Хочу поделиться с вами моим первым успешным опытом восстановления полной работоспособности базы данных Postgres. С СУБД Postgres я познакомился пол года назад, до этого опыта администрирования баз данных у меня не было совсем.

Я работаю полу-DevOps инженером в крупной IT-компании. Наша компания занимается разработкой программного обеспечения для высоконагруженных сервисов, я же отвечаю за работоспособность, сопровождение и деплой. Передо мной поставили стандартную задачу: обновить приложение на одном сервере. Приложение написано на Django, во время обновления выполняются миграции (изменение структуры базы данных), и перед этим процессом мы снимаем полный дамп базы данных через стандартную программу pg_dump на всякий случай.
Во время снятия дампа возникла непредвиденная ошибка (версия Postgres – 9.5):
Ошибка «invalid page in block» говорит о проблемах на уровне файловой системы, что очень нехорошо. На различных форумах предлагали сделать FULL VACUUM с опцией zero_damaged_pages для решения данной проблемы. Что же, попрробеум…
ВНИМАНИЕ! Обязательно сделайте резервную копию Postgres перед любой попыткой восстановить базу данных. Если у вас виртуальная машина, остановите базу данных и сделайте снепшот. Если нет возможности сделать снепшот, остановите базу и скопируйте содержимое каталога Postgres (включая wal-файлы) в надёжное место. Главное в нашем деле – не сделать хуже. Прочтите это.
Поскольку в целом база у меня работала, я ограничился обычным дампом базы данных, но исключил таблицу с повреждёнными данными (опция -T, --exclude-table=TABLE в pg_dump).
Сервер был физическим, снять снепшот было невозможно. Бекап снят, двигаемся дальше.
Перед попыткой восстановления базы данных необходимо убедиться, что у нас всё в порядке с самой файловой системой. И в случае ошибок исправить их, поскольку в противном случае можно сделать только хуже.
В моём случае файловая система с базой данных была примонтирована в «/srv» и тип был ext4.
Останавливаем базу данных: systemctl stop postgresql@9.5-main.service и проверяем, что файловая система никем не используется и её можно отмонтировать с помощью команды lsof:
lsof +D /srv
Мне пришлось ещё остановить базу данных redis, так как она тоже исползовала "/srv". Далее я отмонтировал /srv (umount).
Проверка файловой системы была выполнена с помощью утилиты e2fsck с ключиком -f (Force checking even if filesystem is marked clean):
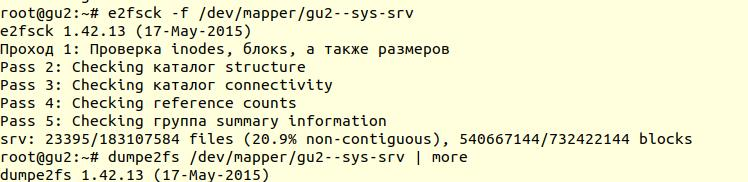
Далее с помощью утилиты dumpe2fs (sudo dumpe2fs /dev/mapper/gu2--sys-srv | grep checked) можно убедиться, что проверка действительно была произведена:

e2fsck говорит, что проблем на уровне файловой системы ext4 не найдено, а это значит, что можно продолжать попытки восстановить базу данных, а точнее вернуться к vacuum full (само собой, необходимо примонтирвоать файловую систему обратно и запустить базу данных).
Если у вас сервер физический, то обязательно проверьте состояние дисков (через smartctl -a /dev/XXX) либо RAID-контроллера, чтобы убедиться, что проблема не на аппаратном уровне. В моём случае RAID оказался «железный», поэтому я попросил местного админа проверить состояние RAID (сервер был в нескольких сотнях километров от меня). Он сказал, что ошибок нет, а это значит, что мы точно можем начать восстановление.
Подключаемся к базе через psql аккаунтом, обладающим правами суперпользователя. Нам нужен именно суперпользователь, т.к. опцию zero_damaged_pages может менять только он. В моём случае это postgres:
psql -h 127.0.0.1 -U postgres -s [database_name]
Опция zero_damaged_pages нужна для того, чтобы проигнорировать ошибки чтения (с сайта postgrespro):

К сожалению, неудача.
Мы столкнулись с аналогичной ошибкой:
pg_toast – механизм хранения «длинных данных» в Postgres, если они не помещаются в одну страницу (по умолчанию 8кб).
Первый совет из гугла не помог. После нескольких минут поиска я нашёл второй совет – сделать reindex повреждённой таблицы. Этот совет я встречал во многих местах, но он не внушал доверия. Сделаем reindex:

reindex завершился без проблем.
Однако это не помогло, VACUUM FULL аварийно завершался с аналогичной ошибкой. Поскольку я привык к неудачам, я стал искать советов в интернете дальше и наткнулся на довольно интересную статью.
В статье выше предлагали посмотреть таблицу построчно и удалить проблемные данные. Для начала необходимо было просмотреть все строки:
В моём случае таблица содержала 1 628 991 строк! По-хорошему необходимо было позаботиться о партициирвоании данных, но это тема для отдельного обсуждения. Была суббота, я запустил вот эту команду в tmux и пошёл спать:
К утру я решил проверить, как обстоят дела. К моему удивлению, я обнаружил, что за 20 часов было просканировано только 2% данных! Ждать 50 дней я не хотел. Очередной полный провал.
Но я не стал сдаваться. Мне стало интересно, почему же сканирование шло так долго. Из документации (опять на postgrespro) я узнал:
Далее мне в голову пришла, казалось бы, гениальная идея: снять дамп в текстовом виде и проанализировать последнюю записанную строку.
Но для начала, ознакомимся со структурой таблицы ws_log_smevlog:

В нашем случае у нас есть столбец «id», который содержал уникальный идентификатор (счётчик) строки. План был такой:
Я начал снимать дамп в текстовом виде:
Снятия дампа, как и ожидалось, прервался с той же самой ошибкой:
Далее через tail я просмотрел конец дампа (tail -5 ./my_dump.dump) обнаружил, что дамп прервался на строке с id 186 525. «Значит, проблема в строке с id 186 526, она битая, её и надо удалить!» – подумал я. Но, сделав запрос в базу данных:
«select * from ws_log_smevlog where id=186529» обнаружилось, что с этой строкой всё нормально… Строки с индексами 186 530 — 186 540 тоже работали без проблем. Очередная «гениальная идея» провалилась. Позже я понял, почему так произошло: при удалении\изменении данных из таблицы они не удаляются физически, а помечаются как «мёртвые кортежи», далее приходит autovacuum и помечает эти строки удалёнными и разрешает использовать эти строки повторно. Для понимания, если данные в таблице меняются и включён autovacuum, то они не хранятся последовательно.
Неудачи делают нас сильнее. Не стоит никогда сдаваться, нужно идти до конца и верить в себя и свои возможности. Поэтому я решил попробовать ешё один вариант: просто просмотреть все записи в базе данных по одному. Зная структуру моей таблицы (см. выше), у нас есть поле id, которое является уникальным (первичным ключом). В таблице у нас 1 628 991 строк и id идут по порядку, а это значит, что мы можем просто перербрать их по одному:
Если кто не понимает, команда работает следующим образом: просматривает построчно таблицу и отправляет stdout в /dev/null, но если команда SELECT проваливается, то выводится текст ошибки (stderr отправляется в консоль) и выводится строка, содержащая ошибку (благодаря ||, которая означает, что у select возникли проблемы (код возврата команды не 0)).
Мне повезло, у меня были созданы индексы по полю id:

А это значит, что нахождение строки с нужным id не должен занимать много времени. В теории должно сработать. Что же, запускаем команду в tmux и идём спать.
К утру я обнаружил, что просмотрено около 90 000 записей, что составляет чуть более 5%. Отличный результат, если сравнивать с предыдущим способом (2%)! Но ждать 20 дней не хотелось…
У заказчика под БД был выделен отличный сервер: двухпроцессорный Intel Xeon E5-2697 v2, в нашем расположении было целых 48 потоков! Нагрузка на сервере была средняя, мы без особых проблем могли забрать около 20-ти потоков. Оперативной памяти тоже было достаточно: аж 384 гигабайт!
Поэтому команду нужно было распараллелить:
Тут можно было написать красивый и элегантный скрипт, но я выбрал наиболее быстрый способ распараллеливания: разбить диапазон 0-1628991 вручную на интервалы по 100 000 записей и запустить отдельно 16 команд вида:
Но это не всё. По идее, подключение к базе данных тоже отнимает какое-то время и системные ресурсы. Подключать 1 628 991 было не очень разумно, согласитесь. Поэтому давайте при одном подключении извлекать 1000 строк вместо одной. В итоге команда преобразилоась в это:
Открываем 16 окон в сессии tmux и запускаем команды:
Это значит, что у нас три строки содержат ошибку. id первой и второй проблемной записи находились между 829 000 и 830 000, id третьей – между 146 000 и 147 000. Далее нам предстояло просто найти точное значение id проблемных записей. Для этого просматриваем наш диапазон с проблемными записями с шагом 1 и идентифицируем id:
Мы нашли проблемные строки. Заходим в базу через psql и пробуем их удалить:
К моему удивлению, записи удалились без каких-либо проблем даже без опции zero_damaged_pages.
Затем я подключился к базе, сделал VACUUM FULL (думаю делать было необязательно), и, наконец, успешно снял бекап с помощью pg_dump. Дамп снялся без каких либо ошибок! Проблему удалось решить таким вот тупейшим способом. Радости не было предела, после стольких неудач удалось найти решение!
Вот такой получился мой первый опыт восстановления реальной базы данных Postgres. Этот опыт я запомню надолго.
Ну и напоследок, хотел бы сказать спасибо компании PostgresPro за переведённую документацию на русский язык и за полностью бесплатные online-курсы, которые очень сильно помогли во время анализа проблемы.
Я работаю полу-DevOps инженером в крупной IT-компании. Наша компания занимается разработкой программного обеспечения для высоконагруженных сервисов, я же отвечаю за работоспособность, сопровождение и деплой. Передо мной поставили стандартную задачу: обновить приложение на одном сервере. Приложение написано на Django, во время обновления выполняются миграции (изменение структуры базы данных), и перед этим процессом мы снимаем полный дамп базы данных через стандартную программу pg_dump на всякий случай.
Во время снятия дампа возникла непредвиденная ошибка (версия Postgres – 9.5):
pg_dump: Oumping the contents of table “ws_log_smevlog” failed: PQgetResult() failed. pg_dump: Error message from server: ERROR: invalid page in block 4123007 of relatton base/16490/21396989 pg_dump: The command was: COPY public.ws_log_smevlog [...] pg_dunp: [parallel archtver] a worker process dled unexpectedly
Ошибка «invalid page in block» говорит о проблемах на уровне файловой системы, что очень нехорошо. На различных форумах предлагали сделать FULL VACUUM с опцией zero_damaged_pages для решения данной проблемы. Что же, попрробеум…
Подготовка к восстановлению
ВНИМАНИЕ! Обязательно сделайте резервную копию Postgres перед любой попыткой восстановить базу данных. Если у вас виртуальная машина, остановите базу данных и сделайте снепшот. Если нет возможности сделать снепшот, остановите базу и скопируйте содержимое каталога Postgres (включая wal-файлы) в надёжное место. Главное в нашем деле – не сделать хуже. Прочтите это.
Поскольку в целом база у меня работала, я ограничился обычным дампом базы данных, но исключил таблицу с повреждёнными данными (опция -T, --exclude-table=TABLE в pg_dump).
Сервер был физическим, снять снепшот было невозможно. Бекап снят, двигаемся дальше.
Проверка файловой системы
Перед попыткой восстановления базы данных необходимо убедиться, что у нас всё в порядке с самой файловой системой. И в случае ошибок исправить их, поскольку в противном случае можно сделать только хуже.
В моём случае файловая система с базой данных была примонтирована в «/srv» и тип был ext4.
Останавливаем базу данных: systemctl stop postgresql@9.5-main.service и проверяем, что файловая система никем не используется и её можно отмонтировать с помощью команды lsof:
lsof +D /srv
Мне пришлось ещё остановить базу данных redis, так как она тоже исползовала "/srv". Далее я отмонтировал /srv (umount).
Проверка файловой системы была выполнена с помощью утилиты e2fsck с ключиком -f (Force checking even if filesystem is marked clean):
Далее с помощью утилиты dumpe2fs (sudo dumpe2fs /dev/mapper/gu2--sys-srv | grep checked) можно убедиться, что проверка действительно была произведена:
e2fsck говорит, что проблем на уровне файловой системы ext4 не найдено, а это значит, что можно продолжать попытки восстановить базу данных, а точнее вернуться к vacuum full (само собой, необходимо примонтирвоать файловую систему обратно и запустить базу данных).
Если у вас сервер физический, то обязательно проверьте состояние дисков (через smartctl -a /dev/XXX) либо RAID-контроллера, чтобы убедиться, что проблема не на аппаратном уровне. В моём случае RAID оказался «железный», поэтому я попросил местного админа проверить состояние RAID (сервер был в нескольких сотнях километров от меня). Он сказал, что ошибок нет, а это значит, что мы точно можем начать восстановление.
Попытка 1: zero_damaged_pages
Подключаемся к базе через psql аккаунтом, обладающим правами суперпользователя. Нам нужен именно суперпользователь, т.к. опцию zero_damaged_pages может менять только он. В моём случае это postgres:
psql -h 127.0.0.1 -U postgres -s [database_name]
Опция zero_damaged_pages нужна для того, чтобы проигнорировать ошибки чтения (с сайта postgrespro):
При выявлении повреждённого заголовка страницы Postgres Pro обычно сообщает об ошибке и прерывает текущую транзакцию. Если параметр zero_damaged_pages включён, вместо этого система выдаёт предупреждение, обнуляет повреждённую страницу в памяти и продолжает обработку. Это поведение разрушает данные, а именно все строки в повреждённой странице.Включаем опцию и пробуем делать full vacuum таблицы:
VACUUM FULL VERBOSE
К сожалению, неудача.
Мы столкнулись с аналогичной ошибкой:
INFO: vacuuming "“public.ws_log_smevlog” WARNING: invalid page in block 4123007 of relation base/16400/21396989; zeroing out page ERROR: unexpected chunk number 573 (expected 565) for toast value 21648541 in pg_toast_106070
pg_toast – механизм хранения «длинных данных» в Postgres, если они не помещаются в одну страницу (по умолчанию 8кб).
Попытка 2: reindex
Первый совет из гугла не помог. После нескольких минут поиска я нашёл второй совет – сделать reindex повреждённой таблицы. Этот совет я встречал во многих местах, но он не внушал доверия. Сделаем reindex:
reindex table ws_log_smevlog
reindex завершился без проблем.
Однако это не помогло, VACUUM FULL аварийно завершался с аналогичной ошибкой. Поскольку я привык к неудачам, я стал искать советов в интернете дальше и наткнулся на довольно интересную статью.
Попытка 3: SELECT, LIMIT, OFFSET
В статье выше предлагали посмотреть таблицу построчно и удалить проблемные данные. Для начала необходимо было просмотреть все строки:
for ((i=0; i<"Number_of_rows_in_nodes"; i++ )); do psql -U "Username" "Database Name" -c "SELECT * FROM nodes LIMIT 1 offset $i" >/dev/null || echo $i; done
В моём случае таблица содержала 1 628 991 строк! По-хорошему необходимо было позаботиться о партициирвоании данных, но это тема для отдельного обсуждения. Была суббота, я запустил вот эту команду в tmux и пошёл спать:
for ((i=0; i<1628991; i++ )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog LIMIT 1 offset $i" >/dev/null || echo $i; done
К утру я решил проверить, как обстоят дела. К моему удивлению, я обнаружил, что за 20 часов было просканировано только 2% данных! Ждать 50 дней я не хотел. Очередной полный провал.
Но я не стал сдаваться. Мне стало интересно, почему же сканирование шло так долго. Из документации (опять на postgrespro) я узнал:
OFFSET указывает пропустить указанное число строк, прежде чем начать выдавать строки.Очевидно, что вышенаписанная команда была ошибочной: во-первых, не было order by, результат мог получиться ошибочным. Во-вторых, Postgres сначала должен был просканировать и пропустить OFFSET-строк, и с возрастанием OFFSET производительность снижалась бы ещё сильнее.
Если указано и OFFSET, и LIMIT, сначала система пропускает OFFSET строк, а затем начинает подсчитывать строки для ограничения LIMIT.
Применяя LIMIT, важно использовать также предложение ORDER BY, чтобы строки результата выдавались в определённом порядке. Иначе будут возвращаться непредсказуемые подмножества строк.
Попытка 4: снять дамп в текстовом виде
Далее мне в голову пришла, казалось бы, гениальная идея: снять дамп в текстовом виде и проанализировать последнюю записанную строку.
Но для начала, ознакомимся со структурой таблицы ws_log_smevlog:
В нашем случае у нас есть столбец «id», который содержал уникальный идентификатор (счётчик) строки. План был такой:
- Начинаем снимать дамп в текстовом виде (в виде sql-команд)
- В определённый момент времени снятия дампа бы прервалось из-за ошибки, но тектовый файл всё равно сохранился бы на диске
- Смотрим конец текстового файла, тем самым мы находим идентификатор (id) последней строки, которая снялась успешно
Я начал снимать дамп в текстовом виде:
pg_dump -U my_user -d my_database -F p -t ws_log_smevlog -f ./my_dump.dump
Снятия дампа, как и ожидалось, прервался с той же самой ошибкой:
pg_dump: Error message from server: ERROR: invalid page in block 4123007 of relatton base/16490/21396989
Далее через tail я просмотрел конец дампа (tail -5 ./my_dump.dump) обнаружил, что дамп прервался на строке с id 186 525. «Значит, проблема в строке с id 186 526, она битая, её и надо удалить!» – подумал я. Но, сделав запрос в базу данных:
«select * from ws_log_smevlog where id=186529» обнаружилось, что с этой строкой всё нормально… Строки с индексами 186 530 — 186 540 тоже работали без проблем. Очередная «гениальная идея» провалилась. Позже я понял, почему так произошло: при удалении\изменении данных из таблицы они не удаляются физически, а помечаются как «мёртвые кортежи», далее приходит autovacuum и помечает эти строки удалёнными и разрешает использовать эти строки повторно. Для понимания, если данные в таблице меняются и включён autovacuum, то они не хранятся последовательно.
Попытка 5: SELECT, FROM, WHERE id=
Неудачи делают нас сильнее. Не стоит никогда сдаваться, нужно идти до конца и верить в себя и свои возможности. Поэтому я решил попробовать ешё один вариант: просто просмотреть все записи в базе данных по одному. Зная структуру моей таблицы (см. выше), у нас есть поле id, которое является уникальным (первичным ключом). В таблице у нас 1 628 991 строк и id идут по порядку, а это значит, что мы можем просто перербрать их по одному:
for ((i=1; i<1628991; i=$((i+1)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id=$i" >/dev/null || echo $i; done
Если кто не понимает, команда работает следующим образом: просматривает построчно таблицу и отправляет stdout в /dev/null, но если команда SELECT проваливается, то выводится текст ошибки (stderr отправляется в консоль) и выводится строка, содержащая ошибку (благодаря ||, которая означает, что у select возникли проблемы (код возврата команды не 0)).
Мне повезло, у меня были созданы индексы по полю id:
А это значит, что нахождение строки с нужным id не должен занимать много времени. В теории должно сработать. Что же, запускаем команду в tmux и идём спать.
К утру я обнаружил, что просмотрено около 90 000 записей, что составляет чуть более 5%. Отличный результат, если сравнивать с предыдущим способом (2%)! Но ждать 20 дней не хотелось…
Попытка 6: SELECT, FROM, WHERE id >= and id <
У заказчика под БД был выделен отличный сервер: двухпроцессорный Intel Xeon E5-2697 v2, в нашем расположении было целых 48 потоков! Нагрузка на сервере была средняя, мы без особых проблем могли забрать около 20-ти потоков. Оперативной памяти тоже было достаточно: аж 384 гигабайт!
Поэтому команду нужно было распараллелить:
for ((i=1; i<1628991; i=$((i+1)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id=$i" >/dev/null || echo $i; done
Тут можно было написать красивый и элегантный скрипт, но я выбрал наиболее быстрый способ распараллеливания: разбить диапазон 0-1628991 вручную на интервалы по 100 000 записей и запустить отдельно 16 команд вида:
for ((i=N; i<M; i=$((i+1)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id=$i" >/dev/null || echo $i; done
Но это не всё. По идее, подключение к базе данных тоже отнимает какое-то время и системные ресурсы. Подключать 1 628 991 было не очень разумно, согласитесь. Поэтому давайте при одном подключении извлекать 1000 строк вместо одной. В итоге команда преобразилоась в это:
for ((i=N; i<M; i=$((i+1000)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id>=$i and id<$((i+1000))" >/dev/null || echo $i; done
Открываем 16 окон в сессии tmux и запускаем команды:
Через день я получил первые результаты! А именно (значения XXX и ZZZ уже не сохранились):1) for ((i=0; i<100000; i=$((i+1000)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id>=$i and id<$((i+1000))" >/dev/null || echo $i; done 2) for ((i=100000; i<200000; i=$((i+1000)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id>=$i and id<$((i+1000))" >/dev/null || echo $i; done … 15) for ((i=1400000; i<1500000; i=$((i+1000)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id>=$i and id<$((i+1000))" >/dev/null || echo $i; done 16) for ((i=1500000; i<1628991; i=$((i+1000)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id>=$i and id<$((i+1000))" >/dev/null || echo $i; done
ERROR: missing chunk number 0 for toast value 37837571 in pg_toast_106070 829000 ERROR: missing chunk number 0 for toast value XXX in pg_toast_106070 829000 ERROR: missing chunk number 0 for toast value ZZZ in pg_toast_106070 146000
Это значит, что у нас три строки содержат ошибку. id первой и второй проблемной записи находились между 829 000 и 830 000, id третьей – между 146 000 и 147 000. Далее нам предстояло просто найти точное значение id проблемных записей. Для этого просматриваем наш диапазон с проблемными записями с шагом 1 и идентифицируем id:
for ((i=829000; i<830000; i=$((i+1)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id=$i" >/dev/null || echo $i; done 829417 ERROR: unexpected chunk number 2 (expected 0) for toast value 37837843 in pg_toast_106070 829449 for ((i=146000; i<147000; i=$((i+1)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id=$i" >/dev/null || echo $i; done 829417 ERROR: unexpected chunk number ZZZ (expected 0) for toast value XXX in pg_toast_106070 146911
Счастливый финал
Мы нашли проблемные строки. Заходим в базу через psql и пробуем их удалить:
my_database=# delete from ws_log_smevlog where id=829417; DELETE 1 my_database=# delete from ws_log_smevlog where id=829449; DELETE 1 my_database=# delete from ws_log_smevlog where id=146911; DELETE 1
К моему удивлению, записи удалились без каких-либо проблем даже без опции zero_damaged_pages.
Затем я подключился к базе, сделал VACUUM FULL (думаю делать было необязательно), и, наконец, успешно снял бекап с помощью pg_dump. Дамп снялся без каких либо ошибок! Проблему удалось решить таким вот тупейшим способом. Радости не было предела, после стольких неудач удалось найти решение!
Благодарности и заключение
Вот такой получился мой первый опыт восстановления реальной базы данных Postgres. Этот опыт я запомню надолго.
Ну и напоследок, хотел бы сказать спасибо компании PostgresPro за переведённую документацию на русский язык и за полностью бесплатные online-курсы, которые очень сильно помогли во время анализа проблемы.