Всем привет, хочу поделиться с общественностью некоторым объемом информации, который как мне показалось трудно найти в интернете.
Что такое дерево, смотрим Википедию.

Рис.1 Пример дерева.
Итак, зачем вообще может понадобится обходить дерево в несколько потоков? В моем случае, это была необходимость поиска файлов на диске. Понятно, что физически диск работает в один поток, но тем не менее, многопоточный поиск файлов может дать ускорение, в случае, когда один-единственный поток ищет файл в многоуровневой иерархии, а искомый файл лежит в соседней папке с одним уровнем. Также доказательством актуальности применения многопоточного поиска служит его реализации во многих успешных коммерческих продуктах. Не исключаю, что возможны и другие варианты применения алгоритма, пишите в комментариях.
Для начала предлагаю рассмотреть анимацию:
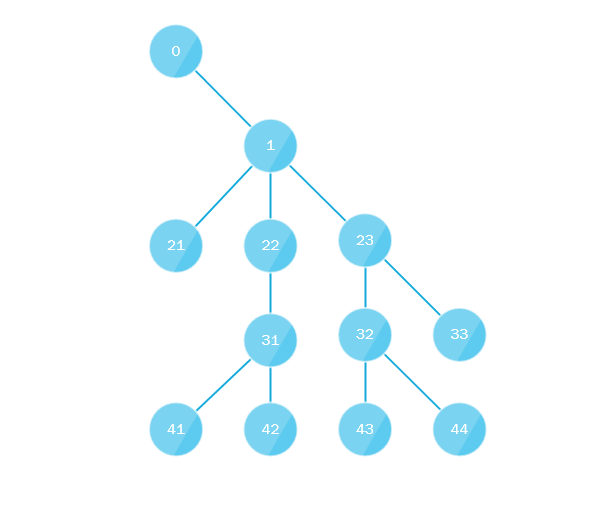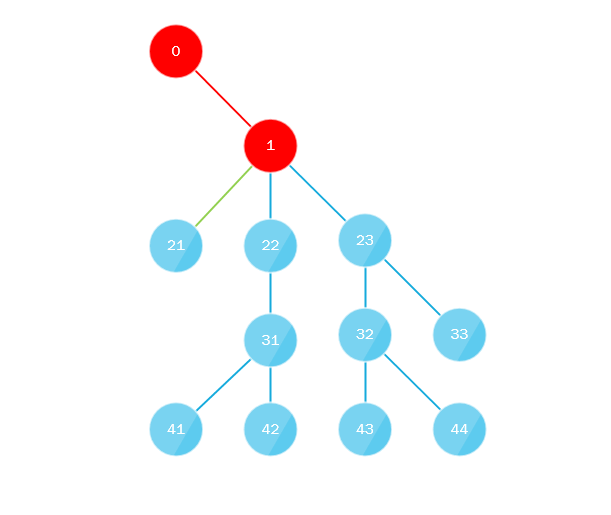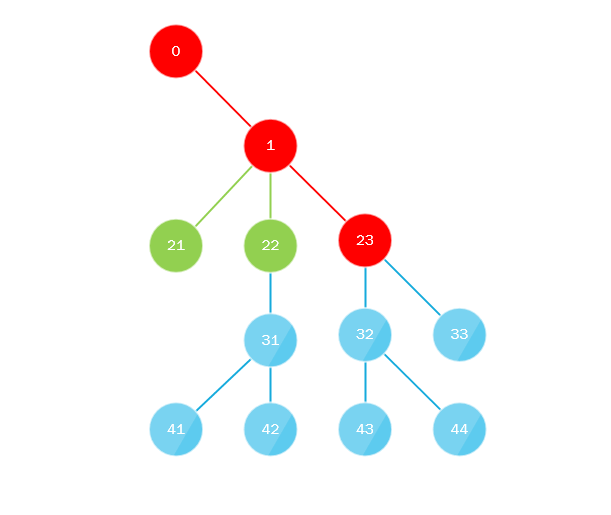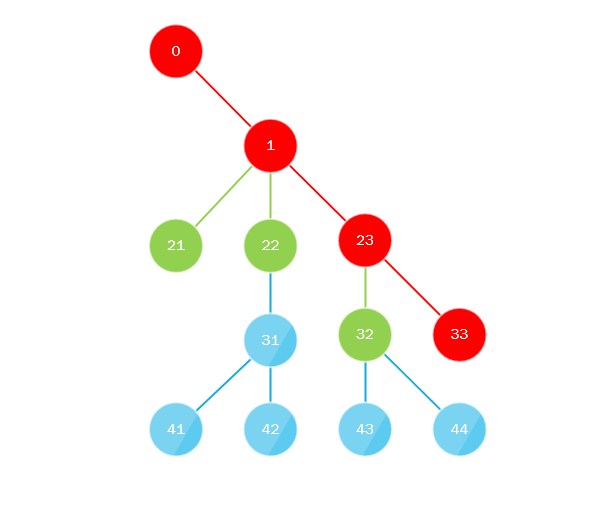
Что здесь происходит? Вся суть алгоритма сводится к тому, что:
По сути дела, в целом алгоритм выглядит так (один цвет – один поток):

Привожу пример кода, который может кому-то пригодится, я его долго искал, но так и не нашел:
Как видно многопоточность в Java можно реализовать достаточно просто посредством BlockingQueue, структуры данных реализующей доступ нескольких потоков к хранимым данных.
В общем-то это и все, если вкратце, пишите комментарии о том какие еще есть способы или методы обхода дерева, хотелось бы услышать мнение гуру в этом вопросе. Пишите вопросы, пожелания.
P.S. также советую всем прочитать комментарии (там много интересного)
Ссылка на GitHub. Там же рядом лежит поисковик на JavaFX, если кто-то захочет потестить, то я только буду рад.
Что такое дерево, смотрим Википедию.
Рис.1 Пример дерева.
Итак, зачем вообще может понадобится обходить дерево в несколько потоков? В моем случае, это была необходимость поиска файлов на диске. Понятно, что физически диск работает в один поток, но тем не менее, многопоточный поиск файлов может дать ускорение, в случае, когда один-единственный поток ищет файл в многоуровневой иерархии, а искомый файл лежит в соседней папке с одним уровнем. Также доказательством актуальности применения многопоточного поиска служит его реализации во многих успешных коммерческих продуктах. Не исключаю, что возможны и другие варианты применения алгоритма, пишите в комментариях.
Для начала предлагаю рассмотреть анимацию:
Что здесь происходит? Вся суть алгоритма сводится к тому, что:
- Первый поток обходит дерево начиная с корня на всю глубину по «крайне левому» пути, т.е. всегда при перемещении вглубь поворачивает налево или другими словами всегда выбирает последний дочерний узел.
- Параллельно первый поток собирает все пропущенные дочерние узлы и отправляет их в очередь (либо в стек) где их забирает другой поток, очередь или стек должны реализовывать многопоточный подход, и алгоритм повторяется, подставляя на место корня только-что взятый узел.
По сути дела, в целом алгоритм выглядит так (один цвет – один поток):
По сути дела, в целом алгоритм выглядит так (один цвет – один поток):
Программная реализация на Java
Привожу пример кода, который может кому-то пригодится, я его долго искал, но так и не нашел:
import java.io.File; import java.util.concurrent.BlockingQueue; import java.util.concurrent.Executor; import java.util.concurrent.Executors; import java.util.concurrent.LinkedBlockingDeque; public class MultiThreadTreeWalker extends Thread { private static BlockingQueue<File> nodesToReview = new LinkedBlockingDeque<>(); private File f; public MultiThreadTreeWalker(File f) { this.f = f; } public MultiThreadTreeWalker() { } public static void main(String[] args) { Executor ex = Executors.newFixedThreadPool(2); MultiThreadTreeWalker mw = new MultiThreadTreeWalker(new File("C:\\")); mw.run(); for (int i = 0;i<2;i++) { ex.execute(new MultiThreadTreeWalker()); } } @Override public void run() { if (f != null) { //только для первого потока reviewFileSystem(f); } else { try { while (true) { f = nodesToReview.take(); reviewFileSystem(f); } } catch (InterruptedException e) { e.printStackTrace(); } } } void reviewFileSystem(File f) { if (f == null) { return; } if (f.isFile()) { //завершение обхода (+дополнительная логика) System.out.println("Файл " + f.getName() + " найден потоком " + Thread.currentThread()); return; } File[] files = f.listFiles(); if (files.length != 0) { for (int i = 0; i < files.length - 1; i++) { nodesToReview.add(files[i]); //добавление файлов всех кроме последнего } //последний дочерний узел используется для перехода дальше File last = files[files.length - 1]; reviewFileSystem(last); } } }
Заключение
Как видно многопоточность в Java можно реализовать достаточно просто посредством BlockingQueue, структуры данных реализующей доступ нескольких потоков к хранимым данных.
В общем-то это и все, если вкратце, пишите комментарии о том какие еще есть способы или методы обхода дерева, хотелось бы услышать мнение гуру в этом вопросе. Пишите вопросы, пожелания.
P.S. также советую всем прочитать комментарии (там много интересного)
Ссылка на GitHub. Там же рядом лежит поисковик на JavaFX, если кто-то захочет потестить, то я только буду рад.

