Вступление
На конференции YOW! 2013 один из разработчиков языка Haskell, проф. Филип Вадлер, показал, как монады позволяют чистым функциональным языкам осуществлять императивные по сути операции, такие, как ввод-вывод и обработку исключений. Неудивительно, что интерес аудитории к этой теме породил взрывной рост публикаций о монадах в Интернет. К сожалению, бо́льшая часть этих публикаций использует примеры, написанные на функциональных языках, подразумевая, что о монадах хотят узнать новички в функциональном программировании. Но монады не специфичны для Haskell или функциональных языков, и вполне могут быть проиллюстрированы примерами на императивных языках программирования. Это и является целью данного руководства.
Чем это руководство отличается от остальных? Мы попытаемся не более чем за 15 минут «открыть» монады, используя лишь интуицию и несколько элементарных примеров кода на Python. Мы поэтому не станем теоретизировать и углубляться в философию, рассуждая о буррито, космических скафандрах, письменных столах и эндофункторах.
Мотивационные примеры
Мы рассмотрим три проблемы, относящиеся к композиции функций. Мы решим их двумя способами: обычным императивным и при помощи монад. Затем мы сравним разные подходы.
1. Логгирование
Допустим, у нас есть три унарные функции:
f1, f2 и f3, принимающие число и возвращающие его увеличенным на 1, 2 и 3 соответственно. Также каждая функция генерирует сообщение, представляющее собой отчёт о выполненной операции.def f1(x): return (x + 1, str(x) + "+1") def f2(x): return (x + 2, str(x) + "+2") def f3(x): return (x + 3, str(x) + "+3")
Мы хотели бы объединить их в цепочку для обработки параметра
x, иначе говоря, мы хотели бы вычислить x+1+2+3. Кроме того, нам нужно получить человекочитаемое объяснение того, что было сделано каждой функцией.Можно добиться нужного нам результата следующим способом:
log = "Ops:" res, log1 = f1(x) log += log1 + ";" res, log2 = f2(res) log += log2 + ";" res, log3 = f3(res) log += log3 + ";" print(res, log)
Это решение неидеально, так как состоит из большого количества однообразного связующего кода. Если мы захотим добавить к нашей цепочке новую функцию, мы вынуждены будем повторить этот связующий код. Кроме того, манипуляции с переменными
res и log ухудшают читаемость кода, мешая следить за основной логикой программы.В идеале, программа должна выглядеть как простая цепочка функций, вроде
f3(f2(f1(x))). К сожалению, типы данных, возвращаемых f1 и f2, не соответствуют типам параметров f2 и f3. Но мы можем добавить в цепочку новые функции:def unit(x): return (x, "Ops:") def bind(t, f): res = f(t[0]) return (res[0], t[1] + res[1] + ";")
Теперь мы можем решить проблему следующим образом:
print(bind(bind(bind(unit(x), f1), f2), f3))
Следующая диаграмма показывает вычислительный процесс, происходящий при
x=0. Здесь v1, v2 и v3 − значения, полученные в результате вызовов unit и bind.
Функция
unit преобразует входной параметр x в кортеж из числа и строки. Функция bind вызывает функцию, переданную ей в качестве параметра, и накапливает результат в промежуточной переменной t.Мы смогли избежать повторений связующего кода, поместив его в функцию
bind. Теперь, если у нас появится функция f4, мы просто включим её в цепочку:bind(f4, bind(f3, ... ))
И никаких других изменений нам делать не понадобится.
2. Список промежуточных значений
Этот пример мы также начнём с простых унарных функций.
def f1(x): return x + 1 def f2(x): return x + 2 def f3(x): return x + 3
Как и в предыдущем примере, нам нужно скомпоновать эти функции, чтобы вычислить
x+1+2+3. Также нам нужно получить список всех значений, полученных в результате работы наших функций, то есть x, x+1, x+1+2 и x+1+2+3.В отличие от предыдущего примера, наши функции компонуемы, то есть типы их входных параметров совпадают с типом результата. Поэтому простая цепочка
f3(f2(f1(x))) вернёт нам конечный результат. Но в таком случае мы потеряем промежуточные значения.Решим задачу «в лоб»:
lst = [x] res = f1(x) lst.append(res) res = f2(res) lst.append(res) res = f3(res) lst.append(res) print(res, lst)
К сожалению, это решение также содержит много связующего кода. И если мы решим добавить
f4, нам опять придётся повторять этот код, чтобы получить верный список промежуточных значений.Поэтому добавим две дополнительные функции, как и в предыдущем примере:
def unit(x): return (x, [x]) def bind(t, f): res = f(t[0]) return (res, t[1] + [res])
Теперь мы перепишем программу в виде цепочки вызовов:
print(bind(bind(bind(unit(x), f1), f2), f3))
Следующая диаграмма показывает вычислительный процесс, происходящий при
x=0. Снова v1, v2 и v3 обозначают значения, полученные в результате вызовов unit и bind.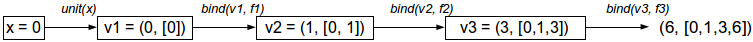
3. Пустые значения
Попробуем привести более интересный пример, на этот раз с классами и объектами. Допустим, у нас есть класс
Employee с двумя методами:class Employee: def get_boss(self): # Return the employee's boss def get_wage(self): # Compute the wage
Каждый объект класса
Employee имеет руководителя (другой объект класса Employee) и зарплату, доступ к которым осуществляется через соответствующие методы. Оба метода могут также возвращать None (работник не имеет руководителя, зарплата неизвестна).В этом примере мы создадим программу, которая показывает зарплату руководителя данного работника. Если руководитель не найден, или его зарплата не может быть определена, то программа вернёт
None.В идеале нам нужно написать что-то вроде
print(john.get_boss().get_wage())
Но в таком случае, если какой-то из методов вернёт
None, наша программа завершится с ошибкой.Очевидный способ учесть эту ситуацию может выглядеть так:
result = None if john is not None and john.get_boss() is not None and john.get_boss().get_wage() is not None: result = john.get_boss().get_wage() print(result)
В этом случае мы допускаем лишние вызовы методов
get_boss и get_wage. Если эти методы достаточно тяжелы (например, обращаются к базе данных), наше решение не годится. Поэтому изменим его:result = None if john is not None: boss = john.get_boss() if boss is not None: wage = boss.get_wage() if wage is not None: result = wage print(result)
Этот код оптимален в плане вычислений, но плохо читается за счёт трёх вложенных
if. Поэтому попробуем использовать тот же трюк, что и в предыдущих примерах. Определим две функции:def unit(e): return e def bind(e, f): return None if e is None else f(e)
И теперь мы можем скомпоновать всё решение в одну строку.
print(bind(bind(unit(john), Employee.get_boss), Employee.get_wage))
Как вы, наверное, уже заметили, в этом случае нам не обязательно было писать функцию
unit: она просто возвращает входной параметр. Но мы оставим её, чтобы нам легче было потом обобщить наш опыт.Обратите внимание также на то, что в Python мы можем использовать методы как функции, что позволило нам написать
Employee.get_boss(john) вместо john.get_boss().Следующая диаграмма показывает процесс вычислений в том случае, когда у Джона нет руководителя, то есть
john.get_boss() возвращает None.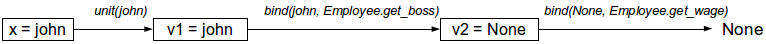
Выводы
Допустим, мы хотим объединить однотипные функции
f1, f2, …, fn. Если их входные параметры совпадают по типу с результатами, мы можем использовать простую цепочку вида fn(… f2(f1(x)) …). Следующая диаграмма показывает обобщённый процесс вычислений с промежуточными результатами, обозначенными как v1, v2, …, vn.
Зачастую этот подход неприменим. Типы входных значений и результатов функций могут различаться, как в первом примере. Либо же функции могут быть компонуемы, но мы хотим вставить дополнительную логику между вызовами, как в примерах 2 и 3 мы вставляли аггрегацию промежуточных значений и проверку на пустое значение соответственно.
1. Императивное решение
Во всех примерах мы вначале использовали самый прямолинейный подход, который можно отобразить следующей диаграммой:

Перед вызовом
f1 мы выполняли некоторую инициализацию. В первом примере мы инициализировали переменную для хранения общего лога, во втором − для списка промежуточных значений. После этого мы перемежали вызовы функций неким связующим кодом: вычисляли агрегатные значения, проверяли результат на None.2. Монады
Как мы видели на примерах, императивные решения всегда страдали многословностью, повторениями и запутанной логикой. Чтобы получить более элегантный код, мы использовали некий шаблон проектирования, согласно которому мы создавали две функции:
unit и bind. Этот шаблон и называется монадой. Функция bind содержит связующий код, в то время, как unit осуществляет инициализацию. Это позволяет упростить итоговое решение до одной строки:bind(bind( ... bind(bind(unit(x), f1), f2) ... fn-1), fn)
Процесс вычисления можно представить диаграммой:

Вызов
unit(x) генерирует начальное значение v1. Затем bind(v1, f1) генерирует новое промежуточное значение v2, которое используется в следующем вызове bind(v2, f2). Этот процесс продолжается, пока не будет получен итоговый результат. Определяя различные unit и bind в рамках этого шаблона, мы можем объединять различные функции в одну цепочку вычислений. Библиотеки монад (например, PyMonad или OSlash, − прим. перев.) обычно содержат готовые к употреблению монады (пары функций unit и bind) для реализации определённых композиций функций.Чтобы собрать функции в цепочку, значения, возвращаемые
unit и bind, должны быть того же типа, что и входные параметры bind. Этот тип называется монадическим. В терминах вышеприведённой диаграммы, тип переменных v1, v2, …, vn должен быть монадическим типом.Наконец, рассмотрим, как можно улучшить код, написанный с использованием монад. Очевидно, повторяющиеся вызовы
bind выглядят неэлегантно. Чтобы избежать этого, определим ещё одну внешнюю функцию:def pipeline(e, *functions): for f in functions: e = bind(e, f) return e
Теперь вместо
bind(bind(bind(bind(unit(x), f1), f2), f3), f4)
мы можем использовать следующее сокращение:
pipeline(unit(x), f1, f2, f3, f4)
Заключение
Монады − это простой и мощный шаблон проектирования, используемый для композиции функций. В декларативных языках программирования он помогает реализовать такие императивные механизмы, как логгирование или ввод/вывод. В императивных языках
он помогает обобщить и сократить код, связывающий серию вызовов однотипных функций.
Эта статья даёт только поверхностное, интуитивное понимание монад. Вы можете узнать больше, обратившись к следующим источникам:

