
Мир кардинально меняется. Многие компании ищут любые способы для сокращения расходов, просто для того, чтобы выжить. При этом усиливается нагрузка на онлайн-сервисы — особенно те, которые связаны с организацией удалённой работы, проведением видео-конференций, онлайн-обучением.
В этих условиях крайне важно с одной стороны — обеспечить надежность и масштабирование вашей инфраструктуры. С другой — не вылететь в трубу с закупкой серверов, дисков, оплатой траффика.
Мы в «Битрикс24» очень активно используем Amazon Web Services, и в этой статье я расскажу о нескольких возможностях AWS, которые помогут вам сократить ваши расходы.
«Битрикс24» — глобальный сервис, мы работаем для клиентов по всему миру. С 2015 года, с момента вступления в силу закона 242-ФЗ о локализации персональных данных, данные российских пользователей хранятся на серверах в России. А вот вся инфраструктура сервиса, обслуживающего остальных клиентов по всему миру, развёрнута в Amazon Web Services.
Экономический кризис — уже свершившийся факт. Курс доллара вырос и вряд ли вернется на прежние позиции в ближайшее время, поэтому оплата хостинга в валюте становится достаточно обременительной.
В этих условиях, если вы продолжаете размещать ваши ресурсы в AWS, вам, скорее всего, будут интересны приёмы, которые помогут вам сэкономить на аренде инфраструктуры.
Я расскажу об основных из них, которые мы сами уже много лет используем. Если же есть какие-то еще способы, которые используете вы — пожалуйста, делитесь в комментариях.
Итак, поехали.
Самый простой и очевидный способ сэкономить в AWS — использовать зарезервированные инстансы EC2. Если вы знаете, что определенные инстансы вы совершенно точно будете использовать, как минимум, в течение года, вы можете внести за них предоплату и получить скидку от 30% до 75%.
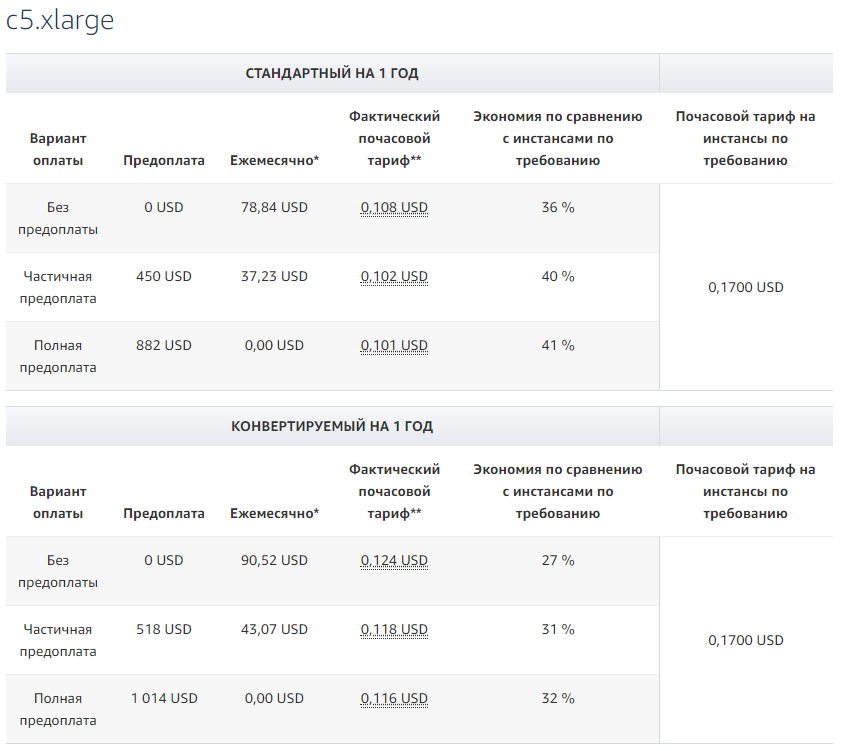
Пример расчетов для инстансов c5.xlarge:
Все цены и расчеты — здесь.
Иногда выглядит сложно и запутанно, но в целом логика такая:
Для себя мы делаем резервирования на 1 год, потому что на 3 года планировать довольно сложно. И это позволяет неплохо экономить на EC2.
Использование Spot Instances — это по сути некоторая биржа ресурсов. Когда у Amazon есть много простаивающих ресурсов, вы можете для специальных «спотов» (Spot Instances) задать максимальную цену, которую вы готовы за них платить.
Если текущий спрос в определенном регионе и AZ (Availability Zone) мал, то вам предоставят эти ресурсы. При чем по цене в 3-8 раз ниже, чем цена on-demand.
В чем подвох?
Исключительно в том, что если свободной емкости не будет, запрошенные ресурсы вам не дадут. И если спрос резко вырастет, и цена на споты превысит вашу заданную максимальную цену, ваш спот будет удален (terminate).
Естественно, такие инстансы не подойдут, например, для БД в продакшене. Но для каких-то задач, которые связаны, например, с теми или иными расчетами, рендерингом, обсчетом моделей, для тестов — отличный способ сэкономить.
Посмотрим на практике, за какие суммы бьемся. И часто ли споты могут «уходить» по цене.
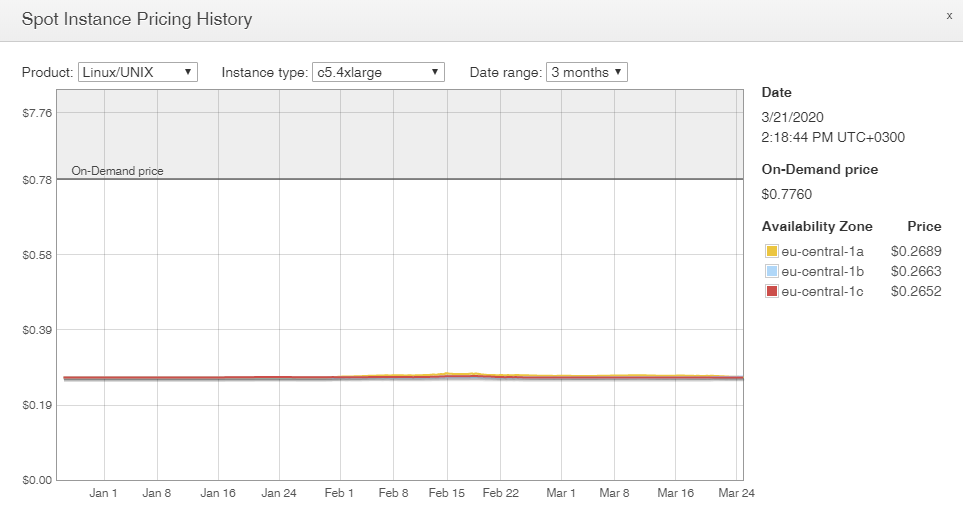
Вот для примера Spot Instance Pricing History прямо из консоли AWS для региона eu-central-1 (Франкфурт) для инстансов c5.4xlarge:
Что мы видим?
Как мы используем споты на практике:
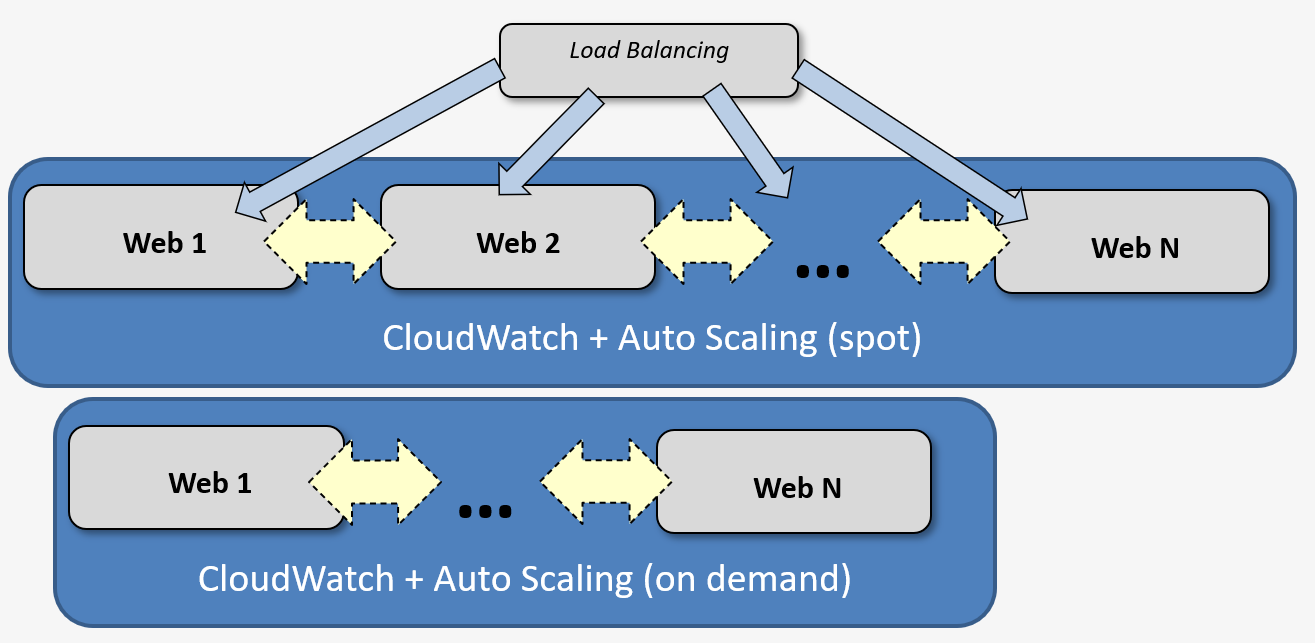
— Мы используем споты для серверов приложений.
— Для них мы активно используем связку CloudWatch + Auto Scaling — для автоматического масштабирования в течение дня: нагрузка возрастает — запускаются новые инстансы, нагрузка падает — они гасятся.
— Для подстраховки у нас за балансировщиками работают две Auto Scaling группы — на тот случай, если споты закончатся. Одна AS группа — с обычными (on demand) инстансами, вторая — со спотами. Amazon через CloudWatch Events предупреждает за 2 минуты о том, что spot instance будет удален (terminate). Мы обрабатываем эти события и успеваем расширить основную группу до нужного количества инстансов, если такое происходит.
Подробности вот здесь — Spot Instance Interruption Notices.
— Чтобы эффективнее работать с Auto Scaling и по максимуму использовать именно машины в группе со спотами, мы применяем такой подход:
Все, кто работает с AWS, знают, что основные диски, которые используются для EC2 инстансов — это EBS (Elastic Block Store). Их можно монтировать к инстансам, отключать, монтировать к другим инстансам, делать с них снэпшоты.
Все EBS в зависимости от их типа так или иначе тарифицируются. И стоят весьма ощутимых денег.
При этом для многих типов инстансов при их создании доступно подключение локальных дисков — EC2 Instance Store.
Главная особенность этих дисков — если вы останавливаете (stop) инстанс с таким диском, то потом после старта эти данные теряются.
Но при этом они условно бесплатны — есть плата только за сам инстанс.
Такие диски можно отлично использовать под любые временные данные, которые не требуют постоянного сохранения — свопы, кэш, любые другие временные данные. Производительность Instance Store дисков достаточно высока: кроме уж совсем старых типов инстансов сейчас под них используются либо SSD, либо NVMe SSD.
В итоге: подключаем меньше EBS дисков, меньше платим.
Выше речь шла, в основном, о EC2. Дальше опишем несколько приемов, которые позволят сэкономить при использовании S3 (Simple Storage Service).
Если вы активно работаете с S3, то, наверняка, знаете, что и S3, и большинство клиентов для работы с этим хранилищем поддерживают Multipart Upload — большой объект загружается «кусочками», которые затем «собираются» в единый объект.
Это отлично работает, но есть одна засада.
Если загрузка по каким-то причинам не завершена (связь оборвалась, например, и загрузку не возобновляли), то уже загруженные части не удаляются сами. При этом они занимают место, вы за них платите.
И неприятный сюрприз — эти неполные данные никак не видны при работе со стандартными инструментами для S3: ни через «ls» в cli, ни в программах-клиентах. Найти их можно, например, в aws cli с помощью команды list-multipart-uploads.
Но так с ними работать слишком утомительно…
Самым логичным было бы вынести какую-то опцию про хранение Incomplete Multipart Uploads в настройки конкретного бакета. Но почему-то Амазон так не сделал.
Тем не менее, способ облегчить себе жизнь и удалять автоматом Incomplete Multipart Uploads есть. В настройках бакета на вкладке Management есть раздел Lifecycle. Это удобный инструмент, который позволяет настраивать различные автоматические правила для работы с объектами: перемещать их в другие хранилища, удалять через какое-то время (expire) и — в том числе — управлять поведением Incomplete Multipart Uploads.

Подробная статья про это есть в блоге AWS — правда, с примерами из старого интерфейса, но там всё довольно понятно.
Важно то, что настроенный на удаление неполных данных Lifecycle сработает не только для новых объектов, но и для уже имеющихся.
За реальным объемом занятого в S3 места можно следить через CloudWatch. Когда мы настроили удаление Incomplete Multipart Uploads, с удивлением обнаружили, что освободили не один десяток терабайт…
В S3 есть несколько разных классов хранилищ:
Все они имеют разные условия использования и разные цены. Их можно и нужно комбинировать — в зависимости от ваших разных задач.
Но относительно недавно появился еще один очень любопытный тип хранилища — Intelligent Tiering.
Суть его работы в следующем: за небольшую дополнительную плату осуществляется мониторинг и анализ ваших данных в S3, отслеживаются обращения к ним, и, если обращений нет в течение 30 дней, объект автоматически перемещается в хранилище нечастого доступа, которое стоит значительно дешевле стандартного. Если через какое-то время к объекту опять обращаются — никакого снижения производительности при этом не происходит — он опять перемещается в хранилище стандартного доступа.
Самое главное удобство: вам самим не надо ничего делать.
Amazon все сделает «по-умному» сам — разберется, какие объекты куда сложить.
Мы, включив Intelligent Tiering, на некоторых бакетах получили экономию до 10-15%.
Всё звучит слишком хорошо и волшебно. Но не может же не быть каких-то подводных камней? Они есть, и их, конечно, надо учитывать.
Как включить Intelligent Tiering?
Можно в явном виде указать класс хранения INTELLIGENT_TIERING в S3 API или CLI.
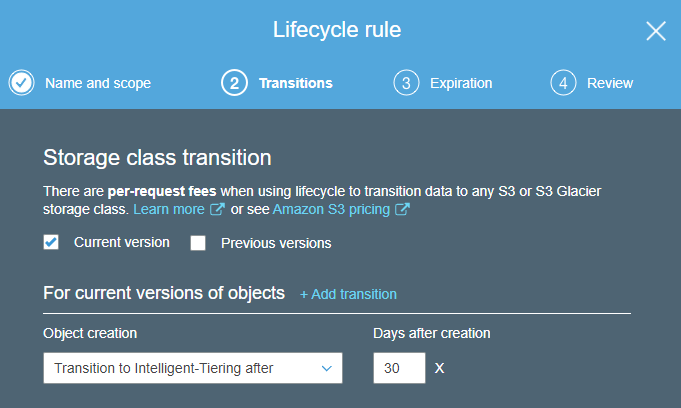
А можно настроить правило Lifecycle, по которому, например, все объекты после определенного времени хранения будут автоматически перемещаться в Intelligent Tiering.
Подробнее — в том же блоге AWS.
Если уж мы заговорили о разных классах хранилищ в S3, то, конечно же, стоит упомянуть и Glacier.
Если у вас есть данные, которые надо хранить месяцы и годы, но доступ к которым нужен крайне редко — например, логи, бэкапы — то обязательно рассмотрите возможность использования Glacier. Цена его использования — в разы меньше, чем стандартный S3.
Для удобной работы с Glacier можно использовать все те же правила Lifecycle.
Например, можно задать правило, по которому объект будет какое-то время храниться в обычном хранилище, например, 30-60 дней (обычно доступ нужен к наиболее близким по времени логам или бэкапам, если мы говорим об их хранении), затем будет перемещаться в Glacier, а по истечение 1-2-3… лет — полностью удаляться.
Это будет в разы дешевле, чем хранение просто в S3.
* * *
Я рассказал о некоторых приемах, которые мы сами активно используем. AWS — огромная инфраструктурная платформа. Наверняка, мы не рассказали о каких-то сервисах, которые используете именно вы. Если есть какие-то еще способы экономии в AWS, которые пригодились именно вам — пожалуйста, делитесь в комментариях.
В этих условиях крайне важно с одной стороны — обеспечить надежность и масштабирование вашей инфраструктуры. С другой — не вылететь в трубу с закупкой серверов, дисков, оплатой траффика.
Мы в «Битрикс24» очень активно используем Amazon Web Services, и в этой статье я расскажу о нескольких возможностях AWS, которые помогут вам сократить ваши расходы.
«Битрикс24» — глобальный сервис, мы работаем для клиентов по всему миру. С 2015 года, с момента вступления в силу закона 242-ФЗ о локализации персональных данных, данные российских пользователей хранятся на серверах в России. А вот вся инфраструктура сервиса, обслуживающего остальных клиентов по всему миру, развёрнута в Amazon Web Services.
Экономический кризис — уже свершившийся факт. Курс доллара вырос и вряд ли вернется на прежние позиции в ближайшее время, поэтому оплата хостинга в валюте становится достаточно обременительной.
В этих условиях, если вы продолжаете размещать ваши ресурсы в AWS, вам, скорее всего, будут интересны приёмы, которые помогут вам сэкономить на аренде инфраструктуры.
Я расскажу об основных из них, которые мы сами уже много лет используем. Если же есть какие-то еще способы, которые используете вы — пожалуйста, делитесь в комментариях.
Итак, поехали.
RI — Reserved Instances
Самый простой и очевидный способ сэкономить в AWS — использовать зарезервированные инстансы EC2. Если вы знаете, что определенные инстансы вы совершенно точно будете использовать, как минимум, в течение года, вы можете внести за них предоплату и получить скидку от 30% до 75%.
Пример расчетов для инстансов c5.xlarge:
Все цены и расчеты — здесь.
Иногда выглядит сложно и запутанно, но в целом логика такая:
- Чем больше срок резервирования — 1 или 3 года — тем больше скидка.
- Чем больше предоплата сразу — можно вообще без предоплаты, можно использовать all upfront, полную предоплату — тем больше скидка.
- Если резервируем конкретный тип инстанса, а не используем конвертируемый — больше скидка.
Для себя мы делаем резервирования на 1 год, потому что на 3 года планировать довольно сложно. И это позволяет неплохо экономить на EC2.
Spot Instances
Использование Spot Instances — это по сути некоторая биржа ресурсов. Когда у Amazon есть много простаивающих ресурсов, вы можете для специальных «спотов» (Spot Instances) задать максимальную цену, которую вы готовы за них платить.
Если текущий спрос в определенном регионе и AZ (Availability Zone) мал, то вам предоставят эти ресурсы. При чем по цене в 3-8 раз ниже, чем цена on-demand.
В чем подвох?
Исключительно в том, что если свободной емкости не будет, запрошенные ресурсы вам не дадут. И если спрос резко вырастет, и цена на споты превысит вашу заданную максимальную цену, ваш спот будет удален (terminate).
Естественно, такие инстансы не подойдут, например, для БД в продакшене. Но для каких-то задач, которые связаны, например, с теми или иными расчетами, рендерингом, обсчетом моделей, для тестов — отличный способ сэкономить.
Посмотрим на практике, за какие суммы бьемся. И часто ли споты могут «уходить» по цене.
Вот для примера Spot Instance Pricing History прямо из консоли AWS для региона eu-central-1 (Франкфурт) для инстансов c5.4xlarge:
Что мы видим?
- Цена примерно в 3 раза ниже, чем on-demand.
- Есть доступные spot instances во всех трех AZ в этом регионе.
- За три месяца цена ни разу не вырастала. Это значит, что запущенный три месяца назад спот с заданной максимальной ценой, например, $0.3 до сих продолжал бы работать.
Как мы используем споты на практике:
— Мы используем споты для серверов приложений.
— Для них мы активно используем связку CloudWatch + Auto Scaling — для автоматического масштабирования в течение дня: нагрузка возрастает — запускаются новые инстансы, нагрузка падает — они гасятся.
— Для подстраховки у нас за балансировщиками работают две Auto Scaling группы — на тот случай, если споты закончатся. Одна AS группа — с обычными (on demand) инстансами, вторая — со спотами. Amazon через CloudWatch Events предупреждает за 2 минуты о том, что spot instance будет удален (terminate). Мы обрабатываем эти события и успеваем расширить основную группу до нужного количества инстансов, если такое происходит.
Подробности вот здесь — Spot Instance Interruption Notices.
— Чтобы эффективнее работать с Auto Scaling и по максимуму использовать именно машины в группе со спотами, мы применяем такой подход:
- У spot группы более низкий верхний трешхолд — начинаем раньше масштабироваться «вверх».
- И более низкий нижний трешхолд — начинаем позже масштабироваться «вниз».
- У обычной группы — наоборот.
EC2 Instance Store
Все, кто работает с AWS, знают, что основные диски, которые используются для EC2 инстансов — это EBS (Elastic Block Store). Их можно монтировать к инстансам, отключать, монтировать к другим инстансам, делать с них снэпшоты.
Все EBS в зависимости от их типа так или иначе тарифицируются. И стоят весьма ощутимых денег.
При этом для многих типов инстансов при их создании доступно подключение локальных дисков — EC2 Instance Store.
Главная особенность этих дисков — если вы останавливаете (stop) инстанс с таким диском, то потом после старта эти данные теряются.
Но при этом они условно бесплатны — есть плата только за сам инстанс.
Такие диски можно отлично использовать под любые временные данные, которые не требуют постоянного сохранения — свопы, кэш, любые другие временные данные. Производительность Instance Store дисков достаточно высока: кроме уж совсем старых типов инстансов сейчас под них используются либо SSD, либо NVMe SSD.
В итоге: подключаем меньше EBS дисков, меньше платим.
S3 Incomplete Multipart Uploads
Выше речь шла, в основном, о EC2. Дальше опишем несколько приемов, которые позволят сэкономить при использовании S3 (Simple Storage Service).
Если вы активно работаете с S3, то, наверняка, знаете, что и S3, и большинство клиентов для работы с этим хранилищем поддерживают Multipart Upload — большой объект загружается «кусочками», которые затем «собираются» в единый объект.
Это отлично работает, но есть одна засада.
Если загрузка по каким-то причинам не завершена (связь оборвалась, например, и загрузку не возобновляли), то уже загруженные части не удаляются сами. При этом они занимают место, вы за них платите.
И неприятный сюрприз — эти неполные данные никак не видны при работе со стандартными инструментами для S3: ни через «ls» в cli, ни в программах-клиентах. Найти их можно, например, в aws cli с помощью команды list-multipart-uploads.
Но так с ними работать слишком утомительно…
Самым логичным было бы вынести какую-то опцию про хранение Incomplete Multipart Uploads в настройки конкретного бакета. Но почему-то Амазон так не сделал.
Тем не менее, способ облегчить себе жизнь и удалять автоматом Incomplete Multipart Uploads есть. В настройках бакета на вкладке Management есть раздел Lifecycle. Это удобный инструмент, который позволяет настраивать различные автоматические правила для работы с объектами: перемещать их в другие хранилища, удалять через какое-то время (expire) и — в том числе — управлять поведением Incomplete Multipart Uploads.
Подробная статья про это есть в блоге AWS — правда, с примерами из старого интерфейса, но там всё довольно понятно.
Важно то, что настроенный на удаление неполных данных Lifecycle сработает не только для новых объектов, но и для уже имеющихся.
За реальным объемом занятого в S3 места можно следить через CloudWatch. Когда мы настроили удаление Incomplete Multipart Uploads, с удивлением обнаружили, что освободили не один десяток терабайт…
S3 Intelligent Tiering
В S3 есть несколько разных классов хранилищ:
- Стандартный.
- Standard-IA (infrequently accessed) — для объектов, к которым редко обращаются.
- One Zone-IA — для относительно некритичных данных. В этом классе объекты реплицируются в меньшее количество точек.
- Glacier — очень дешевое хранилище, но из него нельзя получить объект моментально. Нужно сделать специальный запрос и ожидать некоторое время.
Все они имеют разные условия использования и разные цены. Их можно и нужно комбинировать — в зависимости от ваших разных задач.
Но относительно недавно появился еще один очень любопытный тип хранилища — Intelligent Tiering.
Суть его работы в следующем: за небольшую дополнительную плату осуществляется мониторинг и анализ ваших данных в S3, отслеживаются обращения к ним, и, если обращений нет в течение 30 дней, объект автоматически перемещается в хранилище нечастого доступа, которое стоит значительно дешевле стандартного. Если через какое-то время к объекту опять обращаются — никакого снижения производительности при этом не происходит — он опять перемещается в хранилище стандартного доступа.
Самое главное удобство: вам самим не надо ничего делать.
Amazon все сделает «по-умному» сам — разберется, какие объекты куда сложить.
Мы, включив Intelligent Tiering, на некоторых бакетах получили экономию до 10-15%.
Всё звучит слишком хорошо и волшебно. Но не может же не быть каких-то подводных камней? Они есть, и их, конечно, надо учитывать.
- Есть дополнительная плата за мониторинг объектов. В нашем случае она полностью покрывается полученной экономией.
- Можно использовать Intelligent Tiering для любых объектов. Однако объекты менее 128 Кб никогда не будут переведены на уровень нечастого доступа и всегда будут оплачиваться по обычной цене.
- Не подходит для объектов, которые хранятся менее 30 дней. Такие объекты все равно будут оплачиваться, как минимум, за 30 дней.
Как включить Intelligent Tiering?
Можно в явном виде указать класс хранения INTELLIGENT_TIERING в S3 API или CLI.
А можно настроить правило Lifecycle, по которому, например, все объекты после определенного времени хранения будут автоматически перемещаться в Intelligent Tiering.
Подробнее — в том же блоге AWS.
Glacier
Если уж мы заговорили о разных классах хранилищ в S3, то, конечно же, стоит упомянуть и Glacier.
Если у вас есть данные, которые надо хранить месяцы и годы, но доступ к которым нужен крайне редко — например, логи, бэкапы — то обязательно рассмотрите возможность использования Glacier. Цена его использования — в разы меньше, чем стандартный S3.
Для удобной работы с Glacier можно использовать все те же правила Lifecycle.
Например, можно задать правило, по которому объект будет какое-то время храниться в обычном хранилище, например, 30-60 дней (обычно доступ нужен к наиболее близким по времени логам или бэкапам, если мы говорим об их хранении), затем будет перемещаться в Glacier, а по истечение 1-2-3… лет — полностью удаляться.
Это будет в разы дешевле, чем хранение просто в S3.
* * *
Я рассказал о некоторых приемах, которые мы сами активно используем. AWS — огромная инфраструктурная платформа. Наверняка, мы не рассказали о каких-то сервисах, которые используете именно вы. Если есть какие-то еще способы экономии в AWS, которые пригодились именно вам — пожалуйста, делитесь в комментариях.
