Лирическое вступление
Как-то вечером, наводя порядок в стенном шкафу, я наткнулся на большую картонную коробку. Она пережила два переезда и не открывалась уже столько лет, что я напрочь забыл, что именно в ней хранилось. Оказалось, там лежали фотографии — в альбомах, в конвертах из фотоателье, а часть просто так.
Многие фотографии были сделаны более семидесяти лет назад. На одной был дедушка — в студенческие годы, еще молодой и статный, в абсолютно ломовейших очках. «Надо же, мой дед носил хипстерские шмотки еще до того, как это стало мейнстримом», подумал я, и невольно улыбнулся. Его я узнал сразу, но дальше пошли фотографии людей, о которых я ничего не помню. В чертах лица можно смутно угадать родство — и все.

Когда мне было пятнадцать, бабушка неоднократно показывала эти карточки и рассказывала о тех, кто на них изображен. К сожалению, ценность подобных историй понимаешь только тогда, когда рассказывать их становится некому. На тот момент мне было абсолютно неинтересно по десятому разу слушать какие-то замшелые байки про довоенные годы, я отмахивался от них и пропускал мимо ушей. Теперь же, внезапно в полной мере осознав, что часть семейной истории безвозвратно утеряна, я загорелся идеей систематизировать и сохранить то, что осталось.
Идеальным решением для хранения семейных данных мне представлялся гибрид вики-движка и фотоальбома. Готовых подходящих решений не оказалось, поэтому пришлось написать собственный. Он называется Bonsai и доступен с открытым кодом по лицензии MIT. Дальше будет история о том, как он устроен и как им пользоваться, а также история его разработки и немного ДРАМЫ.

Очередной велосипед?
На сегодняшний день существует масса средств, позволяющих составлять фамильные деревья и каталогизировать информацию о родственниках. Они условно делятся на две большие категории — онлайн-сервисы и десктопные приложения.
В случае с десктопным приложением база обычно хранится в виде файла на диске. Вы открываете приложение и пополняете ее в однопользовательском режиме. При необходимости данные можно экспортировать для бэкапа или переноса в другую систему (например, в формате GEDCOM). Из тех, что я смотрел, самыми приятными в использовании показались Gramps (бесплатный) и отечественное Древо жизни (требует одноразовой покупки).
Противоположная сторона спектра — это веб-сервисы. Они хранят ваши данные на удаленных серверах и берут периодическую плату за использование. Поскольку это коммерческий продукт с централизованной базой и неплохой монетизацией, сервисы такого плана дают вам возможность, например, искать потерянных родственников по ДНК-тесту или архивным записям.
Плюсы и минусы обоих вариантов довольно очевидны. В первом случае вы храните базу локально и полностью управляете доступом к ней и созданием бэкапов. Если приложение с открытым кодом, при большой необходимости можно даже добавить в него дополнительный функционал. Однако работать с такой базой совместно или просмотреть данные с другого устройства будет затруднительно. Во втором же, наоборот, доступ есть с любого устройства, но вы отдаете свои данные третьим лицам и надеетесь на их порядочность. В истории моей семьи нет никакого компромата и страшных секретов, однако я все равно считаю эту информацию сугубо личной и принципиально не хочу, чтобы кто-то другой ее хранил или анализировал.
Если учесть недостатки обоих этих подходов, можно сформулировать список требований к «идеальному» движку:
- Веб-приложение, размещаемое на собственном сервере
- Создание статей о людях, питомцах, местах, событиях и т.д. наподобие вики
- Загрузка медиафайлов
- Отметки людей на фото и видео
- Автоматическое построение генеалогического дерева
- Календарь со всеми важными датами
- Инструменты для совместного редактирования и заливки
Справедливости ради, мне удалось найти несколько проектов с self-hosted-реализацией, но они были в плачевном состоянии: внешний вид застыл на уровне середины двухтысячных, полного набора нужного функционала нет, а копаться в легаси-скриптах на PHP не хотелось. Кроме того, предыдущий pet project закончился и было желание взяться за что-то новое.
Золотое правило гласит: хочешь сделать хорошо — сделай это сам!
Используемые технологии выбирались по трем критериям: мой опыт работы с ними, популярность и открытость-бесплатность. Вот что получилось в результате:
- Рантайм: .NET Core 2.1
- Бэкенд: ASP.NET Core MVC
- База данных: PostgreSQL
- Логика фронтенда: частично Vue, частично jQuery.
- Стили фронтенда: Bootstrap + Sass
Во второстепенных ролях — Elasticsearch для полнотекстового поиска и ffmpeg для получения скриншотов из видео.
Схема данных
Основными объектами в базе Bonsai являются страница и медиа-файл. Они связаны соотношением «много ко многим» через отметки. Отметка может иметь заголовок без ссылки — например, если нужно отметить кого-то на фотографии, но информации на полноценную страницу о нем нет.
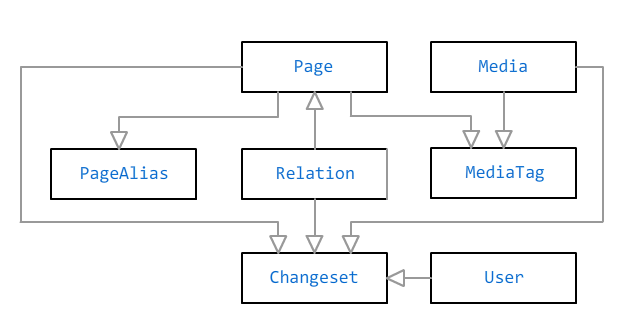
Помимо текста в свободной форме на странице могут быть указаны факты, которые вводятся в специальные поля в админке. По фактам вычисляются дополнительные данные: например, если указать дату рождения человека, то она отметится в календаре, а на его странице будет указан текущий возраст (или продолжительность жизни, если дата смерти тоже указана), по полу можно определить корректное название отношений («отец» или «мать» вместо общего «родители»), и так далее. В базе факты хранятся как JSON-документ.
На выбор доступно пять типов страниц: человек, питомец, событие, место и «прочее». От типа страницы зависит список доступных фактов: например, «образование» актуально только для человека, «дата рождения» — для человека и животного, а «адрес» — только для места.
Страницы связаны между собой отношениями: «родитель», «супруг», «друг», «владелец», «житель» и многими другими. Некоторые отношения могут быть ограничены по времени (супруг, владелец, житель), другие считаются постоянными.
При сохранении любой страницы или отношения получаемая модель проверяется на непротиворечивость. Например, года жизни супругов должны пересекаться, у человека не может быть больше одного биологического родителя каждого пола, и стать собственным папой тоже нельзя. Однополые браки, впрочем, допустимы.
Редактирование страницы, медиа-файла или отношения сохраняет в базу изменение. Это позволяет хранить историю правок и при необходимости их откатывать.
Отношения
Родственные отношения — одна из самых древних концепций в обществе. Уже в праиндоевропейском языке существовало множество названий для них, которые в несколько измененном виде перекочевали в современные языки самых разных групп: слово «мама» поймет и русский, и англичанин, и китаец.
Вариантов родственных отношений очень много, однако базовыми из них являются три: родитель, ребенок и супруг. Они позволяют построить из семьи направленный граф, где эти отношения являются ребрами, а люди — узлами. На таком графе можно выразить любое другое отношение, зная путь между участникам и их пол: например, чтобы определить чьего-то дедушку, нужно найти сначала его родителя (любого пола), а потом родителя этого родителя (мужского пола), и так далее.
В админке Bonsai можно заносить отношения именно этих трех базовых типов. Для каждого отношения будет автоматически создано обратное — родитель для ребенка, супруг для супруга, владелец для питомца. Все дополнительные отношения вычисляются движком и показываются на боковой панели на странице:
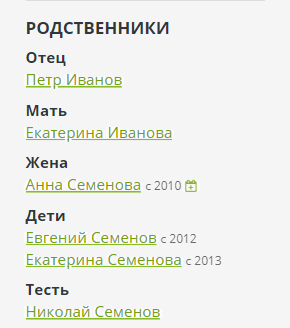
Для вычисления отношений используется элементарный обход графа, а названия родства задаются в виде специального DSL:
public static RelationDefinition[] ParentRelations = { new RelationDefinition("Parent:m", "Отец"), new RelationDefinition("Parent:f", "Мать"), new RelationDefinition("Parent Child:m", "Брат", "Братья"), new RelationDefinition("Parent Child:f", "Сестра", "Сестры"), new RelationDefinition("Parent Parent:m", "Дедушка", "Дедушки"), new RelationDefinition("Parent Parent:f", "Бабушка", "Бабушки") };
Даже прямых родственников у человека может быть много. Bonsai делит связи на следующие группы:
- Ближайшее кровное родство — семья, в которой человек вырос: мать и отец, бабушки и дедушки, братья и сестры. Если смотреть на граф, то это путь на 1-2 шага вверх и на 1 в стороны.
- Собственная семья: по одной группе на каждого супруга и детей от него. Сюда также попадают родственники супруга — тещи, шурины и тому подобное.
- Прочее: более дальние родственники (внуки, дяди-тёти) и не-родственные связи (друзья, коллеги).
Иногда одного пути для определения принадлежности к группе недостаточно. Данные могут быть неполными, но их все равно нужно показать максимально адекватно. Рассмотрим следующий родственный граф:
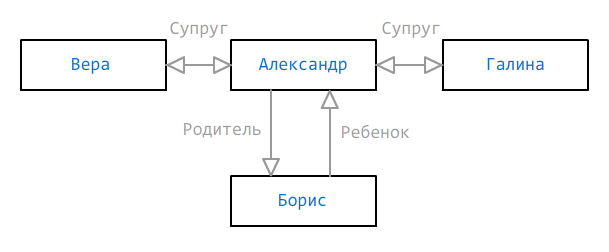
Как мы видим, для Александра указаны две жены (Вера и Галина) и сын (Борис), но мы не знаем, кто из жен является матерью ребенка — может быть, это вообще какая-то третья женщина, но она пока не добавлена. Для таких случаев может быть указано несколько путей, которые должны существовать или не существовать, и они помечаются знаками
+ и - соответственно:new RelationDefinition("Spouse Child+Child", "Сын|Дочь|Ребенок", "Дети") new RelationDefinition("Spouse Child-Child:m", "Пасынок") new RelationDefinition("Spouse Child-Child:f", "Падчерица")
Генеалогическое древо
Любой приличный генеалогический движок должен уметь строить фамильное древо. Это самый наглядный способ показать общую информацию о людях и их родственных связях. Данные хранятся в базе в виде направленного графа и, в теории, его должно быть несложно визуализировать. На практике же именно с отображением дерева возникло больше всего сложностей.
Вот несколько примеров того, как могут выглядеть генеалогические деревья:
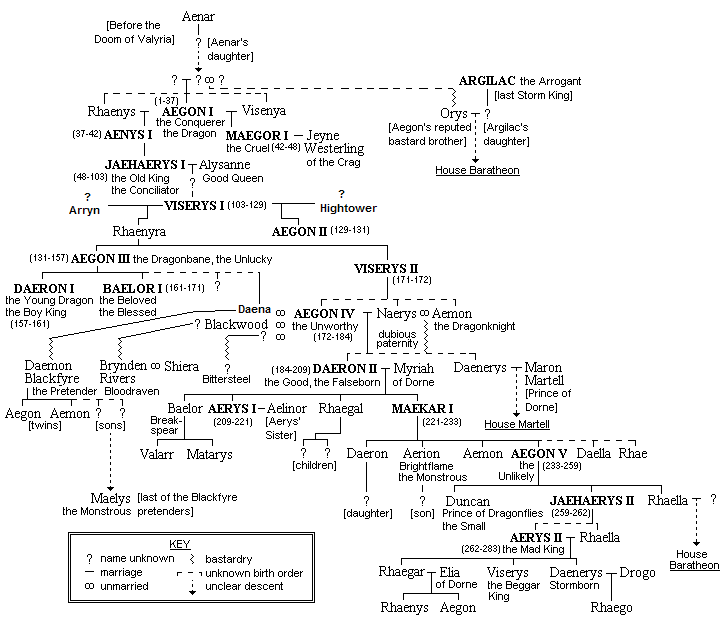
Родословная Таргариенов. Очень компактно, потому что сделано вручную. Сгенерировать такое дерево из произвольных данных автоматически будет крайне сложно.

Греческие боги. Графическое представление генерируется из специального markdown-синтаксиса, в котором все равно нужно вручную расставить все блоки и прочертить связи между ними. Немного похоже на ASCII-art.
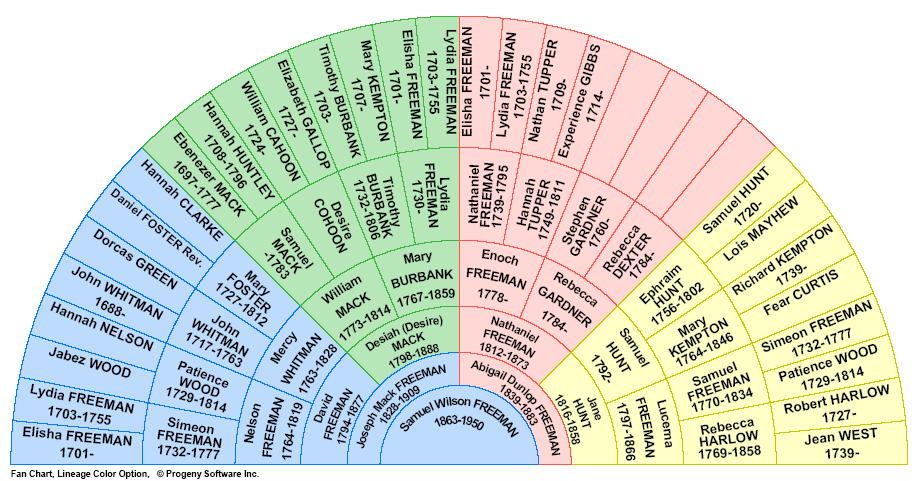
Представление дерева в виде полукруговой диаграммы. Легко генерируется автоматически, но учитывает только прямых предков.
Я просмотрел множество вариантов. Самый эстетически приятный был на сайте MyHeritage:
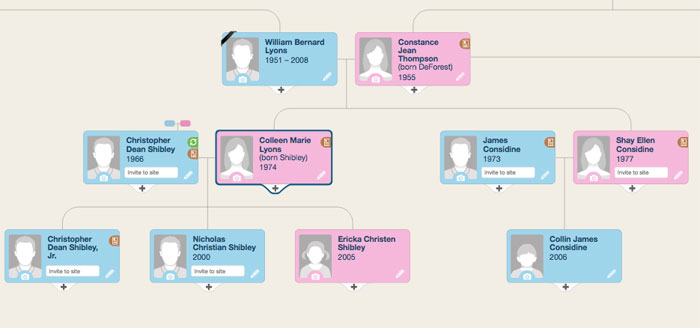
Отрисовку такого дерева можно разбить на три условных шага: получение данных из базы, расстановка блоков/соединительных линий, и непосредственно отображение их на странице. Если с первым и третьим шагами все было тривиально, то на втором я споткнулся.
Попытки набросать самопальное решение на скорую руку закончились полным фиаско. Грамотная расстановка элементов графа — настолько сложная область, что по ней пишут диссертации, а готовые компоненты стоят как квартира в Москве. Ладно, самому написать не получится, но ведь наверняка есть приличные бесплатные решения?
Больше всего надежд я возлагал на библиотеку D3.js. Пожалуй, это первое, что приходит в голову при необходимости нарисовать график или диаграмму на веб-странице. Увы, среди более трех сотен (!) примеров на wiki не оказалось ни одного более-менее похожего на дерево с MyHeritage.
Следующим шагом было погружение в библиотеки, занимающиеся не отрисовкой, а именно вычислением оптимального расположения элементов в графе. Большинство из них предлагают так называемый Force layout. Это очень простой подход, который основан на физических формулах: узлы графа представляются упругими телами, а соединительные линии — пружинами. Его можно легко узнать по характерной анимации — граф как бы «расправляется» на ходу, и это не дополнительная фича, а неизбежное следствие симуляционной природы алгоритма. Подход force-layout хорош для визуализации данных без четкой иерархи (например, связей в соцсетях), но фамильное древо в таком виде выглядит ущербно.
Еще один рассмотренный вариант — библиотека Graphviz. Результат ее работы можно легко узнать по характерным стрелкам. Для описания графа используется специальный язык DOT. Тестовые примеры выглядят еще более-менее, а вот с реальными данными возникают проблемы: стрелки «заламываются» и соединяются под странными углами, граф расползается, и это уже никак не настроишь и не обойдешь.
Не найдя подходящего решения самостоятельно, я решил заказать его на фрилансе, и тут началась та самая ДРАМА.
Заказ был размещен утром 22 октября и уже за час на него поступило несколько откликов. Одного из откликнувшихся звали Владислав; он прислал пример аналогичного решения и пообещал сделать задачу за один день. Такая скорость показалась мне подозрительной, но я понадеялся на его опыт и про себя дал парню погрешность в неделю. Первые пару дней Владислав задавал дополнительные вопросы, не переставая приятно удивлять глубокой погруженностью в проект и внимательным отношением к деталям, а потом пропал. Очнулся он 1 ноября, извинился за вынужденное исчезновение по семейным обстоятельствам и прислал ссылку с бета-версией, которая выглядела довольно похоже на желаемое, если бы не узел в соединительных линиях в центре:
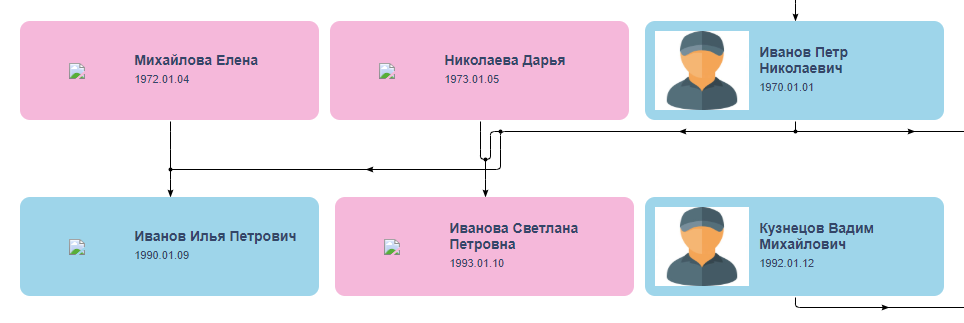
Исчезновение исполнителя — всегда тревожный звонок, но мало ли, всякое бывает, ведь сделал же что-то. Пусть продолжает! Я отправил предоплату и стал ждать доработок. Через пару дней Владислав написал, что исправить проблему он не может, а потом пропал снова — на этот раз на три недели. За это время он ничего не сделал и предоплату возвращать отказался, потому что «задачу на самом деле делал глупый бывший друг, который подвел его и деньги не отдает». После пары уточняющих вопросов горе-делегатор перестал пытаться отмазываться и просто замолчал. Так теперь и живем — периодически я напоминаю ему про долг, а он в ответ присылает скриншот из банковского приложения — дескать, «денег нет, но как только — так сразу». Владиславу я желаю успехов в бизнесе и побыстрее разбогатеть!
Кинул пацана — минус в карму на!
Потерять деньги было не так досадно, но прошел целый месяц, а задача не сдвинулась с мертвой точки, и ждать помощи теперь было неоткуда. В первую очередь я был зол на самого себя: пошел по пути наименьшего сопротивления, нарушил золотое правило — и вот результат. Исполнившись праведным гневом, я повторно засел за изучение библиотек для отрисовки графов и — о чудо! — внезапно нашел именно то, что нужно.
Библиотека называлась Eclipse Layout Kernel, сокращенно ELK. Как можно догадаться, она применяется для отображения диаграмм в IDE Eclipse, но может быть использована и автономно. Вообще она написана на Java, но существует версия, транслированная в JS. Да, ее код кошмарен и весит полтора мегабайта, но эти недостатки можно простить за то, что она просто работает и делает именно то и именно так, как нужно. Интерфейс элементарный: на вход передаются узлы, ребра и настройки, а на выходе получаем координаты. Отрисовать дерево по ним можно любым удобным способом: я выбрал SVG для соединительных линий и div'ы с абсолютным позиционированием для блоков.
Интеграция библиотеки и подбор оптимальных настроек занял от силы два вечера. Это, конечно, не «одни сутки», как обещал мой незадачливый и самонадеянный фрилансер, но довольно близко. В результате Bonsai смог отображать дерево примерно в таком виде:
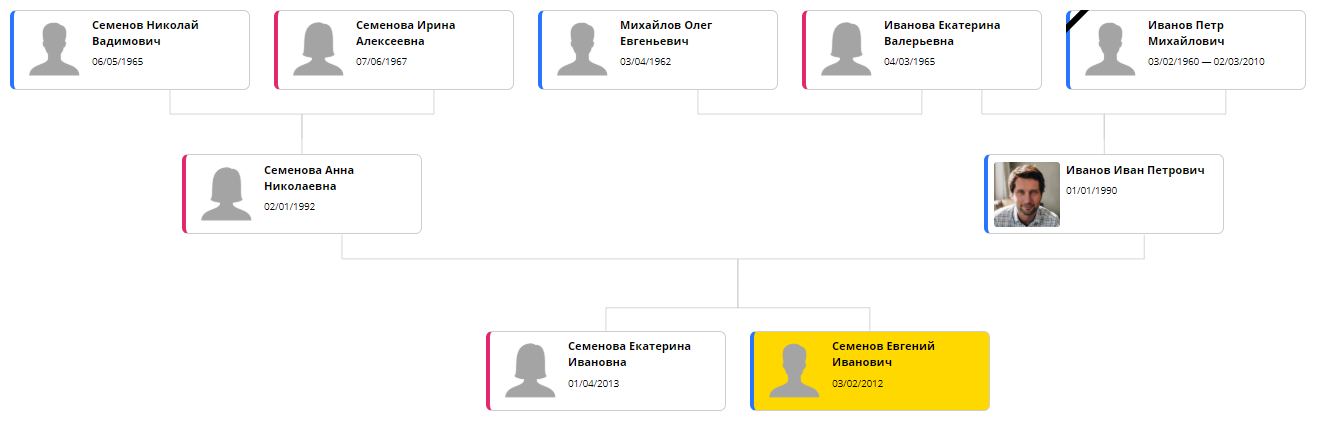
Теперь осталась единственная проблема — время обработки. ELK использует итеративный алгоритм: можно получить более близкое к оптимальному размещение, потратив дополнительное время. На дереве в 20-30 элементов хороший результат требует порядка 5 секунд. Из-за этого страница с деревом каждый раз открывается долго, и это быстро начинает раздражать. К следующей версии вычисление будет перенесено на бэкенд, чтобы его можно было сделать один раз при изменении страницы и закешировать.
Полнотекстовый поиск
Система для хранения текстовой информации была бы бесполезной без удобного полнотекстового поиска. В Bonsai используется база данных PostgreSQL, поэтому первым делом я решил проверить, что она может предложить из коробки. Очередное разочарование:
tsvector справляется с обычными словами, но искать самое главное — имена и фамилии — напрочь отказывается:SELECT to_tsvector('Проверки') @@ to_tsquery('Проверка'), -- true to_tsvector('Иванов') @@ to_tsquery('Иван'), -- false to_tsvector('Иванова') @@ to_tsquery('Иван'), -- false to_tsvector('Иванова') @@ to_tsquery('Иванов'), -- false to_tsvector('Иванов Иван Иванович') @@ to_tsquery('Иванова') -- false
Триграммы тоже не дали ничего хорошего. В итоге я остановился на довольно ожидаемом варианте: ElasticSearch + Russian Morphology. Работать с ним из .NET оказалось очень неудобно, однако с поиском по ФИО он справляется на твердую пятерку.
Сознательное несовершенство
При работе над проектом регулярно возникали ситуации, когда от выбранного решения внутренний перфекционист приходил в бешенство. Предметная область довольно нестандартная и общепринятые «правила хорошего тона» работают не всегда.
Вот например, что происходит, когда мы открываем любую страницу?
- Текст страницы компилируется из Markdown в HTML. Если в тексте есть ссылки на другие страницы и медиафайлы, придется сходить за дополнительной информацией в базу.
- Факты десериализуются из JSON, в котором они хранятся в базе, во вьюмодели.
- Определяются родственные связи. Для этого из многострадальной базы необходимо достать весь граф связей и найти в нем узлы по заранее известному списку путей.
На первый взгляд кажется, что это ужасно тяжелая операция, но на самом деле это не так из-за относительно малого объема данных. Сколько родственников вы можете вспомнить и захотите записать? Попробуйте ради интереса их пересчитать и обнаружите, что набрать хотя бы сотню будет очень сложно. А скольким людям захотите дать доступ? Даже астрономически большое для семьи число — тысяча человек! — по меркам современных баз данных остается смехотворным.
Конечно, скомпилированная вьюмодель страницы все равно кешируется при первом открытии и переиспользуется при последующих — в первую очередь потому, что это было очень просто реализовать. Правило инвалидации кеша при изменениях в админке тоже взято максимально простое: если мы меняем только текст и некоторые локальные факты (список языков, группа крови, цвет волос и т.д.), то достаточно сбросить эту конкретную страницу. При любом другом изменении — название страницы, дата рождения или пол, добавление или изменение любой связи — кеш сбрасывается полностью. Да, это не самый умный способ очистки. Да, наверняка можно было бы написать сложный алгоритм, который сбрасывал бы только то, что нужно — но для данного проекта он не оправдал бы затрат.
Проект не поддерживает локализацию и смену внешнего вида, авторизация работает по OAuth на Facebook\Google, а админка сделана на обычных формах, а не каком-нибудь SPA-фреймворке по последнему писку моды. Все это можно было бы реализовать или улучшить, но оно не решило бы никакой проблемы, а следовательно время было бы потрачено зря.
С надеждой в будущее
Еще одна причина, по которой нет смысла вкладываться в сложность устройства движка — эфемерность реализации по сравнению с данными, которые она хранит. Задумайтесь на минуту: веб в нынешнем его виде существует едва ли двадцать лет, а семейная история подразумевает хранение веками. Такую задачу еще никто не решал просто потому, что сама отрасль информационных технологий существует гораздо меньше. Что же можно сделать?
Движок придется регулярно переписывать с нуля — точно так же, как на протяжении тысяч лет монахи усердно переписывали тексты из обветшалых книг в новые. Разница только в том, что книга может и сто лет пролежать при должном обращении, а приложение — от силы 15-20 лет. Надеюсь, что через двадцать лет я еще буду в состоянии сделать это самостоятельно, а вот еще через двадцать это придется делать моим детям или внукам. Хочется оставить им простой, понятный и документированный исходник.
На самых первых этапах проектирования мне хотелось встроить в движок некий SQL-подобный язык, с помощью которого можно было бы получать ответы на конкретные вопросы: «какой процент моих предков с голубыми глазами», «когда Иван купил первый автомобиль» и так далее. От данной идеи пришлось отказаться, потому что она потребовала бы вместо обычного текста заносить всю информацию в неком формализованном виде, и только описание этого вида заняло бы годы. С другой стороны, Natural Language Understanding сейчас набирает обороты. Не удивлюсь, если через десяток-другой лет можно будет попросить Siri прочитать текст за тебя, походить по ссылкам и в итоге представить выжимку из фактов. Ребята, поднажмите!
Как попробовать?
К сожалению, я не могу предоставить ссылку на готовую демку: нет сервера, который бы выдержал хабраэффект. Зато есть несколько наглядных скриншотов (картинки кликабельны).



Если Bonsai показался вам полезным и вы захотите запустить его самостоятельно, исходный код можно скачать с Гитхаба:
https://github.com/impworks/bonsai
Подробная инструкция по установке указана в Readme. Вам понадобится вот что:
- .NET Core 2.1+
- PostgreSQL 10+
- ElasticSearch 5.x и плагин Russian Morphology
- Приложение в Facebook или Google для авторизации по oAuth
После первого запуска в базе создается несколько тестовых страниц и фотографий. Для продакшена это поведение не нужно и отключается флагом в настройках.
Буквально месяц назад я запустил собственный инстанс и начал обкатывать его, заводя настоящие данные. Некоторые шероховатости встречаются, но в остальном я полностью доволен результатом. Теперь проект будет постепенно развиваться и дорабатываться. Первоочередные задачи — ускорить отображение дерева, разрешить загрузку документов в виде PDF и добавить тонкую настройку прав доступа. Было бы хорошо улучшить юзабилити админки в некоторых местах или сделать автоматическое распознавание лиц на фото — но это не точно.

