Модель «Инфраструктура как код (IaC)», которую иногда называют «программируемой инфраструктурой», — это модель, по которой процесс настройки инфраструктуры аналогичен процессу программирования ПО. По сути, она положила начало устранению границ между написанием приложений и созданием сред для этих приложений. Приложения могут содержать скрипты, которые создают свои собственные виртуальные машины и управляют ими. Это основа облачных вычислений и неотъемлемая часть DevOps.
Инфраструктура как код позволяет управлять виртуальными машинами на программном уровне. Это исключает необходимость ручной настройки и обновлений для отдельных компонентов оборудования. Инфраструктура становится чрезвычайно "эластичной", то есть воспроизводимой и масштабируемой. Одни оператор может выполнять развертывание и управление как одной, так и 1000 машинами, используя один и тот же набор кода. Среди гарантированных преимуществ инфраструктуры как кода — скорость, экономичность и уменьшение риска.
Как раз об этом расшифровка доклада Кирилла Ветчинкина на DevOpsDays Moscow 2018. В докладе: переиспользование модулей Ansible, хранение в Git, ревью, пересборка, финансовые выгоды, горизонтальное масштабирование в 1 клик.
Кому интересно, прошу под кат.
Всем привет. Как уже говорили, я Ветчинкин Кирилл. Я работаю в компании TYME и сегодня мы с вами поговорим про инфраструктуру как код. Также поговорим о том, как мы научились экономить на этой практике, потому что она достаточно дорогая. Писать много кода, для настройки инфраструктуры достаточно затратно.
Вкратце расскажу о компании. Я работаю в компании TYME. У нас произошел ребрендинг. Сейчас мы называемся PaySystem — как видно из названия, мы занимаемся платежными системами. У нас есть как собственные решения — это процессинги, так и заказная разработка. Заказная разработка — это электронные банки, биллинги и тому подобные вещи. И как вы понимаете, если это заказная разработка, то это каждый год большое количество проектов. Проект идет за проектом. Чем больше проектов, тем больше однотипной инфраструктуры приходится поднимать. Поскольку проекты зачастую высоконагруженные, то мы применяем микросервисную архитектуру. Поэтому в одном проекте содержится еще много-много маленьких подпроектов.
Соответственно, всем этим зоопарком управлять без полноценного DevOps весьма сложно. Поэтому в нашей компании внедрили различные практики DevOps. Естественно, мы работаем по kanban, по SCRUM, все храним в git. После того, как закоммитили, идет непрерывная интеграция, прогоняются тесты. Тестировщики пишут на PyTest end-to-end тесты, которые каждую ночь стартуют. Unit-test стартуют после каждого коммита. Мы используем раздельный процесс сборки и деплоя: собрали, потом много раз деплоим на различные среды. Мы были на windows. На windows мы деплоили с помощью Octopus deploy, В этом году мы разрабатываем на DotNet Core. Поэтому мы имеем возможность теперь запускать ПО на Linux системах. Мы ушли от Octopus и пришли к Ansible. Сегодня мы поговорим об этой части, представляющей из себя новую практику, которую мы развили в этом году, то чего у нас раньше не было. Когда у вас есть тесты, когда вы умеете хорошо собирать приложение, деплоить его куда-то — все прекрасно. Но если у вас две среды настроены по-разному, то вы все равно упадете, причем упадете на production. Поэтому управлять конфигурациями это очень важная практика. Вот о ней мы сегодня будем говорить.

Вкратце расскажу как вообще строится экономика продукта по трудозатратам: 60 процентов у нас тратиться на разработку, аналитика занимает где-то 10 процентов, QA (тестирование) занимает около 20 процентов и все остальное как раз отводится на конфигурирование. Когда системы идут целым потоком, в них многие стороннее ПО, сами операционные системы настраиваются практически одинаково. Мы на это тратим лишнее время, делая по сути одно и тоже. Появилась идея это все автоматизировать и снизить издержки на конфигурирование инфраструктуры. Однотипные задачи автоматизированы, хорошо отлажены и не содержат ручных операций.

Каждое приложение работает в каком-то окружении. Давайте посмотрим, из чего это все состоит. У нас как минимум должна быть операционная система, ее нужно сконфигурировать, есть какие-то сторонние приложения, которые тоже нужно сконфигурировать, само приложение должно получить конфигурации, но чтобы весь продукт заработал, должно запуститься само приложение, которое во всей этой системе функционирует. Есть еще сеть, которую тоже нужно настраивать, но про сеть мы сегодня говорить не будем, потому что у нас разные заказчики, разные сетевые устройства. Мы пытались тоже автоматизировать конфигурирование сети, но поскольку устройства разные, никакого особо толку от этого не было, больше тратили ресурсов на это. Но операционные системы, сторонние приложения и передачу конфигурационных параметров в сами приложения мы автоматизировали.

Два подхода как вы можете конфигурировать сервера: руками — если вы конфигурируете их руками, у вас соответственно может получиться такая ситуация, что у вас production настроен одним образом, тест другим, на тесте все зеленое, тесты зеленые. Вы деплоите на production, а там не стоит какой-то фреймворк — у вас ничего не работает. Другой пример: три Application сервера настроены руками. Один Application сервер настроили одним образом, другой Application сервер другим образом. Сервера могут работать по-разному. Еще пример: была ситуация, когда у нас один Stage сервер полностью перестал работать. Запустили создание нового сервера используя и через 30 сервер был готов. Еще пример: сервер просто перестал работать. Если настраивали руками, то нужно искать человека, который знает как его настраивать, нужно поднимать документацию. Как мы знаем, документация вряд ли бывает актуальной. Это большие проблемы. И, самое главное, — это аудит, то есть грубо говоря, у вас есть десять администраторов, каждый из них что-то руками настраивает, то не особо понятно корректно они это настроили или некорректно, и как вообще понять, нужно ли делать какие-то настройки, могли что-то лишнее поставить, открыть какие-то ненужные порты.

Есть альтернативный вариант — это как раз то, про что мы сегодня говорим — это конфигурирование из кода. То есть у нас есть git репозиторий, в котором вся инфраструктура хранится. Там хранятся все скрипты, с помощью которых мы будем это настраивать. Поскольку это все в git, мы получаем все преимущества от управления кодом, как в разработке, то есть мы можем делать ревью, аудит, историю изменений, кто сделал, почему сделал, комментарии, можем откатываться. Чтобы работать с кодом нужно использовать конвейер непрерывной сборки — конвейер развертывания. Чтобы какая-то система именно вносила изменения в сервера, то есть не человек что-то руками делал, а исключительно делала это система.

В качестве системы, которая вносит изменения, мы используем Ansible. Поскольку у нас нет огромного количества серверов, он нам вполне подходит. Если у вас там 100-200 серверов, то у вас будут небольшие проблемы, потому что он (т.е. Ansible) все-таки соединяется с каждым и по очереди их настраивает — это проблема. Лучше другие средства использовать, которые не пушат (push), а пулят (pull). Но для нашей истории, когда у нас много проектов, но серверов не больше 20 — нам это вполне подходит. У Ansible большой плюс — это низкий порог вхождения. То есть буквально любой ИТ-специалист за три недели может его полностью освоить. У него много модулей. То есть вы можете управлять облаками, сетями, файлами, установкой программ, деплоем — абсолютно всем. Если нет модулей, вы можете написать свой собственный, вы можете в конце концов написать что-то используя модуль Ansible shell или command.
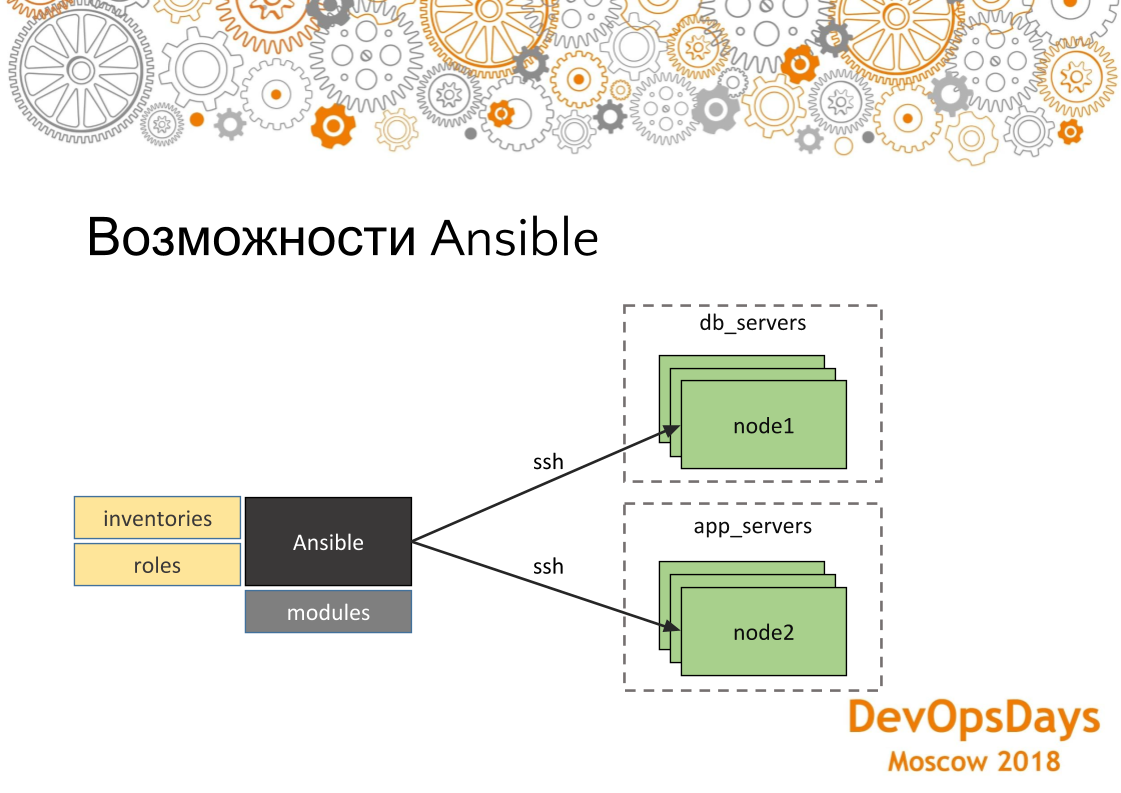
В общем, вкратце рассмотрим как он вообще выглядит, этот инструмент. У Ansible есть модули, про которые я уже говорил. То есть их можно доставлять, самим писать, которые что-то делают. Есть inventories — это куда мы будем накатывать наши изменения, то есть это хосты, их IP адреса, переменные, специфичные для этих хостов. И, соответственно, роли. Роли — это что мы будем накатывать на эти сервера. И также у нас хосты группируются по группам, то есть в данном случае мы видим, что у нас есть две группы: сервера баз данных и сервера приложений. В каждой группе у нас по три машины. Они по ssh соединяются. Таким образом, мы решаем те проблемы, про которые мы говорили раньше, что у нас во первых сервера настроены идентично, поскольку одна и та же роль накатывается на сервера. И точно так же, если эту роль запустим на нескольких машинах, то на каждый тоже она отработает аналогично.
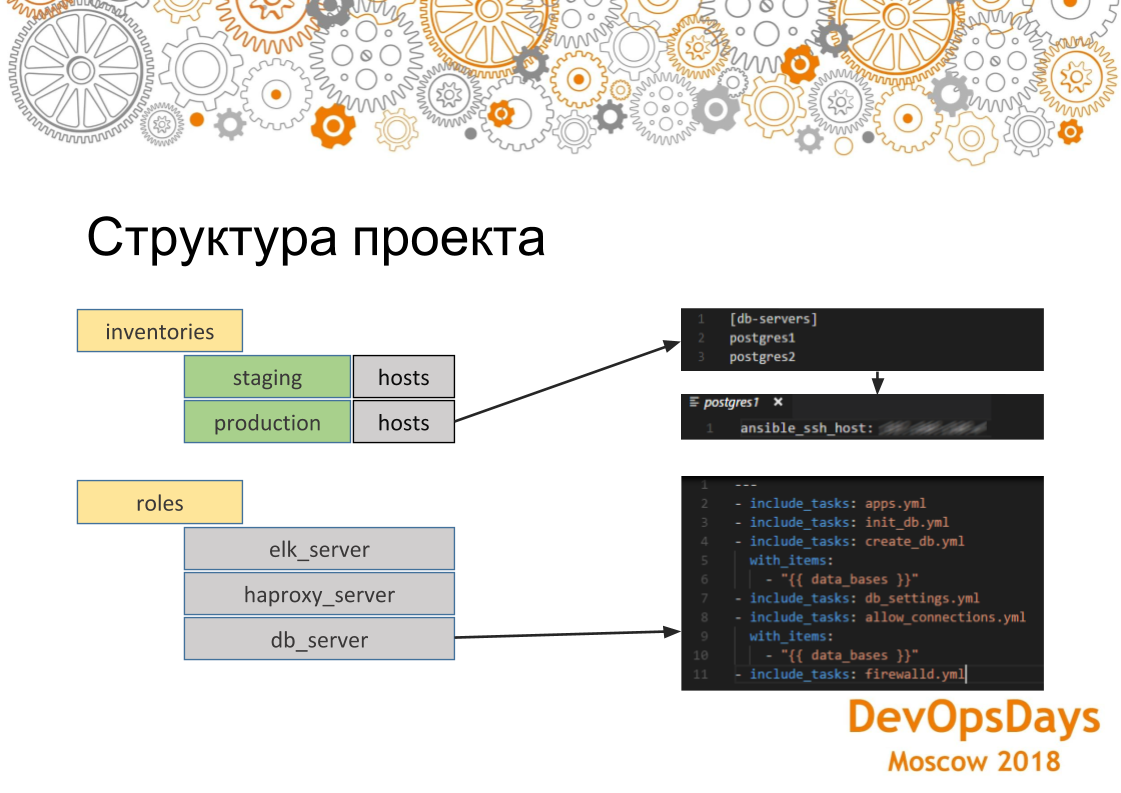
Если мы более глубоко посмотрим на то, как устроен проект Ansible, то здесь мы видим, что вот inventories хосты допустим для production. Вот эта группа указана и в ней два сервера. Если мы зайдем в конкретный сервер, то видим что здесь указан IP адрес этой машины. Также там могут быть указаны другие параметры — переменные, специфичные для этой среды. Если мы посмотрим на роли. То роль содержит несколько задач (task), которые будут выполняться. В данном случае это роль для установки PostgreSQL. То есть мы устанавливаем необходимое приложение, создаем базы данных. Здесь мы используем цикл. Их (базы данных) несколько создастся. Затем мы устанавливаем необходимое соединение — IP адреса, которые могут в этой базе авторизоваться. И, соответственно, настраиваем в самом конце firewall. Настройки будут применены ко всем серверам в группе.

Как раз подходим к самой проблеме: мы отлично научились конфигурировать сервера с помощью Ansible и было все прекрасно. Но, как я уже говорил, у нас множество проектов. Они почти все одинаковы. В каждом проекте участвуют примерно вот такие системы (k8s, RabbitMQ, Vault, ELK, PostgreSQL, HAProxy). Для каждой мы написали свою роль. Мы ее можем накатывать с кнопки.

Но проектов то у нас много и в каждом они по сути пересекаются. То есть в одном такой набор, во втором такой, в третьем такой. У нас получаются точки пересечения, в которых одни и те же роли в разных проектах.

У нас есть репозиторий с приложением, есть репозиторий с инфраструктурой для проекта. У второго проекта точно также. Продолжение инфраструктуры. И у третьего. Если мы будем одно и то же реализовывать, то по сути получится copy-paste. На одну и ту же роль в 10 местах сделаем. Потом, если будет какая-то ошибка, мы будем в 10 местах править.
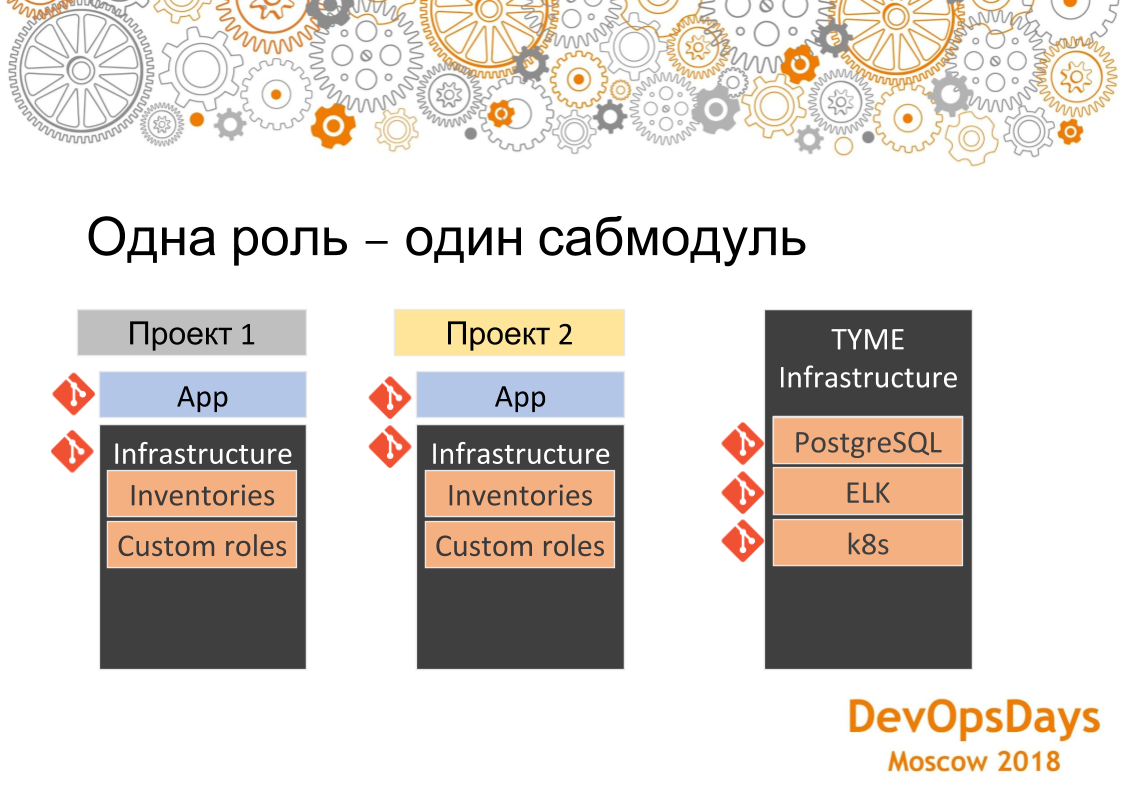
Что мы сделали: мы каждую роль, которая общая для всех проектов и все ее конфигурации, которые приходят извне, вынесли в отдельный репозиторий и положили их в гит в отдельную папочку — назвали TYME Infrastructure. Там у нас лежит роль для PostgreSQL, для ELK, для развертывания кластеров Kubernetes. Если нам в какой-то проект понадобится поставить допустим тот же PostgreSQL, то просто включаем его как submodule, переписываем inventories, то есть, грубо говоря, конфигурацию куда эту роль накатывать. Саму роль мы не переписываем: она уже есть. И у нас по клику кнопки во всех новых проектах появляется PostgreSQL. Если нужно поднять кластер Kubernetes — то же самое.

Таким образом, получилось снизить издержки на написание ролей. То есть один раз написали — 10 раз использовали. Когда проект идет за проектом — это очень удобно. Но поскольку мы теперь работаем с инфраструктурой как с кодом, нам, естественно, нужны конвейеры, про которые мы говорили. Люди коммитят в git, могут закоммитить какую-то некорректность — нам нужно это все отслеживать. Поэтому у нас построен вот такой pipeline. То есть разработчик коммитит в git скрипты Ansible. TeamСity их трекает и передает в Ansible. Teamcity здесь нужен только по одной причине: во первых, у него визуальный интерфейс (есть бесплатная версия Ansible Tower — AWX, которая решает эту же задачу — прим. ред.) в отличие от Ansible бесплатного и, в принципе, у нас Teamcity как единый CI. Так-то в принципе Ansible имеет модуль, который сам может git трекать. Но в данном случае сделали просто по образу и подобию. И как только он его трэкнул, он передает весь код в Ansible и Ansible соответственно запускает их на integration сервере и меняет конфигурацию. Если этот процесс нарушился, значит мы разбираем что не так, почему плохо написали скрипты.

Второй момент, что есть специфичная инфраструктура, то здесь у нас инфраструктура деплоится отдельно, приложение деплоится отдельно. Но есть специфичную инфраструктура для каждого приложения, то есть которую нужно деплоить перед тем, как мы будем его запускать. Здесь, соответственно, нельзя выносить это в разный pipeline. У вас должно это развертываться в том же контейнере, что и само приложение. То есть, допустим, фреймворки — популярная вещь, когда вам нужно для нового приложения один фреймворк поставить, для другого другой фреймворк поставить. Вот как с данной ситуацией. Либо кэши надо почистить. К примеру, Ansible может также залезть, кэш почистить.
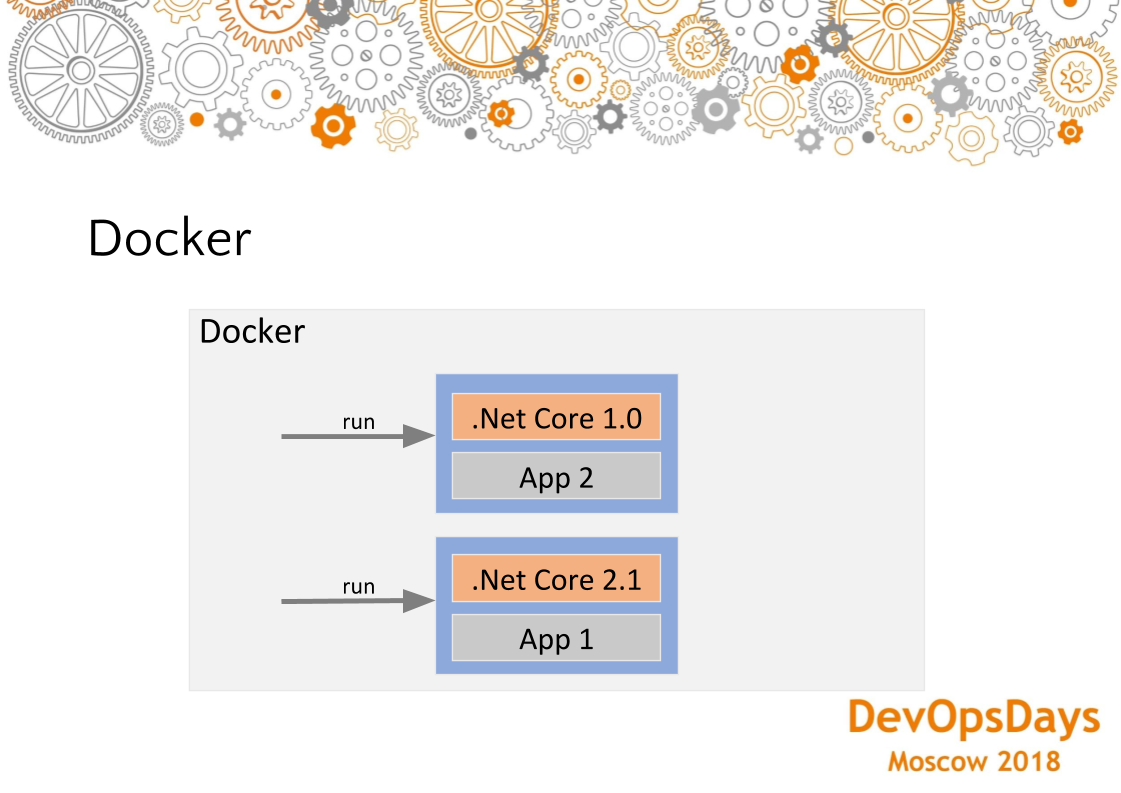
Но здесь мы применяем докер в сочетании с Ansible. То есть специфичная инфраструктура нас находится в докере, неспецифичная в Ansible. И таким образом, мы как бы разделяем вот эту маленькую дельту в докере, все остальное, фундаментальное — в Ansible.
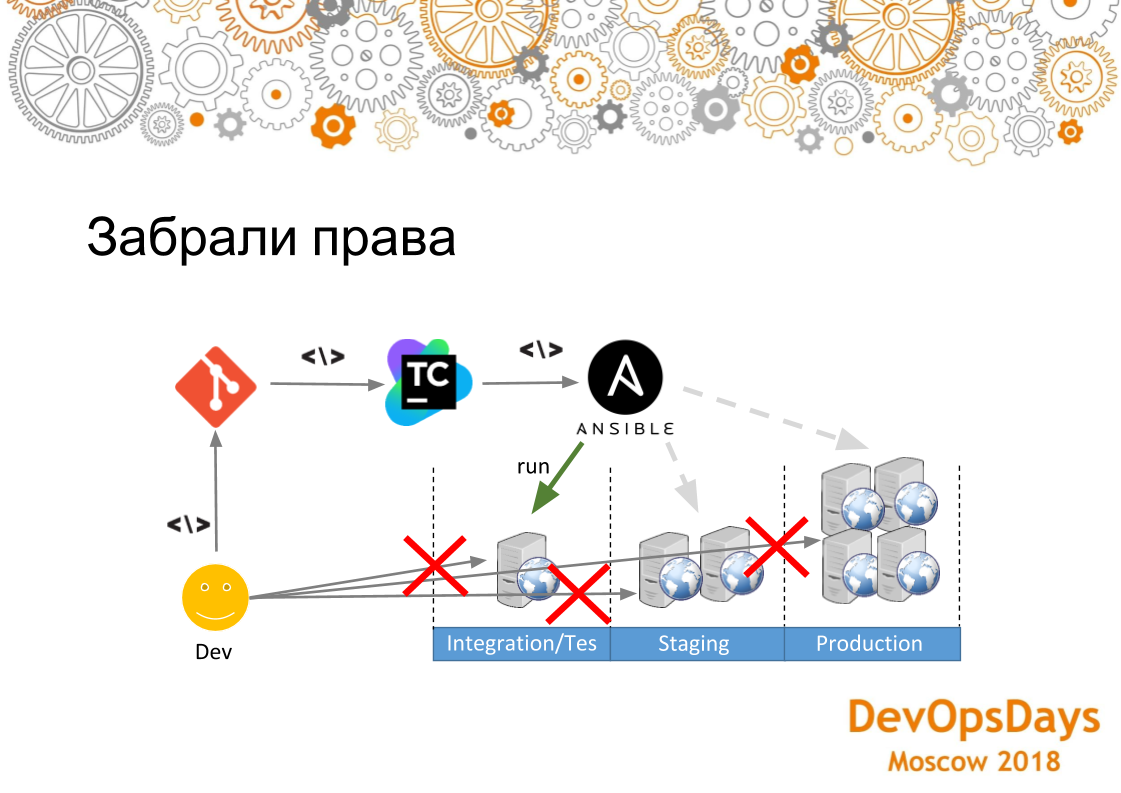
Очень важный момент — если вы катите инфраструктуру через какие-то скрипты, через код, то если у вас все же остаются ручные манипуляции серверами, то это потенциальная уязвимость. Потому что допустим, вы на тестовый сервер поставили java, написали роль ELK, накатили ее. Деплой в тест прошел успешно. Деплоите в production, а там java нет. А java в скрипте вы не указали — деплой в production упал. Поэтому нужно забрать права со всех серверов у администраторов, чтобы они руками туда не залезали и все изменения вносили через git. Весь этот конвейер мы сами проходили. Здесь есть одно но — не надо сильно закручивать гайки. То есть нужно внедрять такой процесс постепенно. Потому что он все еще необкатанный. В нашем случае мы оставили доступ до всех систем у самого главного руководителя администраторов на случай непредвиденных инцидентов. Доступ выдан с условием, что он не будет ничего руками настраивать.
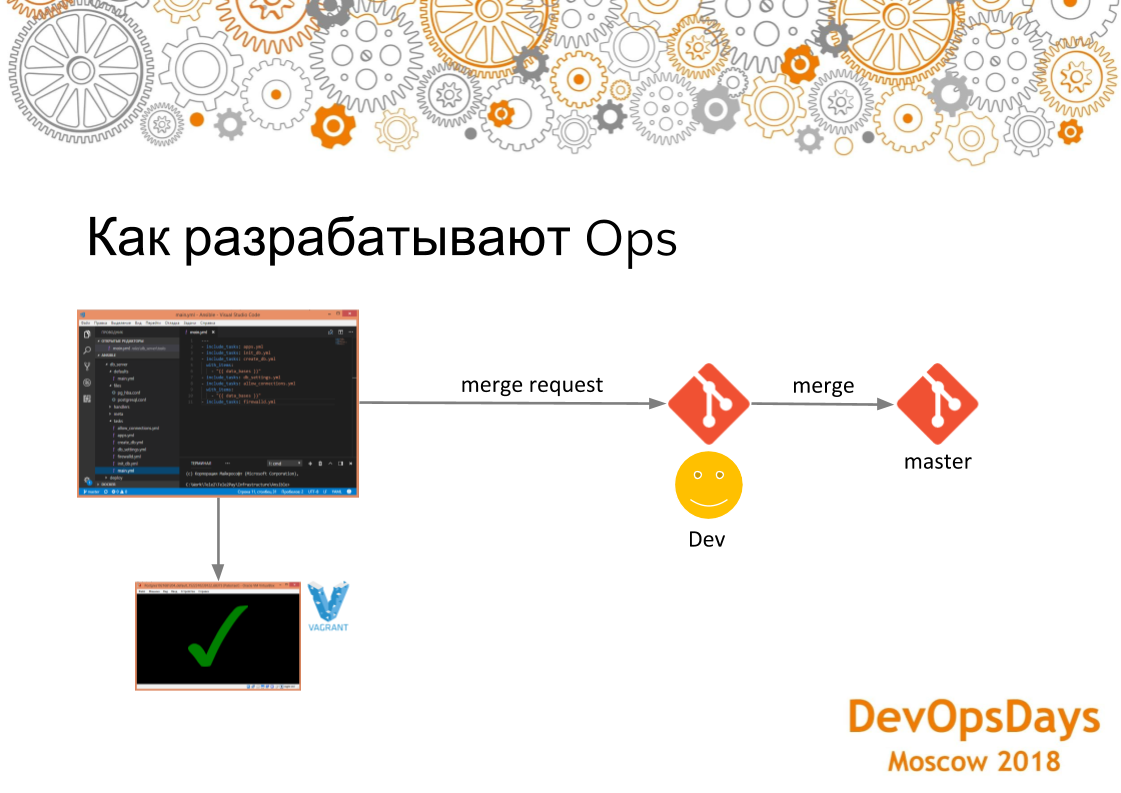
Как происходит разработка? Выкатка в staging, production должна быть без ошибок. У нас что-то может сломаться. Если выкатка в integration окружение будет постоянно падать на ошибках — это будет плохо. Это похоже на отлаживать приложения на удаленной машине. Когда разработчик разрабатывает сначала все на машине, компилирует. Если все компилируется, потом отправляет в репозиторий. Здесь используется такой же подход. Разработчики используют Visual Studio Code с плагинами Ansible, Vagrant, Docker и т.д. Разработчики тестируют свой инфраструктурный код на локальном vagrant. Там поднимается чистая операционная система. Сами скрипты для поднятия этой машины тоже находятся в этом репозитории с инфраструктурой, про которую мы говорили. Разработчик начинает на ней устанавливать FTP-сервер. Если что-то пошло не так, он ее просто удаляет, заново загружает, и заново пытается на нее установить нужное ПО, используя скрипты развертывания. После отладки скриптов развертывания он делает Merge Request в основную ветку. После слияния Merge Request CI раскатывает эти изменения integration сервер.

Поскольку все скрипты это код, то можем писать тесты. Допустим, мы установили PostgreSQL. Хотим проверить работает он или нет. Для этого используем модуль Ansible assert. Сравниваем установленную версию PostgreSQL с версией в скриптах. Таким образом мы понимаем, что установлен, он вообще запущен, он той самой версии, которой мы ожидали.

Мы видим, что тест прошел. Значит наш playbook отработал корректно. Таких тестов можно писать сколько угодно. Они идемпотентные. Идемпотентность (операция, которая если применяется к любому значению несколько раз — всегда получается то же значение, как и при однократном применении). Если вы пишите свобственные скрипт по установке, настройке, то убедитесь что ваши скрипты всегда получает то же значение, если запускать их несколько раз.

Есть еще другой тип тестов, которые к тестированию инфраструктуры напрямую не относятся. Но они как бы косвенно затрагивают его. Это end-to-end тесты. У нас инфраструктура и сами приложения устанавливаются на один и тот же сервер, который тестировщики тестируют. Если мы накатили какую-то некорректную инфраструктуру, то у нас просто комплексные тесты не пройдут. То есть наше приложение будет работать как-то неправильно. В данном примере мы на production установили новую версию — приложение работает. Затем был сделан commit в git и end-to-end тесты, которые проходит по ночам, отследили, что вот здесь у нас отсутствует файл на ftp. Разбираем этот кейс и видим, что проблема именно в настройках ftp. Мы исправляем скрипты в коде, снова деплоим и все становится зеленым. Такая же история с кодом. Код инфраструктуры и инфраструктура так или иначе косвенно тестируется. Мы ее можем потом деплоить на production.

Когда мы этот подход внедрили, CI (Teamcity), который выкатывал изменения на integration сервер падал 8 раз из 10. Никто не обращал на это внимания, потому что не было обратной связи. У разработчиков эти процессы достаточно давно были внедрены, а до OPS (системных администраторов) сообщения не доходили. Поэтому мы добавили Dashboard со сборками данного проекта на большой монитор в самом видном месте в офисе. На нем различные проекты выделены зеленым — это значит, что с ним все в порядке. Если выделены красным значит, что с ним все плохо. Мы видим, что некоторые тесты не прошли. На презентации в левой стороне второй сверху видим результат инфраструктурых деплойных тасок. Инфраструктурные деплойные таски зеленые. Это значит, что все тесты пройдены, никаких дефектов не было, они успешно собрались. Оповещение: Допустим ИТ-специалист запустил скрипт и отошел. Если коммит все сломал. Ему в канал Slack приходит оповещение о том, что вот такой-то ИТ-специалист таким-то коммитом сломал наш проект.

Ok, мы сейчас говорили про то, как мы разрабатываем, как мы коммитим какие-то тестовые среды, как мы вообще выкатывает это дальше на другие среды. Мы используем trunk based подход. Поэтому здесь Master ветка — это основная ветка разработки. При коммите в Master ветку CI сервер (Teamcity) выкатывает изменения на integration сервер. Если таска в CI сервере зеленая, то тогда мы пишем тестировщикам что можно тестировать продукт на integration сервере. Формируем release candidate. На тестовом сервере эта конфигурация появляется. Ее тестировщики могут тестировать вместе с самими приложениями. Если все ок, если end-to-end тесты пройдены, мы уже можем саму конфигурацию и приложение выкатывать на staging окружение. Затем можем выкатывать на production. За счет таких вот разноуровневых барьеров мы достигаем того, что staging окружение у нас всегда зеленое.
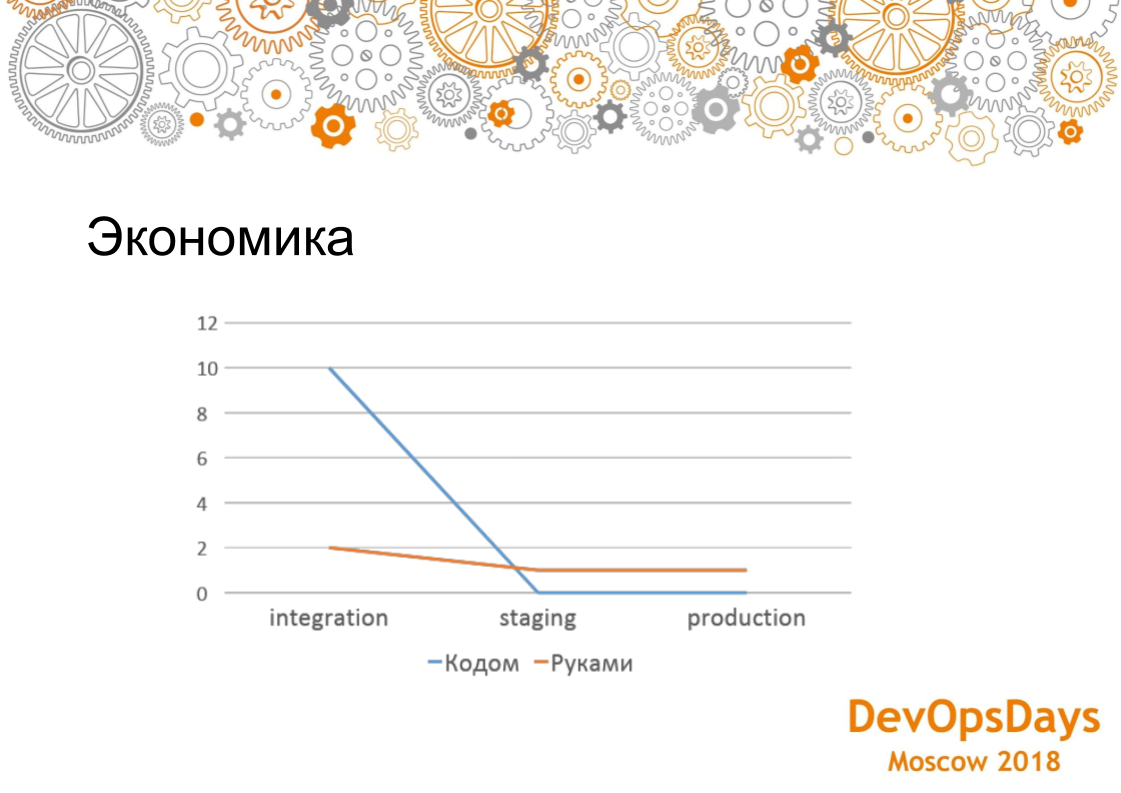
Сравним управление инфраструктурой из кода и настройка инфраструктуры руками. Какая экономика? Данный график показывает, как мы устанавливали PostgreSQL. Управление инфраструктурой из кода получилось 5 раз дороже на раннем этапе. Все скрипты необходимо написать, оталадить руками. Этой займет 1-2 часа. Со временем появляется опыт написания этих скриптов. Сравним установку, настройку PostgreSQL час руками и используя скрипт развертывания. Поскольку скрипты разверывания и настройки PostgreSQL уже написаны, то деплоится на staging, production 4 минуты. Чем больше сред, чем больше машин, то вы начинаете выигрывать по трудозатратам в настройке инфраструктуре. И если у вас один проект и одна база данных, то вам дешевле это делать руками. То есть это интересно только когда у вас масштабные какие-то проекты.

Мы внедрили git submodule позволяем несколько раз использовать Ansible роль. Нам второй раз не писать не нужно, она уже есть. Добавляем git submodule с Ansible ролью добавляем в проект. Пишем в inventories сервера, куда эту роль деплоить. Это занимает 30 минут. В случае использования git submodule трудозатраты на написание скриптов развертывания сильно обогнал ручные операции.

Про идентичность сред: здесь я не готов сказать, сколько у нас было ошибок до этого и сколько стало потом. Но хочу сказать, что при соблюдении всех правил, про которые мы сегодня говорили, у нас staging настроен точно так же, как и тест. Поскольку, если тест разваливается, мы уничтожаем машину, заново пытаемся настроить, и только тогда, когда она становится зеленая, накатывается все дело на staging. Сколько руками ошибок делает ваша команда — вы можете сами подумать, посчитать, у каждого наверняка какой-то свой порог.

На графике видны итоги за 6 месяцев. Трудозатраты — сложность по 10 бальной шкале. Первые два месяца мы просто писали эти роли очень больно и долго. Потому что это была новая система. Когда мы их написали, график пошел вниз. Где-то в середине внедрили git submodule, когда мы уже написанные роли стали переиспользовать разных проектов. Это привело к резкому спаду трудозатрат. Если сравнивать с ручной настройкой проекта, по которому данная оценка делалась, то руками мы настраивали три дня, с помощью подхода инфраструктуры как код настраивал около месяца. В перспективе, использование подхода инфраструктура как код более эффективен, чем настройка серверов руками.

Выводы.
Во-первых, мы получили документацию, то есть когда приходит менеджер и меня спрашивает: на каком порту у нас слушает база данных, я открываю Ansible скрипт в git репозитории, говорю: “Вот смотри, вот на таком-то порту”. Какие у нас здесь настройки? Все это видно в git репозитории. Это можно аудировать, показывать менеджерам и так далее. Это 100% достоверная информация. Документация устаревает. А в данном случае ничего не устаревает.
Важный момент, про который мы не говорили. Про него косвенно скажу. Есть команды разработки, которым локально тоже нужно поднимать RabbitMQ, ELK, чтобы протестироварь различные идеи. Если они будут делать руками, то поднятие ELK может занять больше часа. При использовании подхода инфраструктура как код разработчик поднимает виртуалку, нажимает кнопку, и у него устанавливается ELK. Если разработчик сломал ELK, то он может удалиль, запустить снова установку ELK на виртуалку.
Как мы уже говорили, это все дешевле только, когда у вас либо много проектов, либо много сред, либо много машин. Если у вас такого нет, то, соответственно, это не дешевле, это дороже. В нашей перспективе в наших проектах это получилось так, что становится дешевле со временем. Поэтому здесь как плюсы так и минусы.
Быстрое восстановление после аварии. Если вы упали, вам нужно искать человека, который может эту машину настроить, который знает, как ее настроить, который помнит, как ее настроить. В данном случае все настройки и скрипты развертывания находятся в git. Даже если человек уволился, перешел в другой проект — все находится в git, все в комментариях, все видно: почему он открывал такой порт, почему ставил такие-то настройки и так далее. Вы все можете легко восстановить.
Количество ошибок снизилось, потому что у нас появились разные барьеры, локальные среды для отслеживания, для разработки и плюс code review. Это тоже немаловажно, потому что разработчики просматривают то, что они делают. Таким образом, они еще продолжают обучаться. Возросла сложность, потому что это, соответственно, новая система, это конвейеры, людям нужно обучаться. Это не то, что как обычно привыкли: прочитали статью и по статье сделали. Здесь немножко другое. Но тем не менее со временем это достаточно легко осваивается. Если полностью посмотреть на освоение, то это где-то три-четыре месяца.
Вопрос задается через приложение, но вопрос не слышно.
Ответ: Роли мы используем последнюю версию, то есть роль выделяем в отдельный git submodule, только когда она уникальна для абсолютно всех систем. Если по ней произошли какие-то коммиты, то мы переходим на latest комит. А вся конфигурация приходит из inventories. То есть роль — это просто то, что будет выполняться. Название базы данных, логин, пароль и т.д. приходит снаружи. Роль — это просто исполняемый алгоритм. Вся конфигурация приходит из самого проекта.
Вопрос: Если у вас какие-нибудь между ролями Ansible транзитивные зависимости и как вы вытягиваете при деплое приложения (роль A зависит от B, B от C и вы когда выкатываете роль A, чтобы она зависимость все сама тянула)? Посредством каких инструментов, если у вас такой есть?
Ответ: В данной парадигме зависимостей таких нет. У нас бывают зависимости от конфигурации. То есть, мы ставим какую-то систему и знаем IP адреса серверов, и в то же самое есть балансировщик, который теперь стал, должен себя как бы вогнать, чтобы балансировать на эти настроенную машину. Это за счет конфигов как бы разруливается. Но, если вы имеете зависимость от модулей, то здесь ничего нет, у нас один свободный, ни от чего не зависит, он самодостаточный. И мы не выносим в общие роли то, что имеет хоть какую-то не общую структуру, то есть, допустим, RabbitMQ могут и в африке RabbitMQ, он ни от чего не зависит. Какую-то специфику мы в докере как храним, те же фреймворки.
P.S. Предлагаю всем заинтересованным совместно на github переводить в текст интересные доклады с конференций. Можно сделать группу в github для перевода. Пока что я перевожу в текст у себя в github аккаунте — туда же можно отправлять Pull request на исправление статьи.

