
Хабр Курсы для всех
РЕКЛАМА
Практикум, Хекслет, SkyPro, авторские курсы — собрали всех и попросили скидки. Осталось выбрать!
Демо стенд быстроработает и на первый взгляд хорошо находит то что искали.
А опечатки вида перестановки букв местами не будет поддерживать?
Есть ли реализация которой уже можно воспользоваться?
Сколько занимают подготовленные матрицы?
Пример с опечаткой поиск по «вйона» вместо «война».Да, спасибо, хороший пример. Можно это решить. Плохой поиск по этой строке происходит вот почему. «вйона» и «война» дают 3 группы — «йна», «в» и «о». Сначала отбирается «йна», но она тут же отрбрасывается, так как группа, находящаяся внутри слова, подбирается в результат только в том случае, если у слова уже подобрана начальная часть. Если этого не делать, возникает некий мусор в результатах, но думаю результат из этого примера хуже, чем тот мусор. Это я сделал уже что называется «на закуску». Подумаю как лучше сделать.
C# не наша платформа, только если в виде сервиса с API на .NET Core в Docker, или консольной утилиты смогли бы к себе внедрить. На Python портировать смысла наверное нет, производительность упадёт.
Еще пример плохого поиска — "крове" (опечатка для поиска "кроме"). Не находит не одного релевантного совпадения в первой сотне. Если исправить опечатку (т.е. искать "кроме"), вся первая сотня содержит это слово.
Алгоритм с отсечением единичных букв для "крове" вообще находит только одну страницу и подсвечивает "кр" в "крикнул".
Кстати, вот не согласен, что в первую очередь важна скорость. В первую очередь важен результат. Лучше искать чуть медленнее, но более релевантно, особенно по "плохим" словам, чем совсем их отсекать.
Предложил бы посмотреть на fst

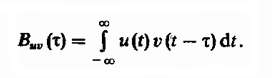
Алгоритм нечеткого поиска TextRadar. Основные подходы (ч. 1)