
Поделюсь рассказом о небольшом проекте: как найти в комментариях ответы автора, заведомо не зная кто автор поста.
Свой проект я начинал с минимальными знаниями по машинному обучению и думаю для специалистов тут не будет ничего нового. Этот материал в некотором смысле компиляция разных статей, в нем расскажу, как подходил к задаче, в коде можно найти полезные мелочи и приемы с обработкой естественного языка.
Мои исходные данные были следующими: БД содержащая 2.5М медиа-материалов и 39.5М комментариев к ним. Для 1М постов так или иначе автор материала был известен (эта информация либо присутствовала в БД, либо получалась посредством анализа данных по косвенным признакам). На этой основе был сформирован датасет из размеченных 215К записей.
Первоначально я применял подход на основе эвристик, выдаваемых естественным интеллектом и транслируемых в sql-запросы с полнотекстовым поиском или регулярными выражениями. Самые простейшие примеры текста для разбора: «спасибо за комментарий» или «благодарю вас за хорошие оценки» это в 99.99% случаев автор, а «спасибо за творчество» или «Благодарю! Пришлите на почту материал. Спасибо!» — обычный отзыв. С таким подходом можно было отфильтровать только явные совпадения исключая случаи банальных опечаток или, когда автор ведет диалог с комментаторами. Поэтому было решено использовать нейросети, идея эта пришла не без помощи друга.
Типичная последовательность комментариев, который из них авторский?

Ответ
За основу был взят метод определения тональности текста, задача проста у нас два класса: автор и не автор. Для обучения моделей я воспользовался сервисом от Гугла предоставляющем виртуальные машины с GPU и интерфейсом Jupiter notebook.
Примеры сетей, найденные на просторах Интернета:
embed_dim = 128 model = Sequential() model.add(Embedding(max_fatures, embed_dim,input_length = X_train.shape[1])) model.add(SpatialDropout1D(0.2)) model.add(LSTM(196, dropout=0.5, recurrent_dropout=0.2)) model.add(Dense(1,activation='softmax')) model.compile(loss = 'binary_crossentropy', optimizer='adam',metrics = ['accuracy'])
на строках, очищенных от html-тегов и спецсимволов, давали порядка 65-74% процентов точности, что не сильно отличалось от подбрасывания монетки.
Интересный момент, выравнивание входных последовательностей через
pad_sequences(x_train, maxlen=max_len, padding=’pre’) давало существенную разницу в результатах. В моём случае, лучший результат был при padding=’post’.Следующим этапом стало применение лемматизации, что сразу дало прирост точности до 80% и с этим уже можно было работать дальше. Теперь основной проблемой стала корректная очистка текста. К примеру, опечатки в слове «спасибо», конвертировались(опечатки выбирались по частоте использования) в такое регулярное выражение (подобных выражений накопилось полтора-два десятка).
re16 = re.compile(ur"(?:\b:(?:1спасибо|cп(?:асибо|осибо)|м(?:ерси|уррси)|п(?:ас(?:асибо|и(?:б(?:(?:ки|о(?:чки)?|а))?|п(?:ки)?))|осибо)|с(?:а(?:п(?:асибо|сибо)|сибо)|басибо|енкс|ибо|п(?:а(?:асибо|всибо|и(?:бо|сбо)|с(?:бо|и(?:б(?:(?:бо|ки|о(?:(?:за|нька|ч(?:к[ио]|ьки)|[ко]))?|[арсі]))?|ки|ьо|1)|сибо|тбо)|чибо)|всибо|исибо|осиб[ао]|п(?:асибо|сибо)|с(?:(?:а(?:иб[ао]|сибо)|бо?|и(?:б(?:(?:ки|о(?:всм)?))?|п)|с(?:ибо|с)))?)|расибо|спасибо)|тхан(?:кс|x))\b)", re.UNICODE)
Здесь хочется выразить отдельную благодарность чрезмерно вежливым людям, которые считают необходимым добавлять это слово в каждое свое предложение.
Уменьшение доли опечаток было необходимо, т.к. на выходе с лемматизатора они дают странные слова и мы теряем полезную информацию.
Но нет худа без добра, устав бороться с опечатками, заниматься сложной очисткой текста, применил способ векторного представления слов — word2vec. Метод позволил перевести все опечатки, описки и синонимы в близко расположенные вектора.
Слова и их отношения в векторном пространстве.
Правила очистки были существенно упрощены (ага, сказочник), все сообщения, имена пользователей, были разбиты на предложения и выгружены в файл. Важный момент: ввиду краткости наших комментаторов, для построения качественных векторов, к словам нужна дополнительная контекстная информация, например, с форума и википедии. На полученном файле были обучены три модели: классический word2vec, Glove и FastText. После многих экспериментов окончательно остановился на FastText, как наиболее качественно выделяющей кластеры слов в моём случае.
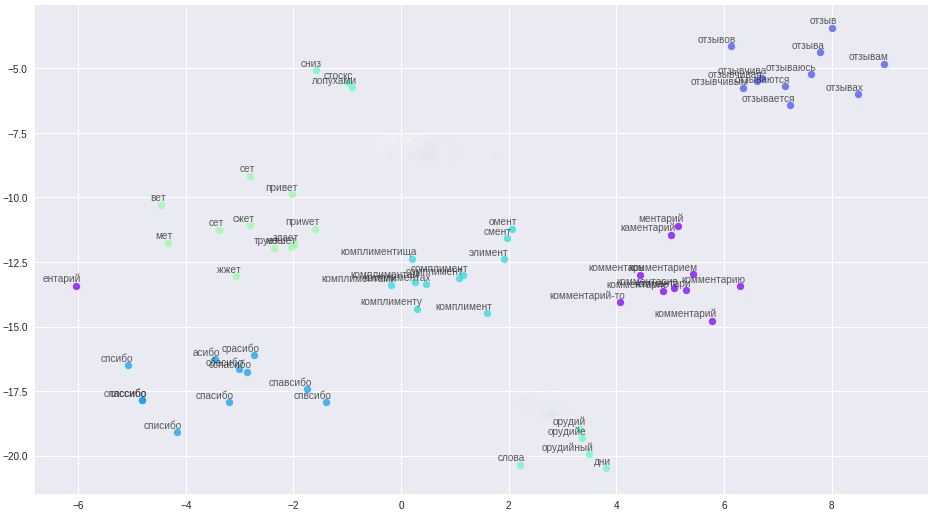
Все эти изменения принесли стабильные 84-85 процентов точности.
Примеры моделей
def model_conv_core(model_input, embd_size = 128): num_filters = 128 X = Embedding(total_unique_words, DIM, input_length=max_words, weights=[embedding_matrix], trainable=False, name='Word2Vec')(model_input) X = Conv1D(num_filters, 3, activation='relu', padding='same')(X) X = Dropout(0.3)(X) X = MaxPooling1D(2)(X) X = Conv1D(num_filters, 5, activation='relu', padding='same')(X) return X def model_conv1d(model_input, embd_size = 128, num_filters = 64, kernel_size=3): X = Embedding(total_unique_words, DIM, input_length=max_words, weights=[embedding_matrix], trainable=False, name='Word2Vec')(model_input) X = Conv1D(num_filters, kernel_size, padding='same', activation='relu', strides=1)(X) # X = Dropout(0.1)(X) X = MaxPooling1D(pool_size=2)(X) X = LSTM(256, kernel_regularizer=regularizers.l2(0.004))(X) X = Dropout(0.3)(X) X = Dense(128, kernel_regularizer=regularizers.l2(0.0004))(X) X = LeakyReLU()(X) X = BatchNormalization()(X) X = Dense(1, activation="sigmoid")(X) model = Model(model_input, X, name='w2v_conv1d') return model def model_gru(model_input, embd_size = 128): X = model_conv_core(model_input, embd_size) X = MaxPooling1D(2)(X) X = Dropout(0.2)(X) X = GRU(256, activation='relu', return_sequences=True, kernel_regularizer=regularizers.l2(0.004))(X) X = Dropout(0.5)(X) X = GRU(128, activation='relu', kernel_regularizer=regularizers.l2(0.0004))(X) X = Dropout(0.5)(X) X = BatchNormalization()(X) X = Dense(1, activation="sigmoid")(X) model = Model(model_input, X, name='w2v_gru') return model def model_conv2d(model_input, embd_size = 128): from keras.layers import MaxPool2D, Conv2D, Reshape num_filters = 256 filter_sizes = [3, 5, 7] X = Embedding(total_unique_words, DIM, input_length=max_words, weights=[embedding_matrix], trainable=False, name='Word2Vec')(model_input) reshape = Reshape((maxSequenceLength, embd_size, 1))(X) conv_0 = Conv2D(num_filters, kernel_size=(filter_sizes[0], embd_size), padding='valid', kernel_initializer='normal', activation='relu')(reshape) conv_1 = Conv2D(num_filters, kernel_size=(filter_sizes[1], embd_size), padding='valid', kernel_initializer='normal', activation='relu')(reshape) conv_2 = Conv2D(num_filters, kernel_size=(filter_sizes[2], embd_size), padding='valid', kernel_initializer='normal', activation='relu')(reshape) maxpool_0 = MaxPool2D(pool_size=(maxSequenceLength - filter_sizes[0] + 1, 1), strides=(1,1), padding='valid')(conv_0) maxpool_1 = MaxPool2D(pool_size=(maxSequenceLength - filter_sizes[1] + 1, 1), strides=(1,1), padding='valid')(conv_1) maxpool_2 = MaxPool2D(pool_size=(maxSequenceLength - filter_sizes[2] + 1, 1), strides=(1,1), padding='valid')(conv_2) X = concatenate([maxpool_0, maxpool_1, maxpool_2], axis=1) X = Dropout(0.2)(X) X = Flatten()(X) X = Dense(int(embd_size / 2.0), activation='relu', kernel_regularizer=regularizers.l2(0.004))(X) X = Dropout(0.5)(X) X = BatchNormalization()(X) X = Dense(1, activation="sigmoid")(X) model = Model(model_input, X, name='w2v_conv2d') return model
и еще 6 моделей в коде. Часть моделей взята из сети, часть придумана самостоятельно.
Было замечено, что на разных моделях выделялись разные комментарии, это натолкнуло на мысль воспользоваться ансамблями моделей. Сначала я собирал ансамбль вручную, выбирая наилучшие пары моделей, потом сделал генератор. С целью оптимизировать полный перебор — взял за основу код грея.
def gray_code(n): def gray_code_recurse (g,n): k = len(g) if n <= 0: return else: for i in range (k-1, -1, -1): char='1' + g[i] g.append(char) for i in range (k-1, -1, -1): g[i]='0' + g[i] gray_code_recurse (g, n-1) g = ['0','1'] gray_code_recurse(g, n-1) return g def gen_list(m): out = [] g = gray_code(len(m)) for i in range (len(g)): mask_str = g[i] idx = 0 v = [] for c in list(mask_str): if c == '1': v.append(m[idx]) idx += 1 if len(v) > 1: out.append(v) return out
С ансамблем «жизнь стала веселее» и текущий процент точности модели держится на уровне 86-87%, что связано по большей степени с некачественной классификацией части авторов в датасете.
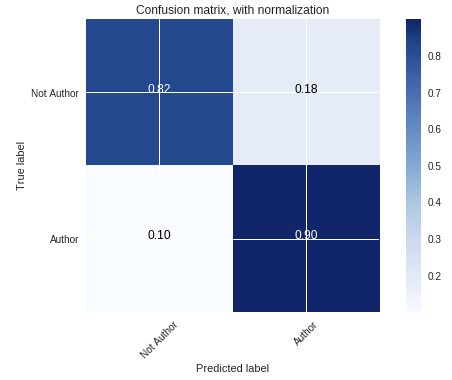
Встреченные мной проблемы:
- Несбалансированный датасет. Количество комментариев от авторов было существенно меньше остальных комментаторов.
- Классы в выборке идут в строгой очередности. Суть в том, что начало, середина и конец существенно отличаются по качеству классификации. Это хорошо заметно в процессе обучения по графику f1-меры.
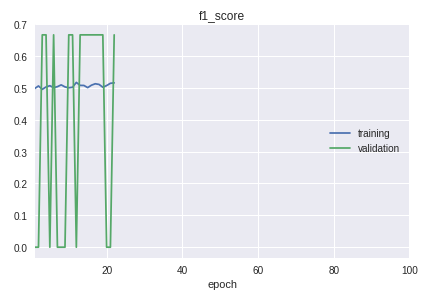
Для решения был сделан свой велосипед для разделения на обучающую и валидационную выборки. Хотя на практике в большинстве случаев хватит процедуры train_test_split из библиотеки sklearn.
Граф текущей рабочей модели:

В итоге я получил модель с уверенным определением авторов по коротким комментариям. Дальнейшие улучшение будет связано с очисткой и перенесением результатов классификации реальных данных в тренировочный датасет.
Весь код с дополнительными пояснениями в выложен репозитории.
В качестве постскриптума: если вам надо классифицировать большие объемы текста, взгляните на модель «Very Deep Convolutional Neural Network» VDCNN (реализация на keras), это аналог ResNet для текстов.
Использованные материалы:
• Обзор курсов по машинному обучению
• Анализ тональностей с помощью свёрток
• Сверточные сети в NLP
• Метрики в машинном обучении
https://ld86.github.io/ml-slides/unbalanced.html
• Взгляд внутрь модели

