
Сегодня, команда Micronaut в Object Computing Inc (OCI) представила Predator, новый проект с открытым исходным кодом, цель которого — значительно улучшить время выполнения и производительность (по памяти) доступа к данным для микросервисов и serverless-приложений, при этом не потеряв в продуктивности по сравнению с такими инструментами, как GORM и Spring Data.
История инструментов доступа к данным
Мы можем отследить историю шаблона репозиторий (data repository) с 2004 года, когда вышел Ruby on Rails с подсистемой ActiveRecord — API, который перевернул наше представление о доступе к данным с точки зрения продуктивности разработчика.
В 2007, команда Grails впервые представила API, похожий на ActiveRecord, для JVM — GORM (часть Grails). GORM полагался на динамическую природу языка Groovy для реализации методов поиска поверх Hibernate и предоставлял те же преимущества по части продуктивности для пользователей JVM.
Поскольку GORM зависит от языка Groovy, в 2011 году был создан проект Spring Data, позволивший Java разработчикам определять методы поиска, такие как findByTitle, в интерфейсе, а логику запроса автоматически реализовывать во время выполнения.
Как работают инструменты доступа к данным
Все упомянутые реализации используют один и тот же шаблон, который заключается в построении метамодели сущностей проекта во время выполнения, которая моделирует отношения между вашими классами сущностей. В Spring Data это MappingContext, и в GORM это тоже называется MappingContext. Они конструируются путём сканирования классов при помощи рефлексии. (Сходство в именовании здесь не случайно. В 2010, я работал с командой Spring Data, чтобы попытаться воссоздать GORM для Java, над проектом, который в конечном итоге превратился в то, что сегодня называется Spring Data)
Затем эта метамодель используется для преобразования поискового выражения, такого как bookRepository.findByTitle("The Stand"), в абстрактную модель запроса во время выполнения при помощи комбинации разбора регулярными выражениями и логики фреймворка. Нам требуется абстрактная модель запросов, поскольку целевой диалект запроса отличается для каждой базы данных (SQL, JPA-QL, Cypher, Bson и т.д.)
Поддержка репозиториев в Micronaut
С момента запуска Micronaut чуть больше года назад основной недостающей возможностью, о которой нас просили, был "GORM для Java" или поддержка Spring Data. Так много разработчиков влюблены в продуктивность, которую дают эти инструменты, а также в простоту определения интерфейсов, которые реализует фреймворк. Я бы сказал, что большую часть успеха Grails и Spring Boot можно отнести к GORM и Spring Data соответственно.
Для пользователей Micronaut, использующих Groovy, у нас была поддержка GORM с первого дня, а пользователи Java и Kotlin оставались ни с чем, ведь им нужно было реализовать репозитории самостоятельно.
Было бы технически возможно, и откровенно проще, просто добавить модуль для Micronaut, который бы настроил Spring Data. Однако, пройдя по этому пути, мы предоставили бы подсистему, реализованную с использованием всех тех методов, которых Micronaut пытался избежать: широкое использование прокси, рефлексии и высокое потребление памяти.
Представляем Predator!
Predator — сокращение от Precomputed Data Repositories, использует API Micronaut для компиляции перед исполнением (AoT, ahead-of-time), чтобы перенести мета-модель сущностей и преобразование поисковых выражений (таких как findByTitle) в соответствующий SQL или JPA-QL в ваш компилятор. В итоге запрос исполняет очень тонкий программный слой времени исполнения без рефлексии, а ему остаётся только запустить запрос и вернуть результаты.
Результат ошеломляет… значительно сокращается холодный старт, мы получаем удивительно низкое потребление памяти и резкое улучшение производительности.
Сегодня мы открываем исходный код Predator под лицензией Apache 2, он будет поставляться с двумя начальными реализациями (больше возможностей запланировано на будущее) для JPA (на базе Hibernate) и для SQL с JDBC.
Реализация JDBC радует меня больше всего, так как она полностью независима от рефлексии, не использует прокси и динамическую загрузку классов для вашего уровня доступа к данным, что приводит к улучшению производительности. Слой времени выполнения настолько лёгок, что даже код эквивалентного репозитория, написанный вручную, не будет исполняться быстрее.
Производительность Predator
Поскольку Predator не нужно исполнять какие-либо преобразования запроса во время исполнения, выигрыш в производительности получается значительным. В мире утилизации облачных вычислений, где вы платите за количество времени, в течение которого ваше приложение работает, или за время выполнения отдельной функции, разработчики часто упускают из виду производительность своих механизмов доступа к данным.
В следующей таблице приведены различия в производительности, которые можно ожидать для простого выражения поиска, такого как findByTitle, по сравнению с другими реализациями. Все тесты были выполнены с использованием тестового стенда на 8-ядерном Xeon iMac Pro при одних и тех же условиях, тесты открыты и их можно найти в репозитории:
| Реализация | Операций в секунду |
|---|---|
| Predator JDBC | 225K ops/sec |
| Predator JPA | 130K ops/sec |
| Spring Data JPA | 90K ops/sec |
| GORM JPA | 50K ops/sec |
| Spring Data JDBC | Finders Not Supported |
Да, вы прочитали всё верно. С Predator JDBC, вы можете ожидать почти 4X кратное увеличение производительности по сравнению с GORM и 2.5X по сравнению со Spring Data.
И даже если вы используете Predator JPA, вы можете рассчитывать на более чем 2X кратное повышение производительности по сравнению с GORM и до 40% увеличения по сравнению со Spring Data JPA.
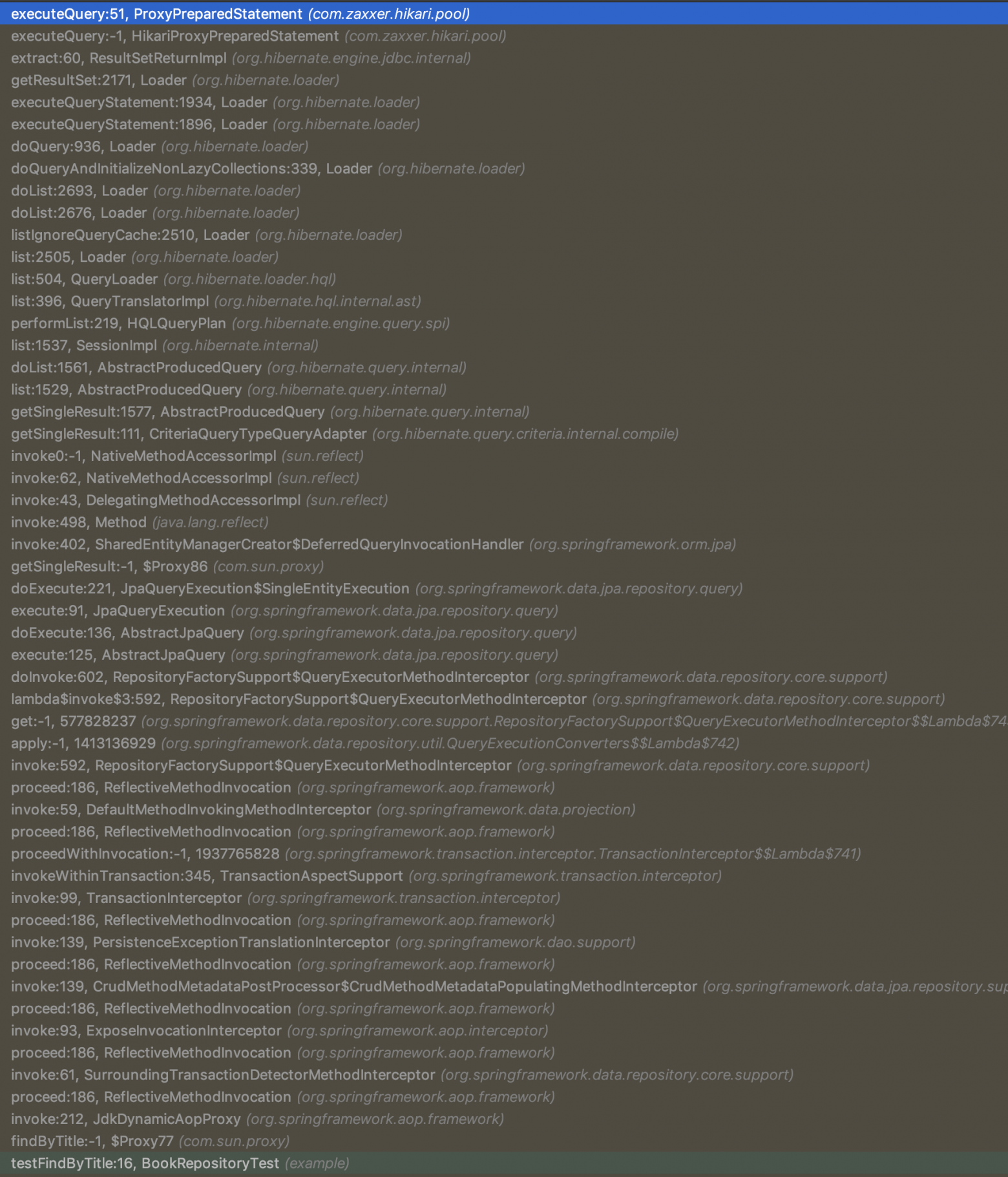
Посмотрите на разницу в размере стека исполнения при использовании Predator по сравнению с альтернативами:
Predator:

Predator JPA:

Spring Data:
GORM:
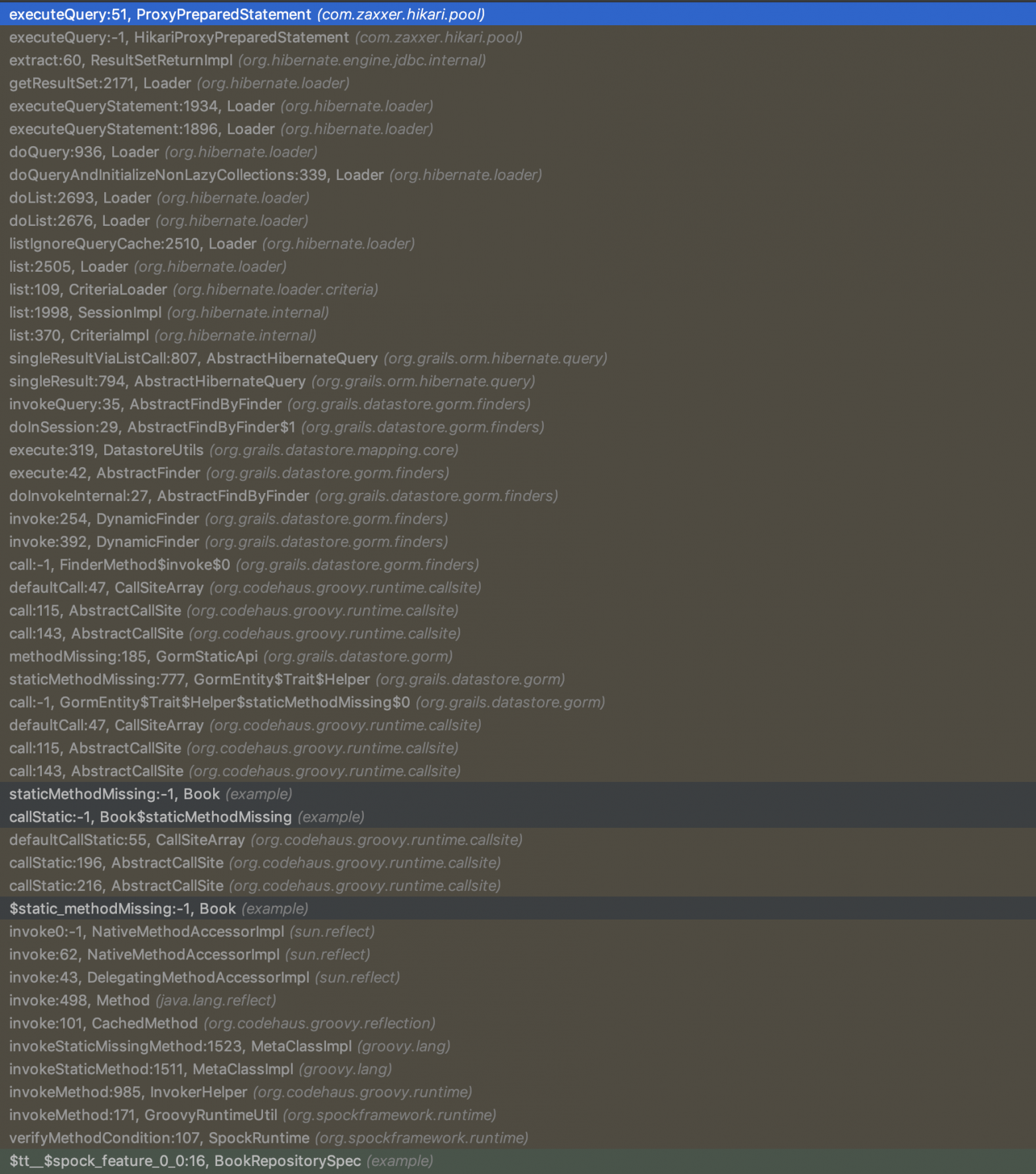
Predator JDBC использует всего 15 фреймов до момента, когда ваш запрос будет выполнен, в то время как Predator JPA использует 30 (в основном из за Hibernate), по сравнению с 50+ фреймами стека у Spring Data или GORM. И всё благодаря AOP механизмам Micronaut, не использующим рефлексию.
Более короткие стактрейсы также упрощают отладку приложений. Одним из преимуществ выполнения большей части работы во время компиляции является то, что ошибки могут быть обнаружены до запуска приложения, что значительно улучшает опыт разработчика. Мы получаем ошибки компиляции немедленно вместо ошибок времени выполнения для самых распространённых ошибок.
Проверки времени компиляции
Большинство реализаций шаблона репозиторий полагаются исключительно на выполнение всех операций во время выполнения. Это означает, что если разработчик ошибается в определении интерфейса репозитория, ошибки не будут видны то тех пор, пока приложение фактически не будет запущено.
Это лишает нас некоторых преимуществ Java для проверки типов и мы получаем плохой опыт работы с данными. С Predator это не так. Рассмотрим следующий пример:
@JdbcRepository(dialect = Dialect.H2) public interface BookRepository extends CrudRepository<Book, Long> { Book findByTile(String t); }
Здесь BookRepository мы объявили запрос к объекту с именем Book, у которого есть свойство title. К сожалению, в этом объявлении есть ошибка: мы назвали метод findByTile вместо findByTitle. Вместо того, чтобы запускать этот код, Predator не позволит вашему коду скомпилироваться с информативным сообщением об ошибке:
Error:(9, 10) java: Unable to implement Repository method: BookRepository.findByTile(String title). Cannot use [Equals] criterion on non-existent property path: tile
Многие аспекты Predator проверяются во время компиляции, когда это возможно, чтобы убедиться в том, что ошибка во время выполнения не вызвана некорректным объявлением репозитория.
Predator JDBC и GraalVM Substrate
Ещё одна причина, по которой стоит порадоваться Predator, — это то, что он совместим "из коробки" с нативными образами GraalVM Substrate и не требует сложных преобразований байт-кода во время сборки, в отличие от таковых для работы Hibernate на GraalVM.
Полностью исключая рефлексию и динамические прокси из слоя доступа к данным, Predator значительно упрощает создание приложений, работающих с данными, запускаемых на GraalVM.
Пример приложения Predator JDBC без проблем работает на Substrate и позволяет создать значительно меньший нативный образ (на 25 MB меньше!), чем требуется для работы Hibernate, благодаря гораздо более тонкому слою времени исполнения.
Мы увидели тот же результат, когда реализовали компиляцию правил Bean Validation для Micronaut 1.2. Размер нативного образа уменьшился на 10 MB, как только мы удалил зависимость от Hibernate Validator, а размер JAR на 2 MB.
Преимущество здесь очевидно: выполняя больше работы во время компиляции и создавая более компактные среды выполнения, вы получаете меньший нативный образ и JAR файл, что приводит к меньшим и более простым в развёртывании микросервисам при развёртывании через Docker. Будущее Java фреймворков — это более мощные компиляторы и меньшие, лёгкие среды выполнения.
Predator и будущее
Мы только начинаем работать с Predator и безумно рады возможностям, которые он открывает.
Изначально, мы запускаемся с поддержкой JPA и SQL, но в будущем вы можете ожидать поддержки MongoDB, Neo4J, Reactive SQL и других баз данных. К счастью, выполнить эту работу намного проще, потому что большая часть Predator фактически основана на исходном коде GORM, и мы сможем повторно использовать логику GORM для Neo4J и GORM для MongoDB, чтобы выпустить эти реализации быстрее, чем вы ожидаете.
Predator — кульминация объединения различных строительных блоков в Micronaut Core, которые сделали возможным его реализацию, от API для AoT, которые также используются для генерации документации Swagger, до относительно новой поддержки Bean Introspection, которая позволяет анализировать объекты во время выполнения без рефлексии.
Micronaut предоставляет строительные блоки для удивительных вещей. Predator — одна из таких вещей, и мы только начинаем работать над некоторыми из многообещающих возможностей Micronaut 1.0.
UPDATE: После эпатажного анонса убийцу Spring Data переименовали в Micronaut Data: https://micronaut-projects.github.io/micronaut-data/1.0.x/guide/

