Привет, Хабр. Не так давно для одного моего проекта понадобилась встраиваемая база данных, которая бы хранила элементы в виде ключ-значение, обеспечивала поддержку транзакций, и, опционально, шифровала данные. После непродолжительных поисков, я наткнулся на проект Berkeley DB. Кроме нужных мне возможностей, эта БД предоставляет STL-совместимый интерфейс, который позволяет работать с базой данных, как с обычным (почти обычным) STL-контейнером. Собственно про этот интерфейс речь пойдет ниже.
Berkeley DB
Berkeley DB — это встраиваемая масштабируемая высокопроизводительная БД с открытым исходным кодом. Она доступна бесплатно для использования в open source проектах, но для проприетарных есть существенные ограничения. Поддерживаемые возможности:
- транзакции
- лог с упреждающей записью для восстановления после отказов
- шифрование данных алгоритмом AES
- репликация
- индексы
- средства синхронизации для многопоточных приложений
- политика доступа — один писатель, множество читателей
- кеширование
А так же многие другие.
При инициализации системы пользователь может указать, какие подсистемы использовать. Это позволяет исключить трату ресурсов на такие операции, как транзакции, логирование, блокировки, когда они не нужны.
Доступен выбор структуры хранения и доступа к данным:
- Btree — реализация отсортированного сбалансированного дерева
- Hash — имплементация линейного хеша
- Heap — для хранения использует heap file, логически разбитый на страницы. Каждая запись идентифицируется страницей и смещением внутри нее. Хранилище организовано таким образом, что удаление записи не требует уплотнения. Это позволяет использовать его при недостатке физического места.
- Queue — очередь, хранит записи фиксированной длины с логическим номером в качестве ключа. Она спроектирована для быстрой вставки в конец, и поддерживает специальную операцию, которая удаляет и возвращает запись из головы очереди за один вызов.
- Recno — позволяет сохранить записи как фиксированной, так и переменной длины с логическим номером в качестве ключа. Обеспечивает доступ к элементу по его индексу.
Чтобы избежать неоднозначности, необходимо определить несколько понятий, которые используются при описании работы Berkeley DB.
База данных — хранилище данных в виде ключ-значение. Аналогом базы данных Berkeley DB в других СУБД может служить таблица.
Среда баз данных — оболочка для одной или нескольких баз данных. Определяет общие настройки для всех баз данных, такие как размер кеша, пути хранения файлов, использование и конфигурацию подсистем блокировки, транзакций, логирования.
В типичном случае использования создается и настраивается среда, а в ней одна или несколько баз данных.
STL-интерфейс
Berkeley DB представляет из себя библиотеку, написанную на С. Она имеет биндинги к таким языкам, как Perl, Java, PHP и другие. Интерфейс для С++ представляет из себя оболочку над С кодом с объектами и наследованием. Для того, чтобы сделать возможным доступ к базе данных аналогично операциям с STL-контейнерами, имеется STL-интерфейс, как надстройка над С++. В графическом виде слои интерфейсов выглядят так:
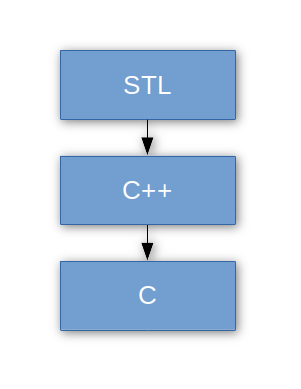
Так, STL-интерфейс позволяет получить элемент из базы данных по ключу (для Btree или Hash) или по индексу (для Recno) аналогично контейнерам std::map или std::vector, найти элемент в БД через стандартный алгоритм std::find_if, проитерировать по всей базе через цикл foreach. Все классы и функции STL-интерфейса Berkeley DB находятся в пространстве имен dbstl, для сокращения, под dbstl будет подразумеваться так же и STL-интерфейс.
Установка
База данных поддерживает большинство Linux-платформ, Windows, Android, Apple iOS и пр.
Для Ubuntu 18.04 достаточно установить пакеты:
- libdb5.3-stl-dev
- libdb5.3++-dev
Для сборки из исходников под Linux необходимо установить autoconf и libtool. Последнюю версию исходных кодов можно найти по ссылке.
Для примера я скачал архив с версией 18.1.32 — db-18.1.32.zip. Необходимо распаковать архив и перейти в папку с исходниками:
unzip db-18.1.32.zip cd db-18.1.32
Далее перемещаемся в директорию build_unix и запускаем сборку и установку:
cd build_unix ../dist/configure --enable-stl --prefix=/home/user/libraries/berkeley-db make make install
Добавление в cmake-проект
Для иллюстрации примеров с Berkeley DB используется проект BerkeleyDBSamples.
Структура проекта выглядит следующим образом:
+-- CMakeLists.txt +-- sample-usage | +-- CMakeLists.txt | +-- sample-map-usage.cpp | +-- submodules | +-- cmake | | +-- FindBerkeleyDB
Корневой CMakeLists.txt описывает общие параметры проекта. Исходные файлы с примерами находятся в sample-usage. sample-usage/CMakeLists.txt выполняет поиск библиотек, определяет сборку примеров.
Для подключения библиотеки в проект cmake в примерах применяется FindBerkeleyDB. Он добавлен как подмодуль git в submodules/cmake. При сборке может потребоваться указать BerkeleyDB_ROOT_DIR. Например, для библиотеки выше, установленной из исходников, необходимо указать флаг cmake -DBerkeleyDB_ROOT_DIR=/home/user/libraries/berkeley-db.
В корневом файле CMakeLists.txt необходимо добавить в CMAKE_MODULE_PATH путь к модулю FindBerkeleyDB:
list(APPEND CMAKE_MODULE_PATH "${CMAKE_CURRENT_SOURCE_DIR}/submodules/cmake/FindBerkeleyDB")
После этого в sample-usage/CMakeLists.txt выполняется поиск библиотеки стандартным образом:
find_package(BerkeleyDB REQUIRED)
Далее, добавляем исполняемый файл и линкуем его с библиотекой Oracle::BerkeleyDB:
add_executable(sample-map-usage "sample-map-usage.cpp") target_link_libraries(sample-map-usage PRIVATE Oracle::BerkeleyDB ${CMAKE_THREAD_LIBS_INIT} stdc++fs)
Практический пример
Для демонстрации применения dbstl разберем простой пример из файла sample-map-usage.cpp. Это приложение демонстрирует работу с контейнером dbstl::db_map в однопоточной программе. Сам контейнер аналогичен std::map и хранит данные в виде пары ключ/значение. В качестве нижележащей структуры БД может использоваться Btree или Hash. В отличии от std::map, для контейнера dbstl::db_map<std::string, TestElement> фактическим типом значения является dbstl::ElementRef<TestElement>. Этот тип возвращается, например, для dbstl::db_map<std::string, TestElement>::operator[]. Он определяет методы для сохранения объекта типа TestElement в БД. Одним из таких методов является operator=.
В примере работа с базой происходит следующим образом:
- приложение вызывает методы Berkeley DB для доступа к данным
- эти методы обращаются к кешу для чтения или записи
- при необходимости идет обращение непосредственно к файлу с данными
Графически этот процесс показан на рисунке:

Для уменьшения сложности примера, в нем не используется обработка исключений. Некоторые методы контейнеров dbstl могут выбрасывать исключения при возникновении ошибок.
Разбор кода
Для работы c Berkeley DB необходимо подключить два заголовочных файла:
#include <db_cxx.h> #include <dbstl_map.h>
Первый — добавляет примитивы интерфейса C++, а второй — определяет классы и функции для работы с БД, как с ассоциативным контейнером, а так же многие служебные методы. STL-интерфейс располагается в пространстве имен dbstl.
Для хранения используется структура Btree, в качестве ключа выступает std::string, а значением — пользовательская структура TestElement:
struct TestElement{ std::string id; std::string name; };
В функции main инициализируем библиотеку вызовом dbstl::dbstl_startup(). Он должен располагаться до первого использования примитивов STL-интерфейса.
После этого инициализируем и откроем среду баз данных в директории, которая задана переменной ENV_FOLDER:
auto penv = dbstl::open_env(ENV_FOLDER, 0u, DB_INIT_MPOOL | DB_CREATE);
Флаг DB_INIT_MPOOL отвечает за инициализацию подсистемы кеширования, DB_CREATE — за создание всех необходимых среде файлов. Так же команда регистрирует данный объект в менеджере ресурсов. Он несет ответственность за закрытие всех зарегистрированных объектов (в нем регистрируются так же объекты баз данных, курсоры, транзакции и пр) и очистку динамической памяти. Если уже есть объект среды баз данных и его нужно только зарегистрировать в менеджере ресурсов, то можно воспользоваться функцией dbstl::register_db_env.
Подобная операция выполняется и с базой данных:
auto db = dbstl::open_db(penv, "sample-map-usage.db", DB_BTREE, DB_CREATE, 0u);
Данные на диск будут записаны в файл sample-map-usage.db, который будет создан при отсутствии (благодаря флагу DB_CREATE) в директории ENV_FOLDER. Для хранения используется дерево (параметр DB_BTREE).
В Berkeley DB ключи и значения хранятся как массив байт. Для применения пользовательского типа (в нашем случае TestElement) необходимо задать функции для:
- получения количества байт под хранения объекта;
- маршалинга объекта в массив байт;
- демаршалинга.
В примере этот функционал выполняют статические методы класса TestMarshaller. Он располагает объекты TestElement в памяти, следующим образом:
- в начало буфера копируется значение длины поля
id - следом побайтово размещается само содержимое поле
id - после него копируется размер поля
name - далее помещается само содержимое из поля
name

Опишем функции TestMarshaller:
TestMarshaller::restore— заполняет данными из буфера объектTestElementTestMarshaller::size— возвращает размер буфера, который необходим для сохранения указанного объекта.TestMarshaller::store— сохраняет объект в буфере.
Для регистрации функций маршалинга/демаршалинга используется dbstl::DbstlElemTraits:
dbstl::DbstlElemTraits<TestElement>::instance()->set_size_function(&TestMarshaller::size); dbstl::DbstlElemTraits<TestElement>::instance()->set_copy_function(&TestMarshaller::store); dbstl::DbstlElemTraits<TestElement>::instance()->set_restore_function( &TestMarshaller::restore );
Инициализируем контейнер:
dbstl::db_map<std::string, TestElement> elementsMap(db, penv);
Вот так выглядит копирование элементов из std::map в созданный контейнер:
std::copy( std::cbegin(inputValues), std::cend(inputValues), std::inserter(elementsMap, elementsMap.begin()) );
А вот таким образом можно распечатать содержимое БД на стандартный вывод:
std::transform( elementsMap.begin(dbstl::ReadModifyWriteOption::no_read_modify_write(), true), elementsMap.end(), std::ostream_iterator<std::string>(std::cout, "\n"), [](const auto data) -> std::string { return data.first + "=> { id: " + data.second.id + ", name: " + data.second.name + "}"; });
Немного необычно выглядит вызов метода begin в примере выше: elementsMap.begin(dbstl::ReadModifyWriteOption::no_read_modify_write(), true).
Такая конструкция используется для получения итератора только на чтение. dbstl не определяет метода cbegin, вместо этого используется параметр readonly (второй по счету) в методе begin. Так же можно использовать константную ссылку на контейнер, чтобы получить итератор только на чтение. Такой итератор разрешает только операцию чтения, при выполнении записи он выбросит исключение.
Почему в коде выше используется итератор только на чтение? Во-первых, выполняется всего лишь операция чтения через итератор. Во-вторых, в документации говорится о том, что он имеет лучшую производительность, по сравнению с обычной версией.
Добавить новую пару ключ/значение, или, если ключ уже существует, обновить значение, так же просто, как и в std::map:
elementsMap["added key 1"] = {"added id 1", "added name 1"};
Как указывалось выше, интрукция elementsMap["added key 1"] возвращает класс-оболочку, у которой переопределен operator=, последующий вызов которого выполняет непосредственое сохранение объекта в базе.
Если необходимо вставить элемент в контейнер:
auto [iter, res] = elementsMap.insert( std::make_pair(std::string("added key 2"), TestElement{"added id 2", "added name 2"}) );
Вызов elementsMap.insert возвращает std::pair<итератор, флаг успешности>. Если вставить объект не удалось, то флаг успешности будет false. В противном случае флаг успешности содержит true, а итератор указывает на вставленный объект.
Еще одним способом найти значение по ключу является использование метода dbstl::db_map::find, аналогичному std::map::find:
auto findIter = elementsMap.find("test key 1");
Через полученный итератор можно выполнить доступ к ключу — findIter->first, к полям элемента TestElement — findIter->second.id и findIter->second.name. Для извлечения пары ключ/значение используется оператор разыменования -auto iterPair = *findIter;.
При применении к итератору оператора разыменования (*) или доступа к члену класса (->) происходит обращение к БД и извлечение из нее данных. Причем ранее извлеченные данные, даже если их модифицировали, затираются. Это означает, что в примере ниже, изменения, выполненные над итератором, будут отброшены, и на консоль выведено значение, хранившееся в базе данных.
findIter->second.id = "skipped id"; findIter->second.name = "skipped name"; std::cout << "Found elem for key " << "test key 1" << ": id: " << findIter->second.id << ", name: " << findIter->second.name << std::endl;
Чтобы этого избежать необходимо получить враппер хранимого объекта из итератора вызовом findIter->second и сохранить его в переменную. Далее, все изменения произвести над этим враппером, а результат записать в БД вызвав метод враппера _DB_STL_StoreElement:
auto ref = findIter->second; ref.id = "new test id 1"; ref.name = "new test name 1"; ref._DB_STL_StoreElement();
Обновить данные можно еще проще — просто получить враппер инструкцией findIter->second и присвоить ему нужный объект TestElement, как в примере:
if(auto findIter = elementsMap.find("test key 2"); findIter != elementsMap.end()){ findIter->second = {"new test id 2", "new test name 2"}; }
Перед завершением программы необходимо вызвать dbstl::dbstl_exit(); для закрытия и удаления всех зарегистрированных объектов в менеджере ресурсов.
В заключении
В этой статье сделан краткий обзор основных возможностей контейнеров dbstl на примере dbstl::db_map в простой однопоточной программе. Это лишь небольшое введение и здесь не рассмотрены такие возможности, как транзакционность, блокировки, управление ресурсами, обработка исключений и выполнение в многопоточной среде.
Я не ставил своей целью подробно описать методы и их параметры, для этого лучше обратиться к соответствующей документации по C++ интерфейсу и по STL-интерфейсу

