За последние тридцать лет компьютеры настолько стали популярны, что успели изменить многие процессы в жизни человека и соответственно общества. С каждым годом, согласно закону Мура, они приобретают все больше вычислительных способностей, что позволяет им решать все более сложные задачи. Уже сегодня компьютеры столкнулись с рядом ограничений, которые не позволяют нам решать задачи из фильмов про будущее. Так ли будет и дальше, есть ли предел у современной архитектуры и что нам делать, если такой стремительный рост в дальнейшем невозможен?

На изображении отладочная плата с расположенными чипами Loihi.
Эта статья является вступлением для статьи Neuromorphic inspired computing и описывает проблематику вопроса, решения предлагаются во второй статье.
“Бутылочное горлышко” архитектуры фон Неймана.
Все классические компьютеры обладают так называемой архитектурой фон Неймана.
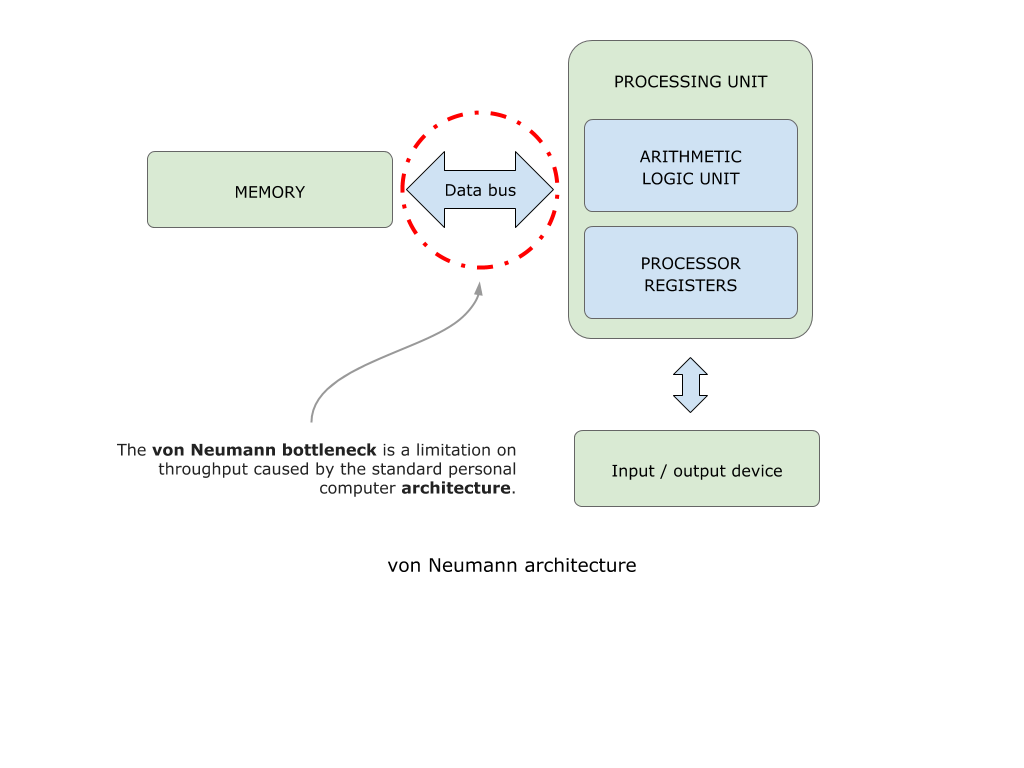
Рис. 1. The decline of von Neumanns architecture
Недостатком такой архитектуры является тот факт, что данные из области памяти цикл за циклом должны передаваться в область вычислительного юнита и обратно. Интерфейс, связывающий вычислительный юнит и память компьютера, ограничен в своей пропускной способности. Даже тот факт, что современные процессоры имеют несколько уровней кэша непосредственно в вычислительном юните, не решает проблему. Данный подход усугубляется необходимостью аккумулировать и структурировать данные для полного заполнения буфера вычисляемых операций. Можно привести метафору с поездом: пока все пассажиры не займут именно свои места в поезде, поезд никуда не поедет.
Согласно закону Мура, количество транзисторов удваивается примерно каждые два года при уменьшении стоимости их производства. Реализуется этот факт посредством уменьшения размера транзистора. Уменьшение размеров транзистора приводит нас к еще одному ограничению: их размеры обусловлены физическими свойствами материалов из которых они производятся.
Реалии представляются таким образом, что этот закон начинает испытывать давление со стороны “законов физики микромира”.
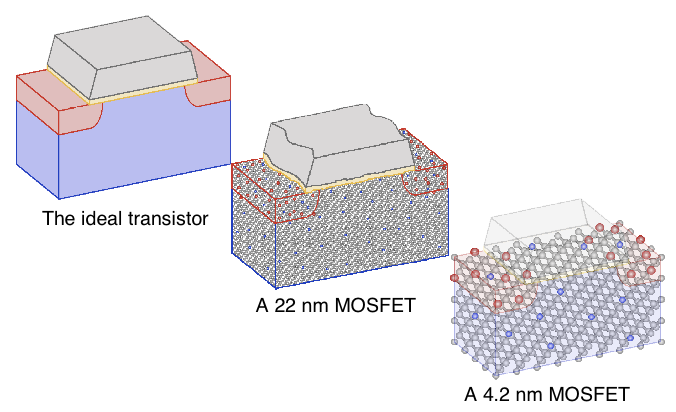
Рис. 2. Уменьшение размеров транзистора приводит к ошибкам в его производстве
Тут мы сталкиваемся сразу с несколькими сложностями:
Задумывались ли вы, как производят младшие модели процессоров и чипов для видеокарт? Вы наверное подумаете, что есть специально выделенные команды, которые разрабатывают каждый год новый упрощенный чип. На самом деле процесс выглядит по-другому. Компания разрабатывает один максимально мощный чип. Его устройство выглядит, как некая повторяющаяся архитектура. Обратите внимание на то, что практически все элементы дублируются, как и в авиации.
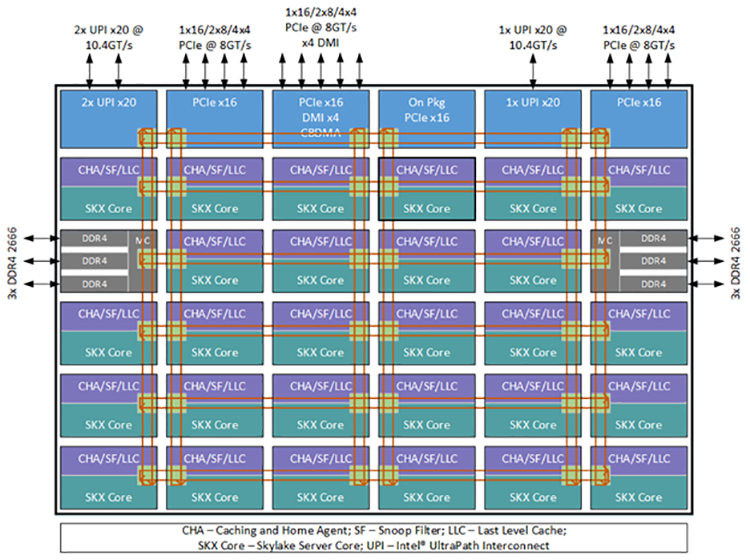
Рис. 3. Блок схема процессора Xeon
Это сделано для того, чтоб в том случае, если в каком-то блоке выйдет из строя большое количество транзисторов из-за брака во время производства, этот блок можно было отключить, а процессор целиком остался в рабочем состоянии. Как вы понимаете, производство процессоров очень дорогое, и одна из причин этого большой процент брака. Процент брака кристаллов для 28-ядерных процессоров Intel Xeon составляет до 65 %. Если у конечного процессора не работает один из блоков памяти или одно из ядер не проходит TDP тест, его отключают, а процессор упаковывают в коробку “младшей модели”.
Подход хороший, но он требует отключения очень больших блоков: в случае отказа нескольких транзисторов, которых в одном ядре может быть семьсот миллионов. То есть отказ 0.000000001% транзисторов приводит к потере 10% и более производительности устройства.
Если предположить, что мы можем создавать блоки, основанные на ста транзисторах при количестве этих самых блоков более миллиона мы бы получили значительный прирост отказоустойчивости в чипе. Это значит, что при выходе из строя небольшого количества транзисторов мы бы теряли очень маленький процент блоков от их общего числа. Этот подход сильно бы удешевил стоимость производства, и топовый чип стоил бы уже не, как малолитражный автомобиль, а как хорошая рубашка.
В современном мире, когда мобильный телефон обладает вычислительными способностями компьютера пятилетней давности и при этом работает от аккумулятора, нам кажется, что мы почти достигли предела в уменьшении потребления энергии компьютерами. Но, если мы сравним вычислительные способности суперкомпьютера IBM Summit, его размеры и потребляемые им объемы энергии с мозгом мыши, окажется, что он неимоверно большой и очень неэффективный.

Рис 4. IBM Power System AC922, IBM POWER9 22C 3.07GHz, NVIDIA Volta GV100, Dual-rail Mellanox
EDR InfiniBand, 2.41 million cores, 148.6 petaflops
Пиковая потребляемая мощность: 13 000 000 W
Размеры: 4,608 nodes * 0.2 m^3 = 920 m^3
Мозг мыши способен обрабатывать куда более сложные задачи при потреблении всего 1-5 ватт.
Тут хочется сказать больше об алгоритмах, нежели об архитектуре, хотя в данном контексте алгоритмы продиктованы архитектурой. Современный компьютер хорошо справляется с дискретными данными, когда есть, пускай и большое количество, но все же порционных, конечных, желательно целочисленных данных, тут он может себя проявить очень хорошо. Но вот, когда речь заходит о последовательностях, непрерывности, бесконечно малых или бесконечно больших значениях, тут мы пытаемся найти некое приближение. В результате мы интерпретируем наши данные в последовательность дискретных кадров, дробим, разделяем и обрабатываем каждый фрейм как нечто статическое и конечное.
Да, сейчас существуют различные подходы bi-directional soft attention (см. BERT) для того, чтобы связывать эти самые кадры в работе с языковыми моделями. Также современные подходы машинного обучения лишены возможности обучаться непосредственно в процессе решения поставленной задачи. Это все еще две различные задачи.
Возвращаясь к архитектуре фон Неймана, мы видим, что весь поток данных проходит через некий вычислительный центр, то есть по сути еще одно узкое горлышко. Количество ядер в современных чипах растет, но вслед за этим возникает и новая проблема: сперва данные нужно распараллелить, а после синхронизировать результаты. То есть, если у вас множество независимых входных сигналов и они не связаны между собой ни во времени, ни в контексте, множество ядер процессоров и ядер видеокарт хорошо справляются с этой задачей. Но в том случае, если у вас большой входной сигнал, то задача параллелизма вычислений, синхронизации результатов может занять большую часть этих самых вычислений.
Оригинал статьи
В следующей статье я рассказываю как решают все перечисленные сложности по средствам Neuromorphic архитектуры.
На изображении отладочная плата с расположенными чипами Loihi.
Дисклеймер
Компьютер фон Неймана все так же будет обрабатывать задачи, связанные с реляционными базами данных (про BigData не уверен), численными методами, интернетом и тд. В общем он так и будет заниматься всем тем, для чего он был создан, но уже не будет такого быстрого прироста вычислительных способностей, а для решения задач обработки сигналов “реального мира” будет использоваться другой архитектурный подход. Оба архитектурных подхода будут использоваться на одной печатной плате, а со временем и в одном чипе.
Эта статья является вступлением для статьи Neuromorphic inspired computing и описывает проблематику вопроса, решения предлагаются во второй статье.
Классическая архитектура фон Неймана
“Бутылочное горлышко” архитектуры фон Неймана.
Все классические компьютеры обладают так называемой архитектурой фон Неймана.
Рис. 1. The decline of von Neumanns architecture
Недостатком такой архитектуры является тот факт, что данные из области памяти цикл за циклом должны передаваться в область вычислительного юнита и обратно. Интерфейс, связывающий вычислительный юнит и память компьютера, ограничен в своей пропускной способности. Даже тот факт, что современные процессоры имеют несколько уровней кэша непосредственно в вычислительном юните, не решает проблему. Данный подход усугубляется необходимостью аккумулировать и структурировать данные для полного заполнения буфера вычисляемых операций. Можно привести метафору с поездом: пока все пассажиры не займут именно свои места в поезде, поезд никуда не поедет.
Физические ограничения материалов
Согласно закону Мура, количество транзисторов удваивается примерно каждые два года при уменьшении стоимости их производства. Реализуется этот факт посредством уменьшения размера транзистора. Уменьшение размеров транзистора приводит нас к еще одному ограничению: их размеры обусловлены физическими свойствами материалов из которых они производятся.
Реалии представляются таким образом, что этот закон начинает испытывать давление со стороны “законов физики микромира”.
Рис. 2. Уменьшение размеров транзистора приводит к ошибкам в его производстве
Тут мы сталкиваемся сразу с несколькими сложностями:
- Во-первых, при уменьшении размеров электрический разряд начинает “пробивать” затвор и затвор перестает выполнять свою роль.
- Во-вторых, усложняется задача отведения тепла от такого транзистора.
- В-третьих, при уменьшении размера транзистора брак при их производстве возрастает, так как меньшее количество вещества на молекулярном уровне формирует сам транзистор.
Отказоустойчивость и брак в производстве
Задумывались ли вы, как производят младшие модели процессоров и чипов для видеокарт? Вы наверное подумаете, что есть специально выделенные команды, которые разрабатывают каждый год новый упрощенный чип. На самом деле процесс выглядит по-другому. Компания разрабатывает один максимально мощный чип. Его устройство выглядит, как некая повторяющаяся архитектура. Обратите внимание на то, что практически все элементы дублируются, как и в авиации.
Рис. 3. Блок схема процессора Xeon
Это сделано для того, чтоб в том случае, если в каком-то блоке выйдет из строя большое количество транзисторов из-за брака во время производства, этот блок можно было отключить, а процессор целиком остался в рабочем состоянии. Как вы понимаете, производство процессоров очень дорогое, и одна из причин этого большой процент брака. Процент брака кристаллов для 28-ядерных процессоров Intel Xeon составляет до 65 %. Если у конечного процессора не работает один из блоков памяти или одно из ядер не проходит TDP тест, его отключают, а процессор упаковывают в коробку “младшей модели”.
Подход хороший, но он требует отключения очень больших блоков: в случае отказа нескольких транзисторов, которых в одном ядре может быть семьсот миллионов. То есть отказ 0.000000001% транзисторов приводит к потере 10% и более производительности устройства.
Если предположить, что мы можем создавать блоки, основанные на ста транзисторах при количестве этих самых блоков более миллиона мы бы получили значительный прирост отказоустойчивости в чипе. Это значит, что при выходе из строя небольшого количества транзисторов мы бы теряли очень маленький процент блоков от их общего числа. Этот подход сильно бы удешевил стоимость производства, и топовый чип стоил бы уже не, как малолитражный автомобиль, а как хорошая рубашка.
Потребление электроэнергии и размер суперкомпьютеров
В современном мире, когда мобильный телефон обладает вычислительными способностями компьютера пятилетней давности и при этом работает от аккумулятора, нам кажется, что мы почти достигли предела в уменьшении потребления энергии компьютерами. Но, если мы сравним вычислительные способности суперкомпьютера IBM Summit, его размеры и потребляемые им объемы энергии с мозгом мыши, окажется, что он неимоверно большой и очень неэффективный.
Рис 4. IBM Power System AC922, IBM POWER9 22C 3.07GHz, NVIDIA Volta GV100, Dual-rail Mellanox
EDR InfiniBand, 2.41 million cores, 148.6 petaflops
Пиковая потребляемая мощность: 13 000 000 W
Размеры: 4,608 nodes * 0.2 m^3 = 920 m^3
Мозг мыши способен обрабатывать куда более сложные задачи при потреблении всего 1-5 ватт.
Online learning and continuous-flow
Тут хочется сказать больше об алгоритмах, нежели об архитектуре, хотя в данном контексте алгоритмы продиктованы архитектурой. Современный компьютер хорошо справляется с дискретными данными, когда есть, пускай и большое количество, но все же порционных, конечных, желательно целочисленных данных, тут он может себя проявить очень хорошо. Но вот, когда речь заходит о последовательностях, непрерывности, бесконечно малых или бесконечно больших значениях, тут мы пытаемся найти некое приближение. В результате мы интерпретируем наши данные в последовательность дискретных кадров, дробим, разделяем и обрабатываем каждый фрейм как нечто статическое и конечное.
Да, сейчас существуют различные подходы bi-directional soft attention (см. BERT) для того, чтобы связывать эти самые кадры в работе с языковыми моделями. Также современные подходы машинного обучения лишены возможности обучаться непосредственно в процессе решения поставленной задачи. Это все еще две различные задачи.
Параллелизм и масштабируемость
Возвращаясь к архитектуре фон Неймана, мы видим, что весь поток данных проходит через некий вычислительный центр, то есть по сути еще одно узкое горлышко. Количество ядер в современных чипах растет, но вслед за этим возникает и новая проблема: сперва данные нужно распараллелить, а после синхронизировать результаты. То есть, если у вас множество независимых входных сигналов и они не связаны между собой ни во времени, ни в контексте, множество ядер процессоров и ядер видеокарт хорошо справляются с этой задачей. Но в том случае, если у вас большой входной сигнал, то задача параллелизма вычислений, синхронизации результатов может занять большую часть этих самых вычислений.
Оригинал статьи
В следующей статье я рассказываю как решают все перечисленные сложности по средствам Neuromorphic архитектуры.

