
Хабр Курсы для всех
РЕКЛАМА
Практикум, Хекслет, SkyPro, авторские курсы — собрали всех и попросили скидки. Осталось выбрать!
А почему, собственно, нет? Как по-вашему иначе показывать преимущества инструмента, если не через подобные демонстрации?
В продакшен реализации слева будет ещё 1-2 панели, так что текст статьи в итоге будет как раз примерно по центру:

То есть тут сравнивается виртуализация рендеринга в $mol и рендер всего и вся на VueJS?
И делается вывод, что VueJS — плохо?
Вот пример из Реакта, во-первых, есть новый API Concurrent Mode с асинхронным рендерингом, а во-вторых, виртуализацию не нужно писать ручками, вот популярный npm-пакет react-virtualized (vuejs тоже имеет подобное)
Так сравните как работает виртуализация в $mol и в react-virtualized. А то получается как-то несправедливо.
вот популярный npm-пакет react-virtualized
Лучше react-window, она почти в 10 раз меньше и во столько же быстрее. Написан автором react-virtualized как переосмысление виртуализации для Реакта.
А ещё есть такая штука как uni-virtualizer от Polymer, но она пока ещё в разработке, правда.
Дело не в том, что можно сделать лучше по другому, дело в выводах.
Автор подменил понятия виртуального рендеринга и "лучше". Как результат — добавились новые проблемы, которые, возможно, не оправдывают вложенных усилий.
А результат — автор делает традиционный вывод: мой колхоз — рулит, а все ваши фермеры — тупят.
Интересно, а если сделать виртуальный скролл несколько иначе — в "невидимой" части показывать комментарии единым блоком текста (без кнопок, разделения на хедер-футер и прочей html-разметки), а при попадании конкретного блока с комментариями — "форматировать" его и показывать полноценной разметкой — будет ли профит?
Из плюсов:
Из минусов:
Число DOM элементов уменьшится раза в 2, но скроллинг будет сильно лагать, ибо при изменении DOM будет полный пересчёт стилей и лейаута для 50К элементов.
Число DOM элементов уменьшится раза в 2
вообще, например, для одного этого комментария используется 47 тегов, против предполагаемого одного (можно даже сам комментарий не форматировать, а ведь там тоже могут быть теги).
но скроллинг будет сильно лагать, ибо при изменении DOM будет полный пересчёт стилей и лейаута для 50К элементов
хм, да, тут не поспоришь… разве что как-то зонировать элементы используя абсолютное позиционирование (но это уже кажется переусложнением)
Текст комментария — это развесистый HTML. Например, в первом вашем комментарии 13 элементов в одном только содержимом.
Это уже виртуализация и получится.)
Это уже виртуализация и получится.)Так предложение и было — сделать виртуализацию, но по-другому.
В принципе было бы круто если бы сделали "супермобильную" без разметки :)
Без разметки это будет XML.
Единый блок текста должен быстро рисоваться. Например, если открыть в браузере текст первой части "войны и мира", проблем вообще никаких нет: http://az.lib.ru/t/tolstoj_lew_nikolaewich/text_0040.shtml, хотя там почти мегабайт текста.
В виртуальном варианте PgUp/PgDown не работает почему-то, а скроллить очень медленно.
Что-то эта страница на моле активно сопротивляется прокрутке в конец… И поиск работает как-то странно, больше на фильтрацию похоже.
Кстати, те кнопки, которые, судя по их расположению и внешнему виду, должны сворачивать-разворачивать ветку комментариев, при активной фильтрации делают какую-то ерунду.
И ведь не первый раз я такое вижу, когда сайт на моле рассыпается от простейших действий...
Попробуйте всё же прочитать статью, которую комментируете.
А что, чтение статьи как-то заставит глючный сайт заработать?
Как минимум — вы перестанете недоумевать почему оно работает так, как работает.
Но я недоумеваю по другому поводу: какого фига оно так работает?
VueJS — тупит, а $mol — рулит.
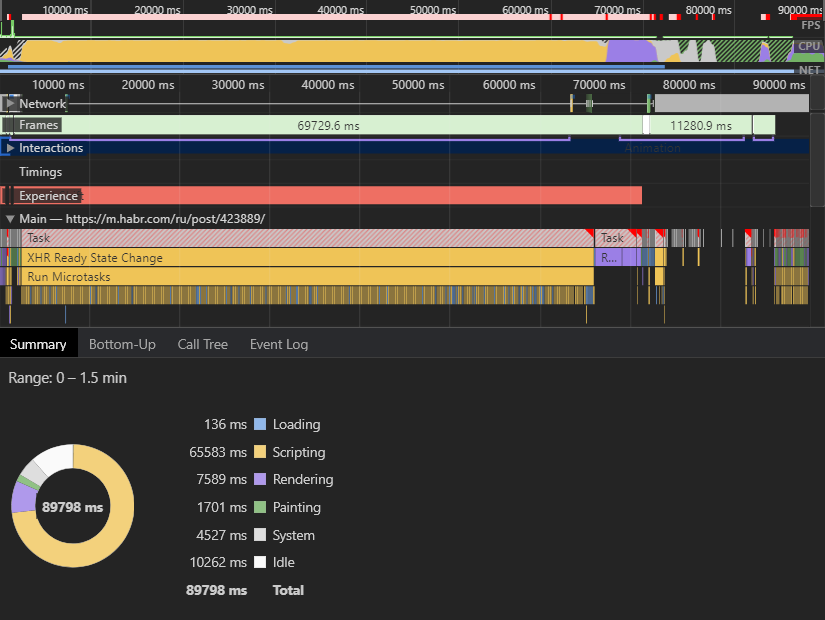
Возьмём, например, вот эту страницу, содержащую 2500 комментариев.На FF 79.0 + Webrender + прочие ускорители на Linux полная загрузка около 10 с.
Скорее всего вы забыли отключить сетевой кеш и браузеру не пришлось параллельно загружать 8 метров картинок.
Тут дело не только в объёме, но и числе изображений, и ограничении браузера на число одновременных загрузок, и латентности сервера.
Отлично теперь мобильный фф
Вообще я телефон использую по прямому назначению — звонить с него.
В основе своей смартфон — это умный телефон, т.е. основной задачей, исходя из этимологии, является все еще звонилка.
А вот этой претензии я вообще не понимаю. Есть телефон. Есть мобильник/сотовый/мобильный телефон. Есть смартфон. Три разных названия для трёх разных вещей.
Не вижу почему это должно быть обязательно так. Для меня смартфон как изначально был "КПК с возможностью коммуникации" так им и остался.
То есть я в какой-то момент сменил два своих гаджета, а именно КПК и мобильник, на один единственный, а именно смартфон. Но при этом КПК я пользовался вовсю, а мобильник мне был скорее навязан окружением. И смартфон для меня в первую очередь это "апгрейд" моего КПК.
Моим первым смартфоном был HTC(Touch если я не ошибаюсь) и он вполне себе адекватно заменял мой тогдашний КПК(уж извините, но модель не вспомню).
Да и вообще я бы скзала что в понимании большинства людей именно смартфон это что-то без кнопок для набора текста/номера
Смартфон как раз был телефоном с дополнительным софтом. А КПК с возможностью мобильных коммуникаций был коммуникатором.
Если эта задача перестает быть основной, то это уже КПК (PDA).
Помнится, девайс, совмещающий функции КПК и телефона пытались обозвать "коммуникатором", но не прижилось.
Т.е. у разрабов хабра мобильная версия тяжелее десктопной. Логика ай-ти ресурса номер один, чо :D
Могли бы просто сss десктопной версии подправить, но видимо захотели новый фреймворк вставить.
К сожалению, у меня нет макбука, чтобы это подебажить.
К сожалению, у меня нет макбука, чтобы это подебажить.можно попробовать поднять виртуалку с макосью для таких тестов.
А что значит "не работает"? Кнопки не нажимаются? Или не появляются? Клавиатура не вылезает? Не меняется число?
Вот это нормальное решение. Можно даже хранить по одному куску сверху и снизу в кэше. Тогда когда мы приходим к концу скролла мы отображаем из кэша а не по сети, а по сети в этот момент запрашиваем уже следущий кусок. Таким образом если пользователь скролит медленно то он вообще не увидит никаких индикаторов загрузки.
А зачем вам дерево? Просто посчитали один раз смещение по горизонтали и всё. Дальше комментарии идут одним списком, уже тут предлагали.
Я смотрю тут много теоретиков, которые знают как надо, но никогда сами руками этого не делали.
Ну а почему прыгает cкролл-бар? Без нашего ведома браузер может поменять шрифты (это не тот случай), и может подгрузить картинки.
Когда подгружаются картинки, то прыгает скролл даже в статическом html. Это не возможно полностью пофиксить. Есть ли у вас другая объективная причина почему оно прыгает?
Кроме редких частных случаев, невозможно узнать высоту контента, пока весь его не отрендеришь.
А что рендеринг асинхронный? Если я удаляю или добавляю елемент сверху для экономии ресурсов, то я заменяю его на соответсвующий margin. То же самое и снизу. Кажется не надо знать всё заранее.
Я тут подумал. Вобщем без того чтобы контролировать scroll bar самому не получится сделать красиво.
Дальше будет критика, но меня просто заинтересовала задача, так что надеюсь конструктивная.
В вашей реализации самое странное это какие-то подергивания. Т.е. я делаю скролл вниз, браузер отрисовывает его ниже и потом он прыгает вверх и сразу вниз. Т.е. вот эти прыжки туда-сюда не понятно зачем нужны. По-идее, мы меняем высоту один раз за обработчик onscroll т.е. прыжок должен быть один. Как это происходит при бесконечной прокрутке например.
Во-вторых, не реализовано запоминание размеров. Т.е. при повторном скролле всё опять дергается.
Демка ngx-virtual-scroller работает плавнее, но возможно из-за того что там распределение рандомных размеров равномерное, а на хабре подругому.
Основная проблема это то что нельзя узнать какая высота изначально. Т.е. как только мы забираем новую пачку комментариев то у нас меняется наше предсказание о том сколько места ещё надо сверху или снизу. Соответственно соотношение место вверху к месту внизу меняется. Решить это можно так: скролл бар должен быть не линейный. Сам указатель скролла мы оставляем на месте, но теперь размеры выше от него и ниже от него умножаем на соответствующий коэффициент. Его учитываем при последующей прокрутке.
Размеры меняются если комментарии добавляются или редактируются?
Да уменьшение сверху это проблема. Наверное у нас нет нужного контроля за рендером чтобы обрезать сверху и при этом одновременно перейти на старое место. Т.е. чтобы не было заметно скачка. С другой стороны если просто идём сверху вниз медленно, то такого не происходит. Или я не правильно понимаю причины скачков?
Корректировки это правильно. просто надо чтобы корректировки позиции для рендера и для скроллбара не были связаны. Как я предложил выше. Что думаете?
Они по разным причинам могут меняться. Например, при догрузке шрифта.
Такого не происходит в самом начале. В середине списка скачет даже при медленной промотке. Причины мне не известны.
Скроллбар показывает позицию вьюпорта относительно контента. Они не могут быть не связаны без деградации UX.
Они по разным причинам могут меняться. Например, при догрузке шрифта.
На самом деле это не важно. всё равно для примерной оценки мы используем текущий размер. можно при каждом отображении обновлять кэш.
Скроллбар показывает позицию вьюпорта относительно контента. Они не могут быть не связаны без деградации UX.
UX уже деградирован. потому что если вы хотите перейти на позицию например 20% но не знаете какая реальная высота коментов. Даже приблизительные размеры не знаете, для тех которые пользователь уже видел.
А то что этот индикатор скачет как бешанная лошадь, вот это как по мне проблема UX. То что отображает скроллбар и так и так будет очень приблизительная оценка. Может дойдут руки и я попробую реализовать. Интересно как будет работать.
Скролл для элементов с динамической высотой сделать сложно, видимо поэтому он и прыгает :). Но, сказать честно, реализация могла быть и получше. Идея ведь совсем не новая, даже для хабра (см. мою статью про похожую проблему аж 2011 года: https://habr.com/ru/post/111422/)
Вы придумали и решаете проблему, значимость которой переоценена. На Хабре мало статей с большим числом комментов, это скорее исключение, чем правило. И оптимизация таких редко встречающихся статей просто не имеет смысла.
Вы предлагаете какое-то жутко переусложненное (тормозящий браузер клиентский рендеринг) решение, на каком-то никому неизвестном JS фреймворке, ломая стандартный функционал браузера (поиск), да еще и с самодельным кешем на Service Worker (страшная бессмысленная технология). Алло, в браузере уже есть кеш, зачем вы предлагаете делать жалкое его подобие, которое только жрет память и замедляет браузер? Всегда можно открыть about:cache или как там и просмотреть кешированную страницу. Без всяких воркеров, JS и потребления памяти, прикиньте?
Самое быстрое и лучшее решение, на мой взгляд — просто отдавать с сервера HTML. Браузер умеет прогрессивно отображать HTML. Вы правы, что картинки стоит сделать лениво загружающимися. Но для отображения HTML нужен еще CSS, и тут разработчикам надо поработать. Надо отказаться от вредной идеи писать все стили в один файл и использовать громоздкие уродливые фреймворки вроде Bootstrap. Нужно выкинуть весь старый CSS код, начать писать для каждого компонента свой файл со стилями CSS, и к странице подключать только используемые на ней компоненты. Тогда объем CSS будет невелик (много ли CSS надо для отображения текстовой статьи? Не более 50 Кб навскидку) и страница будет загружаться быстрее. Увы, на практике почему-то встречается подход "склеиваем вебпаком все в огромный CSS на мегабайт и удивляемся, почему все тормозит".
JS файл, нужный на странице, можно подгрузить асинхронно — он не критичен для отображения статьи, если она правильно сверстана.
Далее, выкиньте веб-шрифты — они не нужны, но замедляют отображения текста. В современных ОС Windows и Mac уже есть хорошие шрифты.
В общем, при моем подходе, для отображения статьи надо всего 2-4 файла — HTML и 1-3 легких CSS файла. Это решение будет грузиться быстро и обладать простой архитектурой, и не потребует разбираться в залежах JS кода.
Также, предлагаю отказаться от метрики "время отображения первого экрана". Какой в ней смысл? Это приводит к нездоровым оптимизациям, когда первый экран грузится быстро, а все, что после него — долго. Это глупая и ненужная метрика, вы же всю статью прочесть хотите, а не первый экран (занятый шапкой и меню)? Последуйте моему совету насчет сокращения объема CSS и эта метрика вам не понадобится.
И что за бредовая идея описывать стили внутри JS кода? CSS справляется с этим намного лучше и не требует тяжелых библиотек для работы, в отличие от JS.
И что это за дурацкое название Maybe(Str)? Это называется Nullable(Str), а ваше название только сбивает с толку. В базе данных мы же пишем IS NOT NULL, а не IS NOT MAYBE. Зачем придумывать новые названия для существующих вещей?
Также, откажитесь от moment.js, это тяжелая переусложненная библиотека, от которой вы будете использовать 5% функционала. Заодно откажитесь от темных тем, бессмысленная трата времени, плюс в браузере есть режим для чтения на такой случай.
"склеиваем вебпаком все в огромный CSS на мегабайт и удивляемся, почему все тормозит".
Интересно, а есть webpack наоборот: вырезать из кучи зависимостей и отдавать только тот CSS и HTML, что нужны?
Получается — это плагин к тому же вебпаку: https://linguinecode.com/post/reduce-css-file-size-webpack-tree-shaking — интересно!
И плюс, для реально больших развесистых комментариев можно спокойно сделать пагинацию, примерно как наши предки сделади лет так пятьсот назад, перейдя с свитка на книги
А новые комментарии?
А это можно решить как и в бесконечном скроле кнопкой сверху "появились новые комментарии, показать?" (в ВК так сделано). Я это к тому, что и при пейджинке и при бесконечно скроллинге добавление новых сущностей сдвигает последовательность.
Как-то можно, наверное. Но вот при пейджнге я думаю, не очень будет удобно по одной кнопке скакать с первой страницы на 50-ю...
А при кролинге от первой к 50-ой переходить удобно? Скролишь и материшься… Потому что при нормально сделанном пейджинге можно ходить как последовательно "назад" и "далее" по страницам, так и задать конкретный номер сразу.
Никаких проблем со скроллингом на Хабре не испытывал, правда нужды перейти на "первые/семнадцатые/последние 5% комментариев" тоже не испытывал: интересует или все комментарии подряд, или непрочитанные, или поиск по ctrl+f как по содержанию, так и по метаинформации типа ника, даты и времени. Хотя вру, иногда не хватает простого способа "перейти в самое начало или самый конец комментариев без обычной клавиатуры"
Да, есть такое. Не часто, но случается. И плоский режим помог бы при таких "форс-мажорах".
Boomburum что думаете?
Про Maybe и Nullable это вы зря. Maybe, Just, Some, Either — это целый отдельный, дивный мир.
Да и темная тема — если вдруг привыкнуть, а главное включать ее автоматом, то не такая уж это и пустая затея.
Тут явно есть обратная связь: чем хуже Хабр работает с комментариями, тем меньше статей с комментариями.
Кроме Windows и Mac есть ещё Linux
Причём вообще базы данных в разговоре о фронте? В SQL и JS семантика null разная.
Тут я рассказываю зачем css-in-ts и как это реализовано: https://youtu.be/FMNLN5YIE_M?t=5555
Maybe, Moment — это просто локальные алиасы:
const Int = $mol_data_integer
const Bool = $mol_data_boolean
const Str = $mol_data_string
const Maybe = $mol_data_nullable
const Rec = $mol_data_record
const List = $mol_data_array
const Dict = $mol_data_dict
const Moment = $mol_data_pipe( Str , $mol_time_moment )решаете проблему, значимость которой переоценена.
На данный момент жуткие лаги при комментировании возникают не из-за отсутствия виртуализации, а из-за кривого редактора. Если отключить все обработчики нажатия клавиш (keydown, keyup и keypress) — лаги сразу же пропадают.
Только не спрашивайте каким таким образом скорость работы этих обработчиков зависит от числа комментариев...
Открываю ваш вариант
В результате вместо статьи без комментариев вижу фигу с ошибкой сети. К сожалению хабр не позволяет догрузить комментарии кусочками через Range или API(или я не знаю как).
Вы забыли про блокировщики, в FF 79 полная загрузка занимает 42 с но с uBlock Origin сокращается до 21 с. Читать можно уже через 10 с, но не очень приятно из-за ресайзов от подгрузки картинок.
Можно попробовать первоначально загружать комментарии без рендеринга, только текст. (По одному диву на комментарий)
Комментарии, который скоро попадут в область просмотра, заменять на полноценный контент.
Те, которые больше не понадобятся, заменять обратно на текст и сохранить высоту содержимого.
Это решит проблемы с поиском и, по большей части, с прокруткой.
Мне кажется, дело еще в том, что там структура тегов древовидная, тег родительского комментария содержит все дочерние комментарии. Браузеру сложнее это перерисовывать, чем если бы был плоский список, а структура комментариев регулировалась только отступами.
Код исходников уложился в 400 строк, на написание которых требуется не более пары часов
А это прямо ровно засеченное время на реализацию или примерное?
Тут самые большие усилия требуются лишь на преодоление когнитивного сопротивления при изучении фреймворка. Дальше, в принципе, ничего сложного: архитектура простая, модули маленькие, апи стандартных компонент тривиальные. Тут главное не пытаться приспосабливать его под привычные паттерны разработки, а освоить новые. Собственно в хабрачиталке код простой как пробка. Самая большая сложность была в том как описать консистентную логику сворачиваний/разворачиваний при наличии/отсутствии фильтрации.
Ну вот у меня есть сомнения, что в 2 часа реально уложиться. Более того. Возникло впечатление, что и сам автор в этот срок не уложился.
Экспертная оценка.
Т.е. это не результат прямого замера, так? Это просто предположение, сколько это будет занимать у тех, кто этим начнет пользоваться.
Вот тут я время замерял, если вам интересно: https://habr.com/ru/post/491120/#istoriya-uspeha
Там оказалось 2 часа на реализацию и ещё 2 пришлось подевопсить. Проработанные дизайн-макеты уже были. Повторение половины от расписанной там функциональности на высокоуровневом react-based фреймворке заняло неделю работы двух разработчиков.
Ну а если вы настолько прям сомневаетесь, то подписывайтесь на Ютуб канал, чтобы не пропустить скринкаст разработки очередного приложения.
Подскажите зачем используются атрибуты вместо классов? Что это даёт?
Что такое селекторы атрибутов я знаю. У вас в HTML коде куча атрибутов без значения которые используются явно вместо классов. Разве они не раздувают DOM и HTML?
Есть ли смысл использовать атрибуты вместо классов?
Если что у классов есть удобное браузерное API которое позволяет легко их добавлять и удалять.
А есть ли смысл использовать классы вместо атрибутов?
Разница в скорости незначительна, семантики у классов никакой, гибкость у классов ограничена, 1 апи проще чем 2.
Так какие возможности дают атрибуты по сравнению с классами?
el.hasAttribute (name) > el.classList.contains (name)
el.removeAttribute (name) > el.classList.remove(name)
el.getAttribute (name) > el.classList.contains(name)
el.setAttribute (name, str) > el.classList.add(name)
А есть ещё:
el.classList.toggle(name) — добавить или убрать класс в зависимости нет его или есть в списке соответственно.
el.classList.replace(old_name, new_name) — заменить один класс другим.
Я не говорю что нужно использовать классы вместо атрибутов. Просто не надо использовать атрибуты вместо классов.
Что это даёт?
В случае с веб-компонентами даёт возможность подписываться на изменение любого свойства компонента через attributeChangedCallback, что часто очень пригождается.
Ну если очень нужно отслеживать добавление и удаление элементу класса то можно отслеживать атрибут class. Он будет меняться при добавлении и удалении класса.
Разбиваем по пробелам oldValue и newValue. Чего нет из oldValue в newValue удалено. Чего нет из newValue в oldValue добавлено.
А затем для передачи параметра mask="99.99.9999" вы начнёте городить парсер разбирающий класс mask_99.99.9999. А ещё вдруг окажется, что к таким классам из-за значения в нём теперь не прицепить ничего из css как можно было с именем атрибута. Да и пробелы иногда нужно в значении передавать. Не придумывайте себе проблемы.
Я не призываю использовать классы там где нужно использовать атрибуты.
Автор же использует атрибуты в роли классов. То есть у элементов куча атрибутов с пустыми значениями. И по именам этих атрибутов элементам задаются CSS стили.
Я не призываю использовать классы там где нужно использовать атрибуты.
Да даже если так, зачем создавать себе гемор вот с этим:
Разбиваем по пробелам oldValue и newValue. Чего нет из oldValue в newValue удалено. Чего нет из newValue в oldValue добавлено.
?
Автор же использует атрибуты в роли классов
А можете привести пример когда что-то должно быть именно классом и совсем не смотрится в виде атрибута?
Иван пытается протолкнуть идею, что булевы параметры для стилизации обязательно задавать исключительно через классы и нельзя через атрибуты. Ему объясняют, что стили необходимо привязывать не только к булевым параметрам. А разделение на булевы и не булевы не даёт ничего кроме усложнения на ровном месте.
Эм, стилизация отдельно, параметры отдельно?
Зачем отдельно? Ситуация когда на добавление/удаление какого-либо атрибута нужно и в js как-то отреагировать и какие-то стили добавить у меня происходит регулярно. По вашему же получается нужно так:
<x-dropdown class="opened" opened></x-dropdown>Если параметры компонента автоматически делать Observable, то да, часто и реактивное программирование находит себе применение:
export class OpalTextInput extends BaseComponent {
// ...
@Param(String)
value: string | null;
@Param(String)
startIcon: string | null;
@Param(String)
endIcon: string | null;
@Param(Boolean)
clearable: boolean;
@Param(Boolean)
loading: boolean;
@Computed
get btnClearShown() {
return this.clearable && !this.loading && !!this.value;
}
@Computed
get endIconShown() {
return !this.loading && !this.btnClearShown;
}
// ...
}Слишком многое "там" может накопиться и рано или поздно что-то забудется добавить или что-то забудется уже ненужное удалить. Особенно если не в одном месте добавляется. Это в целом, а в случае веб-фронта так проще делать полифилы и прочие graceful degradation
Проблема "забудется" решается правильной структурой кода, не должно быть нескольких мест которые управляют одним и тем классом/атрибутом.
Вот как раз с подходом "есть код, который добавляет этот класс, вот там и нужно реагировать" и будет с большой вероятностью много таких мест, потому что класс (читай визуальное отображение) может быть один, а вот реакции (читай поведение) — разными в разных контекстах.
Если реакции должны быть разными — то на изменение класса/атрибута вы их никак не "повесите". А если не должны — то нет никаких проблем не дублировать код.
Вот что я вижу здесь в инспекторе:
<mol_dimmer id="$my_habrcomment.Root(0).Article().Text([object Text])" mol_html_view_text="" my_habrcomment_article_text="" mol_dimmer="" mol_paragraph="" mol_view="" style="min-height: 72px;">Как это могло бы выглядеть.
<mol_dimmer id="$my_habrcomment.Root(0).Article().Text([object Text])" class="mol_html_view_text my_habrcomment_article_text mol_dimmer mol_paragraph mol_view" style="min-height: 72px;">Может даже класс "mol_dimmer" лишний так как элемент и так называется "mol_dimmer".
Чем стало хуже написано выше. Чем лучше то стало?
Каждый атрибут это тоже node() который имеет свои параметры и занимает оперативку.
1: mol_html_view_text=""
baseURI: "https://nin-jin.github.io/habrcomment/#article=423889"
childNodes: NodeList []
firstChild: null
isConnected: false
lastChild: null
localName: "mol_html_view_text"
name: "mol_html_view_text"
namespaceURI: null
nextSibling: null
nodeName: "mol_html_view_text"
nodeType: 2
nodeValue: ""А класс это уже просто значение атрибута class.
Экономия на спичках.
Например на cтранице у меня сейчас отображается только часть комментариев.
Имеем 40КБ текста и 200КБ тегов и атрибутов просто как текст. Элементов 762 и атрибутов 5197. Как то многовато для 19 комментариев отображаемых на странице.
У приведённой страницы есть проблемы с потреблением памяти?
Автор решил проблему памяти держа в DOM только часть документа. Но при этом раздул количество объектов на единицу текста. От чего похоже у меня на планшете его вариант притормаживает больше чем десктопная версия на том же планшете.
А класс это уже просто значение атрибута class.
Который парсится браузером в объект classList.
Может даже класс "mol_dimmer" лишний так как элемент и так называется "mol_dimmer".
Не лишний. У наследника будет иное имя.
В чате у нас тут подсказывают, что в следующей версии Хрома уже запилили виртуализацию DOMа для решения "не существующей" проблемы: https://web.dev/content-visibility/
Со скачками скроллбара и необходимостью весь этот DOM рендерить — всё как мы любим.
Вы предлагаете Хабру добить полный набор антипаттернов разработки "веб-приложений", чтобы писать статью о том, "как нельзя" можно было на примере одного только m.habr.com?
Это без сомнения похвально, а то я чуть не забыл, что поиск по странице на Хабре все таки почти всегда работает (за исключением 500+ комментариев в мобильном хроме).
Хочу отметить, что тормоза при прокрутке и при наборе комментариев связаны не с размером DOM, а с чрезмерной заскриптованностью. На каждое событие, буть то нажатие кнопки или скролл зачем-то навешаны обработчики. И если отключить JS, то всё будет работать плавно.
Так что моё решение — четвёртое. Надо не отрезать ногу, а лечить пациента. Оставляем HTML/JSON-версию и просто убираем прожорливые обработчики.
Оптимизация синоним хрупкости. Экономия на спичках даст ровно противоположный эффект: поддерживать и улучшать станет сложнее, баги будут фикситься дольше. Решение проблемы нужно искать в другой плоскости.
Мы остались в той же плоскости, чтобы уйти в другую плоскость нужно задавать другие вопросы. Например: почему пользователям нужно грузить все 2500 комментариев при начальной загрузке страницы?
Не стоит вопрос в полном отказе от оптимизации, но любая оптимизация должна быть осмысленной и продуманной.
Например: почему пользователям нужно грузить все 2500 комментариев при начальной загрузке страницы?
Чтобы работал поиск.
А теперь можно пойти дальше и спросить: как можно искать по комментариям кроме рендеринга всего списка? Что можно искать в комментариях? Ну и так далее.
Верните старый хабр...
Если хотите посмотреть, как сделать нормально комментарии — откройте пикабу и посмотрите.
А ещё на пикабу не теряется информация о непрочитанных комментариях, если страница не загрузилась или же загрузилась, но пользователь случайно перезагрузил страницу.
Barbaresk Как веб-разработчик я могу с уверенностью заявить, что ....А я как пользователь хочу, чтобы все комментарии загружались сразу, без необходимости совершать какие-то дополнительные действия (в том числе прокручивать страницу). Как это сделать — не мои проблемы. Варианты решений: меньше js, обработчики событий подгружать при попадании в зону видимости (ими редко пользуются) и т.д.
Вместо поддержки двух абы как слепленных реализаций для разных девайсов, лучше потратить это время на одну, но толковую и адаптивную
и писал в техподдержку Хабра про это. Мне сказали — на мобильном у-ве сиди на мобильной версии, мы десктопную версию на мобилках не поддерживаем (фейспалм). А самое интересное действительно происходит именно в горячих статьях с 1000-ми комментариев. Приходится выкручиваться.
Очень надеюсь, что разработчики воспримут статью серьезно и перенимут из нее часть технических решений — как минимум пользовательский опыт реально станет лучше
Да уж, у меня типичный ритуал с мобильной версией выглядит так:
А всё потому, что довольно тривиальную страницу уведомлений всё никак не завезут на мобильную версию.
У меня один один. Было бы не плохо позвать разработчиков хабра в тред.
Да я думаю они и так в курсе.
Boomburum
Я тут понял, что неправильно замерял потребление памяти: вместо размера JS heap надо замерять выделенный для вкладки объём. Разница получается ещё более удручающая:
Десктопная версия: 800 MB
Мобильная версия: 1000 MB
Ускоренная универсальная версия: 80 MB
Скорее всего именно этим и объясняется, что на моём телефоне рендерятся лишь несколько первых комментариев — памяти не хватает на всё остальное. Поправил статью.
Димочка пора уже функциональное программирование подучить и начать заниматься хотя бы йогой, а не только mol)
{kind=link}
Вырезаем SSR и ускоряем Хабр в 10 раз