
Эта статья описывает технические детали проблем, из-за которых Slack упал 12 мая 2020 года. Больше о процессе реагирования на тот инцидент см. хронологию Райана Каткова «Обе руки на пульте».
12 мая 2020 года у Slack произошел первый значительный сбой за долгое время. Вскоре мы опубликовали краткое изложение инцидента, но это довольно интересная история, поэтому хотели бы подробнее остановиться на технических деталях.
Пользователи заметили даунтайм в 16:45 по тихоокеанскому времени, но на самом деле история началась около 8:30 утра. Команда разработки по надёжности БД (Database Reliability Engineering Team) получила предупреждение о значительном увеличении нагрузки на часть инфраструктуры. В то же время команда по трафику (Traffic Team) получила предупреждения, что мы не выполняем некоторые запросы API.
Повышенная нагрузка на БД была вызвана деплоем новой конфигурации, которая вызвала давнюю ошибку производительности. Изменение было быстро определено и откатано — это был флаг функции, выполнявшей постепенный деплой, так что проблему решили быстро. Инцидент немного повлиял на клиентов, но это продолжалось всего три минуты, и большинство пользователей всё ещё могли успешно отправлять сообщения в течение этого короткого утреннего глюка.
Одним из последствий инцидента стало значительное расширение нашего основного уровня веб-приложений. Наш генеральный директор Стюарт Баттерфилд писал о некотором влиянии карантина и самоизоляции на использование Slack. В результате пандемии мы запустили значительно больше инстансов на уровне веб-приложений, чем в далёком феврале этого года. Мы быстро масштабируемся, когда воркеры нагружаются, как это произошло здесь — но воркеры гораздо дольше ждали завершения некоторых запросов к БД, что вызвало более высокую загрузку. Во время инцидента мы увеличили количество инстансов на 75%, что привело к максимальному количеству хостов веб-приложений, которые мы когда-либо запускали до сегодняшнего дня.
Казалось, что всё прекрасно работает в течение следующих восьми часов — пока не выскочило предупреждение о необычно большом количестве ошибок HTTP 503. Мы запустили новый канал реагирования на инциденты, а дежурный инженер по веб-приложениям вручную увеличил парк веб-приложений в качестве первоначального смягчения последствий. Как ни странно, это нисколько не помогло. Мы очень быстро заметили, что часть инстансов веб-приложений находится под большой нагрузкой, в то время как остальные — нет. Начались многочисленные исследования, изучающие и производительность веб-приложений, и балансировку нагрузки. Через несколько минут мы определили проблему.
За балансировщиком нагрузки на 4-м уровне стоит набор инстансов HAProxy для распределения запросов на уровень веб-приложений. Мы используем Consul для обнаружения служб и consul-template для рендеринга списков здоровых бэкендов веб-приложений, к которым HAProxy должен направлять запросы.
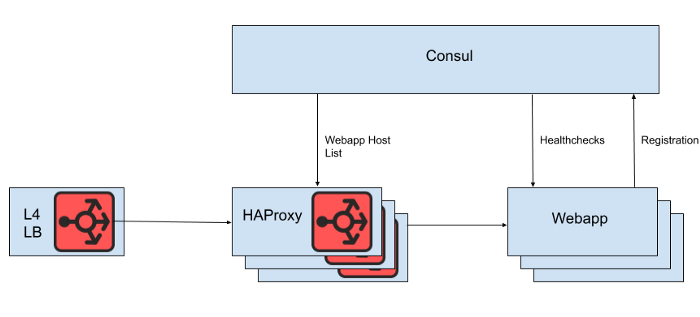
Рис. 1. Высокоуровневое представление архитектуры балансировки нагрузки Slack
Однако мы не рендерим список хостов веб-приложений прямо из конфигурационного файла HAProxy, потому что обновление списка в таком случае требует перезагрузки HAProxy. Процесс перезагрузки HAProxy включает в себя создание совершенно нового процесса, сохраняя при этом старый, пока он не закончит работу с текущими запросами. Очень частые перезагрузки могут привести к слишком большому количеству запущенных процессов HAProxy и низкой производительности. Это ограничение находится в противоречии с целью автоматического масштабирования уровня веб-приложений, которая заключается в том, чтобы как можно быстрее вводить в эксплуатацию новые инстансы. Поэтому мы используем HAProxy Runtime API для управления состоянием сервера HAProxy без перезагрузки каждый раз, когда сервер веб-уровня входит в эксплуатацию или выходит из неё. Стоит отметить, что HAProxy может интегрироваться с DNS-интерфейсом Consul, но это добавляет лаг из-за TTL DNS, ограничивает возможность использования тегов Consul, а управление очень большими ответами DNS часто приводит к болезненным пограничным ситуациям и ошибкам.
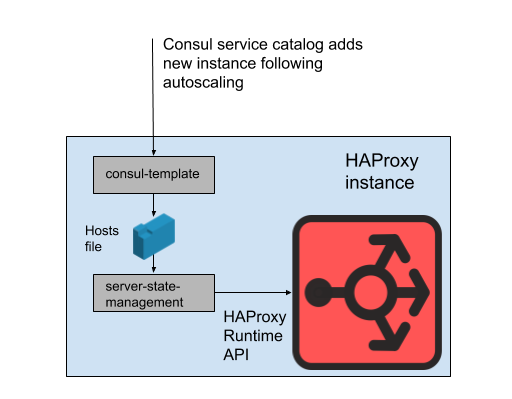
Рис. 2. Как набор бэкендов веб-приложений управляется на одном сервере Slack HAProxy
В нашем состоянии HAProxy мы определяем шаблоны серверов HAProxy. Фактически, это «слоты», которые могут занимать бэкенды веб-приложений. Когда выкатывается инстанс нового веб-приложения или старый начинает отказывать, обновляется каталог сервисов Consul. Consul-template выводит новую версию списка хостов, а отдельная программа haproxy-server-state-management, разработанная в Slack, считывает этот список хостов и использует HAProxy Runtime API для обновления состояния HAProxy.
Мы запускаем M параллельных пулов инстансов HAProxy и веб-приложений, каждый пул в отдельной зоне доступности AWS. HAProxy сконфигурирован с N «слотами» для бэкендов веб-приложений в каждой зоне доступности (AZ), что даёт в общей сложности N*M бэкендов, которые могут быть направлены на все AZ. Несколько месяцев назад это количество было более чем достаточным — мы никогда не запускали ничего даже близко к такому количеству инстансов нашего уровня веб-приложений. Однако после утреннего инцидента с базой данных мы запустили чуть больше, чем N*M инстансов веб-приложений. Если представить слоты HAProxy как гигантскую игру в стулья, то некоторые из этих инстансов webapp остались без места. Это не было проблемой — у нас более чем достаточно возможностей для обслуживания.

Рис. 3. «Слоты» в процессе HAProxy с некоторыми избыточными экземплярами веб-приложений, которые не получают трафик
Однако в течение дня возникла проблема. Выявился баг в программе, которая синхронизировала список хостов, сгенерированный consul-template, с состоянием сервера HAProxy. Программа всегда пыталась найти слот для новых инстансов webapp, прежде чем освободить слоты, занятые старыми инстансами webapp, которые больше не работают. Эта программа начала выдавать ошибки и рано завершать работу, потому что не могла найти ни одного пустого слота, а это означало, что запущенные инстансы HAProxy не обновляли своё состояние. В течение дня группа автомасштабирования webapp увеличивалась и уменьшалась, а список бэкендов в состоянии HAProxy всё больше устаревал.
В 16:45 большинство инстансов HAProxy были способны отправлять запросы только к набору бэкендов, доступных утром, и этот набор старых бэкендов webapp теперь составлял меньшинство. Мы регулярно предоставляем новые инстансы HAProxy, так что оставалось несколько свежих с правильной конфигурацией, но большинство из них оказались старше восьми часов и поэтому застряли с полным и устаревшим состоянием бэкенда. В конечном итоге, произошёл сбой сервиса. Это случилось в конце рабочего дня в США, потому что именно тогда мы начинаем масштабировать уровень веб-приложений по мере снижения трафика. Автомасштабирование в первую очередь завершает работу старых инстансов webapp, и это означало, что в серверном состоянии HAProxy их осталось недостаточно для обслуживания спроса.
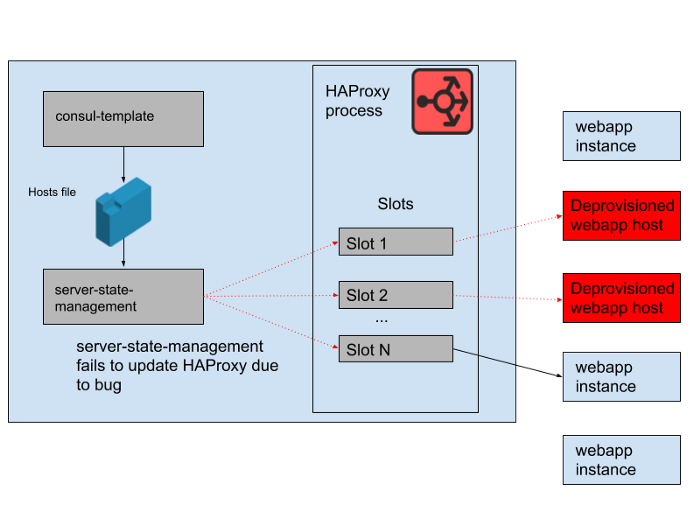
Рис. 4. Состояние HAProxy изменялось с течением времени и слоты начали ссылаться в основном на удалённые хосты
Как только мы узнали причину сбоя, он был быстро устранён с помощью плавного перезапуска флота HAProxy. После этого мы сразу задали вопрос: почему мониторинг не уловил эту проблему. У нас есть система оповещения для этой конкретной ситуации, но, к сожалению, она не сработала так, как предполагалось. Поломка мониторинга не была замечена отчасти потому, что система «просто работала» в течение длительного времени и не требовала никаких изменений. Более широкий деплой HAProxy, частью которого является это приложение, также относительно статичен. При низкой скорости изменений всё меньше инженеров взаимодействует с инфраструктурой мониторинга и оповещения.
Мы особо не переделывали этот стек HAProxy, потому что всю балансировку нагрузки постепенно переводим на Envoy (недавно мы перенесли на него трафик веб-сокетов). HAProxy хорошо и надёжно служил в течение многих лет, но у него есть некоторые операционные проблемы, как в этом инциденте. Сложный конвейер для управления состоянием сервера HAProxy мы заменим собственной интеграцией Envoy с плоскостью управления xDS для обнаружения конечных точек. Самые последние версии HAProxy (начиная с версии 2.0) тоже решают многие из этих операционных проблем. Тем не менее, мы уже некоторое время доверяем Envoy внутреннюю сервисную сетку, поэтому стремимся и балансировку нагрузки тоже перевести на него. Наше первоначальное тестирование Envoy + xDS в масштабе выглядит многообещающе, и в будущем эта миграция должна улучшить как производительность, так и доступность. Новая архитектура балансировки нагрузки и обнаружения служб не восприимчива к проблеме, вызвавшей этот сбой.
Мы стремимся поддерживать доступность и надёжность Slack, но в этом случае потерпели неудачу. Slack является важным инструментом для наших пользователей, и именно поэтому мы стремимся вынести урок из каждого инцидента, независимо от того, заметили его клиенты или нет. Приносим извинения за неудобства, вызванные этим сбоем. Обещаем использовать полученные знания для улучшения наших систем и процессов.
См. также:
- «5 опенсорсных альтернатив Slack для группового чата
- ««Не выходя из прачечной». Как СЕО Google, Amazon, Nasdaq и Slack работают из дома»
- «7 cмертных грехов Slack в большой компании (и как победить их автоматизацией)»

