i loop _prev ;;;;;;;;;; MOV AH,2 ; переходим на новую строку MOV DL,0Ah INT 21h mov AX, 4c00h ; завершение программы int 21h end start
Далее, добавим цикл, отображающий элементы массива в виде чисел, в основную программу.
.model tiny jumps .data str_arr DB 256h DUP('$') data_arr DB 0,0,0,0,0,0,0,0,0,0,'$' i DB 0,'$' j DB 0,'$' i_stor DB 0,'$' .code ORG 100h start: mov AX, @data mov DS,AX ;;; mov ah, 3fh mov cx, 100h mov dx,OFFSET str_arr int 21h ;;; mov DL, str_arr prev: cmp DL, 24h je exit_loop cmp DL, 2Bh jne next mov BL, j inc data_arr[BX] next: cmp DL, 2Dh jne next1 mov BL, j dec data_arr[BX] next1: cmp DL, 3Eh jne next2 inc j next2: cmp DL, 3Ch jne next3 dec j next3: cmp DL, 2Eh jne next4 mov AH,2 mov BL, j mov DL, data_arr[BX] int 21h next4: cmp DL, 5Bh jne next5 ;mov BL, j ;mov DL, data_arr[BX] ;cmp DL, 00 ;jz next5 mov DL, i mov i_stor, Dl next5: cmp DL, 5Dh jne next6 mov BL, j mov DL, data_arr[BX] cmp DL, 00 jz next6 mov DL, i_stor mov i, DL next6: inc i mov BL, i mov DL, str_arr[BX] ; loop prev jmp prev exit_loop: ;;;;;;;;;;;;;;;; MOV AH,2 ; новая строка MOV DL,0Ah ; новая строка INT 21h ; новая строка ; output data_arr mov CX, 0Ah ; 10 тактов sub AL,AL ; обнуляем AL mov i, AL ; обнуляем счётчик sub BX,BX ; обнуляем BX _prev: ; incorrect 1st element sub AH, AH ; обнуляем AH mov AL, data_arr[BX] ; делимое ;mov AL, data_arr+1 mov BL, 10 ; делитель div BL ; частное AL=десятки и AH=единицы mov BX,AX add BX,3030h mov AH,2 ; функция вывода 2 прерывания 21h mov DL,BL ; выводим десятки int 21h mov DL, BH ; выводим единицы int 21h ; выводим пробел (пустой символ) sub DL, DL int 21h ;;; sub BX,BX inc i ; увеличиваем индекс массива mov BL, i loop _prev ;;;;;;;;;; MOV AH,2 ; новая строка MOV DL,0Ah ; новая строка INT 21h ; новая строка mov AX, 4c00h ; завершение программы int 21h end start
Теперь HelloWorld выглядит так
Поскольку мы не обрабатываем числа больше 99, то число 100 отображается некорректно, остальные числа отображаются корректно.
Вложенные скобки
Для обработки вложенных скобок будем открывающие скобки помещать в стэк, а закрывающие извлекать из стека.
Напишем простую программу работы со стеком на Паскале.
var a : array[1..10] of integer; size : integer; procedure push(c : integer); begin size := size + 1; a[size] := c; end; procedure pop; begin size := size - 1; end; begin size := 0; Push(1); writeln(a[size]); Push(2); writeln(a[size]); Push(3); writeln(a[size]); Pop(); writeln(a[size]); Pop(); writeln(a[size]); end.
Взял отсюда.
Проверить можно здесь или здесь.
Изменим процедуру push так, чтобы при size равном нулю мы получали ссылку на первый элемент.
procedure push(c : integer); begin a[size+1] := c; size := size + 1; end;
Добавим «стэк» в основную программу.
Program bf5_stack; LABEL prev,next; var a : array[1..10] of integer; size : integer; data_arr:array[1..10] of integer; // массив данных str_arr: string; // команды i,j,k: integer; // индексы строки и массива i_stor: integer; //Stack procedure push(c : integer); begin a[size+1] := c; size := size + 1; end; procedure pop; begin size := size - 1; end; {---------------------------------------------------} begin j:=1; // нумерация элементов массива начинается с единицы i:=1; size := 0; {Изначально стек пуст} //readln(str_arr); //считываем строку //str_arr:='+++[>+++[>+<-]<-]'; // 3*3=9 str_arr:='+++[> +++[>+++[>+<-]<-] <-]'; //3^3=27; prev: if i>length(str_arr) then goto next; if (str_arr[i]='+') then data_arr[j]:= data_arr[j]+1; if (str_arr[i]='-') then data_arr[j]:= data_arr[j]-1; if (str_arr[i]='>') then j:=j+1; if (str_arr[i]='<') then j:=j-1; if (str_arr[i]='.') then write(chr(data_arr[j])); // скобки if (str_arr[i]='[') then Push(i); if (str_arr[i]=']') then begin Pop(); if (data_arr[j]>0) then begin i := a[size+1]; goto prev; end; end; i:=i+1; goto prev; next: for k:=1 to 10 do begin write(data_arr[k]); write(' '); end; end.
ideone.com
Если мы встречаем открывающую скобку, то просто помещаем её адрес в стэк, когда мы встречаем закрывающую скобку, то извлекаем её адрес из стека, если при этом значение в текущей ячейке больше нуля, то возвращаемся на открывающую скобку.
Пример использования нормального/«стандартного» стэка показан в программе bf51_stack.pas
«Добавим» стэк к основной ассемблерной программе
.model tiny ; bf7_stack_decoder.asm jumps .data str_arr DB 256h DUP('$') ; буфер на 256 символов data_arr DB 0,0,0,0,0,0,0,0,0,0,'$' ; данные i DB 0,'$' ;индекс элемента массива команд j DB 0,'$' ;индекс элемента массива данных i_stor DB 0,'$' .code ORG 100h start: ;Подготовим все необходимое mov AX,@data ; настраиваем сегмент данных mov DS,AX ;;; mov ah, 3fh ; функция ввода mov cx, 100h ; 256 символов mov dx,OFFSET str_arr int 21h ;;; mov DL, str_arr ; загружаем в DL 1ую команду ;mov CX, 100h ; 256 тактов prev: cmp DL, 24h ; символ '$' je exit_loop cmp DL, 2Bh ; ячейка содержит + jne next ; нет, переходим на метку next mov BL, j ; загружаем в BL индекс данных inc data_arr[BX] ; да, увеличиваем значение в ячейке на 1 next: cmp DL, 2Dh ; ячейка содержит - jne next1 ; нет, переходим на метку next1 mov BL, j dec data_arr[BX] ;BX, но не Bl next1: cmp DL, 3Eh ; ячейка содержит > jne next2 ; нет, переходим на метку next2 inc j ; да, переходим на следующий элемент массива data_arr next2: cmp DL, 3Ch ; ячейка содержит < jne next3 ; нет, переходим на метку next3 dec j ; да, переходим на предыдущий элемент массива data_arr next3: cmp DL, 2Eh ; ячейка содержит . jne next4 ; нет, переходим на метку next4 mov AH,2 ; да, выводим содержимое ячейки mov BL, j mov DL, data_arr[BX] int 21h next4: cmp DL, 5Bh ; ячейка содержит [ jne next5 ; нет, переходим на метку next5 ;sub DX,DX mov AL, i ; иначе загружаем push AX next5: cmp DL, 5Dh ; ячейка содержит ] jne next6 ; нет, переходим на метку next6 sub AX,AX pop AX mov BL, j mov DL, data_arr[BX] cmp DL, 00 ; да, проверяем текущий элемент data_arr на ноль jz next6 ; если ноль, прыгаем дальше mov i, AL ; в i_stor значение переменной i mov BL, i mov DL, str_arr[BX] jmp prev next6: inc i ; переходим к следующей команде mov BL, i mov DL, str_arr[BX] jmp prev exit_loop: ;Выод ascii-символов чисел MOV AH,2 ; новая строка MOV DL,0Ah ; новая строка INT 21h ; новая строка ; output data_arr mov CX, 0Ah ; 10 тактов sub AL,AL ; обнуляем AL mov i, AL ; обнуляем счётчик sub BX,BX ; обнуляем BX _prev: ; incorrect 1st element sub AH, AH ; обнуляем AH mov AL, data_arr[BX] ; делимое ;mov AL, data_arr+1 mov BL, 10 ; делитель div BL ; частное AL=десятки и AH=единицы mov BX,AX add BX,3030h mov AH,2 ; функция вывода 2 прерывания 21h mov DL,BL ; выводим десятки int 21h mov DL, BH ; выводим единицы int 21h ; выводим пробел (пустой символ) sub DL, DL int 21h ;;; sub BX,BX inc i ; увеличиваем индекс массива mov BL, i loop _prev ;;;;;;;;;; MOV AH,2 ; новая строка MOV DL,0Ah ; новая строка INT 21h ; новая строка ;;;;;;;;;;;;;;; mov AX, 4c00h ; завершение программы int 21h END start
Ссылка на github с листингами программ.

