Предлагаю ознакомиться с расшифровкой доклада начала 2019 года Алексея Лесовского — «Поиск и устранение проблем в Postgres с помощью pgCenter»
Время от времени при эксплуатации Postgres'а возникают проблемы, и чем быстрее найдены и устранены источники проблемы, тем благодарнее пользователи. pgCenter это набор CLI утилит которые является мощным средством для выявления и устранения проблем в режиме "здесь и сейчас". В этом докладе я расскажу как эффективно использовать pgCenter для поиска и устранения проблем, в каких направлениях осуществлять поиск и как реагировать на те или иные проблемы, в частности, как:
- проверить, все ли в порядке с Postgres'ом;
- быстро найти плохих клиентов и устранить их;
- выявлять тяжелые запросы;
- и другие полезные приемы с pgCenter.

Всем привет, меня зовут Алексей Лесовский. Я работаю в компании Data Egret. Это консалтинговая компания. И я вам расскажу, как мы в нашей консалтинговой компании занимаемся поиском и устранением неисправностей в PostgreSQL.
Я расскажу о том, как с помощью консольной утилиты pgCenter можно хорошо, быстро и эффективно находить самые разные проблемы и переходить к их устранению.

Немного о себе. Я долгое время был системным администратором. Занимался Linux, виртуализацией, мониторингом. И в какой-то момент времени стал заниматься больше Postgres'ом. И работа с Postgres стала занимать большую часть времени. И так я стал PostgreSQL DBA. И сейчас уже работая в консалтинговой компании, я работаю с Postgres каждый день. И каждый день наши заказчики предоставляют нам самый разный материал для новых конференций.

Все общение с нашими заказчиками происходит в виде беседы в чатах. Это самые разные чаты: Slack, Telegram. Но наши заказчики часто обнаруживают какую-нибудь проблему у себя и пишут. Мы в свою очередь должны на это отреагировать.

На слайде всем широко известная диаграмма Брендана Грэгга, как находить различные проблемы, связанные с производительностью в Linix. Это довольно познавательная диаграмма. Она показывает, как устроен Linux и какие утилиты есть для нахождения проблем. По сути, можно обложиться всеми этими утилитами и смотреть, что происходит.

Но в любом случае мы увидим то, что у нас все замыкается на Postgres. Процессорное время потребляется Postgres. Дисковый ввод-вывод так же генерируется Postgres'ом. Всю память съел тоже Postgres. Мы будем видеть только один Postgres.
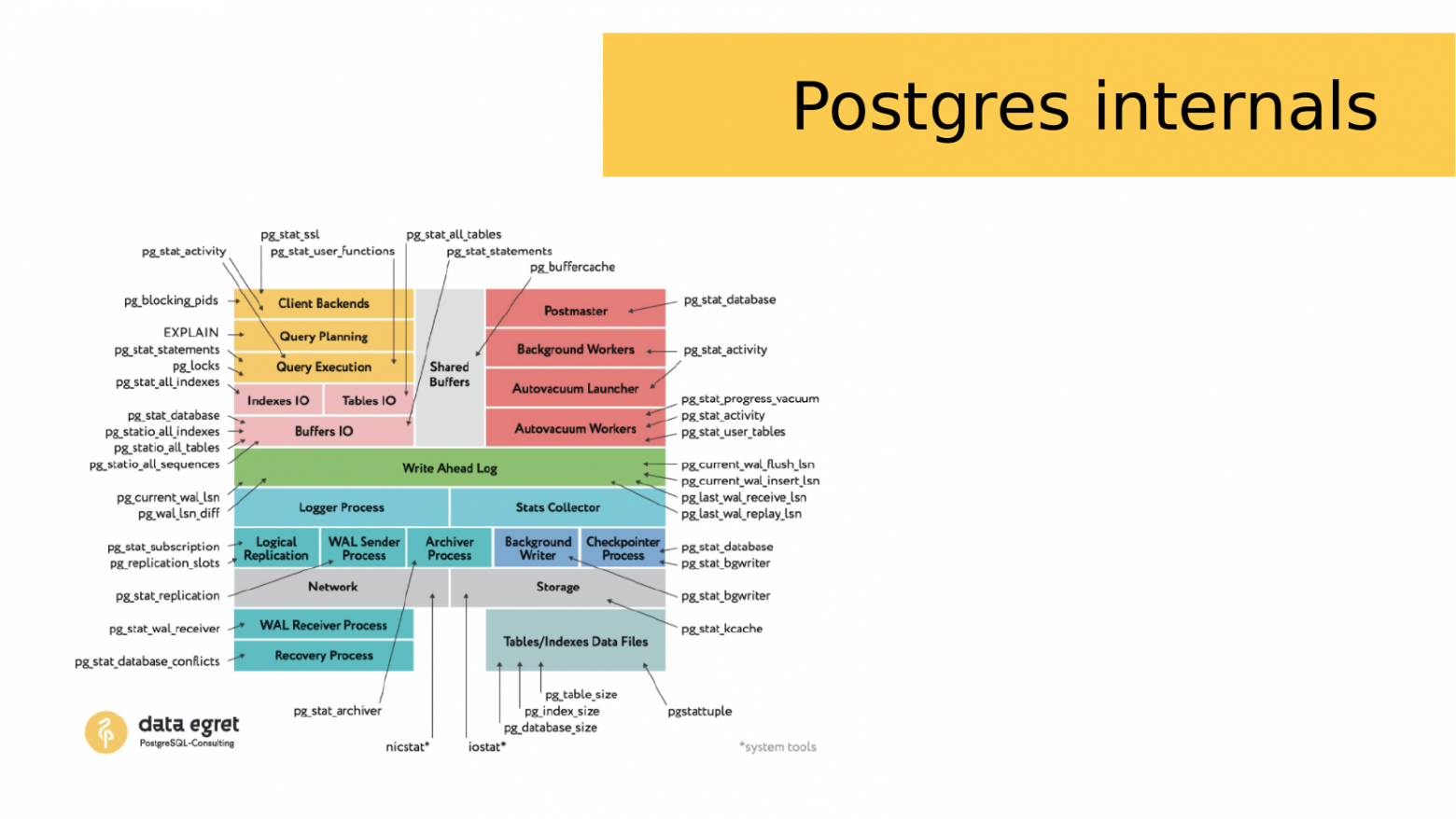
Для Postgres есть аналогичная картинка. Она также разбивает Postgres на несколько подсистем и показывает из чего состоит Postgres. Кроме того, в Postgres есть большое количество статистических представлений (views), с помощью которых можно анализировать работу этих подсистем.
И этих статистических представлений довольно много. Но во всех этих представлениях есть колонки. Эти колонки имеют собственные имена. И держать все это в голове бывает довольно-таки сложно.

И когда ты начинаешь искать какую-то проблему, нужно вспомнить имена нужных представлений, найти свои скрипты, которые ты, возможно, заранее приготовил. И это довольно-таки тяжело. И одновременно возникает масса вопросов: «Что тормозит?», «Где тормозит?» и «Что с этим делать?». На поиск всего этого нужно время, которого как обычно мало.

И разбираясь с проблемой одного из заказчиков, когда я тоже разбирал свои скрипты и пытался диагностировать проблему выполняя рутинные однообразные действия, мне пришла в голову идея, что нужна программа, которая будет это все дело облегчать. Более-менее хороших программ не нашлось и так пришла идея написать pgCenter.
Изначально она была написана на С. Это консольная утилита, которая показывала статистику в TOP-подобном виде.
Через какое-то время я понял, что C мне не очень подходит. т.к. я не профессиональный программист. И я переписал ее на Golang, этот язык показался мне более простым, но при этом напоминал С. И мне на нем легче добавлять новые функции.
Go это компилируемый язык и чтобы использовать pgCenter его нужно скомпилировать. Но в репозитории уже есть пакеты и вам как пользователю не нужно компилировать программу самостоятельно. К репозиторию подключена система сборки, которая после каждого коммита, компилирует бинарник, собирает targz, deb- и rpm-пакеты и выкладывает их в релизы. Т.е. не нужно устанавливать какие-то пакеты, ставить make, GCC или Golang. Достаточно просто зайти в релизы, скопировать нужный пакет по ссылке, распаковать руками или установить через дефолтный пакетный менеджер и можно уже пользоваться.

Изначально весь pgCenter представлял собой именно просмотрщик статистики, который в top-режиме показывает текущие изменения статистики за последнюю секунду (интервал изменений настраивается).

Однако потом я начал добавлять новые функции. И позже уже появились такие штуки, как сохранение статистики в файл и построение отчетов. И буквально совсем недавно я добавил сэмплер wait_events. Это штука позволяет смотреть, на каком месте запросы проводят время в ожидании чего-либо.

По ходу разработки я постарался сохранить синтаксис команды PSQL. Если вы работаете с Postgres, вы знаете что запустив PSQL без аргументов и параметров можно подключиться к Postgres. С pgCenter тоже самое, достаточно запустить «pgcenter top» из под postgres пользователя и она начнет показывать вам какую-то статистику (по-умолчанию, текущая активность в БД).

В более сложных случаях, если вы работаете от другого пользователя или нужно подключиться к какой-то другой базе, или к БД, которая находится на другом хосте, то можно указать те же самые ключи, которые вы используете в PSQL, которые определяют подключения к хосту, к конкретному порту, к конкретной базе и под конкретным именем пользователя.

Но можно даже не указывать хост, можно подключаться через UNIX-сокеты, т. к. go'шный драйвер, который используется под капотом pgCenter позволяет подключиться не только к сетевым сокетам, но и к UNIX.

Кроме того, тот же драйвер поддерживает переменные окружения libpq. Даже если у вас особенный случай, например, pg_stat_statements установлен в отдельной схеме и pgCenter не может его найти, то можно переопределить поведение через переменные окружения. Это тоже поддерживается.
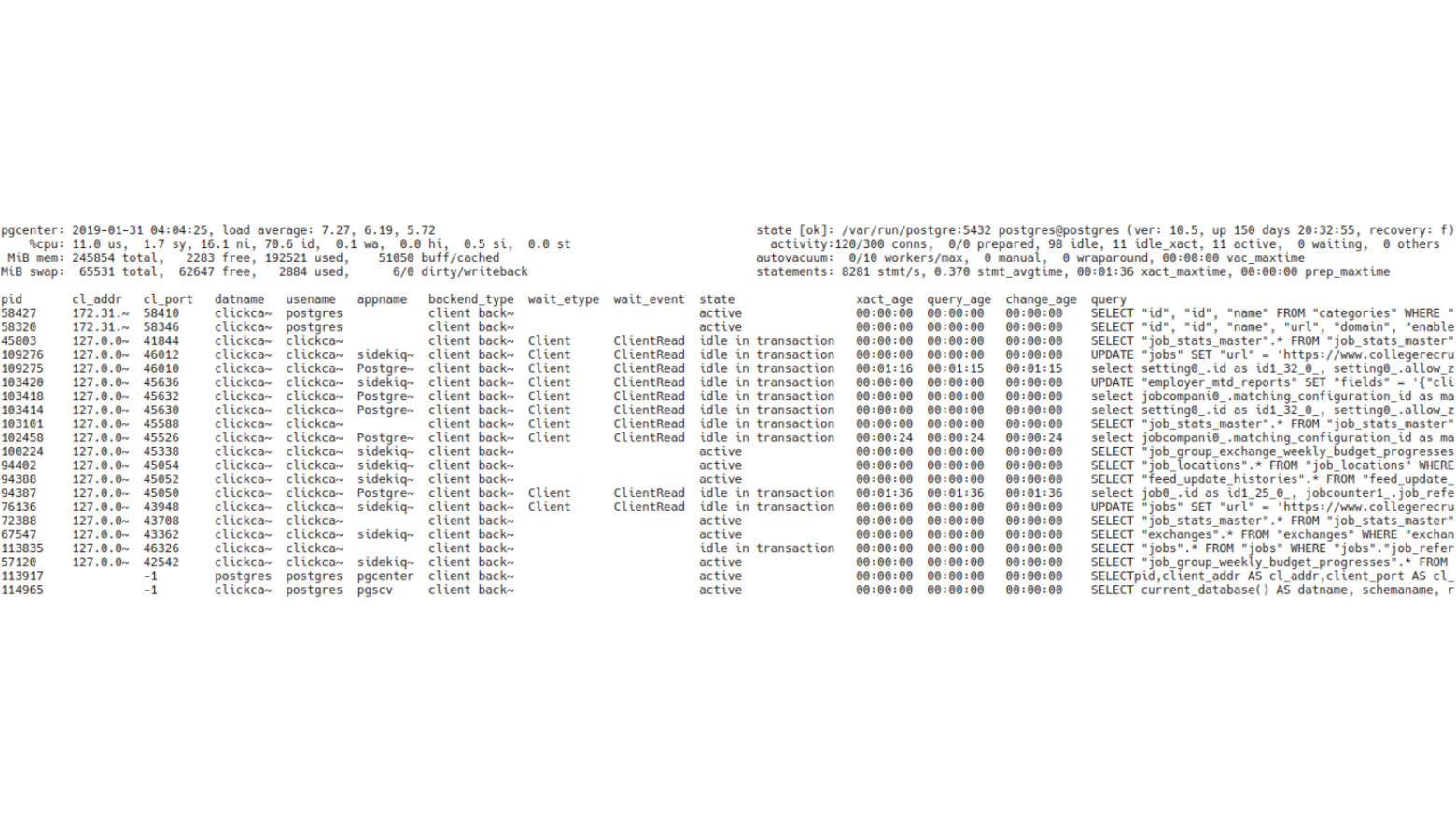
И вот так выглядит внешний вид утилиты (pgcenter top). И в первый раз, когда ее запускаешь, это может немного напрячь. Это похоже, что это какой-то центр управления полетами. Много цифр, много букв, все это быстро меняется. Но это на самом деле не важно. Здесь важно помнить, что интерфейс pgCenter, а именно top-просмотрщика, состоит из трех частей.

Первая часть – системная информация. Эта информация находится в верхнем левом углу.

Вторая часть – верхний правый угол, здесь располагается сводная информация по Postgres. Здесь можно получить уже какую-то детальную информацию о том, как Postgres работает в данный момент.

И третья часть – статистика из самих статистических представлений (views). Здесь информация из stat-представлений, которые есть в Postgres, в этой части отображаются изменения этой статистики.

Кроме того, интерфейс предоставляет дополнительные функции. Нажимая стрелки влево-вправо, вы можете менять сортировку. Вы можете указать сортировать строки по интересующему вас полю. Например, сортировку по именам таблиц, сортировку по текстам запросов, по времени и жизни транзакций, и т. д.
Если информации слишком много, можно использовать фильтры. В качестве фильтров там применяются регулярные выражения (regexp). И вы можете отфильтровать выводимую инфоормацию по интересующим вас критериям. Например, показать запросы конкретного пользователя, базы или конкретно какие-то запросы: селекты или апдейты.
Далее в докладе я расскажу, с какими конкретно кейсами вы можете столкнуться у себя в работе и какие подходы можете применять используя pgCenter. И самый основной кейс – это проверка все ли в порядке с базой и нет ли там каких-то проблем.

И здесь мы все делаем, как по известному USE методу. Нам нужно определить использование ресурсов. Если ресурсы используются более-менее хорошо и прекрасно, то мы смотрим наличие ошибок.

Для этого мы начинаем смотреть системную информацию. У нас есть информация об использовании процессора. Всем, кто знаком с утилитой линуксовой Top, вот этот раздел статистики будет очень хорошо знаком. Он показывает утилизацию процессора: системную, пользовательскую и т.д.

Если нам интересно посмотреть память, то в этой же строке также мы можем посмотреть и память: сколько у нас есть памяти вообще, сколько свободно, сколько занято.

И, соответственно, swap. Если в системе есть swap, а для базы данных он важен, то можно посмотреть еще и статистику по swap. Таким образом в части по системной статистике можно быстро определить – есть ли у нас проблема с утилизацией ресурсов.

Кто-то может спросить: «А как с блочным вводом-выводом и сетью?». Эта статистика тоже есть. Ее я покажу чуть позже, по ней тоже есть цифры.

Когда мы посмотрели нет ли у нас проблем с утилизацией ресурсов, мы можем идти к проверке – нет ли у нас каких-либо ошибок на уровне работы Postgres. Мы можем посмотреть uptime. Вообще, uptime в Postgres – не совсем честный, но тем не менее это лучше, чем совсем ничего. С аптаймом можно быстро определить, как давно у нас работает Postgres и не было ли у него незапланированных рестартов.

Кроме того мы можем посмотреть состояние по подключениям. Не все клиенты, которые работают с Postgres, могут быть хорошими. У нас могут быть ждущие транзакции, которые находятся в ожидании, или транзакции которые ничего не делают. Т. е. это та активность которую важно отслеживать и вовремя принимать меры.

И, конечно, автовакуум. Я думаю, многие из вас знают, что такое автовакуум. С ним связано много интересных историй, поэтому про вакуум тоже можно посмотреть. Например, сколько воркеров запущено и посмотреть их длительность. И после этого можно как-то реагировать на эту информацию.

И долгие транзакции, потому что Postgres MVCC база данных. В ней MVCC движок. И он очень сильно зависит от того, как долго там работают транзакции. Поэтому самые долгие транзакции тоже важно отслеживать и быстро о них узнавать.

На этом слайде было переключение на статистику баз данных с помощью горячей клавиши 'd'.
Говоря про ошибки, важно отметить pg_stat_database которая предоставляет некоторое количество информации об ошибках, тут нас интересует поле «rollbacks». Это поле не только про команду «ROLLBACK», но еще и про различные ошибки которые привели к отмене запроса/транзакции. Это могут быть ошибки нарушения ограничений (constraints), это могут быть ошибки синтаксиса и т. п. По этой статистике можно уже отследить, что происходит в базе.
И плюс в pg_stat_database есть еще информация по конфликатм репликации (conflicts) и взаимоблокировкам (deadlocks). По сути, это тоже виды ошибок, которые говорят о том, что в базе что-то идет не так.

ОК, мы запустили pgCenter. И за относительно короткое время мы смогли посмотреть много вещей, ради которых нам бы пришлось запустить несколько утилит. Во-первых, это:
top
vmstat
iostat
nicstat
pg_stat_activity
pg_stat_statements
Плюс там еще использовали некоторые функции, которые тоже показывают информацию в более понятном виде.

Допустим, что в процессе проверки мы обнаружили, что у нас какая-то есть нагрузка на процессор.

Вот такой простой пример. Вам не обязательно все это рассматривать, важно отследить те места, которые используются в процессе оценки. Т. е. здесь CPU usage – 85 %. Это говорит о том, что у нас нагрузка на процессоры довольно-таки высокая. И нам нужно найти, кто же так активно использует процессора. Понятно, что это Postgres. Нам нужно заглянуть глубже в Postgres и посмотреть, какие типы запросов у нас больше всего потребляют процессорного времени.

Если мы посмотрим на вторую часть экрана, то мы увидим, что у нас 38 активных клиентов, которые что-то делают. При этом нужно посмотреть на соседние state: на waiting и на idle_xact. Waiting у нас 0, т. е. у нас клиенты не находятся в режиме ожидания и это хорошо. С другой стороны, у нас есть 20 idle транзакций. Соответственно, мы можем включить сортировку по длительности транзакций (xact_age) и посмотреть – сколько времени наши транзакции находятся в простое. И здесь видно, что простаивает всего одна транзакция. И ее время жизни – 15 секунд. Это не страшно, и в большинстве случаев это можно не считать криминалом.

(Примечание: На слайде переключились в pg_stat_statements. Чтобы переключится в pg_stat_statements необходимо нажать "x", там будут нужные столбцы. Второй вариант "shift + x" и в меню выбрать pg_stat_statements_timings. Если будет ошибка "pg_stat_statements not available on this database", то нужно установить расширение pg_stat_statements от юзера postgres в базу postgres: create extension pg_stat_statements;)
Но мы же ищем источник, кто у нас потребляет больше всего (процессорного) времени. Нам нужно оценить, какие запросы используют больше всего времени. Для этого мы используем pg_stat_statements. Это contrib. Он показывает нам статистику по запросам: сколько они выполнялись, сколько ресурсов потребляли. Этот contrib должен быть установлен в базе, чтобы брать с нее статистику. К сожалению, он выключен по-умолчанию. И одна из основных рекомендаций по настройке Postgres – включать pg_stat_statements.
Предположим, что он у нас стоит. Нам нужно посмотреть время, кто у нас тратить больше всего. Мы стрелочками переключаем сортировку. И видим те запросы, которые у нас тратили больше всего CPU с момента сброса статистики pg_stat_statements. Тут отражен примерно суточный разрез – за сутки конкретный тип запроса отработал 2 часа с лишним. Это запрос SELECT COUNT (*) FROM "game_competition_events". Т. е. уже имея на руках запрос, мы можем сходить в логи, взять параметры этого запроса и посмотреть, какой у него план, и попытаться с ним разобраться. Может быть, там нет какого-нибудь индекса, может быть, там запрос написан неоптимальный или еще что-то. Уже у нас есть конкретная информация о том, кто потребляет процессорное время.
Но здесь есть небольшая ловушка. Мы используем сортировку под total_time. А в total_time включается не только процессорное время, но еще и время, потраченное на операции блочного ввода/вывода: на чтение и на запись. Соответственно, нам желательно включить сортировку по полю «t_cpu_t». Оно нам более релевантно. Оно нам позволяет смотреть именно процессороемкие запросы.

Как я уже сказал, эта статистика показывает самые жадные до ресурсов запросы с момента сброса статистики. Если нам нужно смотреть запросы, которые отнимают процессорное время здесь и сейчас, то мы смотрим уже по полю «cpu_t», это, условно говоря, дельта. Мы берем snapshot статистики за прошлую секунду, за текущую секунду, считаем дельту и показываем. Здесь запрос уже совершенно другой. Это SELECT "courses_logs".* FROM course_logs. И здесь видно, что текущую секунду он съел уже 5 секунд процессорного времени. Это либо запрос, который использует параллельные воркеры, либо, возможно, он просто запускается слишком часто.
И если посмотреть на соседнюю колонку «calls», то там будет видно, что запрос выполняется один. Один запрос в секунду. Т. е. это запрос с параллельными воркерами.

Пока мы все это смотрели, мы могли использовать другие утилиты. Это Top и плюс нам нужно было заглянуть в pg_stat_activity и в pg_stat_statements. Но с помощью pgCenter это все в одном месте собрано и можно этим пользоваться.

Другой вариант – это нагрузка на ввод-вывод. Это другая противоположность, когда с процессорами у нас все в порядке, но диски слабые и нужно разобраться, кто утилизирует ввод-вывод.

Ситуация похожа на предыдущий случай. Мы смотрим на утилизацию процессоров и видим, что у нас утилизация процессоров на время ожидания блочного ввода-вывода довольно высокое – 27 %. Нам нужно найти те запросы, которые вызывают этот ввод-вывод.

Плюс мы можем еще обратить внимание на то, что многие клиенты с типом «background worker». Это явный показатель, что у нас параллелизм включен и запрос выполняется параллельно.

Посмотрим по соседним «wait_event». И тут видно, что эти клиенты находятся в ожидание ввода-вывода. Т. е. очень много времени тратится на чтение данных с диска.

И здесь нам уже понадобится статистика по блочному вводу-выводу. С помощью горячей клавиши 'B' мы включаем встроенный iostat. И он нам показывает утилизацию дисковых устройств. Здесь видно, что утилизация одного из устройств 99 %. Но здесь самое главное – это не попасть в ловушку, потому что устройство у нас NVME. И нужно уже смотреть не только на утилизацию, но и на latency.

Если посмотреть на latency, то latency для этого устройства будет составлять всего лишь 1 миллисекунду. И это вполне нормально.
Это значит, что у нас нет особых проблем в производительности. Это связано с тем, что современные SSD и NVME-устройства выполняют операции ввода-вывода в несколько потоков, поэтому мы можем видеть большую утилизацию, но при этом низкий latency. Если мы видим большие цифры по latency, то это значит, что у нас действительно уже есть проблемы и нужно что-то делать.
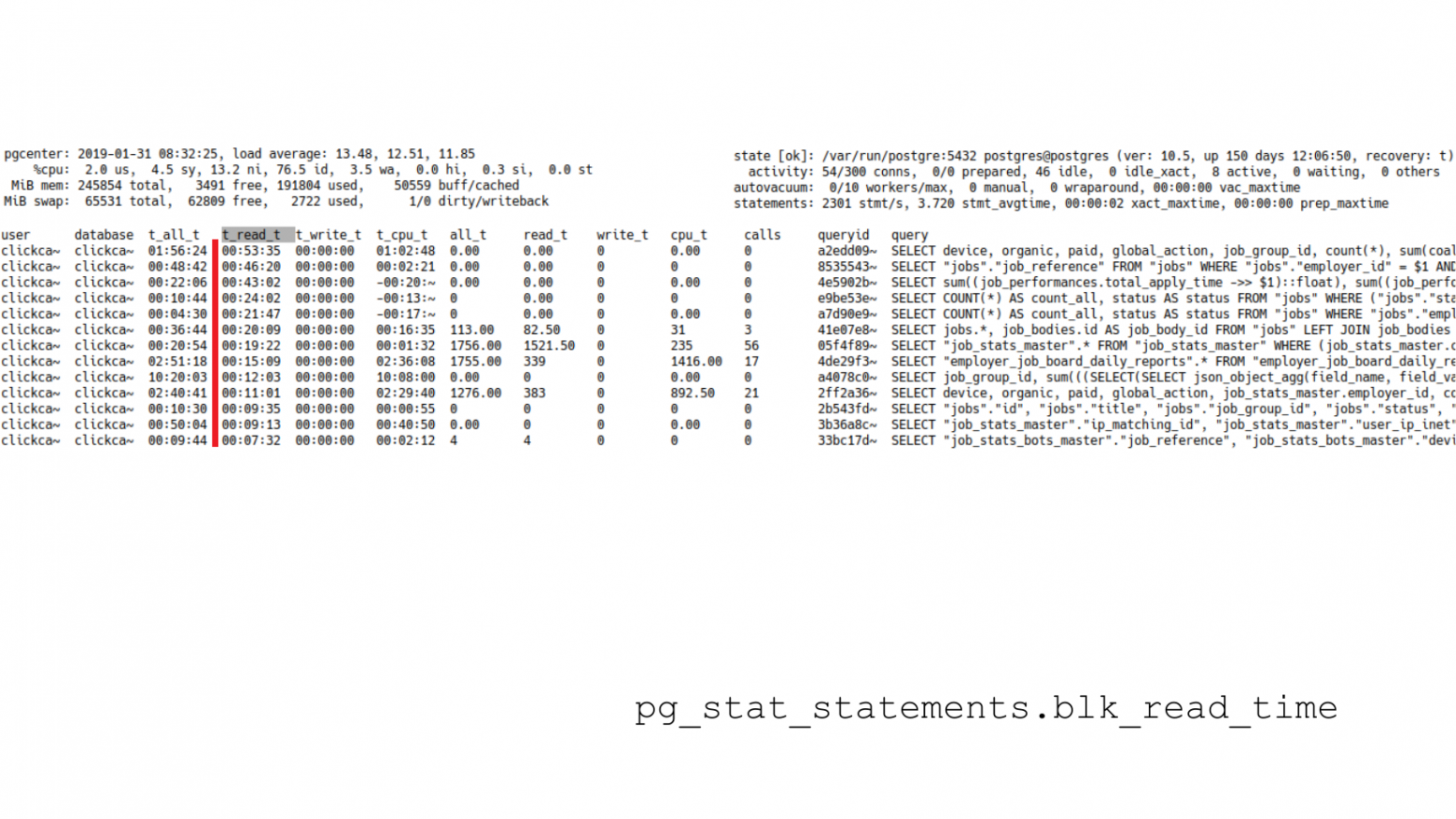
Но тем не менее давайте смотреть, какие запросы выполняют больше операций ввода-вывода. Мы переключаемся на pg_stat_statements и смотрим уже не процессорное время, а время ввода-вывода. Это колонка «t_read_t», т. е. время, потраченное на чтение данных с момента сброса статистики.
Аналогичная колонка есть и для просмотра статистики за последнюю секунду. Это колонка «read_t». Мы можем менять сортировки и смотреть, какие запросы за весь интервал времени сожрали больше всего ввода-вывода, либо за последнюю секунду.
Важно отметить что статистика по ввод/выводу собирается только при включенном track_io_timing.
И уже имея текст запроса мы можем переходить к его поиску в логах, найти его параметры и узнать, что там долго там работает. Но pgCenter еще предоставляет такую штуку как queryid. Это такой идентификатор запроса. Но это не такой идентификатор, который предоставляется в pg_stat_statements. Он немного другой. Его можно использовать для построения отчетов. Т. е. pgCenter предоставляет такую функцию как построение отчетов по конкретной группе запросов. Также через горячие клавиши мы смотрим по queryid. И pgCenter предоставляет отчет.

Отчет состоит из трех частей:
Первая часть – это summary, общая картина составленная на основе той статистики, которая накопилась в pg_stat_statements. Это количество запросов, затраченное время в процессорах, затраченное время ввода-вывода.
Вторая секция уже связана уже с нашим запросом, эта секция описывает, какой вклад запрос вносит в общую статистику в summary. И мы уже можем видеть статистику связанную с этим запросом относительно всех остальных запросов.
И, конечно, сам текст запроса.
Строя такие отчеты, мы можем быстро посмотреть, насколько наш запрос вносит нагрузку в суммарную картину.

И если рассматривать, что мы затронули под капотом, пока это все смотрели, то все это покрывается утилитами top, iostat и представлениями pg_stat_activity, pg_stat_statements. Плюс там есть еще несколько функций, которые приводят все это в понятный вид.

Но запросы клиентские – это не единственная вещь, которая позволяет генерировать ввод-вывод. И в Postgres есть еще всякие фоновые задачи, которые тоже могут создавать нагрузку на диск.
Это:
Checkpointer pocess.
WAL writer process.
Autovacuum workers.
Background workers.
На данный момент pgCenter показывает только прогресс по вакууму, по остальным пока информации нет, но тем не менее это уже хорошо.

Предположим, что у нас с ресурсами все в порядке: блочного ввода-вывода никто особо не потребляет, с процессорами тоже полный порядок. И мы переходим к вопросу, что нужно посмотреть, что у нас на уровне ошибок.

И чаще всего это описывается ситуациями, когда клиент пишет в чат, что у него ничего не работает. Всё лежит и нужно что-то делать.
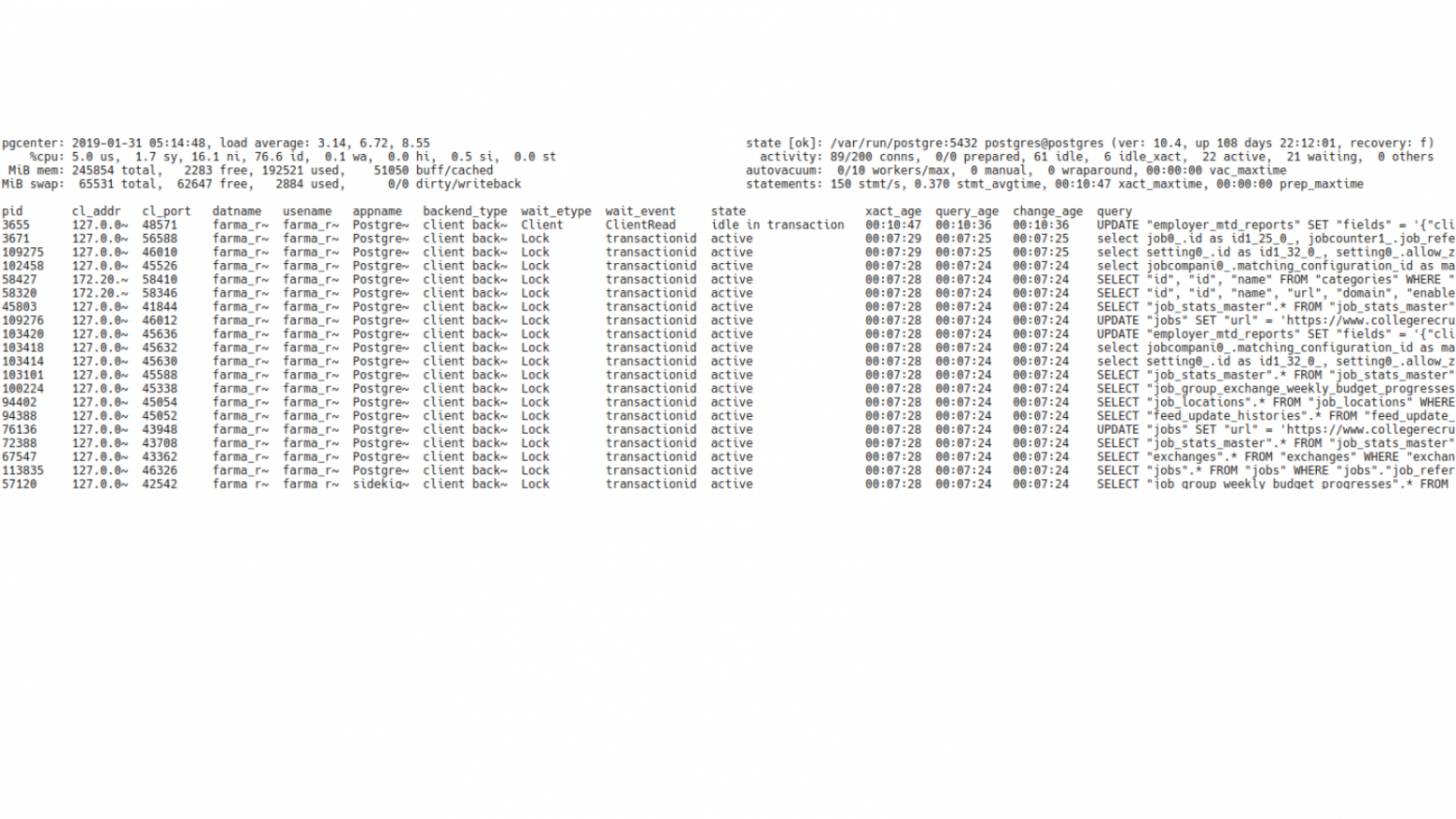
Здесь мы мельком посмотрели утилизацию ресурсов.

И тут нужно уже смотреть на состояние подключенных клиентов. Если посмотреть на клиентов, то будет видно, что у нас 22 активных клиентов и при этом 21 из них находится в режиме ожидания. Это уже показатель того, что что-то работает не так.
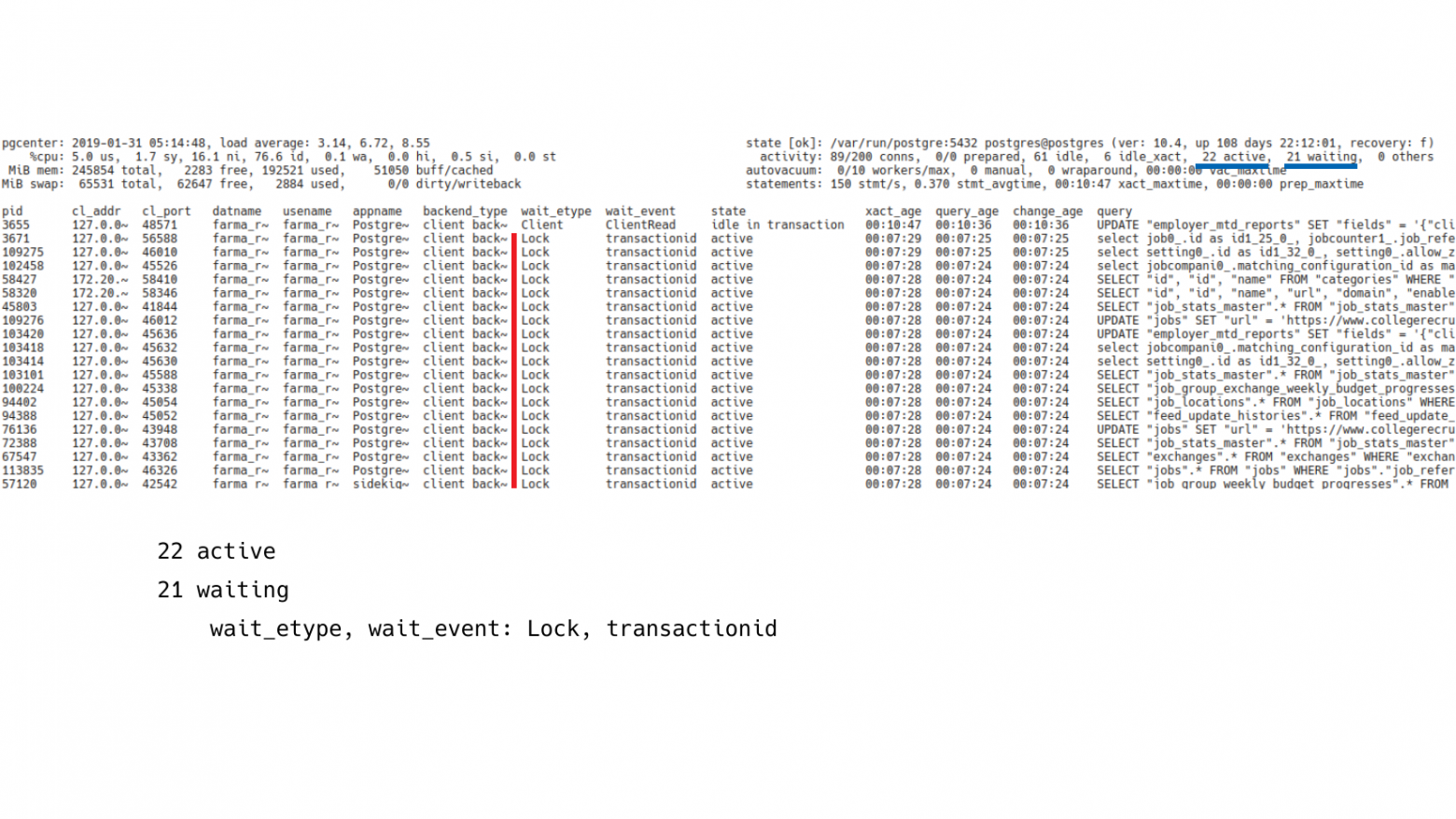
Если посмотреть на wait_event этих клиентов, то будет видно, что они все находится в режиме ожидания идентификатора транзакций. Т. е. какой-то клиент что-то делает, а остальные выстроились в некий хвост и пытаются дождаться, когда эта транзакция сделает свою работу.
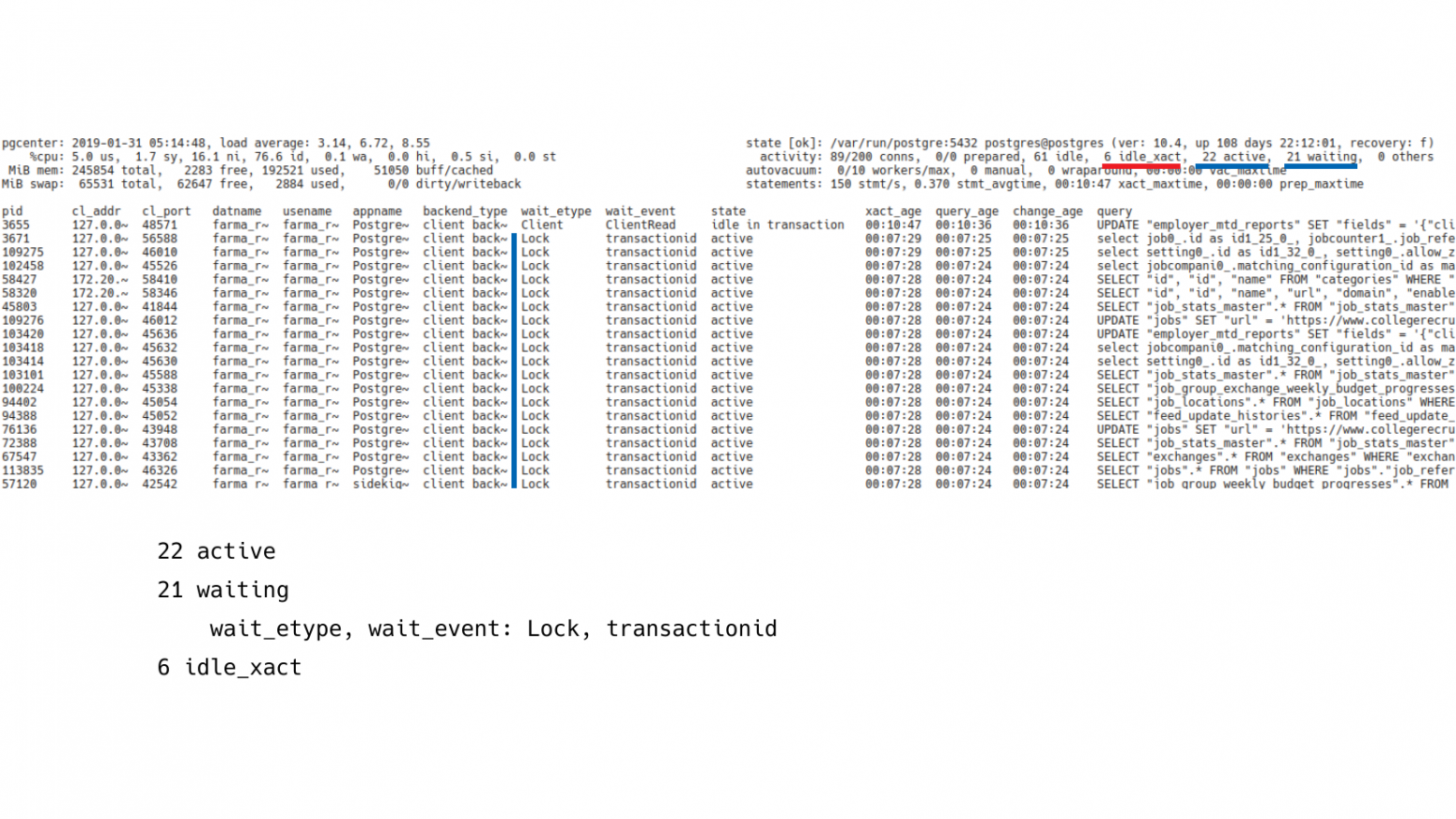
Нужно посмотреть на соседнее поле, которое показывает транзакции в режиме простоя (idle in transaction). И здесь мы видим, что их 6 штук. И нужно включить сортировку по времени работы транзакции.

Если посмотреть на отсортированное поле, то мы увидим, что у нас есть 10-минутная транзакция, которая ничего не делает в данный момент. Если мы посмотрим ниже, то есть еще куча транзакций, которые 7 минут находятся в ожидании. И они явно выстроились как раз в хвост за 10-минутной транзакцией.

Если посмотреть на wait_etype, wait_event этой транзакции, которая ничего не делает, то мы увидим, что она ждет как раз ожидания ввода со стороны клинского приложения (Client:Client Read). Приложение открыло транзакцию, что-то поделало, а потом ушло делать какую-то другую работу. И, возможно, где-то произошла ошибка, приложаени упало в том участке кода, но транзакция осталась незакрытой. Пришли другие транзакции и попытались обновить другие строки и прочитать данные, которые изменила эта транзакция, но попали в заблокированное состояние и теперь они все ждут завершения транзакции.
Самое просто решение – это отменить эту транзакцию. Есть две функции: pg_cancel_backend и pg_terminate_backend. Они позволяют отменить запрос, либо просто завершить работу этого backend. В pgCenter тоже есть эти функции. Можно с помощью горячих клавиш убивать как отдельный backend и запросы на основе pid, либо убивать их группами на основе маски.

Тем не менее под капотом здесь у нас:
Pg_stat_activity.
Pg_stat_statements.
Pg_cancel_backend ().
Pg_terminate_backend ().

Опыт показывает, что ситуации бывают разные. Бывает, не только, что собрался хвост из длинных транзакций.
Бывает долгая транзакция на таблице с очередью. Тот случай когда очередь реализована не отдельным брокером сообщений, а реализованы непосредственно в базе данных. У нас есть какая-то таблица. В нее вставляется много записей, также много строк обновляется и много строк удаляется (добавилось событие, изменился его статус, удалилось событие). Пришла какая-то долгая транзакция, которая поработала с этой таблицей, но также она перешла в состояние idle transaction и ничего не делает. И у нас также собрался длинный хвост из блокировок и все повисло — очередь перестала работать.

Другой кейс – это когда приложение в несколько потоков пытается обновлять одни и те же данные. И эти потоки начинают конфликтовать друг с другом, в результате возникают ситуации блокировок и взаимоблокировок (deadlocks) и все начинает работать совсем плохо.

Миграции. Можно сделать ALTER TABLE, добавление колонки, например, с простановкой дефолтных значений. Это очень тяжелая операция. Ее, к счастью, исправили в 11-ой версии и начиная с нее проставление дефолтов при добавлении поля работает безболезненно. Но тем не менее у многих заказчиков стоят старые версии Postgres, которые работают по старому. И любой такой тяжелый ALTER может также собрать на себе хвост ждущих транзакций и остановить работу приложения.

И классика жанра – это CREATE INDEX без CONCURRENTLY, когда кто-то по незнанию, либо просто забыл, что запустил создание индекса. Создание индекса заблокировало таблицу и появился снова хвост из блокировок.

Сейчас немного про репликацию, т.к. сегодня сложно представить, чтобы в production был сервер Postgres без реплики, поэтому бывает необходимость проверить репликацию и все ли с ней в порядке.
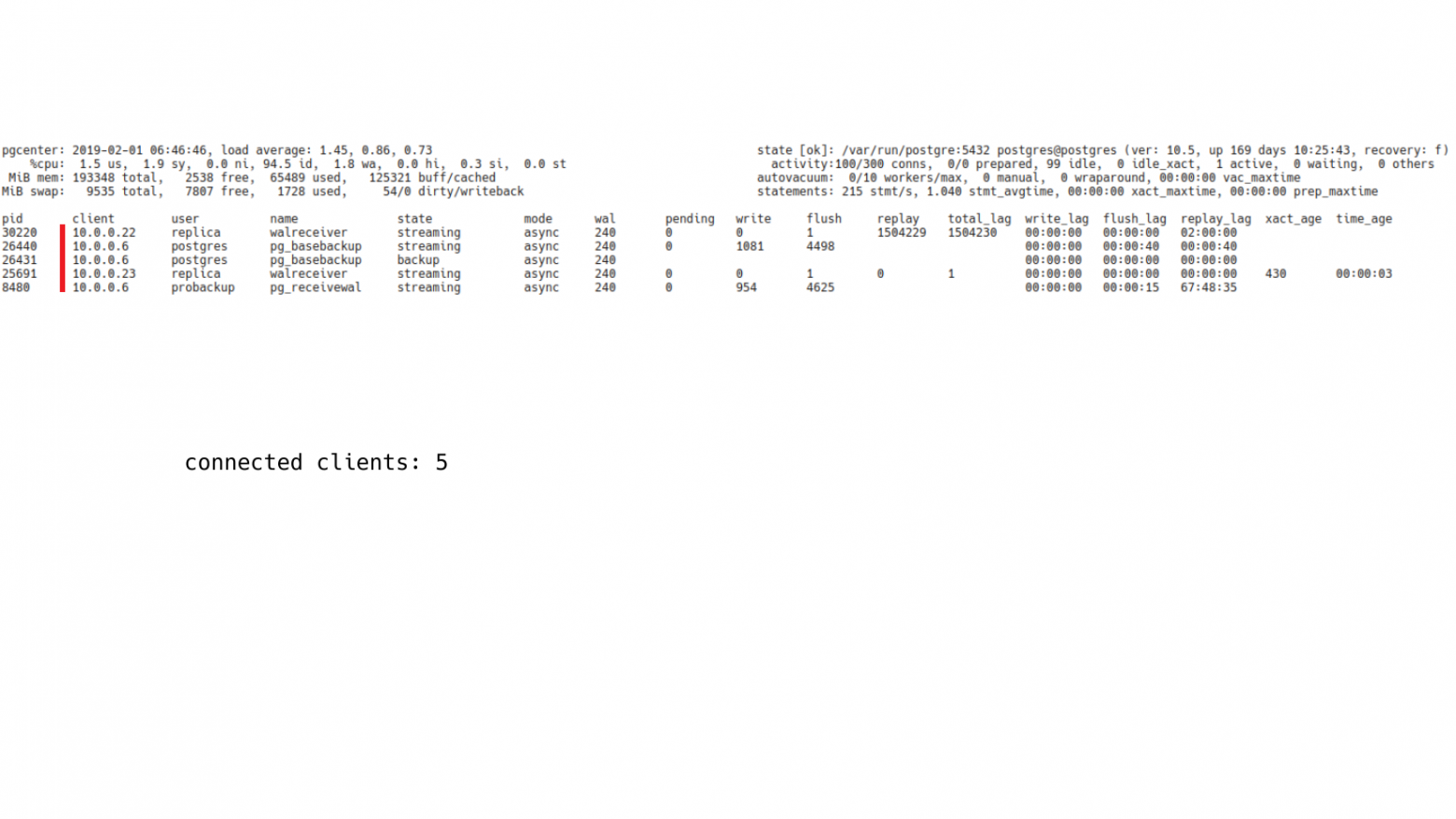
Для этого есть представление pg_stat_replication. Она показывает клиентов, подключенных к Postgres, которые принимают журнал транзакций с этого узла по протоколу репликации.
И pgCenter тоже поддерживает pg_stat_replication. И можно переключиться с помощью горячих клавиш, и посмотреть, что там происходит.
В данном случае у нас здесь 5 клиентов. Они все подключены и принимают журнал транзакций.

Если посмотреть на их имена, то можно будет понять, кто это такие и что они делают. У нас здесь 2 walreceiver, т. е. это конкретно 2 реплики.

И дальше нас интересует, какой лаг репликации у этих клиентов, потому что лаг репликации непосредственно влияет на величину проблемы, которая у нас есть. Если маленький лаг, значит, более-менее все в порядке. Большой лаг, значит, проблемы есть – реплика сильно отстает по каким-то причинам и нам нужно выяснить по каким.
Соответственно, pg_stat_replication предоставляет разную информацию, которая позволяет нам посчитать лаг в байтах и лаг в секундах. И здесь лаг у одной из реплик на уровне 1,5 GB. И replay_lag в секундах – 2 часа. На самом деле это нормальная реплика. Она просто настроена с отложенным восстановлением журнала транзакций. У нее выставлено восстановление на уровне 2-х часов. Она скачивает все журналы к себе и воспроизводит их с задержкой в 2 часа, т. е. это вполне нормальная ситуация.
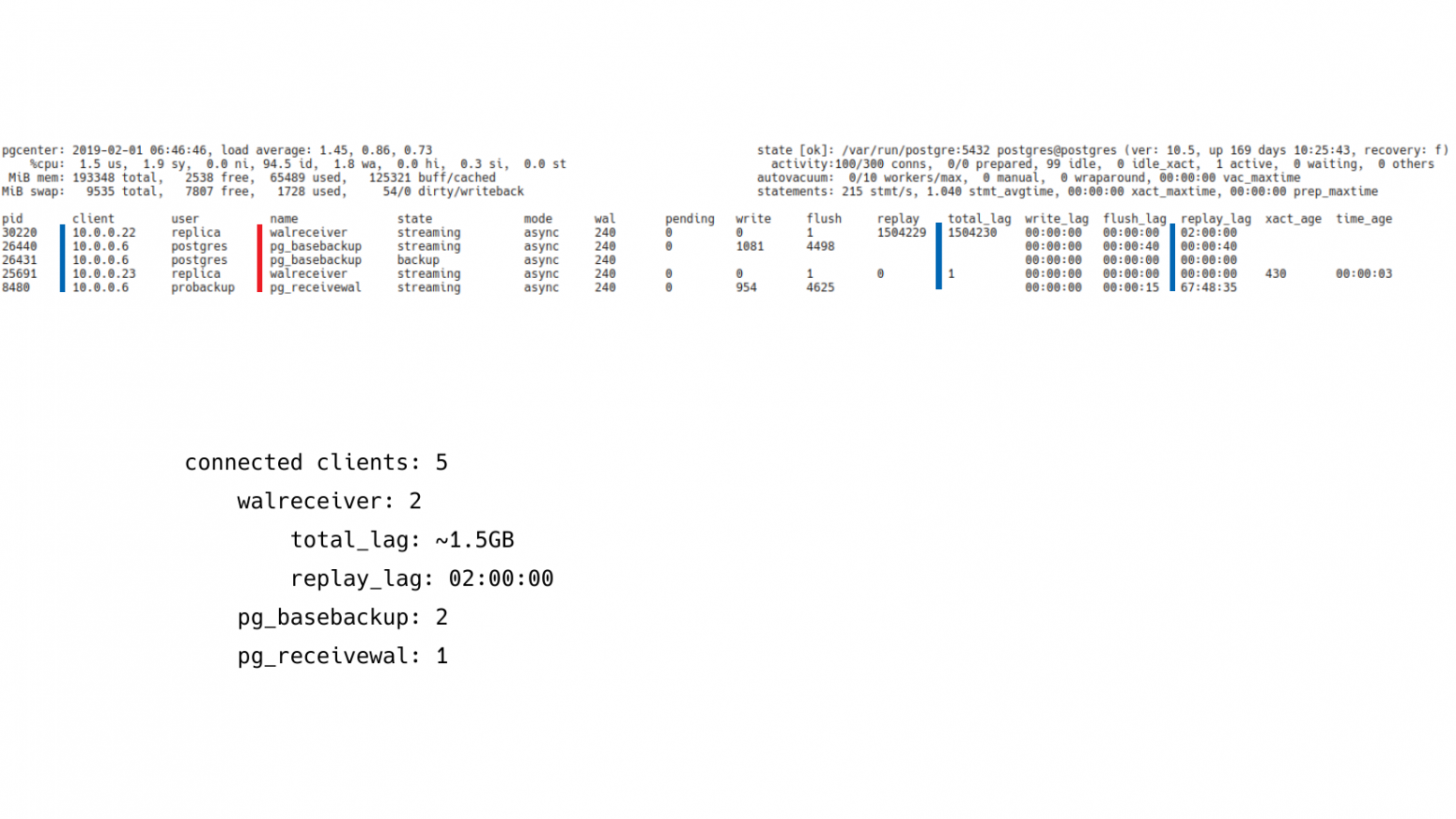
Если мы посмотрим на других клиентов, то будет видно, что у нас есть 2 pg_basebackup и 1 pg_receivewal. Pg_basebackup – это резервное копирование которое также работает по протоколу репликации. Он также виден в pg_stat_replication. И pg_receivewal – это процесс, который принимает журналы транзакций и сохраняет для задач архивирования. Т. е. здесь, в принципе, никакой проблемы нет. Здесь нет каких-то криминальных реплик, которые нужно было бы расследовать.
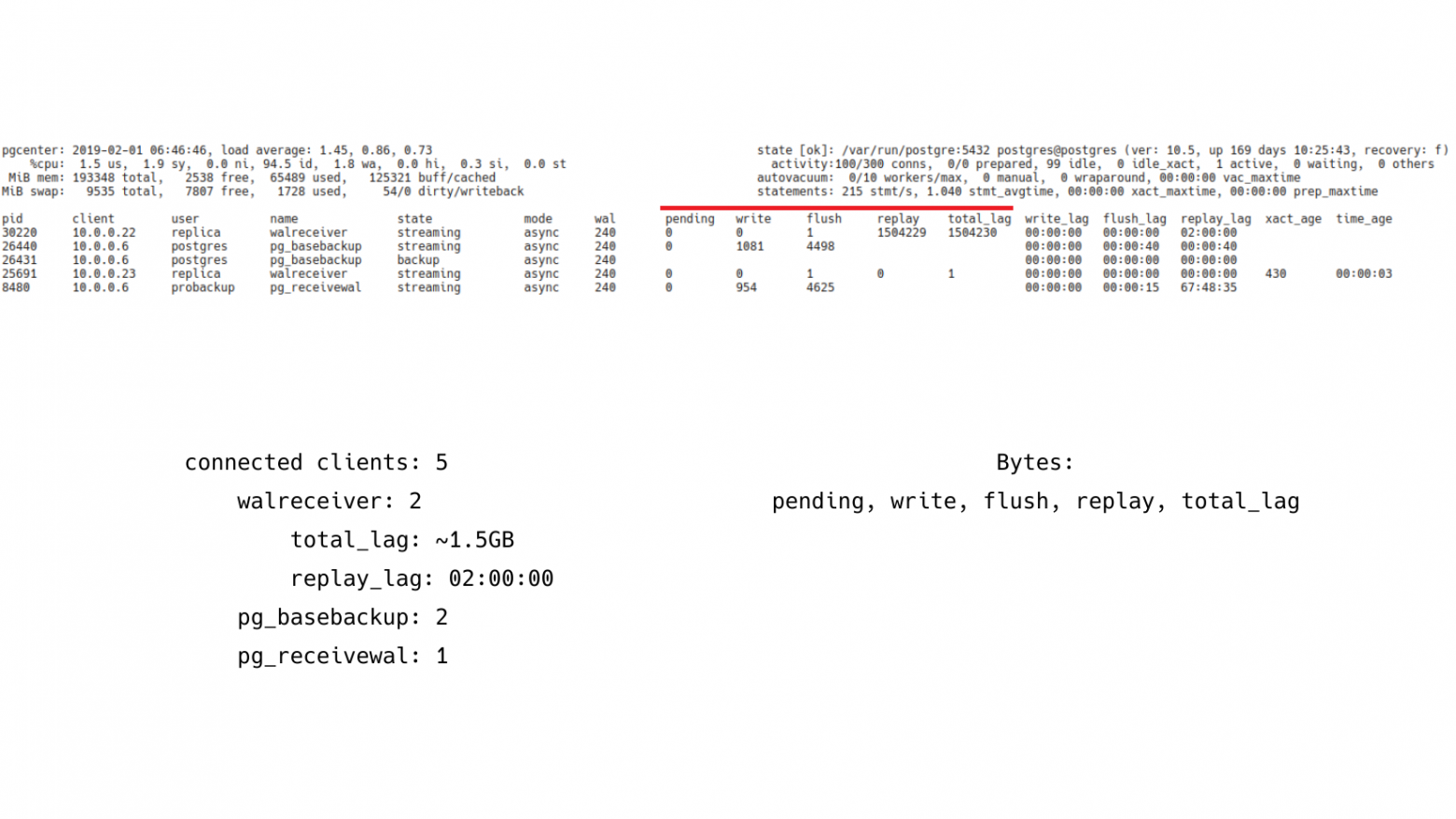
Но тем не менее pg_stat_replication позволяет показывать лаг в нескольких единицах измерениях. Это байты. И самое интересное, что этих метрик здесь аж 5 штук. Это: pending, write, flush, replay, total_lag. Т. е. лаг репликации может быть разным.
Pending – это когда журнал транзакций сгенерировался, лежит на Мастере. И Мастер его еще не успел передать реплике.
Write – это когда передача журналов уже идет, но до реплики еще не дошла, т. е. она еще не успела записаться.
Flush – это когда успели записать уже на реплику, но не успели сбросить на надежное хранилище.
Replay – это когда сбросили на надежное хранилище. И осталось только проиграть.
Total_lag – это максимальная величина от момента генерации до момента проигрывания.
Соответственно, наблюдая лаг в этих местах, в этих контрольных точках, мы можем более-менее понять, где у нас проблема. Например, проблема на дисковой подсистеме Мастера; либо ошибки сети, которые снижают скорость передачи; либо это загруженная дисковая подсистема реплики, которая не успевает все это писать, синхронизировать с диском и воспроизводить.

Кроме того, есть лаг репликации во времени. Он более человекопонятный. Когда людям говоришь про минуты, про секунды, они это лучше воспринимают.
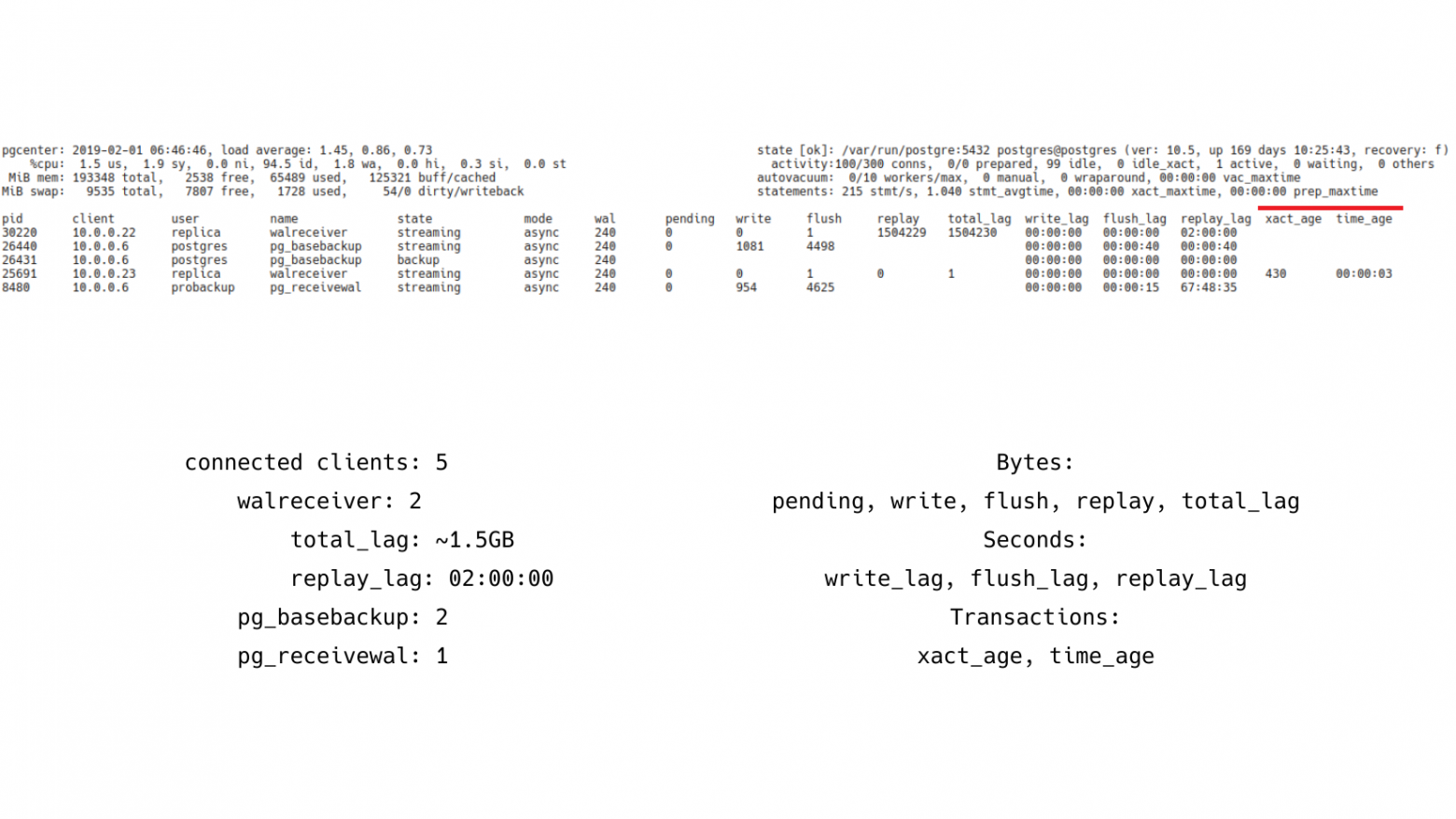
И последний момент – это лаг репликации в транзакциях, т. е. можно отследить величину – сколько транзакций нужно проиграть реплике, чтобы она догнала Мастера. Эта штука по умолчанию выключена в Postgres, ее нужно включать отдельно. Но она редко бывает нужна, только в каких-то особых случаях.

Под капотом этой всей диагностики у нас:
pg_stat_replication.
pg_wal_lsn_diff().
pg_current_wal_lsn().
pg_last_commited_xact().

Я вам рассказал все эти кейсы, но за кадром есть еще много других вещей.

Например, в top можнос смотреть статистику по таблицам. Табличные статистики – это все Seq Scan, количество update, delete, insert, живые и мертвые строки.

Статистика по индексам. Можно посмотреть утилизацию индексов. Отыскивать неиспользуемые индексы и их заносить в черный список и потом удалять.

Статистика по функциям. Можно смотреть, какие пользовательские функции запускаются больше всего, сколько времени они потребляют. Можно также сортировать, смотреть и выбирать кандидата для оптимизации.

И, конечно, pg_stat_progress_vacuum появился в 9.6. Раньше, в плане статистики, вакуум был черным ящиком, было сложно понять, как долго работает, как скоро он закончится и сколько ему еще работы надо делать. И pg_stat_progress_vacuum – это способ заглянуть в этот черный ящик и понять что там происходит. Можно оценить, сколько ему там осталось доработать. Хотя, конечно, есть недостатки, есть претензии к нему. Но тем не менее лучше, чем ничего.

И есть вспомогательные, админские функции для самого администратора. Это просмотр логов, просмотр и изменение конфигурации, т. е. мы можем через горячие клавиши открыть postgresql.conf, что-то в нем поправить и потом горячей клавишей сделать reload. Это не самая правильная практика, конечно, но тем не менее возможность есть.
Плюс есть функции по просмотру логов. Вам не нужно помнить, где же лежит лог, как он там называется и набирать руками путь до него. Нажимает хоткей и лог открывается в просмотрщике. Можно найти там нужный запрос с нужными параметрами, скопировать и дальше изучать его.
Плюс есть функция вызова psql, т. е. мы также нажимаем горячую клавишу и у нас открывается psql к той базе, к которой у нас подключен pgCenter. Таким образом если есть какие-то вещи, которые нам надо сделать и мы не можем сделать это с помощью pgCenter, мы можем быстро вызвать psql и сделать это там.

top-просмотрщик – это основная утилита, которая развивалась изначально в pgCenter. Но помимо top есть еще другие утилиты, которые тоже являются частью pgCenter. Это record и report.
Суть в том, что мы делаем мгновенные снимки статистики и сохраняем их в файле. Мы можем запускать сбор с нужным интервалом и эти снимки будут сохраняться. А потом с помощью report строить отчеты, аналогичные тому, что показывает Top. В некоторых ситуациях это бывает полезно — например отсутствие полноценого мониторинга.

Я использую это для своих микро-тестов. Когда мне нужно что-то потестировать, я запускаю record. Раз в секунду он там все записывает и мне не нужно ставить никаких мониторинговых агентов. Я могу это все так быстро на коленке посмотреть.

Плюс недавно я добавил сэмплер wait_event’ов, можно брать свои долгие запросы и смотреть, на каких участках запрос тратит свое время на ожидание.

Вот простой пример: SELECT всех строк из таблицы с последующей сортировкой. Если посмотреть, куда тратится время, то видно, что 44 % времени запрос выполняется, делает какую-то полезную работу, а оставшееся время – это ожидание ввода-вывода при чтении файлов, взаимодействие между параллельными воркерами.

Второй пример: это VACUUM FULL. Здесь видно, что большую часть времени VACUUM FULL работает с дисковым IO и читает данные, а работает он всего 12 %. Вот эта штука довольно полезная, когда есть любопытство попрофилировать свои долгие запросы и посмотреть, чем они занимаются и в каких местах проводят время в ожидании.
Вопросы
Спасибо за утилиту! Лично я ею пользуюсь. Она мне нравится. Я часто использую ее с ноутбука. И когда я смотрю, например, pg_stat_statements, у меня колонка query с текстом не влезает. Есть ли какая-то возможность поменять порядок столбцов или какие-то столбцы отключить на время?
К сожалению, такой функции нет. Архитектурно программа так устроена, что эта фичу тяжело запилить, но можно, наверное, что-то придумать там, переписать и такая функция появится. Как минимум, не перестановку колонок, а отключение-включение по желанию. Но отсюда вылезает второй вопрос. Наверняка кто-то захочет сохранить отображение этих колонок и при последующем запуске показать. Т. е. появится необходимость конфига, который нужно поддерживать, хранить где-то. Это такая задачка, которая собирает еще другие задачки, чтобы ее реализовать. Я думаю, что это можно сделать, но пока этого нет.
И второй комментарий из той же оперы. Когда режим базы данных, то у вас количество rollbacks. Иногда хотелось бы отличать rollbacks, которые были по команде от тех rollbacks, которые не по команде.
Это, к сожалению, невозможно, потому что сам интерфейс pg_stat_database не позволяет такого. Он показывает только rollbacks и все.
Там можно из pg_stat_statements считать rollbacks, вычитать.
Можно, если заморочиться. Можно расширить запрос. Мы делаем `SELECT FROM pg_stat_database JNOIN pg_stat_statements` под запрос к pg_stat_statements, где мы считаем rollbacks и плюс арифметика, которая это все высчитывает. Теоретически можно. Но нужно посмотреть, как быстро будет работать этот запрос и не займет ли выполнение больше 10-20 миллисекунд.
Алексей, спасибо за доклад! С какой минимальной версией Postgres ваша утилита работает?
Я ее тестировал с версии 9.0-9.1, когда еще на C писал. Если какие-то запросы, особенно связанные с репликацией, не работают, то она пишет небольшую ошибку и есть возможность переключится на другой скрин, на другую статистику. Go версию тестировал, начиная с 9.4. Потому что в 9.4 появился функционал, когда мы берем SELECT… where filter. Это такой синтаксис интересный. В старых версиях (9.3) его нет. А у меня часть запросов как раз используют этот синтаксис и в старых версиях это работать не будет. Либо это будет работать, но будет показывать нули там, где эта статистика используется. Но я стараюсь на всех версия тестировать, проверять, чтобы, как минимум, ошибок не было.
Алексей, спасибо за утилиту! И спасибо за то, что интерфейс там от TOP. За это двойное спасибо.
Более того, я старался горячие клавиши делать, похожими на другие утилиты. Например, кнопка фильтра – это слеш. Кто знаком с less (пейджер такой), то слеш – это поле ввода, чтобы набрать шаблон для поиска.
У меня вопрос по поводу сортировки. Там так же как в TOP подсветка поля идет сортируемого?
Да. У меня на скриншотах это не видно, я, видимо, упустил этот момент. На некоторых скриншотах видно, на некоторых не видно. Да, поле подсвечивается. Когда вы стрелками перемещаетесь, вы видите, что у вас сортировка меняется и имя в колонке подсвечивается.
Спасибо за утилиту! Сегодня в первый раз о ней узнал. Оказывается, столько много возможностей. Вы размышляете, что вот у меня 85% CPU usage, давайте проанализирую, что сейчас происходит. Для этого пойду и обращусь к временным снимкам pg_stat_statements. Но там же архив находится. А нас интересует, что сейчас происходит.
Не архив. В нагрузке на CPU есть два поля. Первое – t_all_t. Это сколько времени намотал запрос со времени сброса статистики pg_stat_statements. Условно, у нас суточный срез. Если мы раз в сутки сбрасываем статистику, то мы получим статистику за текущий момент от начала суток. Плюс есть разбивка t с подчеркиванием и они уже здесь заканчиваются. Т. е. у нас есть аналогичные поля без префикса «t». Они как раз нам показывают статистику за текущую секунду. Т. е. мы можем смотреть, сколько процессорного времени потрачено запросом прямо сейчас.
Это понятно. Но если сейчас происходит то, что еще нет в pg_stat_statements, то как мы это проанализируем?
Мы каждую секунду выходим к pg_stat_statements и берем снапшот статистики прямо в real time.
Вопрос был в том, что в pg_stat_statements залетит уже после, а цифра 85 CPU usage – она сейчас.
Да, расхождение статистики будет. Но вы все равно можете смотреть текущую статистику, которую вам pg_stat_statements показывает. Если вы видите, что у вас использование процессора упало, то вы уже не увидите тот срез статистики, который был 10 секунд назад, когда использование процессоров было высокое. Тут нет такой интроспекции на 10 секунд назад – запомнить и отмотать, как это сделано, например, в atop. Вы на atop намекаете?
Примерно, да. Тут некое будущее и прошлое pg_stat_statements, а CPU, которая сейчас, нужно потом проанализировать, что залетит в pg_stat_statements.
Для этого придумана система мониторинга. Например, Grafana, там есть отрисовка графиков и вы уже в исторической перспективе все эти графики смотрите и анализируете. Т. е. pgCenter – это инструмент, который нам нужен здесь и сейчас, чтобы быстро продиагностировать, быстро понять, что происходит.
В связи с этим же вопрос. pgCenter умеет как atop сбрасывать статистику в текстовом виде, чтобы потом можно было запихнуть в Grafana?
Есть функции pgCenter report и pgCenter record, т. е. можно снапшоты статистики сбрасывать в текстовые файлы. Единственное, что там нет интерфейса, как по стрелочкам переключаться и смотреть. Т. е., условно говоря, с помощью pgCenter report запросить нужную статистику, например, по pg_stat_database и он прочитаем там все файлы накопленной статистики и как sar покажет. Я вдохновлялся больше им. Нет такого как у atop, когда можно стрелочками работать.
Алексей, большое спасибо! В отличие от всей известной базы Х, в Postgres, к сожалению, нет, кумулятивных статистик ожиданий. Вы сделали профайлер, который показывает разброску по ожиданиям. А с какой частой вы их опрашиваете? Какая там детализация?
Дефолтный интервал в 10 миллисекунд. А через флажок «-f», можно указывать частоту детализаций. Понятно, что высокая частота детализации, например, в 10 миллисекунд тоже создает нагрузку на систему. Но учитывая, что pg_stat_activity в памяти, то запросы там довольно легковесные. Они доли миллисекунд занимают. Но если такая частота напрягает, можно менять. Поставить, например, раз в 50 миллисекунд. Я замерял, как отражается это на конечной статистике, там погрешность есть на уровне 1-2 %. Т. е. если просуммировать все столбики, то мы увидим, что у нас куда-то 0,5-2 % потерялось.
Там в конце суммарная статистика есть. Можно видеть, что что-то потерялось.
Да, там видно будет. Да, даже на нашем примере мы видим, что 0,04 % не учли. Но, я думаю, это не критично. Это не какой-то инструмент для хардкор аналитики.
Но лучше все равно ничего нет.
Интересно просто посмотреть, что там у нас происходит.
Алексей, спасибо за доклад! Вдогонку вопрос по профайлеру. Вот этот wait_event Running – это просто отсутствующий?
Да.
Я его воспринимаю как ожидание на CPU.
Да, именно так. Т. е. когда мы заметили, что wait_events у этого PID нет, то мы считаем, что backend делает какую-то полезную работу, прямо крутится на процессоре, что-то высчитывает. И мы закидываем в Running, типа он работает, т. е. он не находится в ожидании.
Но все же это ближе к CPU?
Да, это ближе к CPU, т. е. запрос делает какую-то работу. Это не ожидание.
Привет! Спасибо за доклад! Насчет пакетирования есть какие-то планы, например, Ubuntu?
Когда она была написана на C, то все майнтейнеры были радостные. Говорили, что круто, сейчас тебе пакетов насобираем. И в официальном репозитории PDGD были пакеты собраны для Ubuntu. Я на Launchpad собирал пакеты, но у них какая-то странная система сборки. Бинарник иногда сегфолтится. И я не мог понять, почему так. А сейчас на Go у меня просто Мастер-ветка, dev-ветка. В Мастере она релизы отсчитывает. И когда я делаю коммит с релизом, то travis-ci не только делает build, он еще делает build бинарника и выкатывает его в раздел релизов. Т. е. если посмотреть в Realeses, то туда релизы будут сваливаться. Вам остается только взять wget, сходить по ссылке, забрать и распаковать tar’ом архив, и можно будет пользоваться.
Есть проект Goreleaser, который позволяет автоматизировать это. И можно собирать пакеты.
Круто, я с GO не очень знаком. Я еще раз повторяю, я не профессиональный программист. Я не знаю, что такое SOLID. И то, что вы говорите, что Goreleaser есть, это интересная штука, я посмотрю, что это такое. Раньше C’шные исходники у меня собирались, и я был счастлив. А сейчас мне приходится всем говорить, что есть ссылка на Realeses. Спасибо за совет!
Updated. Goreleaser успешно добавлен, большое спасибо за идею!
Алексей, вопрос по поводу queryid. Мы там видим queryid. У вас получается, что там поле немножко урезано и мы хвост не видим. Мы можем его полностью увидеть?
Да, конечно. Если мы не будем обрезать названия, то у нас в какой-то момент ширина колонок будет прыгать. И это для глаз не очень хорошо, плохо воспринимается. Поэтому ширина колонок рассчитывается под какую-то величину. Величина рассчитывается по сложному кейсу. Но в итоге ширина колонок ужимается и не прыгает. Если мы хотим ее увеличить, то мы стрелочкой переходим на это поле через сортировку. А потом стрелкой вверх увеличиваем ширину. А стрелкой вниз можем уменьшить ширину. И она сохраняется. Вы потом дальше можете сортировку менять, у вас ширина поля останется той, какой вы задали.
Ясно, это важный момент, потому что queryid – это четкий адрес.
Да, изначально ширина колонок прыгала и это раздражало. Я в dev-ветке это поправил, а в Мастер-ветке этого пока нет. В середине февраля я хочу выпустить Event Profiler. И как раз фиксированная ширина колонок будет.
Замечательно.
Да, через стрелки можно регулировать ширину.
Спасибо, Алексей!
Спасибо большое вам!
Видео:


{kind=link}