В мире криптографии есть много простых способов зашифровать сообщение. Каждый из них по-своему хорош. Об одном из них и пойдёт речь.
Ылчу Щзкгув
Или в переводе с «Шифра Цезаря» на русский — Шифр Цезаря.

— В чём его суть?
— Он кодирует сообщение, смещая каждую букву на N пунктов. Классический шифр Цезаря двигает буквы на три шага вперёд. Простыми словами — было «абв», стало «где».
— А как же буквы в конце алфавита? Что с пробелами?
С ними всё в порядке. Если смещая букву шифр выходит за рамки алфавита — он начинает отсчёт сначала. То есть, буквы «эюя» обратяться в «абв». А пробелы остаются пробелами.
— Разве N обязательно должно равняться трём?
Совсем нет. N может отличаться от тройки. Допускаются любые N в промежутке [1: M-1], где M — количество букв в алфавите.
Такой шифр легко расшифровать, если знать о его существовании. Но меня привлекла не его «надёжность», а кое-что другое.
Завязка
Одним летним днём мне захотелось узнать:
- А что если я зашифрую слово с помощью «Цезаря», а на выходе получу существующее слово?
- Сколько таких слов «перевёртышей» есть?
- И будет ли закономерность, если менять N?
Ответы на эти вопросы я начал искать в те же минуты.
Задача: Найти все слова
Отступление. Из концертов Михаила Задорнова и личного опыта я понял две вещи:
- Американцы не обижаются на речи русских комиков.
- Русский язык силён и могуч. И слов в нём немеряно много.
Поэтому я решил взять за основу английскую мову. К тому же, когда-то давно была инфа, что англоязычные ребята смогли собрать полный словарь английских слов. Что побудило меня найти такой Датасет.
Первая строка вялого гугления навела меня на этот репозиторий. Автор обещал 479K английских слов в удобных форматах. Мне приглянулся файл json, в котором все слова были уложены в удобном виде для загрузки в словарь Python.
После первого вскрытия оказалось, что слов там поменьше — 370 101 штука. «Но это не беда, ведь для показательного примера вполне хватит», подумал я.
words = json.load(open('words_dictionary.json', 'r')) len(words.keys()) >> 370101
Для начала нужно создать алфавит. Решил сделать его в виде списка самым удобным для меня методом. Также нужно было запомнить количество букв в алфавите:
abc = list('abcdefghijklmnopqrstuvwxyz') abc_len = len(abc)
Сначала было интересно сделать функцию перевода слова в зашифрованное. Вот что получилось:
# слово в цезарь-слово def cesar(word, abc, abc_len, step=3): word_list = list(word) result = [] for w in word_list: i = abc.index(w) i = (i+step) % abc_len wn = abc[i] result.append(wn) result = ''.join(result) return result
Решил сделать большой цикл по всем словам и начать их переводить одно за другим. Но наткнулся на проблему. Оказалось, что некоторые слова содержали знак «-», что было удивительно и естественно одновременно.
Недолго думая, я подсчитал количество таких слов и оказалось, что их — всего два. После чего удалил оба, ведь на результате это почти не скажется. На помощь мне родилась эта функция:
# удаляет символ «-» и возвращает исправленный словарь def rem(words): words_list = list(words.keys()) words = {} for word in words_list: if '-' in word: words_list.remove(word) else: words[word] = 1 return words
Словарь имел вид:
{'a': 1, 'aa': 1, 'aaa': 1, 'aah': 1, ... }
Поэтому я принял решение не мудрить и заменить единички на закодированные слова. Для этого написал функцию:
# конвертирует словарь {'word': 1} в {'word': 'cesar-word'} def cesar_all(words, abc, abc_len, step=3): result = words for w in result: result[w] = cesar(w, abc, abc_len, step=step) return result
И, конечно, нужен был большой цикл, который пройдёт по всем словам, найдёт слова-перевёртыши и сохранит результат. Вот он:
# проходит по словам и сохраняет результат def check_all(words_cesar, min_len=0): words_keys = words_cesar.keys() words_result = {} for word in words_keys: if words_cesar[word] in words_keys: if len(word) >= min_len: words_result[word] = words_cesar[word] return words_result
Вы могли заметить, что в параметрах функции стоит «min_len=0». Он будет нужен в будущем. Ибо особенностью этого Датасета был «странный» набор слов. Таких как: «аа», «aah» и подобные сочетания. Именно они дали первый результат — 660 слов-перевёртышей.
Поэтому пришлось поставить ограничение в пять минимум пять символов, чтобы слова были приятны глазу и похожи на существующие.
words_result = check_all(words_cesar, min_len=5) words_result >> {'abime': 'delph', 'biabo': 'elder', 'bifer': 'elihu', 'cobra': 'freud', 'colob': 'frore', 'oxime': 'ralph', 'pelta': 'showd', 'primero': 'sulphur', 'teloi': 'whorl', 'xerox': 'ahura'}
Да, десять слов-перевёртышей нашлись благодаря алгоритму. Моё любимое сочетание:
primero [Первый] → sulphur [Сера]. Большинство других пар Google-переводчик не распознаёт.
На этом этапе я частично погасил жажду познания. Но впереди остались вопросы типа: «А что же с другими N?»
И с помощью данной функции я нашёл ответ:
# цикл для всех N def loop_all(words, abc, abc_len, min_len=5): result = {} for istep in range(1, abc_len): words_rem = rem(words) words_cesar = cesar_all(words_rem, abc, abc_len, step=istep) words_result = check_all(words_cesar, min_len=min_len) result[istep] = words_result print('DONE: {}'.format(istep)) return result
Цикл закончил работу за 10–15 секунд. Осталось только посмотреть результаты. Но, как я считаю — всё интереснее, когда есть график. А вот финальная функция, которая покажет нам итог:
# цветовой график def img_plot(result): lengths = [] for k in result.keys(): l = len(result[k].keys()) lengths.append(l) lengths = np.reshape(lengths, (5,5)) display(lengths) plt.figure(figsize=(20,10)) plt.imshow(lengths, interpolation='sinc') plt.colorbar() plt.show() >> array([[ 12, 5, 10, 41, 4], [116, 23, 18, 20, 29], [ 18, 15, 56, 15, 18], [ 29, 20, 18, 23, 116], [ 4, 41, 10, 5, 12]])
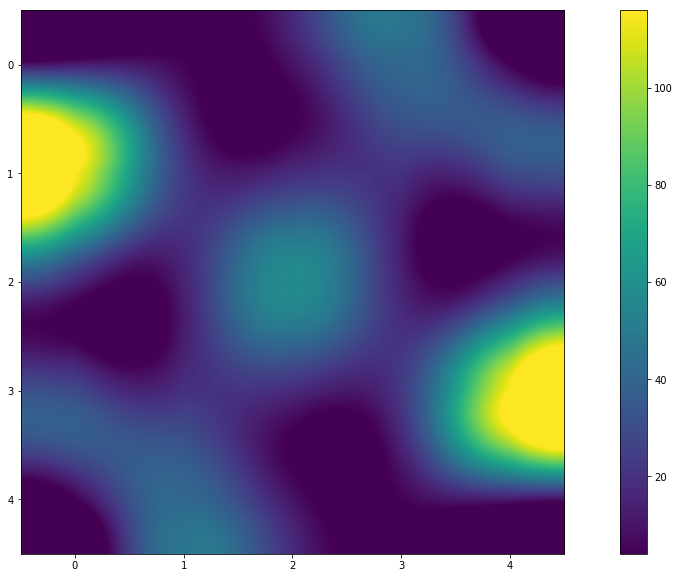
Итог
Ответы на вопросы в начале
— А что если я зашифрую слово с помощью «Цезаря», а на выходе получу существующее слово?
— Такое возможно, даже очень. Некоторые N дают намного бОльше слов, чем другие.
— Сколько таких слов «перевёртышей» есть?
— Зависит от N, минимальной длины и, конечно, от Датасета. В моём случае при N=3, минимальной длиной слова в 0 и в 5 — количество слов: 660 и 10 соответственно.
— И будет ли закономерность, если менять N?
— Как видно, да! Из графика (или тепловой карты) можно заметить, что цвета симметричны. И значения в матрице результатов говорят об этом. А ответ на вопрос «Почему так?» оставлю читателю.
Минусы этой работы
- Не совсем корректный Датасет. Многие слова неочевидны. Хотя, так может быть. Это же «все» слова английского языка.
- Код
всегдаможно улучшить. - «Шифр Цезаря» — частный случай «Афинного шифра», где формула:

Для «Шифра Цезаря» А = 1. Кстати, у него больше нюансов, а значит — больше интересного.
Мой рабочий файл с результатом и списком слов-перевёртышей лежит в этом репозитории

