
Как-то я прочитал на Хабре статью про настройку BGP на роутере. Инструкции оттуда можно использовать для настройки домашнего роутера так, чтобы трафик на определённые IP-адреса шёл через другой канал. Однако здесь есть проблема: список IP-адресов может быть очень большим.
В этот граф, помимо сетей из списка, добавлены ещё и наибольшие общие подсети соседних сетей. О том, зачем это нужно, читайте далее.

Так выглядело дерево сетей от Роскомнадзора в мае 2018 года.
Сначала я попробовал добавить весь список через /ip route add в мой MikroTik hAP ac lite — на роутере кончилось место на диске. Затем загрузил через BGP все адреса в память — роутер немного поработал и завис. Стало очевидно, что список нужно урезать.
В статье упоминается утилита network-list-parser от хабраюзера Unsacrificed. Она делает то, что мне нужно, но увидел я её уже после того, как начал изобретать свой велосипед. Потом уже доделывал из интереса, потому как то, что у меня получилось, работает качественнее, хоть и существенно медленнее.
Итак, постановка задачи: нужно написать скрипт, который принимает на вход список IP-адресов и сетей и укорачивает его до указанного размера. При этом новый список должен охватывать все адреса из старого, а количество новых адресов, вынужденно в него добавленных, должно быть минимальным.
Начнём с построения графа всех исходных сетей (то, что на картинке выше). Корневым узлом будет сеть 0.0.0.0/0. При добавлении новой подсети A находим в дереве подсеть B, чтобы A и B находились в подсети C и при этом размер подсети C был минимальным (маска максимальной). Другими словами, количество общих битов подсетей A и B должно быть максимальным. Добавляем эту общую подсеть в дерево, а внутрь переносим подсети A и B. Наверное, это можно назвать бинарным деревом.
Например, построим дерево из двух подсетей (192.168.0.1/32 и 192.168.33.0/24):

Получим дерево:

Если сюда добавить, скажем, сеть 192.168.150.150/32, тогда, дерево будет выглядеть так:

Оранжевым тут отмечены общие подсети, добавленные при построении дерева. Именно эти общие подсети мы и будем «схлопывать» для уменьшения размера списка. Например, если схлопнуть узел 192.168.0.0/16, тогда мы уменьшим размер списка сетей на 2 (было 3 сети из исходного списка, стала 1), но при этом дополнительно охватим 65536-1-1-256=65278 IP-адреса, которые не входили в наш исходный список.
Удобно для каждого узла рассчитать «коэффициент выгоды от схлопывания», показывающий количество IP-адресов, которые будут дополнительно добавлены на каждую из удалённых из списка записей:
weight_reversed = net_extra_ip_volume / (in_list_records_count - 1)
Мы будем использовать weight = 1 / weight_reversed, т.к. это удобнее. Любопытно, что вес может быть равен бесконечности, если, к примеру, в списке есть две сети /32, которые вместе составляют одну большую сеть /31.
Таким образом, чем больше weight, тем выгоднее такую сеть схлопнуть.
Теперь можно посчитать вес для всех узлов в сети, отсортировать узлы по весу и схлопывать подсети до тех пор, пока не получим нужный нам размер списка. Однако тут есть сложность: в тот момент, когда мы схлопываем какую-нибудь сеть, меняются веса всех родительских сетей.
Например, у нас есть дерево с рассчитанными весами:

Схлопнем подсеть 192.168.0.0/30:
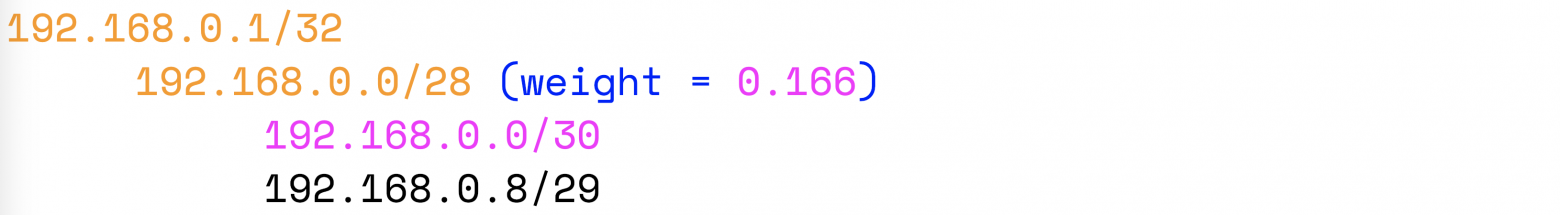
Вес родительского узла уменьшился. Если в дереве есть узлы с весом больше, чем 0.166, то следующими следует схлопывать уже их.
В итоге сжатие списка приходится выполнять рекурсивно. Алгоритм примерно такой:
- Рассчитываем веса для всех узлов.
- Для каждого узла храним максимальный вес дочернего узла (Wmax).
- Получается, что Wmax корневого узла — это максимальный вес узла во всём дереве (может быть несколько узлов с весом, равным Wmax).
- Рекурсивно сжимаем все сети с весом, равным Wmax корневого узла. При этом пересчитываем веса. Возвращаемся в корневой узел.
- Wmax корневого узла уменьшился — выполняем п.4 до тех пор, пока не получим нужный размер списка сетей.
Интереснее всего наблюдать за алгоритмом в движении. Вот пример для списка сетей:
192.168.0.1
192.168.0.2
192.168.0.8/29
192.168.150.1
192.168.150.2
192.168.150.8/29
192.168.20.1
192.168.20.2
192.168.20.3
192.168.20.4
192.168.20.5
192.168.20.6
192.168.20.7Тут одинаковые по структуре подсети 192.168.0.0/24 и 192.168.150.0/24 — так лучше видно, как при сжатии алгоритм перепрыгивает из одной ветки в другую. Подсеть 192.168.20.0/24 добавил для того, чтобы показать, что иногда выгоднее сжимать родительскую сеть, чем дочернюю. Обратите внимание на подсеть 192.168.20.0/30: после заполнения дерева её вес меньше, чем у родительской подсети.
Заполнение дерева:

Тут чёрный шрифт — настоящие сети из исходного списка. Жёлтый — добавленные сети. Синий — вес узла. Красный — текущая сеть. Розовый — схлопнутая сеть.
Сжатие:

Была мысль ускорить алгоритм схлопывания сетей: для этого не обязательно на каждой итерации схлопывать только сети с максимальным весом. Можно заранее подобрать значение веса, которое даст нам список нужного размера. Подобрать можно бинарным поиском, т.е. сжимать с определённым весом и смотреть, какой размер списка получается на выходе. Правда, для этого нужно в два раза больше памяти и переписывать код — у меня попросту не дошли руки.
Теперь осталось сравнить с network-list-parser из статьи про BGP.
Плюсы моего скрипта:
- Удобнее настройка: достаточно указать требуемый размер списка сетей, и на выходе будет список именно такого размера. У network-list-parser множество ручек, и нужно подобрать их сочетание.
- Степень сжатия адаптируется к исходному списку. Если из списка убрать какие-то сети, то мы получим меньше дополнительных адресов, если добавить — больше. При этом размер результирующего списка будет постоянным. Можно подобрать максимальный размер, который способен обработать роутер, и не беспокоиться о том, что в какой-то момент список станет слишком большим.
- Полученный список содержит минимально возможное количество дополнительных сетей. На тестовом списке из GitHub мой алгоритм дал 718479 дополнительных IP-адреса, а network-list-parser — 798761. Разница всего 10%.
Как я это рассчитал? Смотрим1. Запускаем
./network-list-parser-darwin-386-1.2.bin -src-file real_net_list_example.txt -dst-file parsed.txt -aggregation-max-fake-ips 0 -intensive-aggregation-min-prefix 31 2>&1
и получаем очищенный список без мусора и частично уменьшенный. Сравнивать буду качество сжатия parsed.txt. (без этого шага были проблемы с оценкой того, сколько фейковых IP добавляет network-list-parser).
2. Запускаем
./network-list-parser-darwin-386-1.2.bin -src-file parsed.txt -dst-file parsed1.txt 2>&1
и получаем сжатый список, смотрим вывод, там есть строчка “Add 7.3% IPs coverage (798761).”
В файле parsed1.txt 16649 записей.
3. Запускаем
python3 minimize_net_list.py parsed.txt 16649.
Видим строчку ### not real ips: 718479.
У получившегося скрипта я вижу только один недостаток: он долго работает и требует много памяти. На моём MacBook список жмётся 5 секунд. На Raspberry — полторы минуты. С РyРy3 на Маке быстрее, на Raspberry PyPy3 поставить не смог. Network-list-parser летает и там, и там.
В целом эту схему имеет смысл использовать только перфекционистам, т.к. все остальные тратить столько вычислительных ресурсов ради 10% сэкономленных сетей вряд ли будут. Ну и немного удобнее, да.
Ссылка на проект в GitHub
Запускать так:
python3 minimize_net_list.py real_net_list_example.txt 30000 | grep -v ### > result.txt
Вот, собственно, и всё.
UPD
Pochemuk в комментариях указал на ошибку в расчёте веса, я исправил её и теперь, при сжатии того же списка из примера с теми же настройками, добавляется 624925 IP адреса, не входящих в изначальный список. Это уже на 22% лучше, чем при обработке network-list-parser -ом
Новый код в ветке untested github.com/phoenix-mstu/net_list_minimizer/tree/untested

