Расшифровка доклада 2018 года Алексея Лесовского "Давайте отключим vacuum?!"
Примечание редактора: Любые рекомендации по изменению параметров всегда стоит сравнивать в других докладах
Такой призыв часто возникает, когда в PostgreSQL возникают проблемы, и главным подозреваемым оказывается vacuum (далее по тексту просто "вакуум"). По опыту, многие наступают на эти грабли, и мне с коллегам по Data Egret нередко приходится разгребать последствия, так как потом всё становится ещё хуже. Но если обратить внимание на сам вакуум, то, пожалуй, нет такого человека, который бы использовал Postgres, и при этом ничего не знал про него. Ведь история вакуума начинается относительно давно, и в интернете можно найти массу как старых, так и новых постов про вакуум, объемные дискуссии в списках рассылки. Несмотря на то, что тема вакуума подробно описана в официальной документации к PostgreSQL, но��ые посты и новые дискуссии будут появляться и дальше. Возможно, поэтому с вакуумом связано очень много мифов, баек, страшилок и заблуждений. Между тем, вакуум является одним из важнейших компонентов PostgreSQL, и его работа напрямую сказывается на производительности. В одном докладе невозможно рассказать про вакуум абсолютно всё, но я бы хотел раскрыть ключевые моменты, связанные с вакуумом, такие как его внутреннее устройство, основные подходы к его настройке, наблюдение за производительностью, мониторинг, и что делать в случае, когда вакуум — главный подозреваемый во всех бедах. Ну и, конечно же, хочется развеять распространенные мифы и заблуждения, связанные с вакуумом.

Добрый день! Меня зовут Алексей. И сейчас я расскажу про вакуум: что бывает, когда специалисты берут и отключают вакуум. Расскажу, что происходит с базой и как не дойти до такой ситуации. И расскажу немного, как настраивать вакуум. В общем, буду рассказывать про вакуум и объяснять какие-то моменты, связанные с его работой.

Начну я с того, как люди доходят до того, что отключают вакуум и о том, как им приходит в голову такая мысль. Далее расскажу, что происходит после отключения вакуума. И расскажу, как устроен вакуум и почему его нельзя отключать, как его лучше настраивать, чтобы не доводить до аварийных ситуаций.

Что бывает, когда люди приходят к мысли, чтобы отключить вакуум?

Очень часто отдел разработки приходят к администраторам баз данных или просто к системному администратору и говорит: «У нас тормозит вся база, приложение тупит. Нужно что-то делать. Смотрите, разбирайтесь».
Как это выглядит? Как правило, админ запускает свою любимую утилиту. Смотрит нагрузку процессоров, смотрит нагрузку на диски и видит, что диски перегружены, утилизация – 100 % (самая дальняя колонка). И видит, что проблема действительно есть. И с этим нужно что-то делать.

Люди начинают смотреть, что у них с запросами. Открывают postgres’овый лог. Смотрят, в чем дело. Смотрят, сколько по времени выполняются запросы. И видят, что даже обычные операции занимают очень много времени. И это тоже проблема. И с этим нужно что-то делать.

Отдел разработки начинает жаловаться, что у них отваливаются запросы. Если какие-то реплики используются для распределения нагрузки на чтение, в логе появляется сообщение, что запросы отвалились, т. е. реплики уже начинают не справляться.
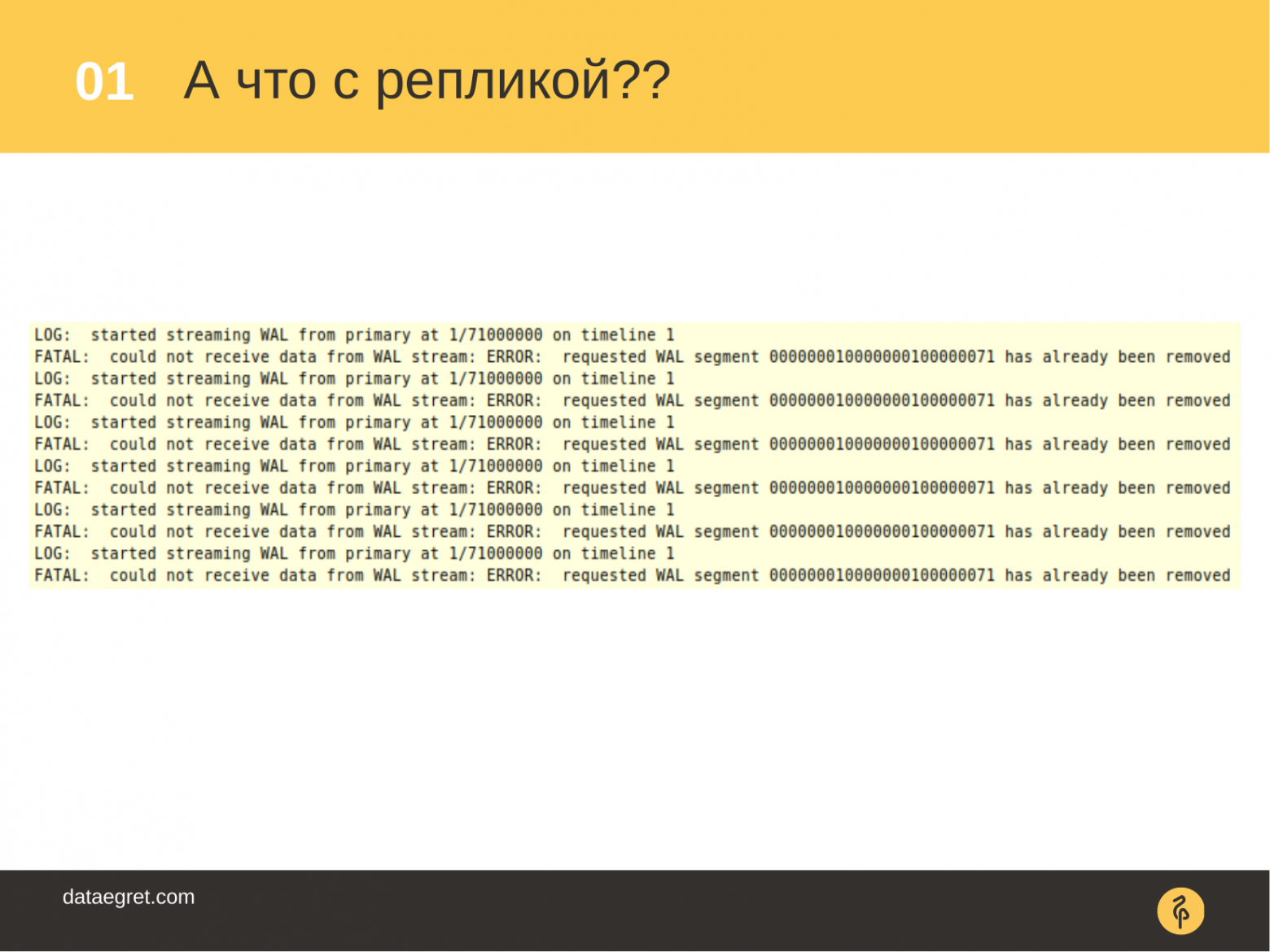
В какой-то момент отдел мониторинга/поддержки говорит: «Есть проблемы, кажется у нас отвалилась реплика». Произошла реальная проблема, ре��лика стала недоступной и ситуация стала критической. И с этим нужно что-то срочно делать.

И когда администратор дальше исследует проблему, он открывает, например, программу iotop и видит, что у него очень много запущено автовакуумов. Они все что-то делают. Они генерируют нагрузку на диск. Они создают большое количество журналов транзакций и реплики не успевают все это принять и обработать.
Это становится проблемой для базы данных. База данных начинает вести себя непредсказуемо в плане времени ответов на запросы и все это очень плохо сказывается на приложении. Приложение тупит, клиенты недовольны и бизнес страдает.

Что делать в этой ситуации? Начинаются попытки тюнинга вакуума, какие-то попытки исправить ситуацию. Начинают пристреливать вакуумы. Вакуумы запускаются снова. Проблема не решается.

И в какой-то момент кто-то предлагает: «Давайте отключим вакуум. Есть такая крутилка в конфиге постгреса – autovacuum. Давайте выставим её в выключенное состояние и будем дальше работать».

И отключают, и вроде бы все хорошо, кажется, что приложение начало работать нормально: данные читаются, запросы выполняются быстро. Все хорошо у нас с данными. И клиенты вроде бы не страдают.
Но есть несколько моментов, которые в долгосрочной перспективе выйдут боком и сделают только хуже.
- Самый пр��стой и очевидный (для DBA) момент – это то, что статистика планировщика перестает собираться. Потому что автовакуум не только чистит таблицы, а еще и собирает статистику о распределении данных. И эта статистика используется планировщиком для того, чтобы строить оптимальные планы для запросов.
- Как только мы выключаем вакуум, таблицы и индексы перестают чиститься. И они начинают пухнуть. В них появляются мусорные строки. Таблицы и индексы начинают расти в размерах.
- Следствием этого является то, что область
shared buffers, где размещаются все оперативные данные для работы базы данных (это таблицы, индексы), начинается использоваться неэффективно. В ней находятся те самые мусорные строки. И чтобы запросу прочитать какие-то данные, постгресу нужно загружать страницу с мусорными данными и помещать ее в shared buffers. - И все это очень плохо с точки зрения общей производительности. Производительность запросов снижается. И в долгосрочной перспективе отключение вакуума – это гарантированно плохие спецэффекты в БД.

Все это можно быстро воспроизвести. Есть небольшой тест который я готовил для одной конференции. Он находится по вот этой ссылке: https://github.com/lesovsky/ConferenceStuff/tree/master/2016.highload
Что происходит в этом тесте? Мы запускаем pgbench на таблице для которой выключен автовакуум. Этот pgbench выполняет очень много обновлений в таблице. Наблюдая в течение относительно небольшого периода времени мы можем заметить падение производительности. Время выполнения запросов увеличивается, а количество транзакций в секунду падает. Т. е. на таком коротком тесте можно понаблюдать, как падает производительность при отключенном автовакууме.

И сейчас стоит рассказать про вакуум. Рассказать, как он работает и зачем он нужен. Многие администраторы, многие разработчики, с которыми я общаюсь, имеют довольно-таки расплывчатые представления об автовакууме. И даже люди, которые пишут патчи для Postgres, про автовакуум знают отрывочно (хотя спустя несколько лет это утверждение кажется мне довольно смелым, но оставим его). Поэтому этот доклад является некоторой попыткой сформировать у вас целостную картину про вакуум, лучше понять его и избавиться от стереотипов.

В качестве небольшого вступления нужно рассказать, что такое MVCC.
MVCC (Multi-Version Concurrency Control) – это "движок" базы данных, движок Postgres'а, т. е. это механизм который обеспечивает конкурентную работы нескольких клиентов с данными хранящимися в БД и как эта БД предоставляет данные клиентами.
- И этот движок очень производительный. Он обеспечивает очень хорошую конкурентность. Клиенты могут подключаться к базе данных и работать параллельно друг с другом.
- И обеспечивается хорошая производительность базы данных как на чтение так и на запись.
- При этом, читатели не блокируют читателей; писатели не блокируют читателей (хотя и есть некоторые исключительные ситуации).

Как это работает на практике? К базе данных подключаются клиенты. Открывая транзакции они начинают работать с данными. Они получают снимок данных (snapshot).
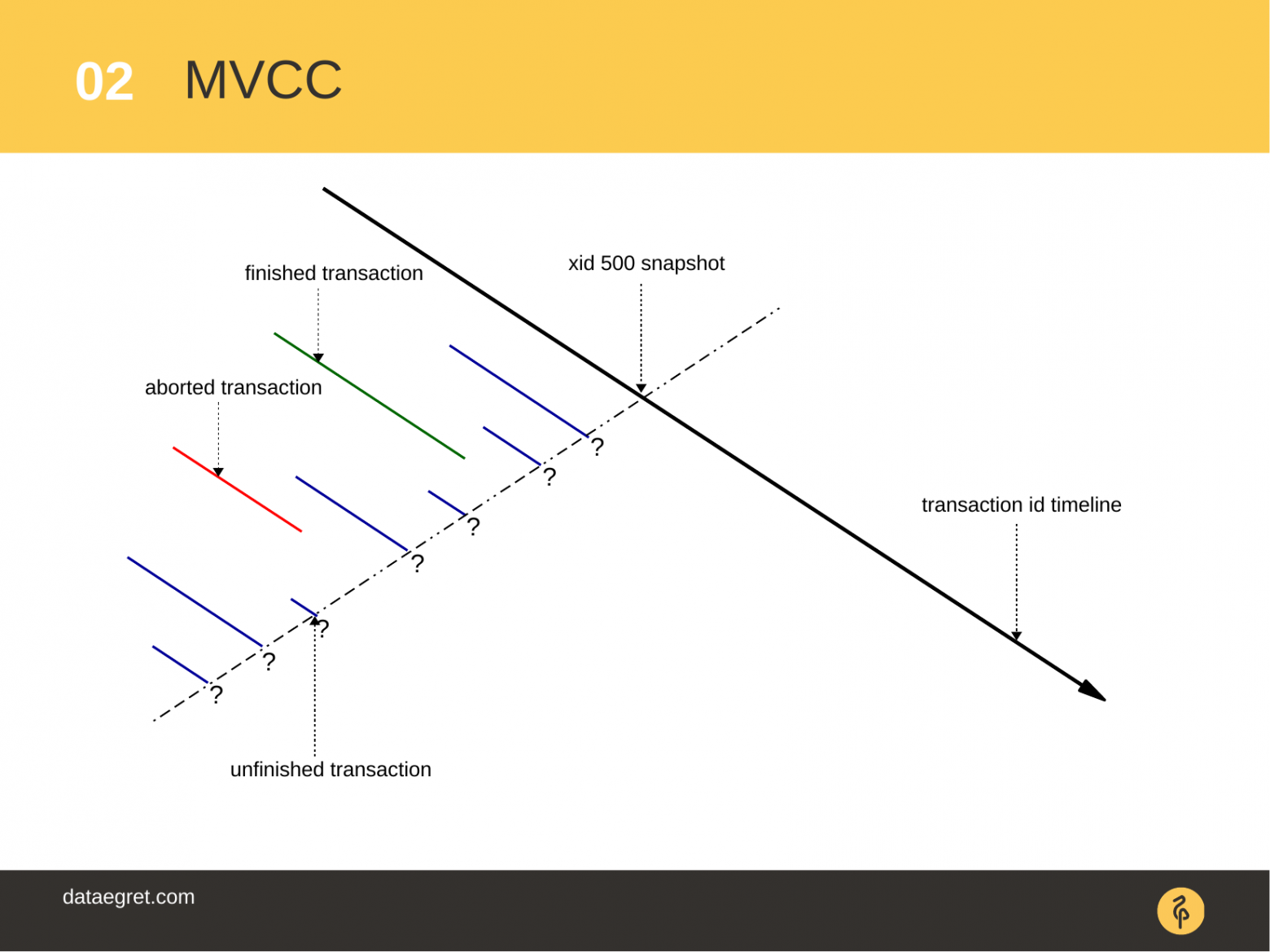
В этих данных они могут делать изменения данных: вставку новых записей, удаление существующих или обновления. И все эти изменения в рамках транзакции не видны другим транзакциям до тех пор, пока не произойдет подтверждение или откат транзакции (операции COMMIT и ROLLBACK).
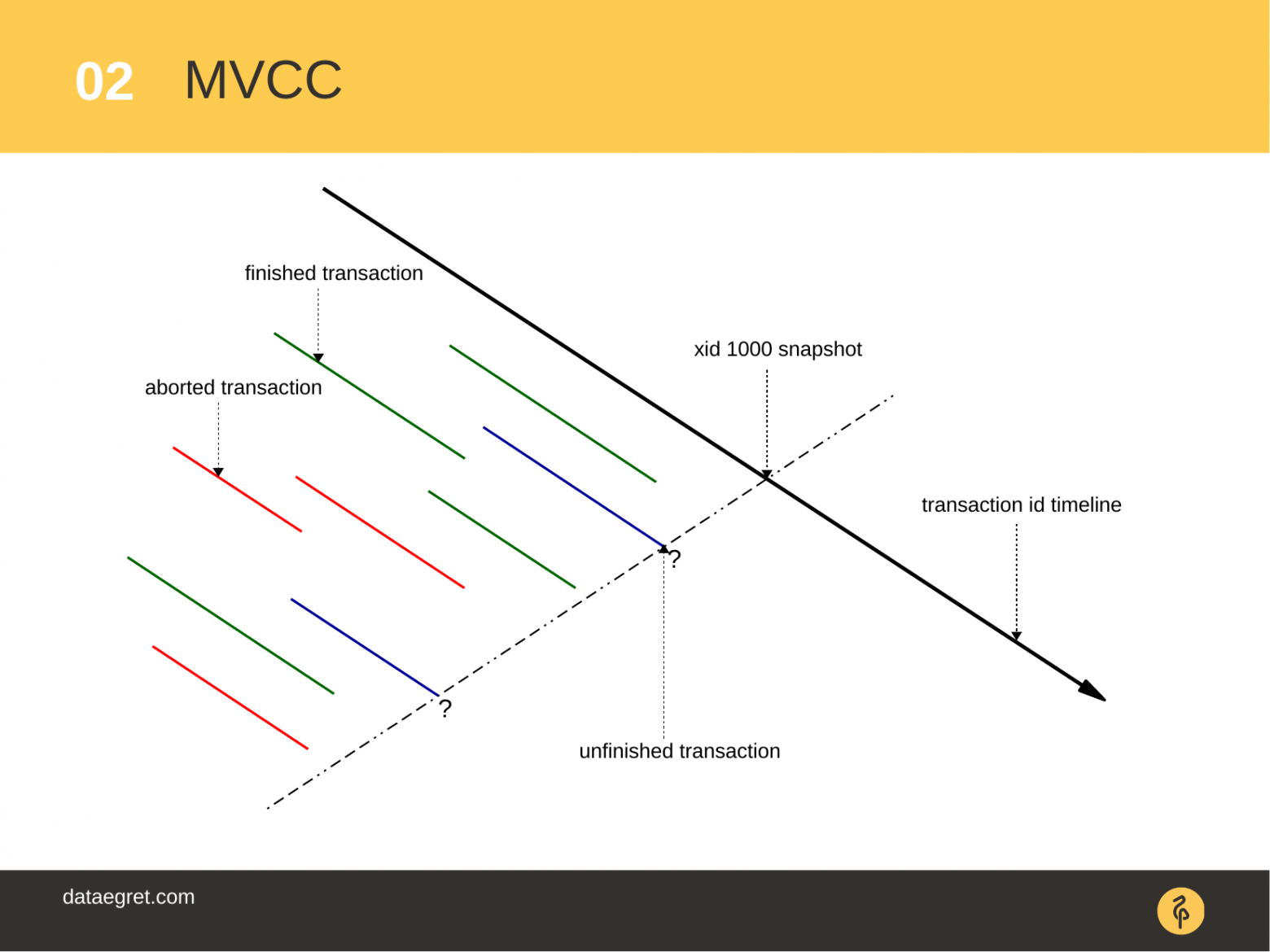
Как только транзакция выполняет операцию COMMIT, то ее изменения могут быть видны другим транзакциям, которые уже открываются или работают в данный момент. Кому интересна эта тема в больших подробностях, то можно поискать информацию по ключевым словам "уровни изоляции транзакции". Подробнее в теме: Изоляция транзакций в PostgreSQL.
И так это все работает. Счетчик транзакций растет, данные появляются. Какие-то данные могут стать неактуальными, потому что происходят операции «delete», «update». В результате чего появляются т.н. "мертвые" строки — dead tuples.

В строках есть две служебные отметки. Первая служебная отметка – это такая называемый xmin. Она показывает номер транзакции, которая произвела вставку строки. Т. е. когда мы делаем insert, то в этот xmin записывается значение транзакции.
Когда мы делаем обновление строки, то под капотом эта строка отмечается как удаленная после чего вставляется новая строка. И в удаленной строке в поле xmax отмечается номер той транзакции, которая произвела обновление.
И delete. Здесь все просто. Строка просто отмечается как удаленная — в поле xmax записывается транзакция которая произвела удаление, так строка становится удаленной.
За счет такой реализации конкурентной работы с данными в базе данных появляются устаревшие версии строк, их еще можно назвать "мертвые" или мусорные строки. Это те строки, у которых xmax младше всех работающих на текущий момент транзакций. Но мы не можем взять и сразу удалить устаревшие версии строк — параллельно могут быть открыты другие транзакции которые могут обратиться к этим данным, поэтому Postgres должен удерживать несколько версий одной и той же строки, на случай если он вдруг понадобятся другим транзакциям. Но транзакции не вечны и когда-нибудь заканчиваются и в какой-то момент времени устаревшие версии строк становятся ненужными, т.к. все транзакции которым бы эти строки могли понадобиться, уже завершились и БД может благополучно удалить устаревшие версии строк.
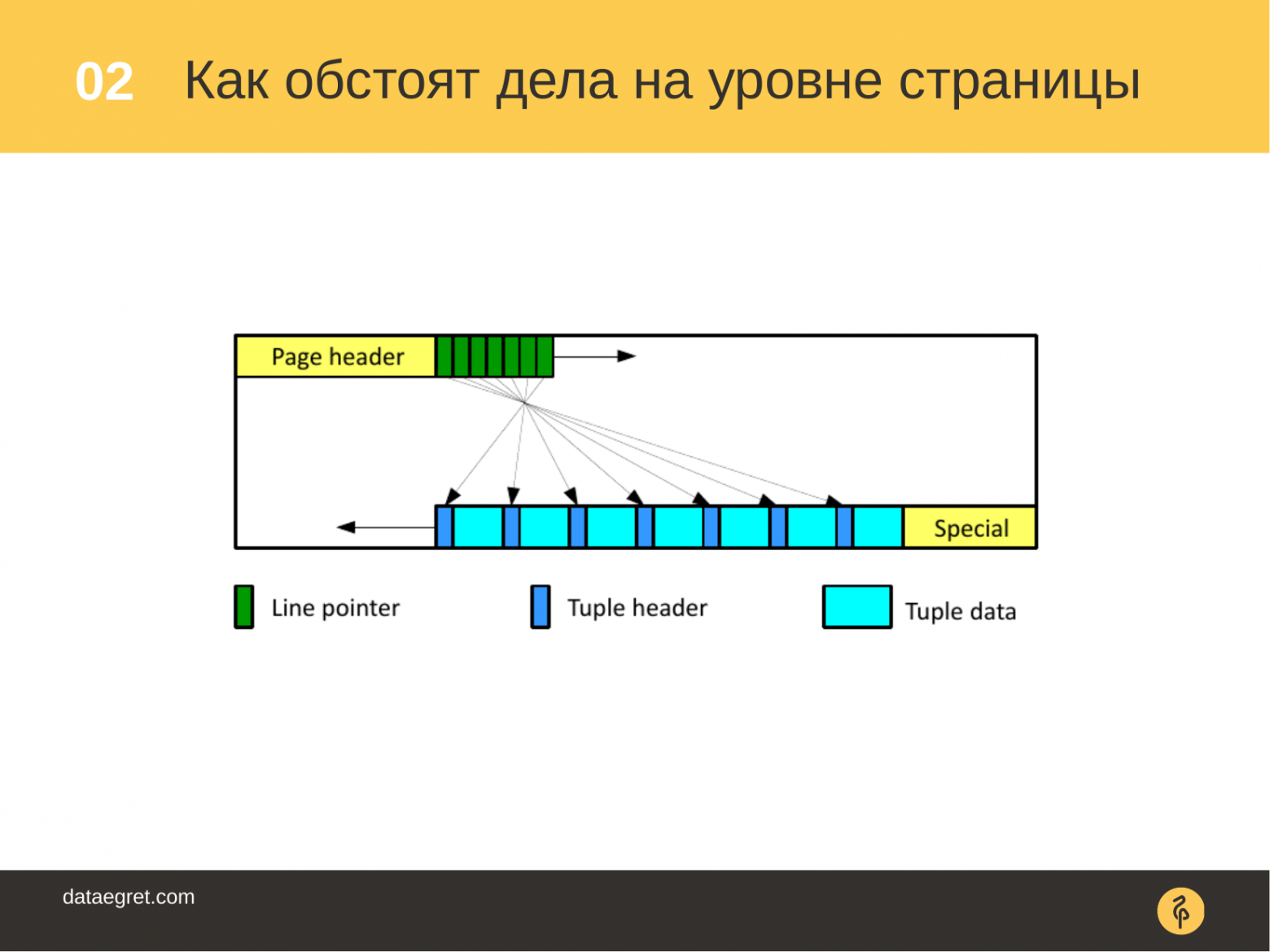
Тут мы приближаемся к теме вакуума, зачем же нужен вакуум? Вакуум нужен для того, чтобы чистить эти строки, которые уже не нужны ни одной транзакции и которые можно безопасно удалить и место в таблице, в индексе использовать повторно.
Выглядит это вот таким образом на уровне страниц. У нас есть некоторые указатели, по которым запросы определяют в какую область страницу нужно сходить и прочитать эти данные. Эти указатели указывают на сами строки.

Когда операции «delete», «update» работают со страницей, то обновленные/удаленные версии строк становятся устаревшими и их нужно будет потом вычистить из страницы. Их нужно будет потом почистить, потому что как уже было сказано ранее, они в какой-то момент станут не нужны ни одной из транзакции.
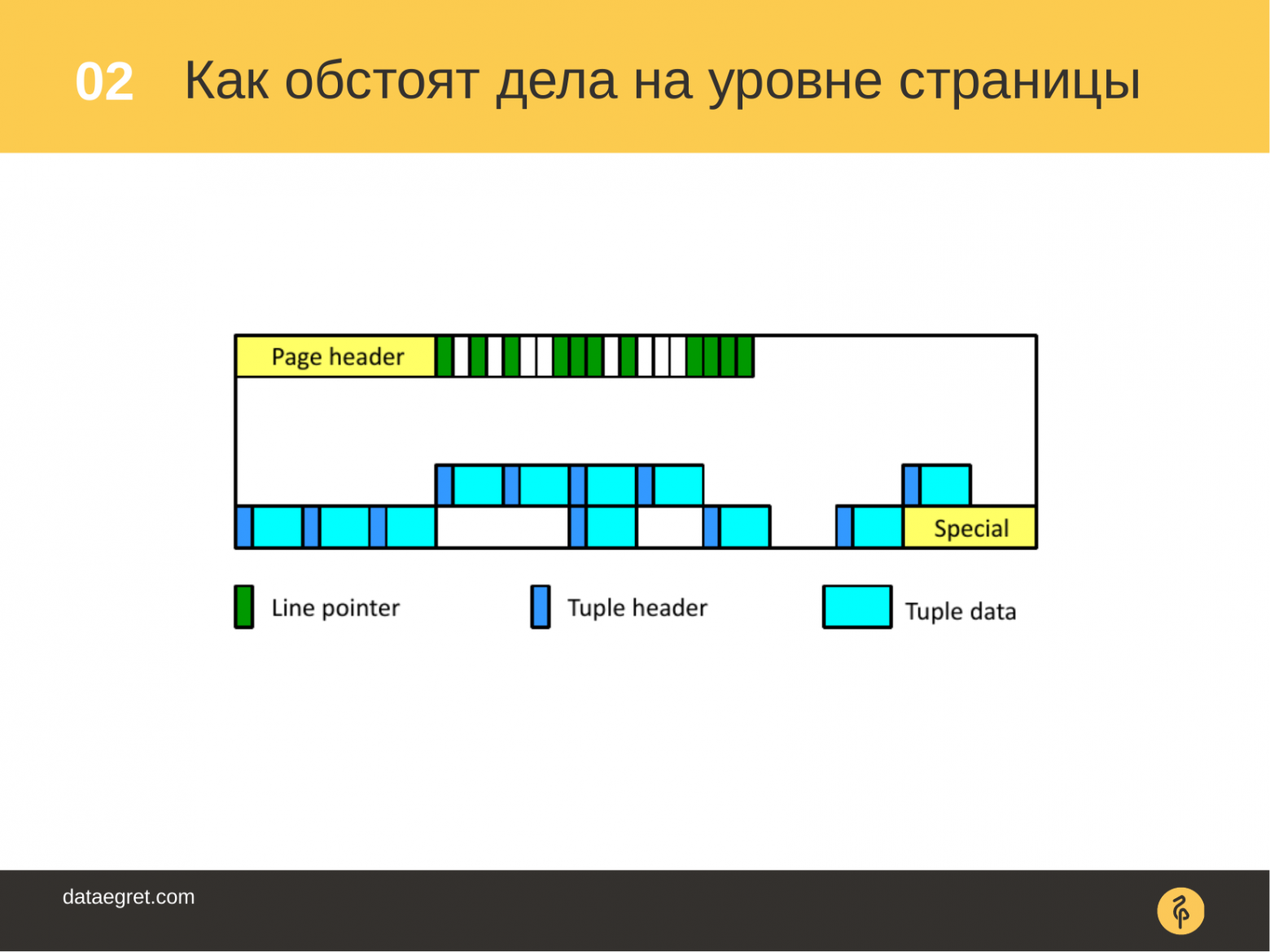
Приходит вакуум и освобождает указатели, делает их доступными для повторного использования. Ну и конечно вычищает устаревшие версии из строк.

В итоге в странице появляется новое место, которое можно использовать для дальнейшей записи, для дальнейших вставок, обновлений и т. п.

Таким образом:
- Вакуум нужен для того, чтобы сохранить общую производительность, чтобы держать таблицы, индексы в "тонусе", чтобы производительность не страдала, чтобы устаревшие версии строк своевременно вычищались.
- Чтобы область shared buffers использовалась эффективно и место в памяти не занимали страницы с большим количеством мусора.
- Чтобы не было
bloatэффекта, т.н. эффекта распухания — когда в таблице большой объем места просто не используется и мог бы без ущерба высвобожден.

И здесь мы уже подходим к технической стороне вакуума. Как обстоят дела с вакуумом?
- Во-первых, это фоновая задача.
- К��гда мы запускаем Postgres, запускается фоновая служба автовакуума. Она периодически запускает служебные рабочие процессы автовакуума. Количество этих процессов ограничено. Тут есть возможность регулировать количество воркеров, но при этом может случиться так, что в какой-то конкретный момент времени их будет работать максимальное, но ограниченное количество.
- Автовакуум запускается с некоторым интервалом. Этот интервал тоже регулируется. Мы можем на него влиять.
- И один из важных моментов – автовакуум собирает статистику о распределении данных для планировщика. Я уже об этом говорил. Планировщик на основе этой статистики старается генерировать оптимальные планы. При качественном изменении данных, с помощью автовакуума статистика для планировщика будет постоянно обновляться.

- Автовакуум запускается и ему нужно выбрать какую-то базу для обработки. Известно, что в одном кластере Postgres может быть очень много баз данных. И нельзя просто взять алфавитный список, и потом по нему идти гулять. Ну можно конечно, но у этой реализации будут минусы.
- Список баз сортируется по отметкам времени и автовакуум выбирает те базы данных, которые не обрабатывались дольше остальных.
- Либо приоритет отдается тем базам, где есть риск
оборачивания счетчика транзакций. Размер счетчика транзакции ограничен 32 битами, т.е его максимальное значение 4294967296. И когда в базе очень много записи, мы можем легко достичь этого числа и переполнить счетчик. В постгресе это считается аварийной ситуацией, не пытайтесь её повторить, в постгресе есть защитные механизмы при которых постгрес просто переходит в аварийный режим и прекращает обработку транзакций (все для того чтобы не повредить ваши драгоценные данные). Для этого есть т.н.to prevent wraparound vacuum, он как раз борется с этой проблемой. Но wraparound vacuum нам сейчас не интересен — о нем чуть позже. - И когда база данных выбрана, дальше нужно выбрать те таблицы, которые нуждаются в обработке. Тут тоже нельзя просто взять алфавитный список и начать как-то по нему идти. Выбор таблиц должен быть оптимальным и для выбора таблиц существует формула. Эта формула оперирует количеством мертвых строк в таблице. Как только количество мертвых строк в таблице превышает определенный порог, эта таблица помещается в список на обработку. Когда список на обработку уже построен, рабочий процесс вакуума начинает обработку таблиц.

- Настройки по умолчанию никуда не годятся. Вообще подход разработчиков к конфигу Postgres такой, что Postgres должен запуститься на любом оборудовании, на самом старом утюге, на самом старом Pentium, чтобы разработчик или пользователь мог начать пользоваться базой и как-то с ней экспериментировать, работать. И всегда эти настройки по-умолчанию приходится пересматривать. Очень часто, когда мы приходим к клиенту и проводим аудит его базы данных и конфигов, то видим, что настройки автовакуума стоят по умолчанию, либо они как-то неадекватно выставлены. А к этому нужно всегда внимательно относиться. Как впрочем и к любой другой конфигурации.
- Но Postgres не стоит на месте и развивается. От версии к версии в коде постгреса происходят разные улучшения которые затрагивают и автовакуум. Наиболее значительные изменения произошли в версии 9.6. Там много улучшений, поэтому если вы используете версии меньше 9.6 и имеете проблемы с вакуумом, то имеет смысл обновиться до версии 9.6. (На момент редактирования этого текста, можно смело обновляться на Postgres 12)

Вроде с вакуум теперь более-менее понятно. Теперь нужно его настроить адекватно оборудованию.

Во-первых, про вакуум всегда следует помнить, что его принцип обработки таблиц и индексов основан на т.н. оценках — cost-based vacuum. И за эти оценки отвечают несколько параметров.
В общих чертах, вакуум работает так: у него есть счетчик очков. Когда начинается обработка таблиц, он начинает считывать блоки датфайла этой таблицы (или индекса) — отсюда и нагрузка на диски от вакуума. За обработку каждой страницы начисляется определенное количество очков.
Как только счетчик очков дошел до предельного значения, рабочий процесс делает паузу на определенное количество времени. После этой паузы он сбрасывает счетчик в ноль и продолжает обрабатывать таблицу с того места где остановился.
За начисление очков при обработке страницы отвечают несколько параметров. Это vacuum_cost_page_hit, vacuum_cost_page_miss, vacuum_cost_page_dirty, коротко говоря hit, miss, dirty.
Hit – это количество очков, начисляемые за обработку страницы, которые находится в shared buffers, т. е. это самая дешевая обработка. Страница уже в памяти, постгресу не нужно читать её с диска или тем более синхронизировать её изменения на диск.
Miss – это если страницы нет в shared buffers и вроде как нужно прочитать её диска. Уже нужны ресурсы на ее чтение. Здесь уже начисляется больше очков, потому что страницу нужно прочитать с диска. Но может быть и так, что страницы нет в shared buffers, но она может быть в страничном кэше операционной системы (page cache) что в общем-то тоже память. Это тоже затрата ресурсов, но не такая затратная как чтение с диска.
Dirty – это количество очков, которые начисляются за обработку страниц, если страница содержит данные еще не синхронизированные с диском и страницу предварительно нужно списать на диск. Это более дорогая операция и соответственно стоит она дороже.
Таким образом в процессе обработки за каждую страницу начисляются очки. И они начисляются до значения параметра vacuum_cost_limit. Этот параметр как раз определяет предельное значение счетчика очков после которого рабочему процессу нужно остановиться и сделать паузу.
Величина паузы определяется параметром vacuum_cost_delay. Тут уже понятно, что мы с помощью cost limit можно влиять на размер пачки страниц за одну итерацию обработки. А с помощью cost delay можем влиять на интервал паузы.
Таким образом вакуум можно делать либо агрессивным, когда он обрабатывает много страниц и спит очень мало времени, либо делать вакуум ленивым, когда он наоборот обрабатывает мало страниц и подолгу спит. Всегда стоит помнить вот эту особенность вакуума при его настройке. Это очень важно.

Во-вторых, рабочих может быть много. По-умолчанию максимальное количество рабочих процессов, которые могут работать одновременно, всего три штуки.
- На современных серверах, когда количество процессорных ядер уже превышает за 32 и более, этот параметр следует увеличивать в большую сторону. И, на мой взгляд, оптимальным значением autovacuum_max_workers является примерно 10-15 % от общего количества процессорных ядер.
- Следующий параметр autovacuum_naptime. Он определяет, как часто нужно запускать рабочие процессы автовакуума. По умолчанию он равен 60 секунд. И это довольно большое значение. Всегда имеет смысл уменьшать его, мы на практике ставим параметр в 1 секунду. Опыт показывает, что это вполне подходящее значение которое не несет больших накладных расходов при уменьшении параметра. Внутри постгреса это небольшая функция, в которой тикает таймер и проверяется – не пора ли запустить вакуум. Т. е. это не ресурсоемкая операция. В общем, всегда имеет смысл уменьшать этот параметр.
- И другой важный момент – это то, что параметр vacuum_cost_limit, который влияет на размер пачки, он делится всегда между активными воркерами, которые запущены и выполняют обработку. Это тоже следует помнить, vacuum_cost_limit следует делить на всех воркеров.

В-третьих, вакуум должен выполнить оценку таблицы чтобы понять нужно ли ее вакуумить, для этого нужно знать сколько мертвых строк в таблице и сколько вообще в таблице строк. Для оценки используется простая формула, которая определяет порог для обработки на основе мертвых строк. И с помощью количества мертвых строк внутри таблицы она определяет – не пора запустить вакуум по таблице.
Работает формула таким образом. Берется общее количество строк в таблице с момента последнего выполнения вакуума и умножается на переменную autovacuum_vacuum_scale_factor. scale factor является процентным отношением. По-умолчанию значение scale_factor 0.2, т. е. 20 %.
К полученному числу добавляется значение autovacuum_vacuum_threshold. По-умолчанию – 50 строк. И получается тот самый порог, если мертвых строк в таблице больше чем полученное пороговое значение, значит нужно обработать таблицу.

Таким образом, по-умолчанию вакуум запускается только тогда когда мертвых строк в таблице более 20 %. На больших таблицах это будет очень много и можно там просто не дождаться вакуума, поэтому всегда имеет смысл autovacuum_vacuum_threshold уменьшать и делать, например, 1-2-5 %.

Но бывают ситуации, когда регулирование с помощью autovacuum_vacuum_scale_factor не приносит должного эффекта. Часто это проявляется на больших таблицах. Когда внутри таблицы миллионы строк, то даже 1 % — это очень большое количество строк. Тогда имеет смысл поставить autovacuum_vacuum_scale_factor в 0. И использовать только autovacuum_vacuum_threshold, т. е. явно указывать, что запустить вакуум нужно например, после одного миллиона строк. На практике получается примерно так autovacuum_vacuum_scale_factor используем в качестве общих дефолтов, и для индивидуальных настроек таблиц используем autovacuum_vacuum_threshold.

Также настройки автовакуума зависят от того, какое используется оборудование. Года 4-5 назад, когда HDD диски встречались практически повсеместно, настройкам вакуума нужно было уделять очень большое внимание. Потому что убить HDD диски и их производительность очень легко. Запускаем много воркеров, делаем агрессивный вакуум и все, мы получили просадку по производительности. И нужно уже, наоборот, делать вакуум более ленивым, тюнить его.
С SSD дисками ситуация стала лучше. И дефолтные настройки вакуум на SSD дисках всегда приходится пересматривать и делать его агрессивным. Это первая задача, которая возникает при аудите.
Но производительности SSD дисков тоже не всегда хватает. Бывают случаи, когда в сервер ставятся недорогие модели дисков. И на высокой конкурентности, когда много запросов (пишущих, читающих), их производительности не хватает. Поэтому всегда рекомендация – ставить серверные модели дисков, которые рассчитаны на высокую производительность.
А если вы используете NVMe устройства, то проблемы вакуума как таковой вообще нет, потому что это очень производительные устройства. И там вопрос I/O практически никогда не стоит. Там можно делать агрессивный автовакуум, делать много воркеров и вообще не беспокоиться. Единственное, что нужно настроить мониторинг и все-таки следить – нет ли каких-то проблем с автовакуумом в процессе работы базы. Поэтому чем лучше оборудование, тем проблем IO, связанных с вакуумом, становятся меньше.

Здесь пожалуй можно сделать предварительный итог и вывести какое-то общее правило. Мы регулируем vacuum_cost_delay и vacuum_cost_limit. Это интервал сна между обработкой и размером пачки. Т. е. всегда нужно отталкиваться от этого. Вы регулируете размер пачки и регулируете интервал паузы. Смотрите мониторинг. Смотрите – есть ли у вас проблемы или нет. Изменения нужно вносить итеративно и отслеживать как ведет себя БД.
Если есть проблемы, вы продолжаете дальше настройку. Если проблем не наблюдается, вы можете оставить такие настройки, как есть и жить спокойно.

vacuum_cost_delay = 0 vacuum_cost_page_hit = 0 vacuum_cost_page_miss = 5 vacuum_cost_page_dirty = 5 vacuum_cost_limit = 200 -- autovacuum_max_workers = 10 autovacuum_naptime = 1s autovacuum_vacuum_threshold = 50 autovacuum_analyze_threshold = 50 autovacuum_vacuum_scale_factor = 0.05 autovacuum_analyze_scale_factor = 0.05 autovacuum_vacuum_cost_delay = 5ms autovacuum_vacuum_cost_limit = -1
Здесь я привожу пример настройки для SSD дисков, которые мы используем на разных клиентах. В принципе, вы можете скачать эти слайды и потом эти настройки применить у себя, и отталкиваться уже от них.
Но здесь важное замечание: это настройки для SSD.

Иногда при настройке бывает необходимость установки индивидуальных параметров вакуума для таблицы или индексов. Это могут какие-то очень большие таблицы или наоборот маленькие таблицы, или кто-то решил "изобрести" очереди у себя в базе и в следствие особенностей работы очередей, на таких таблицах нужно часто запускать вакуум.
В таких случаях как раз хорошо подходят индивидуальные параметры для вакуума, которые задаются через storage parameters. Их можно определять для отдельных табличных пространств tablespaces, для таблиц и даже для индексов. Эта функциональность дает дополнительную гибкость при настройке вакуума, про которую стоит помнить.

Однако бывают ситуации, когда автовакуум вроде бы делает свою работу — чистит таблицы и индексы, но при этом не помогает, размер таблиц остается прежним и чтобы освободить занимаемое пространство приходится прибегать к дополнительным сторонним инструментам, которых нет в штатной поставке Postgres. Это, как правило, утилиты pgcompacttable и pg_repack.
Они позволяют уменьшить bloat таблиц и вернуть занятое место.
У этих двух инструментов разные методы работы, поэтому перед использованием рекомендуется ознакомиться с ними и посмотреть, как они работают. Однако же оба инструмента позволяют достичь одного результата – уменьшение размеров БД, таблиц или индексов (насколько это возможно). Поэтому очень рекомендую иметь эти утилиты в арсенале инструментов администратора.

Также следует затронуть и тему мониторинга и немного рассказать, как мониторить вакуум. Здесь довольно-таки все просто.
В Postgres есть всего два места, где можно смотреть, что происходит с вакуумом.
Первое место это pg_stat_activity. Как мне кажется, данные из этого представления (view) должны быть в любом мониторинге, это представление показывает текущую активность в базе данных, в том числе и активность вакуумов.
В этом представлении мы можем смотреть количество вакуумов, сколько их работает и текущее состояние, не заблокированы ли они, а также длительность их выполнения. Т. е. администратор всегда может через pg_stat_atctivity отследить работу (авто)вакуума.
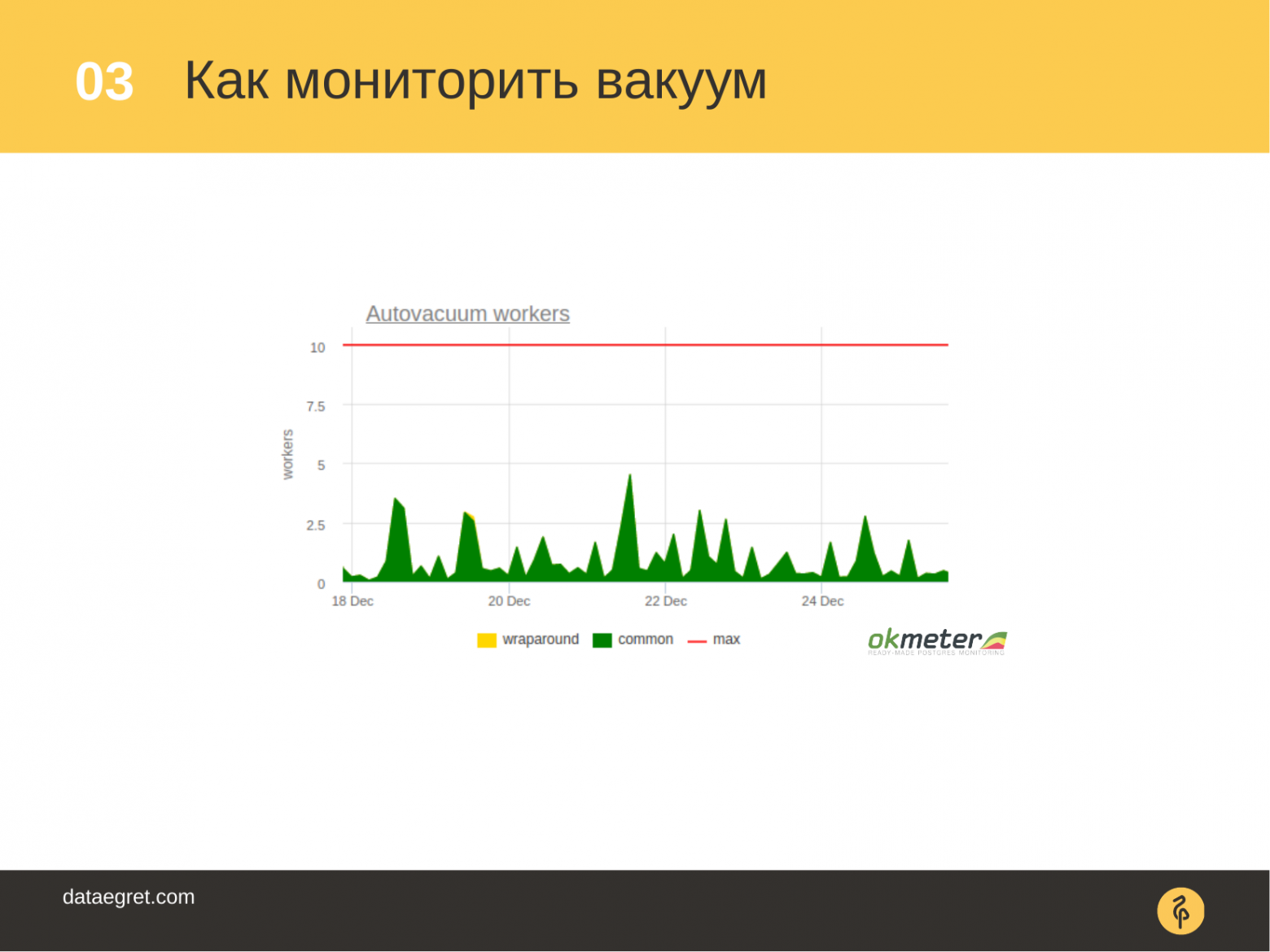
Вот так выглядит, например, классический график про вакуумы в системе мониторинга. У нас есть информация о количестве выполняющихся рабочих процессов, при этом с разделением по типу обычные вакуумы и prevent wraparound вакуумы. Дополнительно можно указать максимальный лимит (autovacuum_max_workers)– не достигли ли мы потолка по количеству воркеров.
С помощью такого графика можно легко анализировать – нет ли у нас проблем с вакуумами. Если количество рабочих процессов уткнулось в красную линию, значит, у нас есть много работы для вакуума, их запущено в недостаточном количестве или они недостаточно агрессивные и нужно делать донастройку или увеличивать количество воркеров. Также нужно смотреть на длительность их выполнения — вакуумы не должны работать десятками часов и тем более сутками. Всем рекомендую такой график иметь у себя в системе мониторинга.

Второе место, которое следует смотреть, это pg_stat_progress_vacuum представление которое появилось в версии 9.6. Представление показывает детальный прогресс выполнения вакуумов которые происходят здесь и сейчас.
По умолчанию это мягко говоря скучное представление, в которой отображаются сырые данные и на первый взгляд не совсем понятно, что эти цифры означают. Поэтому если использовать pg_stat_activity и некоторую информацию оттуда, плюс взять системные функции, которые показывают размеры таблиц, индексов, то можно неплохо облагородить содержимое pg_stat_progress_vacuum с помощью вот такого запроса.

https://github.com/lesovsky/uber-scripts/blob/master/postgresql/sql/vacuum_activity.sql
Запрос показывает, какой тип вакуума запущен, его длительность выполнения, на какой таблице он работает в данный момент и какой у него прогресс. В данном случае можно наблюдать, что у нас вакуум обрабатывает примерно 50 % таблицы и он еще будет работать примерно столько же. По самым приблизительным оценкам если он проработал 3 часа, то вероятно он будет работать еще 3 часа.
Вывод — с помощью этого представления можно оценивать прогресс выполнения вакуума: как долго он будет работать, как скоро он закончится. Очень полезное представление, рекомендую взять на вооружение.

Ну и в конце несколько важных моментов:
- Вакуум отключать нельзя. Это очень важный компонент СУБД.
- Настраивать вакуум не сложно. Вакуум является cost-based, при настройке отталкивайтесь от cost-параметров.
- И вакуум – это хорошо. Он позволяет держать базу в тонусе, чтобы она не увеличивалась в размерах, поэтому никогда не отключайте вакуум.
Вопросы
Здравствуйте! Спасибо за доклад! Меня зовут Андрей. В 9.6 обещали сильно оптимизировать вакуум именно на данных, которые не меняются. Но на боевом сервере все равно вижу постоянно, что партиции, данные которые не меняются, они постоянно вакуумируются. Можно этот момент как-то прояснить? Может быть, я что-то неправильно настроил?
Все верно. В 9.6 появилась freeze-карта, которая показывает замороженные блоки и позволяет избегать их обработки во время вакуума. Есть также в postgres’овом конфиге опции, которые влияют на срабатывание этого wraparound vacuum. Нужно просто их увеличить, чтобы этот вакуум срабатывал реже. Но, по идее, этот вакуум должен быть легковесным. Он пробегает по таблице, видит, что все блоки находятся в карте заморозки. Он выполняется быстрее и использует минимум ресурсов сервера, чем если бы он использовал их в 9.5 и ниже. Он становится более легковесным, но обработка страниц никуда не девается. Он просто читает заголовки страниц и видит, что строки заморожены и можно в эту таблицу не ходить.
Я правильно понимаю, что если вакуум агрессивный читает страницу и ее нет в buffer cache, он с диска делает read?
Нет, когда autovacuum worker запускается, то там есть buffer-менеджер. Он для автовакуума использует размер буфера 32 килобайта, по-моему. Это кольцевой буфер, через который строки прогоняются и в итоге кэш не вымывается.
Он делает чтение страниц с диска?
Да, конечно, если страницы нет в buffer cache, то если повезет она может быть в page cache, если нет и там, то нужно читать с диска. Страничный кэш при этом вымывается. Данные читаются с диска, появляются в page cache, затем в shared buffers но при этом сам шаредный буфер не вымывается.
Алексей, много полезного и интересного! Единственный момент, мы столкнулись с такой ситуацией. У нас есть хосты, на которых по сотням тысяч таблиц. И time там стоял дефолтный. По 5 или 1 минуты, не помню. У нас все сшибало капитально. Мы вынуждены были в свое время снизить его до раза в сутки, потому что у нас каждые 5 минут ресурсы упирались под 100 % и по CPU, и по storage. При этом диски у нас быстрые.
Здесь вариант – это увеличивать количество воркеров. Много таблиц – много воркеров. Но если вы упираетесь в количество CPU, нужно как-то расширять мощности сервера. И есть такой интересный момент – какая схема энергосбережения процессором используется? Очень часто сервера БД работают на Ubuntu. И у Ubuntu дефолтная настройка для схемы энергосбережения процессора powersave. Т. е., условно говоря, в сервере стоит процессор 3,4 GHz, а на тактовой частоте он работает – 1,2. И это очень плохо. Мы в таких случаях делаем performance схему энергосбережения. И он работает на максимальной частоте. Он, конечно, греет атмосферу, экологи скажу что все плохо, но, по крайней мере, запросы начинают быстрее выполняться. И задачи, связанные с вычислением на процессорах, тоже начинают работать быстрее.
В вашем случае нужно посмотреть схемы энергосбережения и попробовать увеличивать количество воркеров через увеличение ядер. Если диски не справляются, то это тоже увеличение дисков, т. е. нельзя получить какую-то серебряную пулю, чтобы диски не просаживались и вакуум держал все время в тонусе. Либо мы какой-то bloat все-таки допускаем в базе и позволяем, чтобы вакуум работал медленнее и при этом диски не страдали. Либо делаем апгрейд железа и позволяем вакууму работать более агрессивно.
Спасибо за доклад! Предположим, что у нас есть две открытые транзакции. В одной из транзакций мы изменяем данные: удаляем или обновляем. Автоматически спустя какое-то количество autovacuum_vacuum_scale_factor или autovacuum_vacuum_threshold начинает выполняться. Как при этом записи он не может освободить, потому что открыта вторая транзакция, которая снапшот, которая видит еще эти строки. И в итоге получается, что naptime секунд автовакуум портит статистику, если выполняется без analyze. Причем в текущей версии Postgres в каждой статистике добавляется еще количество мертвых строк. Это отражается в pg_class reltuples
Да.
С каждым вакуумом число увеличивается. И это влияет на планы запросов.
Да.
Для того чтобы не добавлялось к этому значению количество dead tuples в community я нашел патч, который сделали разработчики 2ndQuadrant. Протестировал – работает. Но тем не менее каждый вакуум без analyze увеличивает количество reltuples и портит статистику.
Да, портит статистику. Основная идея – это избегать долгих транзакций. Уменьшить их длину жизни. Следить за тем, чтобы они не были в статусе «idle in transactions», чтобы база данных не ожидала, когда придет следующая команда от клиента. Не делать в транзакции какие-то обращения к внешним ресурсам. Вот это основная рекомендация, т. е. уменьшить время жизни транзакции и следить, чтобы они не тупили.
Это понятно, но за баг это не считается?
Да, это такое поведение MVCC и самого вакуума. Если эти строки потенциально могут понадобиться каким-то другим транзакциям, то чистить их нельзя.
Зачем каждый раз увеличивать количество reltuples?
Сложный вопрос. Сходу не отвечу.
(другой спикер) Я могу сказать. Не надо думать, что это вакуум увеличивает. Увеличивает ваша транзакция: update, insert и т. д. Вакуум это всего лишь приведение статистики в порядок: то, что реально есть в таблице. Он не увеличивает количество tuples. Он может только уменьшить.
Да, т. е. за счет открытой транзакции появляются новые записи, которые вставляются другими транзакциями. И изменения незаконченной транзакции добавляются к этой статистике. И reltuples обновляется вакуумом. Когда вакуум закончился по таблице, он посчитал количество строк, с учетом всех транзакций висящих, и это значение зафиксировал, записал. Т. е. он не может какую-то аналитику там сделать – понадобятся или не понадобятся. Он просто в тупую их фиксирует.
Вы упоминали о том, что вакуум напрямую связан с планировщиком. А через какие механизмы автовакуум взаимодействует или оказывает какое-либо влияние на планировщика запросов?
В postgres’овом коде есть отдельные функции, которые собирают статистику о распределении данных внутри таблиц. Это отдельная подсистема автовакуума. Он читает sample данных ограниченного размера из таблицы. И на основе ее строит распределение по данным. И эту информацию он сохраняет в системном каталоге pg_statistic или в системном представлении pg_stats. И когда планировщик строит планы запросов, он читает информацию из этого каталога. И на ее основе строит планы. И дальше уже выбирает оптимальный.

