
Хабр Курсы для всех
РЕКЛАМА
Практикум, Хекслет, SkyPro, авторские курсы — собрали всех и попросили скидки. Осталось выбрать!
Константин, отличное применение! Добавлю 5 копеек:
doFuture. С ним этап сбора данных можно распараллелить не по ядрам, а по доп. процессам, а их можно запустить больше и получить результат еще быстрее, поскольку процессы будут просто ждать ответа от контролллеров. DoFuture почитаю. Спасибо. Единый лог файл, да. Согласен, что не помешал бы. Попробую добавить.
Еще пара трюков по ggplot:
facet_wrap по сути более подходит, поскольку набор данных одномерный по разбивке.scales = "free_y", тогда графики будут более читаемые, поскольку каждый тип ошибки получит свою нормировку.scale_x_datetime(labels = date_format("%H:%M", tz = "Europe/Moscow"),
breaks = date_breaks("1 hour"),
limits = base::range(df$time, na.rm = TRUE)) +При этом надо в facet указать scales = "free"
Спасибо за советы. Завтра попробую — покажу, что получилось на примере имеющихся данных.
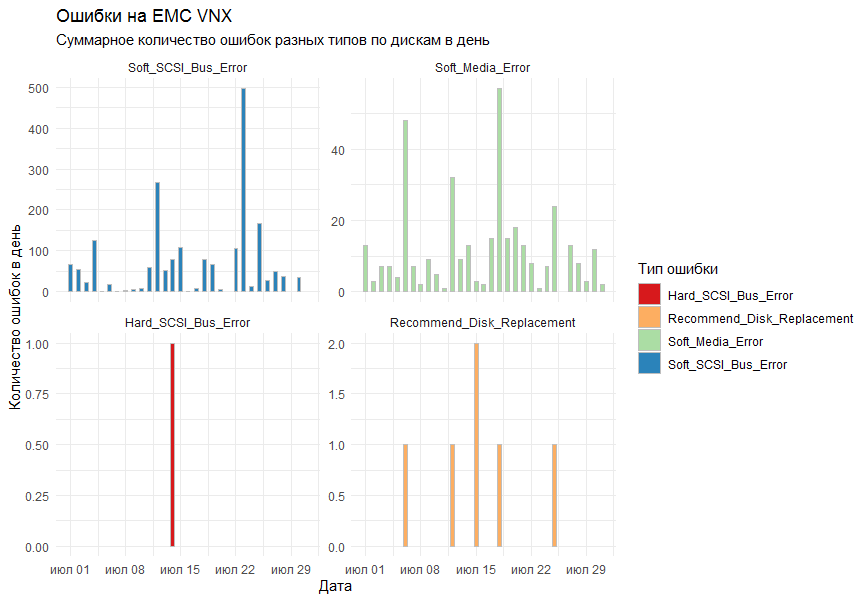
Применил рекомендации.
Итоговый результат.
Есть у нас ЦОД. Там не очень свежие СХД.
Мониторинг по SNMP этими СХД не поддерживается
Спасибо на добром слове.
Это EMC VNX 5300.
Ну и, на самом деле, если бы был мониторинг по SNMP — это бы не помогло, потому что интересующие нас сообщения не являются аварийными. Может, по ним snmp trap и не получилось бы генерить. А если бы получилось забирать весь лог через snmp poll, то всё равно всё свелось бы к тому, что результат надо чем-то парсить и т.д. По факту в тот же код можно пару строчек поменять и будет опрос через snmp :)
Именно R, по простой причине, что я его более-менее знаю и уже использовал в подобных задачах. Думаю, что на Python можно сделать всё плюс-минус то же самое. Вопрос того кому что удобнее.
А что по ML делали на R? Поделитесь.
А что по ML делали на R? Поделитесь.
Спасибо за внимательность :)
Согласен, что в этом плане сравнение скорости выполнение не очень честное.
Оно скорее, как рекламный слоган со звёздочкой.
Дело в том, что в изначальном коде с помощью getdisk ещё собираются серийные номера дисков, а на момент переписывания кода на R стало понятно, что эти данные не нужны.
Помечу в тексте данную оговорку, чтобы было честно.
Пишите в процессе. Буду рад помочь, если что.
Только учтите пожалуйста, что в коде учитывается вариант, что по какой-то СХД не будет ошибок, но не учитывается вариант, когда вообще нигде не будет ошибок (у нас такого не бывает, так что я поленился). Если у вас такое может быть, то это надо учесть. :)
Отчёты по состоянию СХД с помощью R. Параллельные вычисления, графики, xlsx, email и всё вот это