
Хабр Курсы для всех
РЕКЛАМА
Практикум, Хекслет, SkyPro, авторские курсы — собрали всех и попросили скидки. Осталось выбрать!
По правде говоря, когда я делал это все у меня не было цели сделать правильно. Была цель просто сделать. А как правильно я надеюсь получить у вас в комментариях
Алексей, а не сможете написать какие ещё ошибки допущены? Желательно с пояснениями почему именно так делать нельзя
Ну еще из того что режет глаза это монтирование путей на сервере внутрь контейнеров:
volumes:
- ./:/var/wwwЭто очень плохая практика которая может создать в дальнейшем множество проблем. Такое решение может быть приемлемым для локальной разработки (и то его необходимо использовать с осторожностью поскольку оно легко приводит ко множеству трудно воспроизводимых багов из-за разницы в окружениях), но его однозначно не стоит использовать на серверах. Тут как раз можно использовать разные наборы docker-compose файлов для локально разработки и для сервера
Если мы говорим о продакшен конфигурации для laravel и вообще PHP и подобных языках, то да, исходники, vendor и т. п. должны быть в образе докера, монтироваться только файлы с данными, типа загружаемых пользователем аватарок и/или расшариваемые между контейнерами данные типа public, расшариваемый с nginx.
В случае с Laravel есть спорный момент насчёт storage — нужно ли его монтировать, а если нужно то на постоянные тома или временные, переживающие перезапуск контейнера, но не переживающие перезапуск системы.
Хотелось бы все таки пояснений
А за это большое спасибо!
Не сможете дать какой нибудь пример с пояснением как структурировать dockerfile?
Перед сборкой образа нужно проконтролировать какие именно файлы попадают в build-context и настроить .dockerignore таким образом чтобы лишние файлы не были в него включены. К лишним относится папка .git, и прочие локальные файлы которые не нужно копировать в финальный образ
Пример 1 (Простой) — https://gist.github.com/Alexei-Kornienko/b048cc969798428740658393018e91c9
Данный Dockerfile использует multi-stage builds (https://docs.docker.com/develop/develop-images/multistage-build/)
Посколько одним Dockerfile описываются правила сборки сразу 2 образов:
Схема стейджей выглядит вот так — 
1) Выбираем базовый образ наиболее подходящий под наше приложение. В данном примере благодаря этому нет необходимости доставлять системные пакеты
2) Добавляем файл который описывает проектные зависимости нашего приложения и устанавливаем их (https://gist.github.com/Alexei-Kornienko/b048cc969798428740658393018e91c9#file-simple-dockerfile-L4). Если правильно построить процесс сборки образа то эти слои будут пересобираться очень редко и будут переиспользоваться по всех образах
3) Далее собирается отдельный стейдж с тестовыми зависимостями которые также меняются редко (test_base)
4) После этого в образ добавляется непосредственно код приложения — https://gist.github.com/Alexei-Kornienko/b048cc969798428740658393018e91c9#file-simple-dockerfile-L15. При нормальном процессе разработки как правило все слои выше этой строчки закешированы и пересобираются только нижележащие слои
5) Отдельно собирается тестовая версия образа — https://gist.github.com/Alexei-Kornienko/b048cc969798428740658393018e91c9#file-simple-dockerfile-L19
В результате у меня например получается вот такой образ:
app develop c7f7a0ff09d3 2 minutes ago 181MB
Очень полезно будет воспользоваться командой docker history для того чтобы посмотреть его слои:
c7f7a0ff09d3 2 minutes ago |1 version=v0.3.6 /bin/sh -c echo $version &… 84B
6cfd15cab214 2 minutes ago /bin/sh -c #(nop) ARG version=unknown 0B
2d1197adf7ef 2 minutes ago /bin/sh -c #(nop) COPY dir:753c8e55ed96ed762… 112kB
f6ae0c62044f 4 months ago /bin/sh -c pip install -r requirements.txt 37.2MB
57c774cffbf4 4 months ago /bin/sh -c #(nop) COPY file:6998a5aae7dd8b37… 133B
59fb244f987c 7 months ago /bin/sh -c #(nop) ENV PYTHONUNBUFFERED=True 0B
c00de12b7b5a 7 months ago /bin/sh -c #(nop) WORKDIR /app 0B
338ae06dfca5 9 months ago /bin/sh -c #(nop) CMD ["python3"] 0B
<missing> 9 months ago /bin/sh -c set -ex; savedAptMark="$(apt-ma… 7.26MB
<missing> 9 months ago /bin/sh -c #(nop) ENV PYTHON_PIP_VERSION=19… 0B
<missing> 9 months ago /bin/sh -c cd /usr/local/bin && ln -s idle3… 32B
<missing> 9 months ago /bin/sh -c set -ex && savedAptMark="$(apt-… 74.3MB
<missing> 9 months ago /bin/sh -c #(nop) ENV PYTHON_VERSION=3.7.3 0B
<missing> 9 months ago /bin/sh -c #(nop) ENV GPG_KEY=0D96DF4D4110E… 0B
<missing> 9 months ago /bin/sh -c apt-get update && apt-get install… 6.48MB
<missing> 9 months ago /bin/sh -c #(nop) ENV LANG=C.UTF-8 0B
<missing> 9 months ago /bin/sh -c #(nop) ENV PATH=/usr/local/bin:/… 0B
<missing> 9 months ago /bin/sh -c #(nop) CMD ["bash"] 0B
<missing> 9 months ago /bin/sh -c #(nop) ADD file:5ffb798d64089418e… 55.3MB Основная задача это сделать так чтобы наиболее толстые слои были расположены ниже в истории, а те слои которые часто пересобираются были вверху и имели минимально возможный размер.
В данном примере сборка образа с нуля занимает — real 0m54.348s.
Пересборка образа при изменении кода — real 0m18.450s (На старом HDD, на относительно новом SSD порядка 5 секунд)
Пример 2 (Сложный) — https://gist.github.com/Alexei-Kornienko/a50f22f1e30839596c985684e8c0fdae
Основная идея таже самая, данный Dockerfile намного сложнее изза того что пришлось заворачивать в контейнер legacy приложение изначально написанное без учета возможностей контейнеризации.
Также используется немного другая схема стейджей — 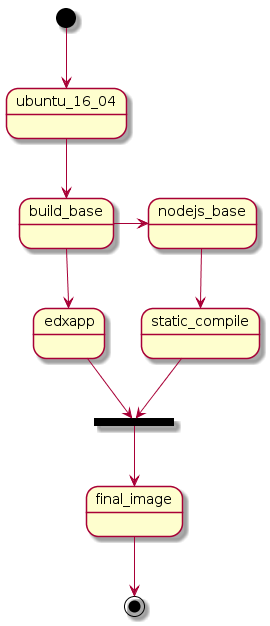 изза необходимости компилировать большое количество статических файлов и всяких js скриптов. В результате в финальный образ переносятся только скомпилированные артефакты без кучи js мусора.
изза необходимости компилировать большое количество статических файлов и всяких js скриптов. В результате в финальный образ переносятся только скомпилированные артефакты без кучи js мусора.
Отдельный раннер на отдельном сервере, извините за глупый вопрос? А как образ должен попадать на боевой сервер? С помощью ssh — экзекутора?
У меня обычно пайплайн собирает новый образ приложения с временным именем образа и запускает тесты для этого нового образа, в случае успешного прохождения всех тестов данный образ получает полное имя и заливается в docker-registry (открытый либо закрытый в зависимости от проекта). Следующий пайплайн дергает хук на сервере и сервер уже тянет хорошие образы из этого registry. Это позволяет хранить версии образов на registry и откатываться на нужную стабильную версию при необходимости.
Начал писать большой комментарий, понял что замечаний много чтобы из головы текстом описывать и могут быть ошибки. Начал поднимать локально с нуля пошагово. Пока вот так https://gitlab.com/volch/laravel-demo
Если есть вопросы по конфигам (собственно ничего и нет больше), то спрашивайте. Ну и не знаю имеет ли смысл продолжать дальше, по CI в частности.
Про какие, например, нюансы забывают?
Ну и docker-compose в принципе слабо подходит для автоматизации сложных флоу CI/CD с командами и прочим c минимальным даунтаймом, а лучше без него.
Laravel+Docker+Gitlab. С чего начать