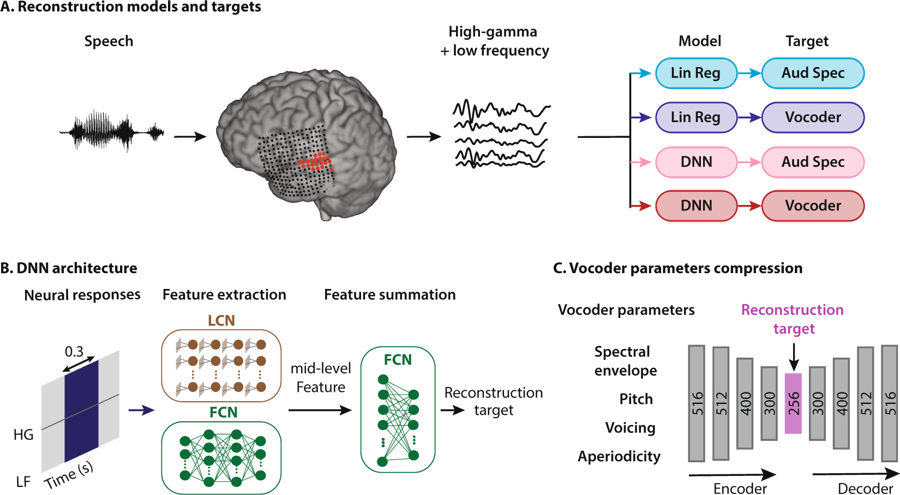
Схема метода реконструкции речи. Человек прослушивает слова, в результате активируются нейроны его слуховой коры. Данные интерпретируются четырьмя способами: сочетанием двух типов регрессионных моделей и двух типов речевых представлений, затем поступают в систему нейросетей для извлечения признаков, которые впоследствии используются для настройки параметров вокодера
Нейроинженеры Колумбийского университета (США) первыми в мире создали систему, которая переводит мысли человека в понятную, различимую речь, вот звукозапись слов (mp3), синтезированных по мозговой активности.
Наблюдая за активностью в слуховой коре головного мозга, система с беспрецедентной ясностью восстанавливает слова, которые слышит человек. Конечно, это не озвучивание мыслей в прямом смысле слова, но сделан важный шаг в этом направлении. Ведь похожие паттерны мозговой активности возникают в коре головного мозга, когда человек воображает, что слушает речь, или когда мысленно проговаривает слова.
Этот научный прорыв с использованием технологий искусственного интеллекта приближает нас к созданию эффективных нейроинтерфейсов, связывающих компьютер непосредственно с мозгом. Он также поможет общаться людям, которые не могут говорить, а также тем, кто восстанавливается после инсульта или по каким-то другим причинам временно или постоянно не способен произносить слова.
Десятилетия исследований доказали, что, в процессе речи или даже мысленного проговаривания слов в мозге появляются контрольные модели активности. Кроме того, отчётливый (и узнаваемый) паттерн сигналов возникает, когда мы слушаем кого-то или представляем, что слушаем. Эксперты давно пытаются записать и расшифровать эти паттерны, чтобы «освободить» мысли человека из черепной коробки — и автоматически переводить их в устную форму.

(А) Сверху показана оригинальная спектрограмма образца речи. Ниже приведены восстановленные слуховые спектрограммы четырёх моделей. (B) Магнитудная мощность частотных полос в течение невокализованной (t = 1,4 с) и вокализованной речи (t = 1,15 с: промежуток показан пунктирными линиями для оригинальной спектрограммы ит четырёх реконструкций)
«Это та же технология, которая используется Amazon Echo и Apple Siri для устных ответов на наши вопросы», — объясняет д-р Нима Месгарани, ведущий автор научной работы. Чтобы научить вокодер интерпретировать мозговую активность, специалисты нашли пятерых пациентов с эпилепсией, уже перенёсших операцию на головном мозге. Их попросили прослушать предложения, сказанные разными людьми, в то время как электроды измеряли мозговую активность, которую обрабатывали четыре модели. Эти нейронные паттерны обучали вокодер. Затем исследователи попросили тех же пациентов послушать, как динамики произносят цифры от 0 до 9, записывая сигналы мозга, которые можно было пропустить через вокодер. Звук, производимый вокодером в ответ на эти сигналы, проанализирован и очищен несколькими нейронными сетями.
В результате обработки на выходе нейросети был получен голос робота, произносящий последовательность чисел. Для проверки точности распознавания людям дали прослушать звуки, синтезированные по их собственной мозговой активности: «Мы обнаружили, что люди могут понимать и повторять звуки в 75% случаев, что намного выше и превосходит любые предыдущие попытки», — сказал д-р Месгарани.
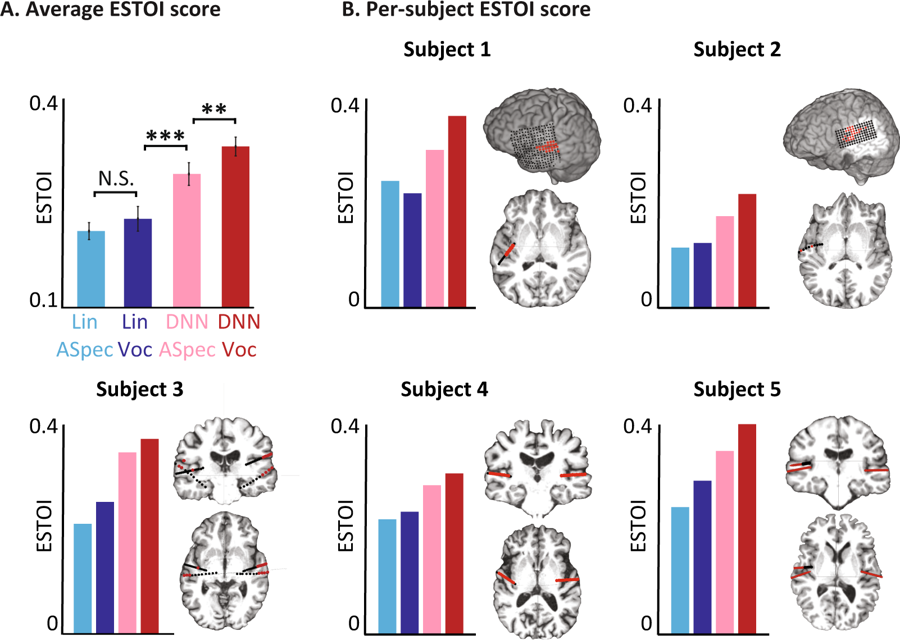
Объективные оценки для разных моделей. (A) Средний балл по стандартной оценке ESTOI по всем испытуемым для четырёх моделей. B) Охват и расположение электродов и оценка ESTOI по каждому из пяти человек. У всех оценка ESTOI вокодера DNN выше, чем других моделей.
Сейчас учёные планируют повторить эксперимент с более сложными словами и предложениями. Кроме того, те же тесты запустят для сигналов мозга, когда человек воображает, что он говорит. В конечном счете они надеются, что система станет частью имплантата, который переводит мысли владельца непосредственно в слова.
Научная статья опубликована 29 января 2019 года в открытом доступе в журнале Scientific Reports (doi: 10.1038/s41598-018-37359-z).
Программный код для проведения фонемного анализа, расчёта высокочастотных амплитуд и восстановления слуховой спектрограммы выложен в открытый доступ.

