TL;DR: GitHub://PastorGL/AQLSelectEx.
Однажды, ещё не в студёную, но уже зимнюю пору, а конкретно пару месяцев назад, для проекта, над которым я работаю (нечто Geospatial на основе Big Data), потребовалось быстрое NoSQL / Key-Value хранилище.
Терабайты исходников мы вполне успешно прожёвываем при помощи Apache Spark, но схлопнутый до смешного объёма (всего лишь миллионы записей) конечный результат расчётов надо где-то хранить. И очень желательно хранить таким образом, чтобы его можно было по ассоциированным с каждой строкой результата (это одна цифра) метаданным (а вот их довольно много) быстро найти и отдать наружу.
Форматы хадуповского стека в этом смысле малопригодны, а реляционные БД на миллионах записей тормозят, да и набор метаданных не столь фиксированный, чтобы хорошо ложиться в жёсткую схему обычной РСУБД — PostgreSQL в нашем случае. Нет, она нормально поддерживает JSON, но с индексами у неё на миллионах записей всё равно проблемы. Индексы пухнут, таблицу становится надо партиционировать, и начинается такая морока с администрированием, что нафиг-нафиг.
Исторически в качестве NoSQL на проекте использовали MongoDB, но монга со временем показывает себя всё хуже и хуже (особенно в плане стабильности), поэтому постепенно вывели из эксплуатации. Быстрый же поиск более современной, быстрой, менее глючной, и вообще лучшей альтернативы привёл к Aerospike. У многих бигдатнутых ребят она в фаворе, и я решил проверить.
Тесты показали, что, действительно, сохраняются данные в сторидж прямиком из спарковского джоба со свистом, а поиск по многим миллионам записей происходит заметно быстрее, чем в монге. Да и памяти она ест поменьше. Но выяснилось одно «но». Клиентское API у аэроспайка — сугубо функциональное, а не декларативное.
Для записи в сторидж это не важно, потому что всё равно все типы полей каждой результирующей записи приходится по месту в самом джобе определять — и контекст не теряется. Функциональный стиль тут к месту, тем более что под спарк по-другому писать код и не выйдет. А вот в веб-морде, которая должна выгружать результат во внешний мир, и является обычным веб-приложением на спринге, уже куда логичнее было бы из пользовательской формочки формировать стандартный SQL SELECT, в котором было бы полным полно AND и OR — сиречь, предикатов, — в условии WHERE.
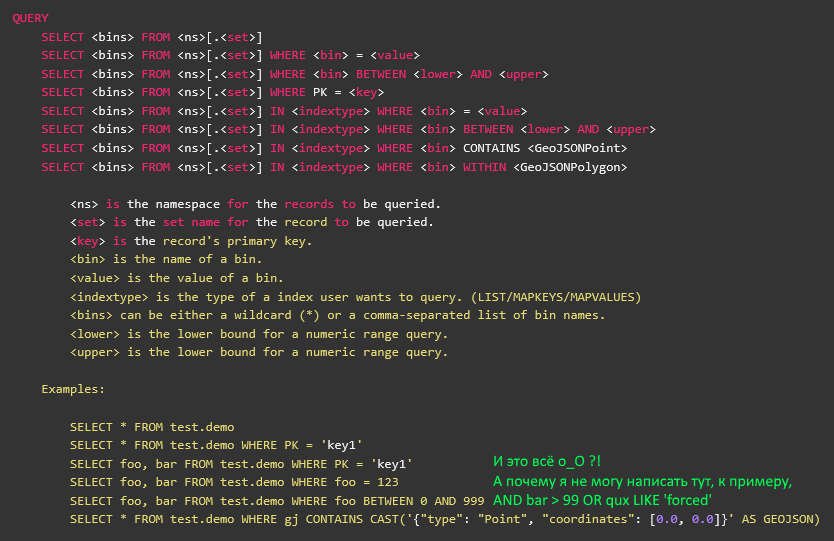
Поясню разницу на таком синтетическом примере:
SELECT foo, bar, baz, qux, quux FROM namespace.set WITH (baz!='a') WHERE (foo>2 AND (bar<=3 OR foo>5) AND quux LIKE '%force%') OR NOT (qux WITHIN CAST('{\"type\": \"Polygon\", \"coordinates\": [0.0, 0.0],[1.0, 0.0],[1.0, 1.0],[0.0, 1.0],[0.0, 0.0]}' AS GEOJSON)
— это и читаемо, и относительно понятно, какие записи хотел получить кастомер. Если такой запрос кинуть в лог прям как есть, его потом и для отладки вручную дёрнуть можно будет. Что очень удобно при разборе всяких странных ситуаций.
А теперь посмотрим на обращение к предикатному API в функциональном стиле:
Statement reference = new Statement(); reference.setSetName("set"); reference.setNamespace("namespace"); reference.setBinNames("foo", "bar", "baz", "qux", "quux"); reference.setFillter(Filter.stringNotEqual("baz", "a")); reference.setPredExp(// 20 expressions in RPN PredExp.integerBin("foo") , PredExp.integerValue(2) , PredExp.integerGreater() , PredExp.integerBin("bar") , PredExp.integerValue(3) , PredExp.integerLessEq() , PredExp.integerBin("foo") , PredExp.integerValue(5) , PredExp.integerGreater() , PredExp.or(2) , PredExp.and(2) , PredExp.stringBin("quux") , PredExp.stringValue(".*force.*") , PredExp.stringRegex(RegexFlag.ICASE) , PredExp.and(2) , PredExp.geoJSONBin("qux") , PredExp.geoJSONValue("{\"type\": \"Polygon\", \"coordinates\": [0.0, 0.0],[1.0, 0.0],[1.0, 1.0],[0.0, 1.0],[0.0, 0.0]}") , PredExp.geoJSONWithin() , PredExp.not() , PredExp.or(2) );
Вот же стена кода, да ещё и в обратной польской нотации. Нет, я всё понимаю, что стековая машина проста и удобна для реализации с точки зрения программиста самого движка, но ломать голову и писать предикаты в RPN из клиентского приложения… Я лично не хочу думать за вендора, я хочу чтобы мне, как потребителю этого API, было удобно. А предикаты даже с вендорским расширением клиента (концептуально похожим на Java Persistence Criteria API) писать неудобно. И по-прежнему нету читаемого SELECT в логе запросов.
Вообще, SQL и был придуман для того, чтобы писать на нём критериальные запросы на птичьем языке, приближенном к естественному. Так, спрашивается, какого лешего?
Погодите, что-то тут не то… На КДПВ же скриншот из официальной документации аэроспайка, на котором вполне себе описан SELECT?
Да, описан. Вот только AQL — это сторонняя утилита, написанная задней левой ногой в тёмную ночь, и заброшенная вендором три года назад во времена предыдущей версии аэроспайка. Никакого отношения к клиентской библиотеке она не имеет, хоть и писана на жабе — в том числе.
Версия трёхлетней давности не имела предикатного API, и потому в AQL нет поддержки предикатов, а всё, что после WHERE — это на самом деле обращение к индексу (вторичному или первичному). Ну, то бишь, ближе к расширению SQL типа USE или WITH. То есть, нельзя просто так взять исходники AQL, разобрать на запчасти, и использовать в своём приложении для предикатных вызовов.
Вдобавок, как я уже сказал, писана она в тёмную ночь задней левой ногой, и на ANTLR4 грамматику, которой AQL парсит запрос, без слёз смотреть невозможно. Ну, на мой вкус. Я почему-то люблю, когда декларативное определение грамматики не перемешано с кусками жабного кода, а там заварена весьма крутая лапша.
Что ж, к счастью, я тоже вроде как умею в ANTLR. Правда, давно уже не брал в руки шашку, и последний раз писал ещё под третью версию. Четвёртая — она намного приятнее, потому что кому захочется писать ручной обход AST, если всё написали до нас, и в наличии имеется нормальный визитор, потому приступим.
В качестве базы возьмём синтаксис SQLite, и попробуем выкинуть всё ненужное. Нам требуется только SELECT, и ничего более.
grammar SQLite; simple_select_stmt : ( K_WITH K_RECURSIVE? common_table_expression ( ',' common_table_expression )* )? select_core ( K_ORDER K_BY ordering_term ( ',' ordering_term )* )? ( K_LIMIT expr ( ( K_OFFSET | ',' ) expr )? )? ; select_core : K_SELECT ( K_DISTINCT | K_ALL )? result_column ( ',' result_column )* ( K_FROM ( table_or_subquery ( ',' table_or_subquery )* | join_clause ) )? ( K_WHERE expr )? ( K_GROUP K_BY expr ( ',' expr )* ( K_HAVING expr )? )? | K_VALUES '(' expr ( ',' expr )* ')' ( ',' '(' expr ( ',' expr )* ')' )* ; expr : literal_value | BIND_PARAMETER | ( ( database_name '.' )? table_name '.' )? column_name | unary_operator expr | expr '||' expr | expr ( '*' | '/' | '%' ) expr | expr ( '+' | '-' ) expr | expr ( '<<' | '>>' | '&' | '|' ) expr | expr ( '<' | '<=' | '>' | '>=' ) expr | expr ( '=' | '==' | '!=' | '<>' | K_IS | K_IS K_NOT | K_IN | K_LIKE | K_GLOB | K_MATCH | K_REGEXP ) expr | expr K_AND expr | expr K_OR expr | function_name '(' ( K_DISTINCT? expr ( ',' expr )* | '*' )? ')' | '(' expr ')' | K_CAST '(' expr K_AS type_name ')' | expr K_COLLATE collation_name | expr K_NOT? ( K_LIKE | K_GLOB | K_REGEXP | K_MATCH ) expr ( K_ESCAPE expr )? | expr ( K_ISNULL | K_NOTNULL | K_NOT K_NULL ) | expr K_IS K_NOT? expr | expr K_NOT? K_BETWEEN expr K_AND expr | expr K_NOT? K_IN ( '(' ( select_stmt | expr ( ',' expr )* )? ')' | ( database_name '.' )? table_name ) | ( ( K_NOT )? K_EXISTS )? '(' select_stmt ')' | K_CASE expr? ( K_WHEN expr K_THEN expr )+ ( K_ELSE expr )? K_END | raise_function ;
Хмм… Таки и в одном только SELECT многовато лишнего. И если от лишнего избавиться достаточно просто, то есть и ещё одна нехорошая вещь относительно самой структуры получающегося пути обхода.
Конечная цель — оттранслироваться в предикатное API с его RPN и подразумеваемой стековой машиной. А тут атомарное expr никак не способствует подобному преобразованию, потому что подразумевает обычный разбор слева направо. Да ещё и рекурсивно определённое.
То бишь, получить наш синтетический пример мы можем, но читаться он будет именно как написан, слева направо:
(foo>2 И (bar<=3 ИЛИ foo>5) И quux ПОХОЖ_НА '%force%') ИЛИ НЕ(qux В_ПОЛИГОНЕ('{\"type\": \"Polygon\", \"coordinates\": [0.0, 0.0],[1.0, 0.0],[1.0, 1.0],[0.0, 1.0],[0.0, 0.0]}')
В наличии скобочки, определяющие приоритет разбора (значит, потребуется мотаться туда-сюда по стеку), а также некоторые операторы ведут себя как вызовы функций.
А нужна нам такая вот последовательность:
foo 2 > bar 3 <= foo 5 > ИЛИ И quux ".*force.*" ПОХОЖ_НА И qux "{\"type\": \"Polygon\", \"coordinates\": [0.0, 0.0],[1.0, 0.0],[1.0, 1.0],[0.0, 1.0],[0.0, 0.0]}" В_ПОЛИГОНЕ НЕ ИЛИ
Брр, жесть, бедный мозг, которым такое читать. Зато без скобок, нет никаких роллбэков и непоняток с порядком вызова. И как нам перевести одно в другое?
И тут в бедном мозге происходит чпок! — здрасте, это же классический Shunting Yard от многоув. проф. Дейкстры! Обычно, таким околобигдатовским шаманам, как я, алгоритмы не нужны, потому что мы просто переводим уже написанные дата-сатанистами прототипы с питона на жабу, и потом долго и нудно тюним перфоманс полученного решения чисто инженерными (== шаманскими) методами, а не научными.
Но тут вдруг стало нужно и знание алгоритма. Или хотя бы представление об оном. К счастью, не весь университетский курс был за прошедшие годы забыт, и коли уж я помню про стековые машины, то и про связанную с ними алгоритмику тоже что-то ещё могу раскопать.
Окей. В грамматике, заточенной под Shunting Yard, SELECT на верхнем уровне будет выглядеть так:
select_stmt : K_SELECT ( STAR | column_name ( COMMA column_name )* ) ( K_FROM from_set )? ( (K_USE | K_WITH) index_expr )? ( K_WHERE where_expr )? ; where_expr : ( atomic_expr | OPEN_PAR | CLOSE_PAR | logic_op )+ ; logic_op : K_NOT | K_AND | K_OR ; atomic_expr : column_name ( equality_op | regex_op ) STRING_LITERAL | ( column_name | meta_name ) ( equality_op | comparison_op ) NUMERIC_LITERAL | column_name map_op iter_expr | column_name list_op iter_expr | column_name geo_op cast_expr ;
То бишь, токены, соответствующие скобкам — значимые, а рекурсивного expr быть не должно. Вместо него будет куча всяких частных чё_нибудь_expr, и все — конечные.
В коде на жабе, который имплементирует визитор для этого дерева, дела обстоят чуточку более по-наркомански — в строгом соответствии с алгоритмом, который сам обрабатывает висящие logic_op и балансирует скобки. Приводить выдержку я не буду (посмотрите на ГХ самостоятельно), но приведу следующее соображение.
Становится понятно, почему авторы аэроспайка не стали заморачиваться поддержкой предикатов в AQL, и забросили его три года назад. Потому что оно строго типизированное, а сам аэроспайк преподносится как schema-less сторидж. И вот так просто взять и распотрошить запрос из голого SQL без заранее заданной схемы нельзя. Упс.
Но мы-то ребята прожжённые, а, главное, наглые. Нужна схема с типами полей, значит будет схема с типами полей. Тем более, что в клиентской библиотеке уже есть все нужные определения, просто их надо подцепить. Хотя кода понаписать под каждый тип пришлось немало (см. по той же ссылке, с 56 строки).
Теперь же инициализируемся...
final HashMap FOO_BAR_BAZ = new HashMap() {{ put("namespace.set0", new HashMap() {{ put("foo", ParticleType.INTEGER); put("bar", ParticleType.DOUBLE); put("baz", ParticleType.STRING); put("qux", ParticleType.GEOJSON); put("quux", ParticleType.STRING); put("quuux", ParticleType.LIST); put("corge", ParticleType.MAP); put("corge.uier", ParticleType.INTEGER); }}); put("namespace.set1", new HashMap() {{ put("grault", ParticleType.INTEGER); put("garply", ParticleType.STRING); }}); }}; AQLSelectEx selectEx = AQLSelectEx.forSchema(FOO_BAR_BAZ);
… и вуаля, теперь наш синтетический запрос просто и понятно дёргается из аэроспайка:
Statement statement = selectEx.fromString("SELECT foo,bar,baz,qux,quux FROM namespace.set WITH (baz='a') WHERE (foo>2 AND (bar <=3 OR foo>5) AND quux LIKE '%force%') OR NOT (qux WITHIN CAST('{\"type\": \"Polygon\", \"coordinates\": [0.0, 0.0],[1.0, 0.0],[1.0, 1.0],[0.0, 1.0],[0.0, 0.0]}' AS GEOJSON)");
А уж для преобразования формочки с веб-морды в сам запрос мы заюзаем давно написанную в веб-морде тонну кода… когда до проекта дойдёт наконец дело, а то заказчик пока что отложил его на полку. Обидно, блин, почти неделю времени потратил.
Надеюсь, потратил я его с пользой, и библиотечка AQLSelectEx окажется кому-нибудь нужна, а сам подход — чуть более приближенным к реальности учебным пособием, чем другие статьи с хабра, посвящённые ANTLR.

