Технологический мир охватил новый хайп — GPT-3.
Огромные языковые модели (вроде GPT-3) все больше удивляют нас своими возможностями. И хотя пока доверие к ним со стороны бизнеса недостаточно для того, чтобы представить их своим клиентам, эти модели демонстрируют те зачатки разума, которые позволят ускорить развитие автоматизации и возможностей «умных» компьютерных систем. Давайте снимем ауру таинственности с GPT-3 и узнаем, как она обучается и как работает.
Обученная языковая модель генерирует текст. Мы можем также отправить на вход модели какой-то текст и посмотреть, как изменится выход. Последний генерируется из того, что модель «выучила» во время периода обучения путем анализа больших объемов текста.
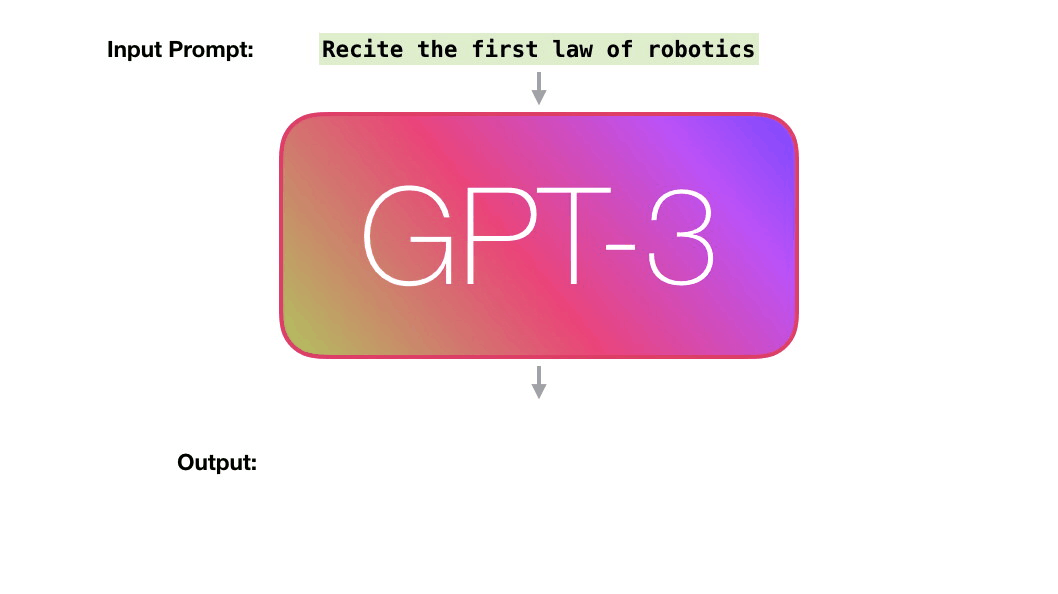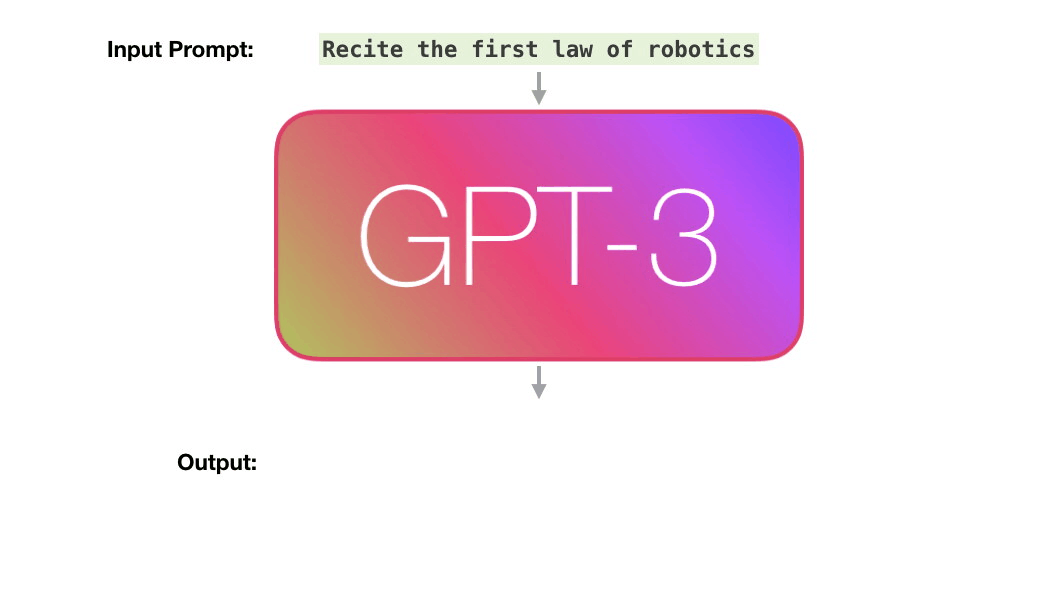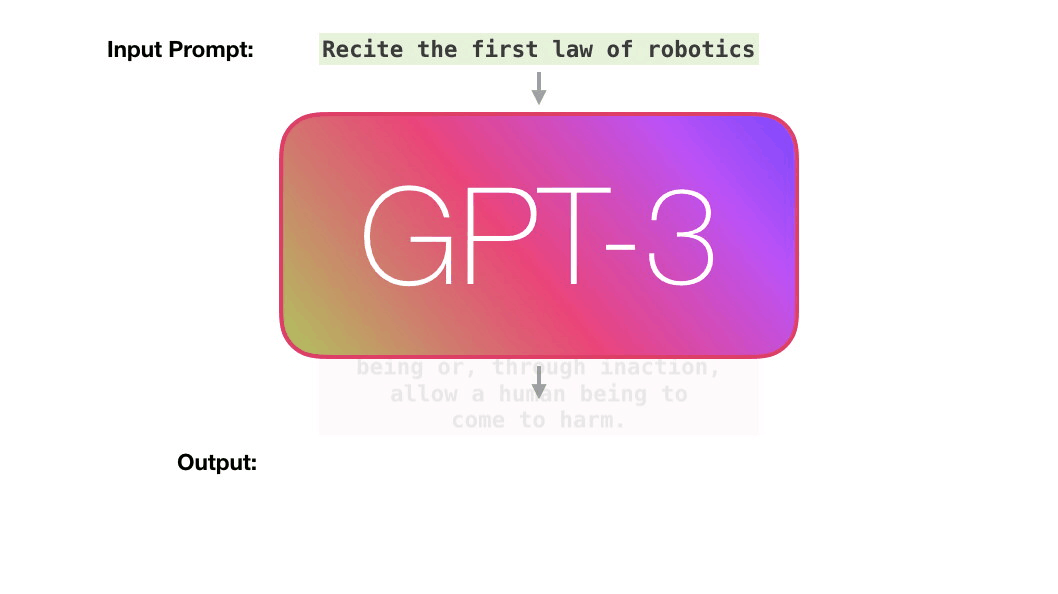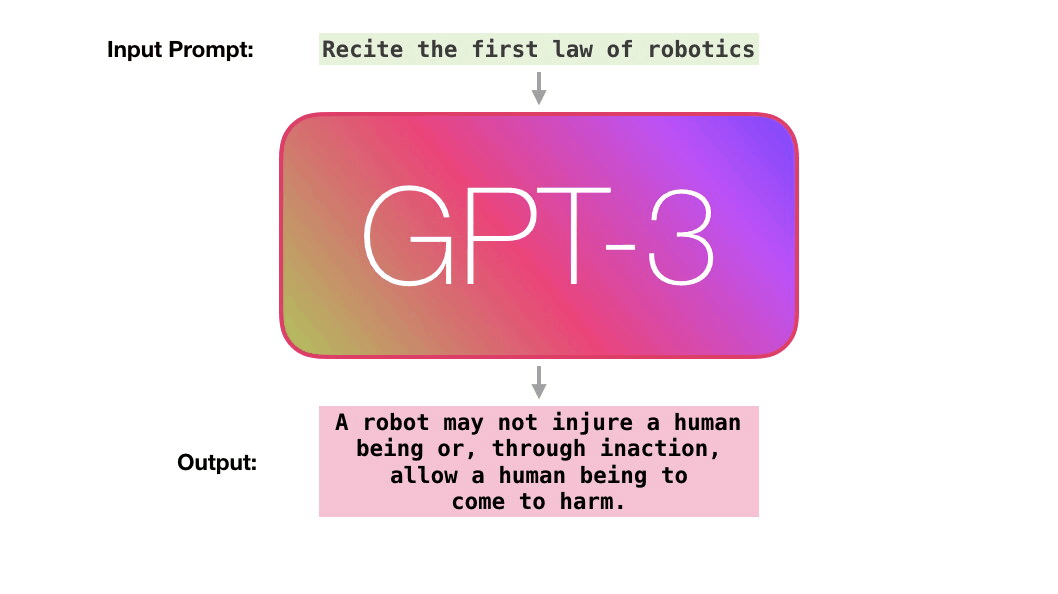
Обучение – это процесс передачи модели большого количества текста. Для GPT-3 этот процесс завершен и все эксперименты, которые вы сможете увидеть, проводятся на уже обученной модели. Было подсчитано, что обучение должно было занять 355 GPU-лет (355 лет обучения на одной видеокарте) и стоить 4.6 миллиона долларов.
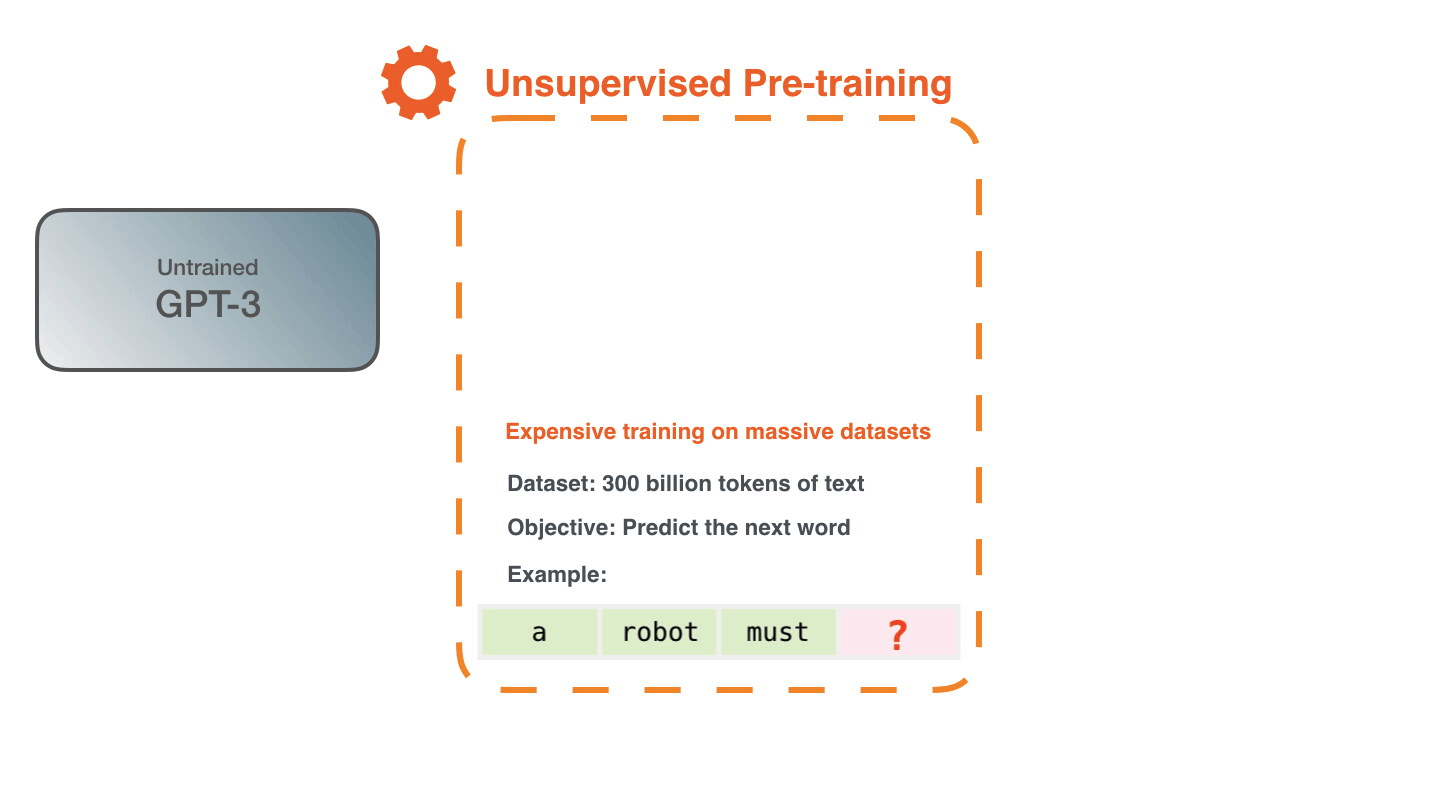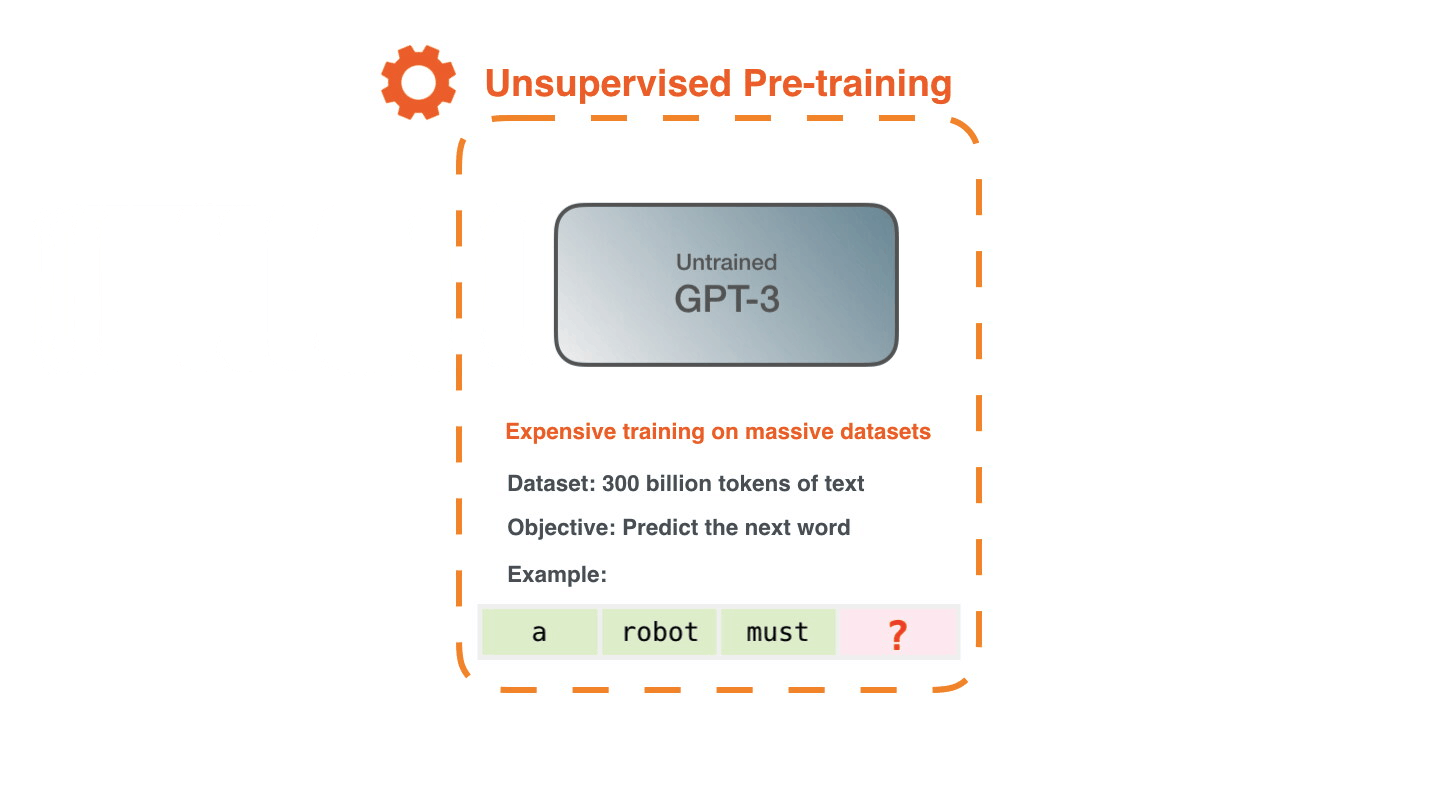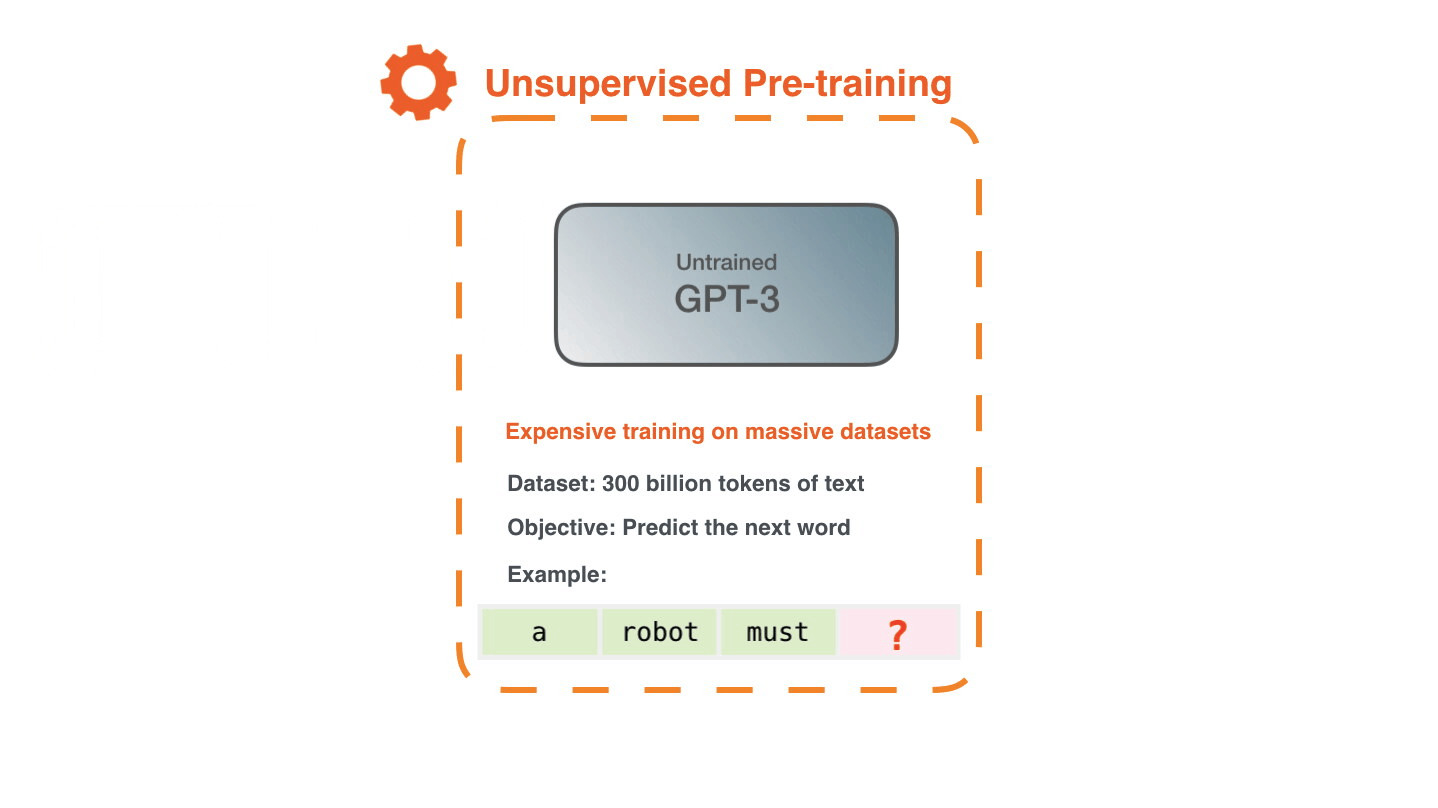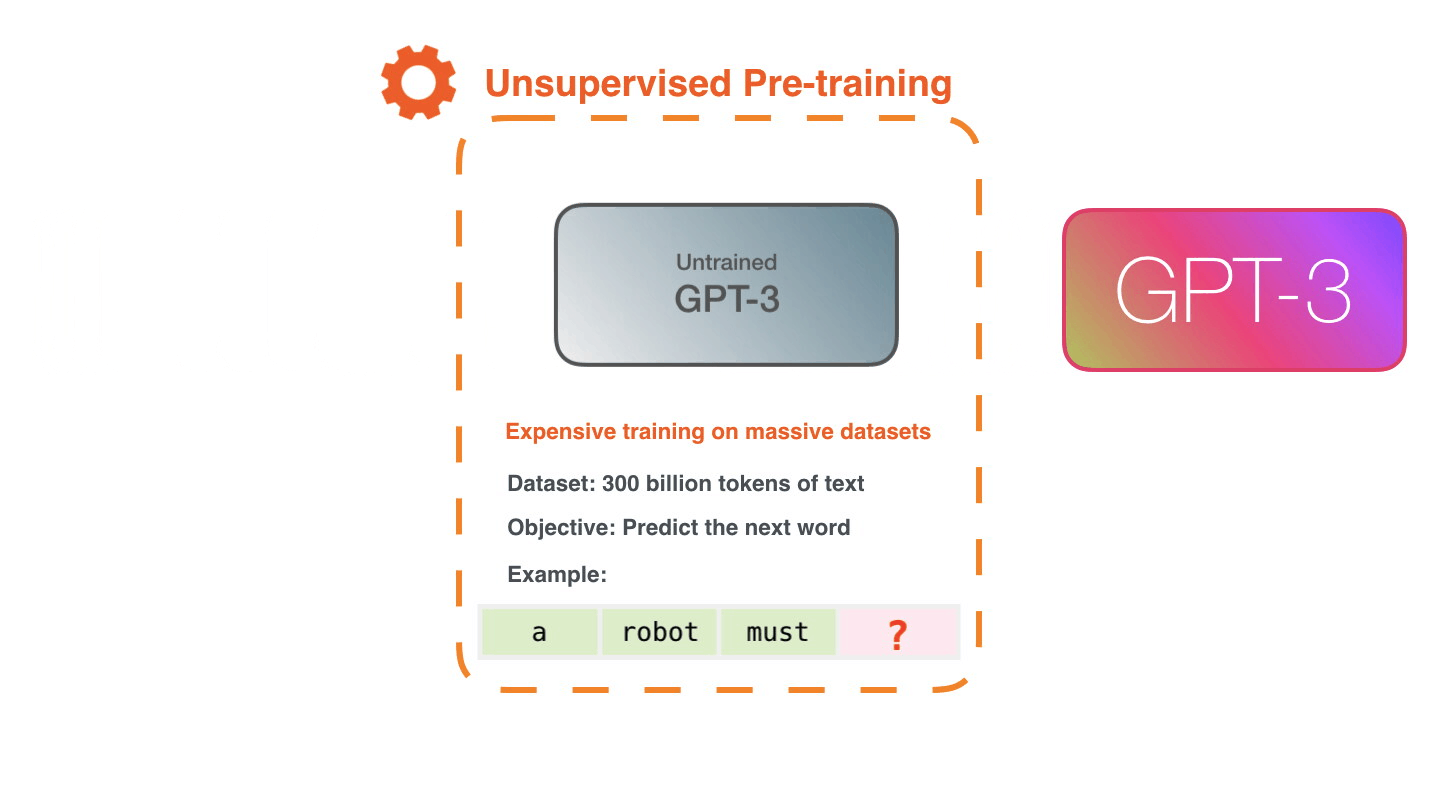
Для генерации примеров для обучения модели был использован набор данных размером в 300 миллиардов текстовых токенов. Например, так выглядят три обучающих примера, полученных из одного предложения, изображенного сверху.
На изображении видно, как мы можем получить множество примеров, просто проходя окном по имеющемуся тексту.
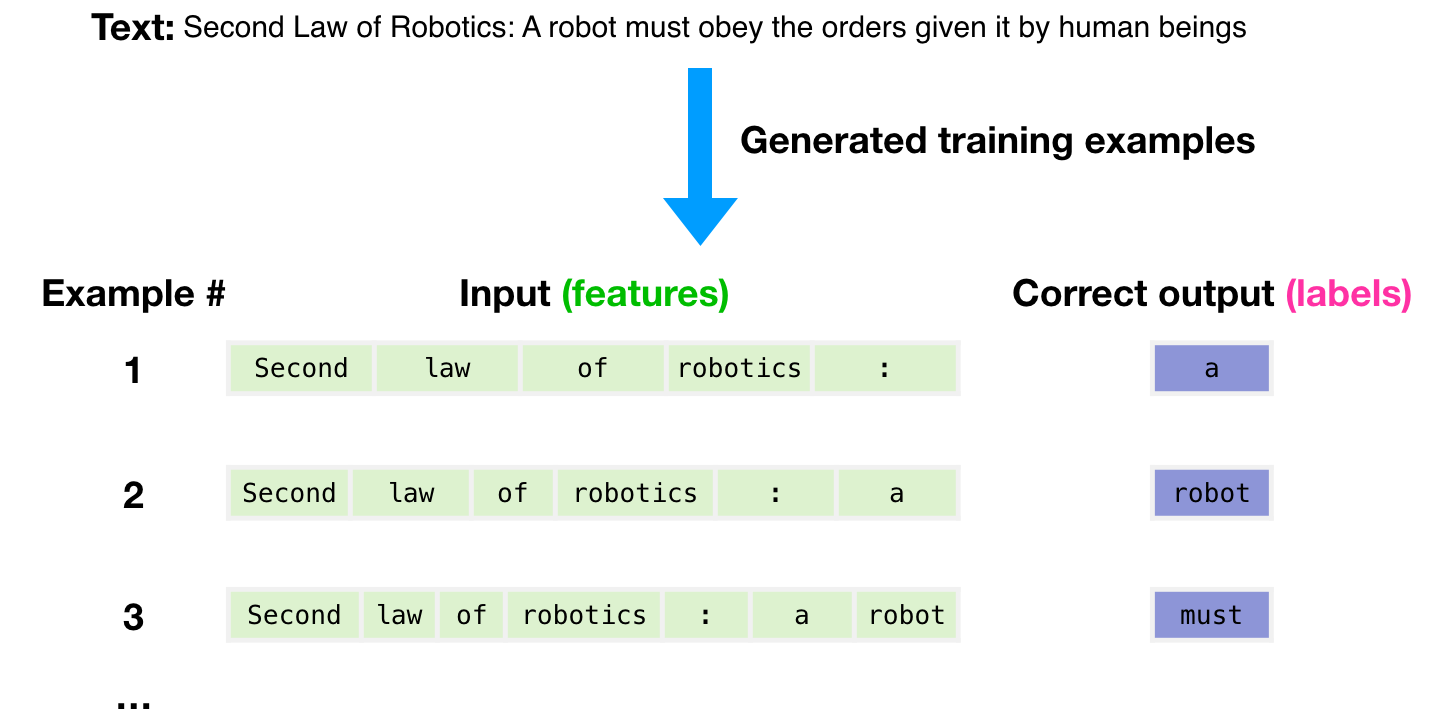
На ввод модели мы подаем один пример (отображаем только признаки) и просим ее предсказать следующее слово предложения.
Поначалу предсказания модели будут ошибочны. Мы подсчитываем ошибку в предсказании и обновляем модель до тех пор, пока предсказания не улучшатся.
И так несколько миллионов раз.

Теперь давайте рассмотрим эти этапы обучения чуть более подробно.
GPT-3 генерирует выход по одному токену за раз (условимся пока, что токен – это одно слово).

Стоит отметить, что эта статья — лишь описание работы GPT-3, а не обсуждение того, что нового эта модель предложила миру (по сути все сводится к до смешного огромным размерам). В основе архитектуры – модель декодирующего Трансформера, описанная в статье.
GPT-3 поистине ОГРОМНА. Она кодирует то, чему выучивается, в 175 миллиардов чисел (называемых параметрами). Эти числа используются для подсчета генерируемого за один прогон токена.
Необученная модель инициализирует параметры случайным образом, а затем в ходе обучения подбирает такие значения, которые помогут получить наилучшие предсказания.
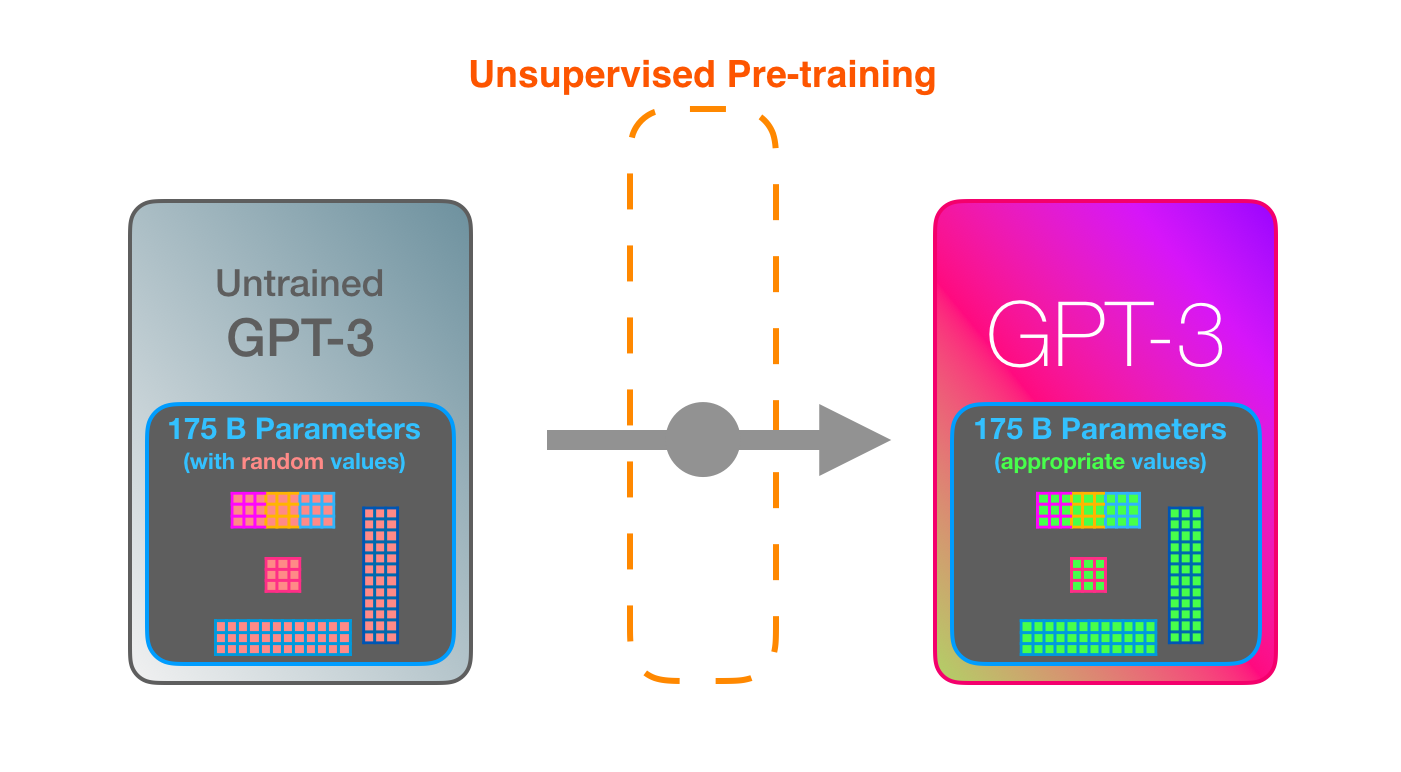
Эти значения – часть сотен матриц внутри модели, а предсказания – главным образом, результат множества матричных перемножений.
В видео «Введение в ИИ на Youtube» показана простая модель машинного обучения с одним параметром – отличное начало для разбора этого 175-миллиардного монстра.
Чтобы пролить свет на то, как эти параметры распределяются и используются, нам нужно открыть модель и посмотреть на нее изнутри.
Ширина GPT-3 составляет 2048 токенов – это её «контекстное окно», что означает наличие 2048 траекторий, по которым продвигаются токены во время их обработки.
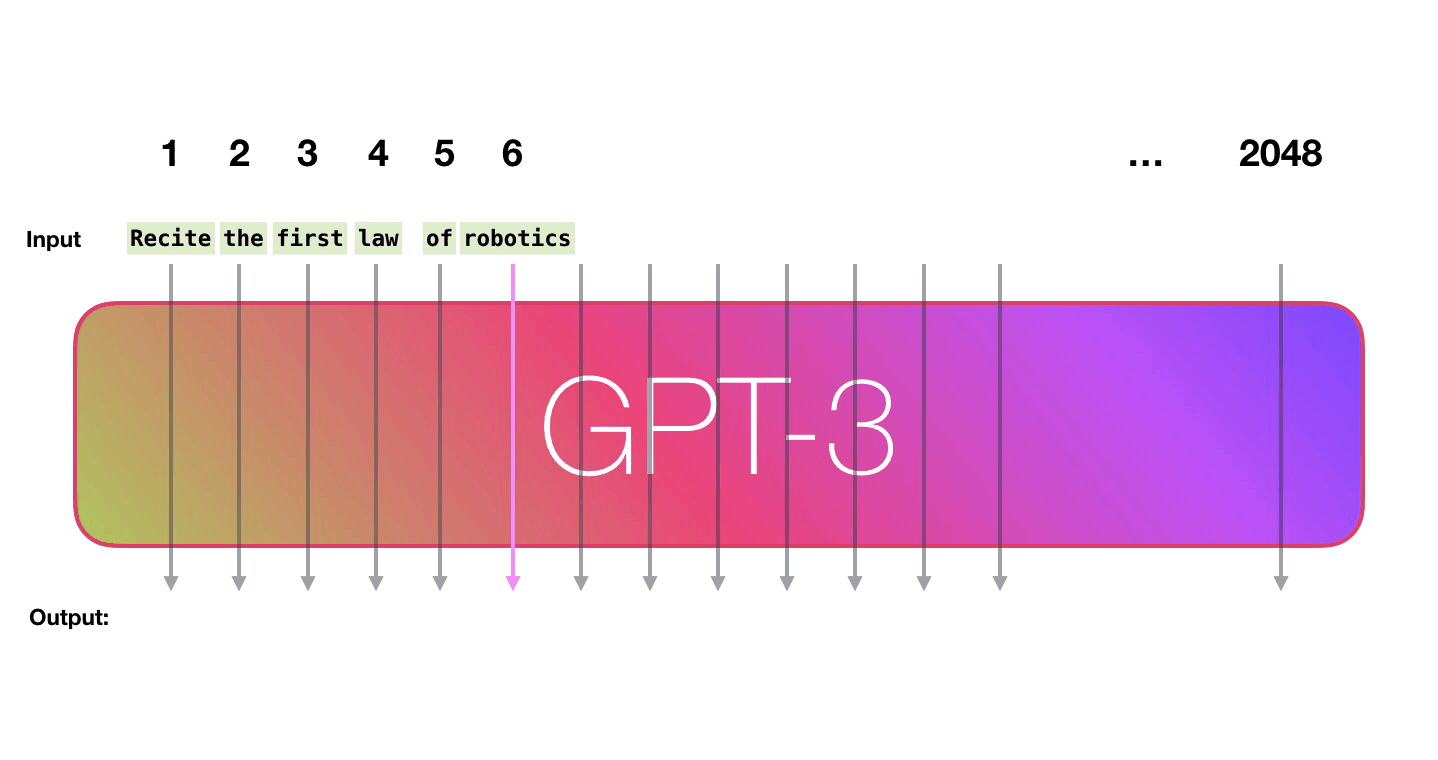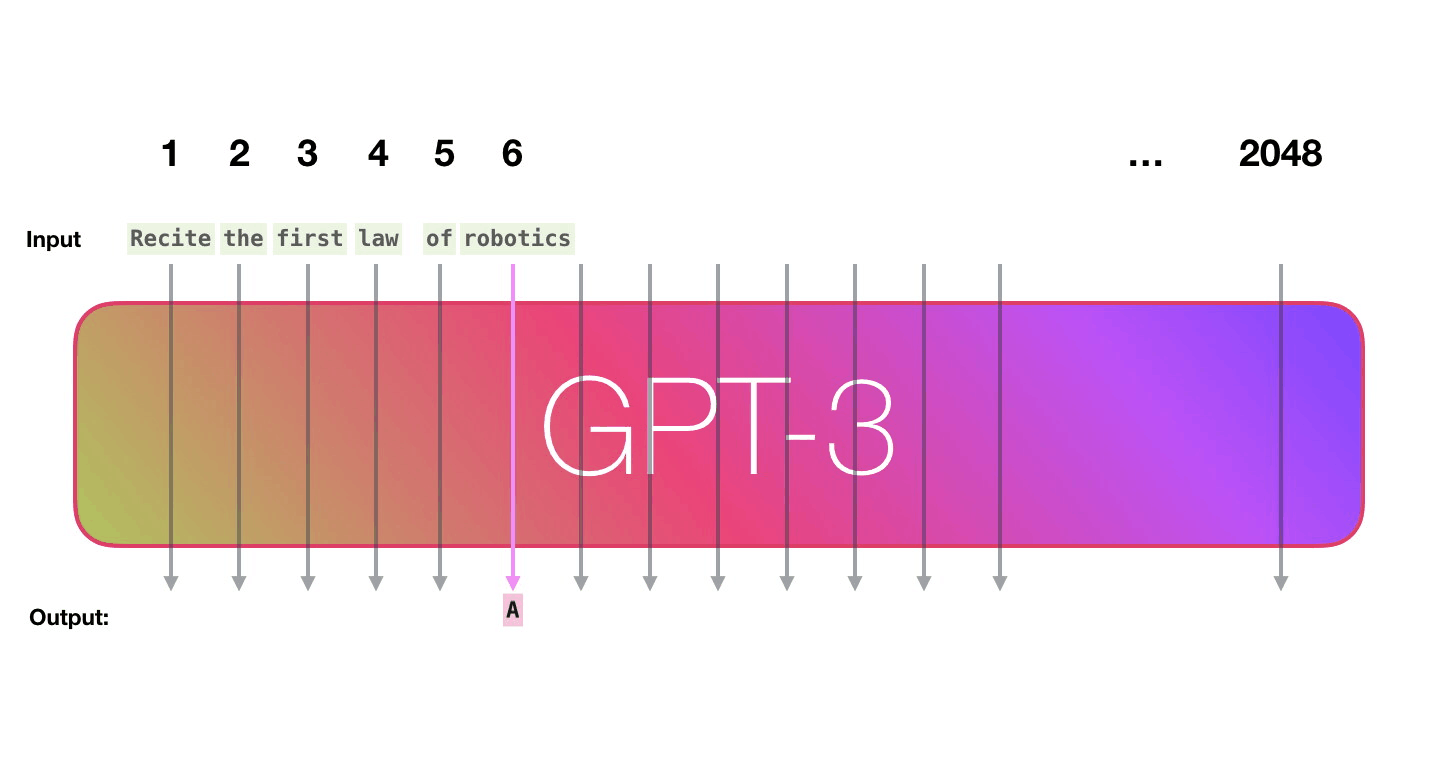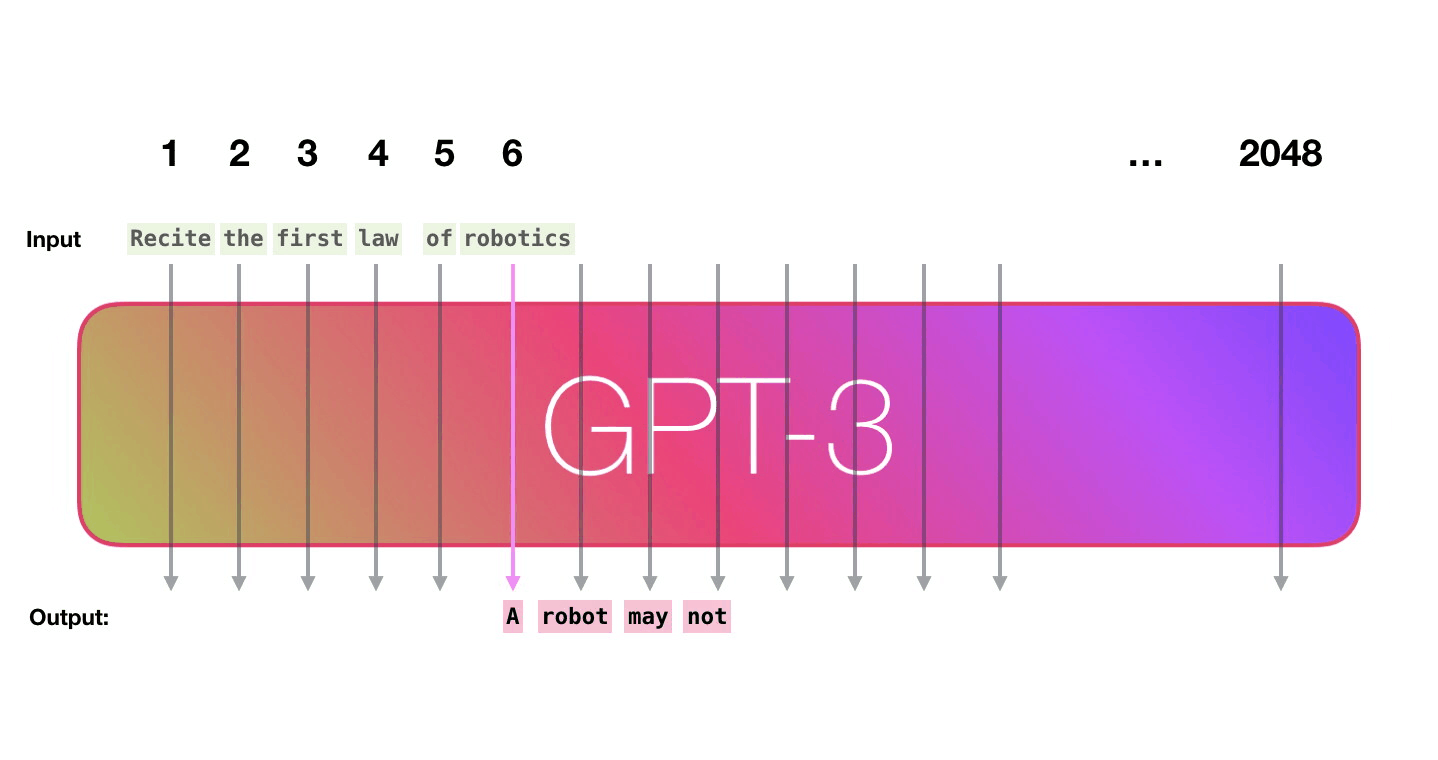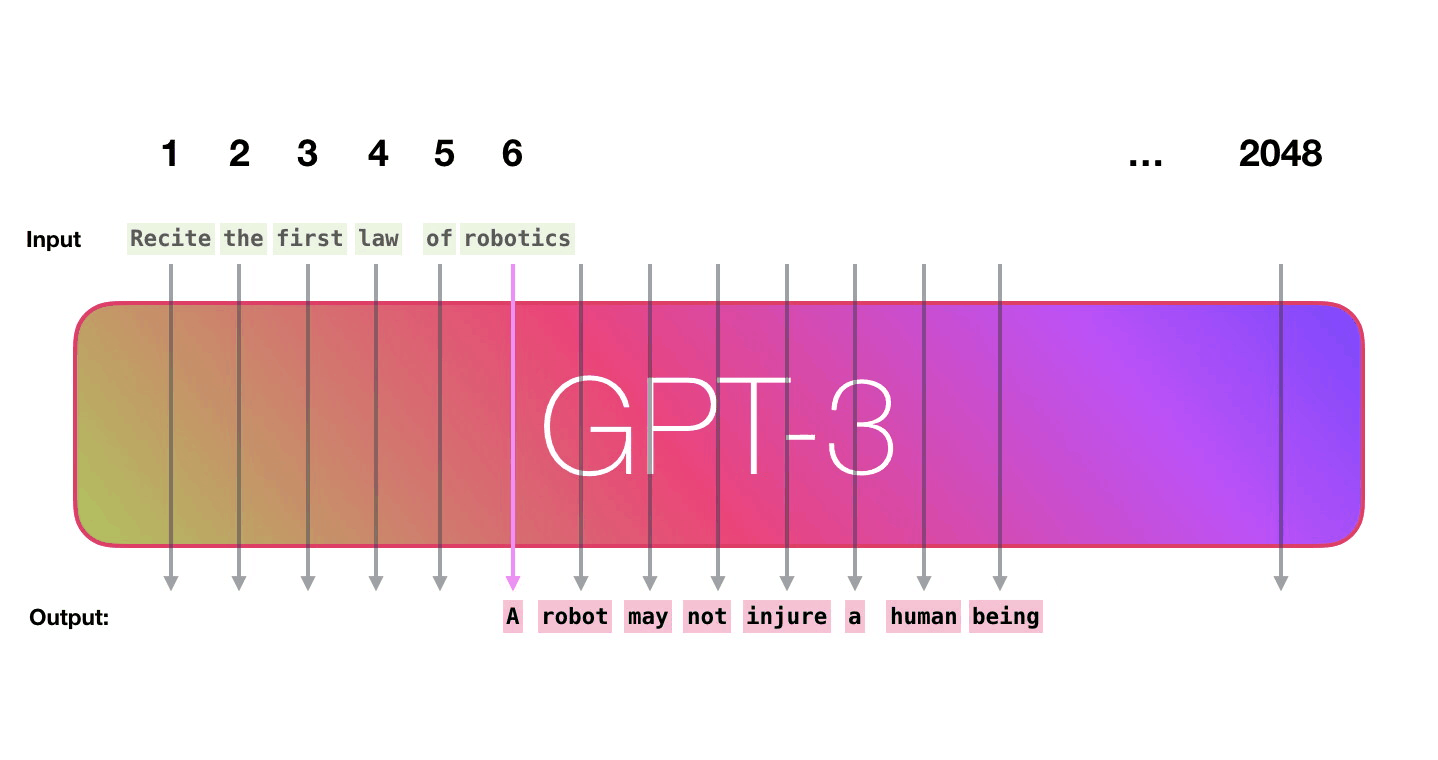
Давайте пройдем по фиолетовой траектории. Как система обрабатывает слово «robotics» и генерирует «A»?
Высокоуровнево шаги выглядят так:
- Преобразование слова в его векторное представление (набор чисел).
- Вычисление предсказания.
- Преобразование полученных векторов в слово.
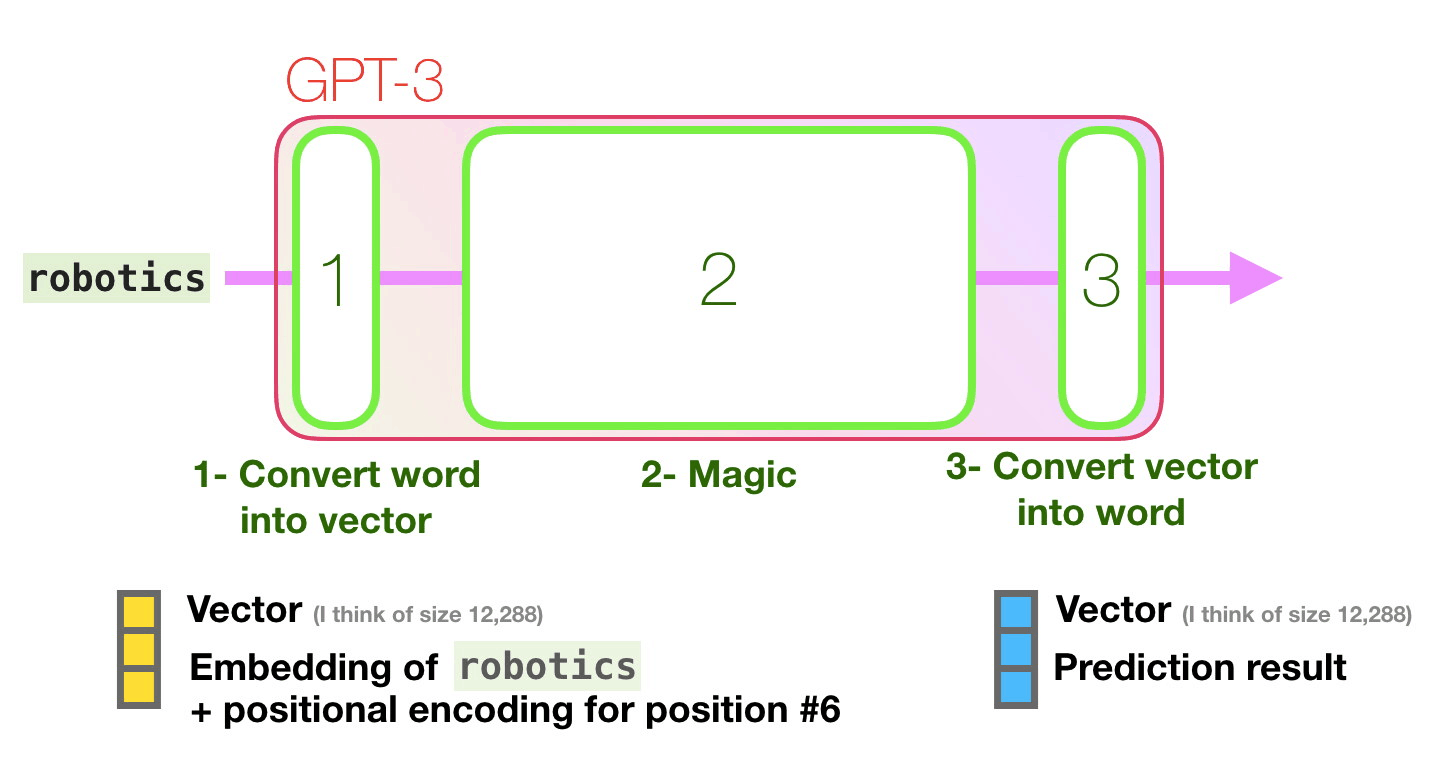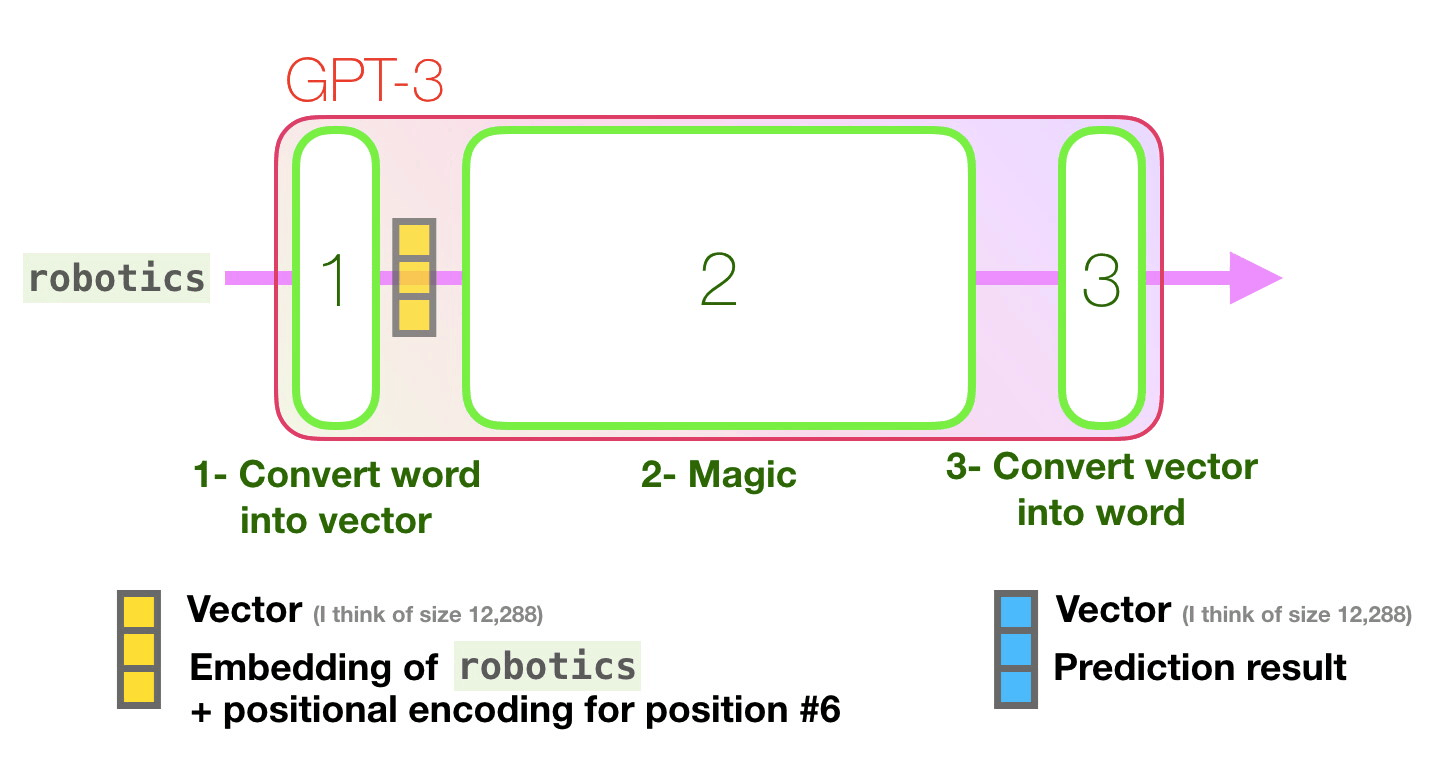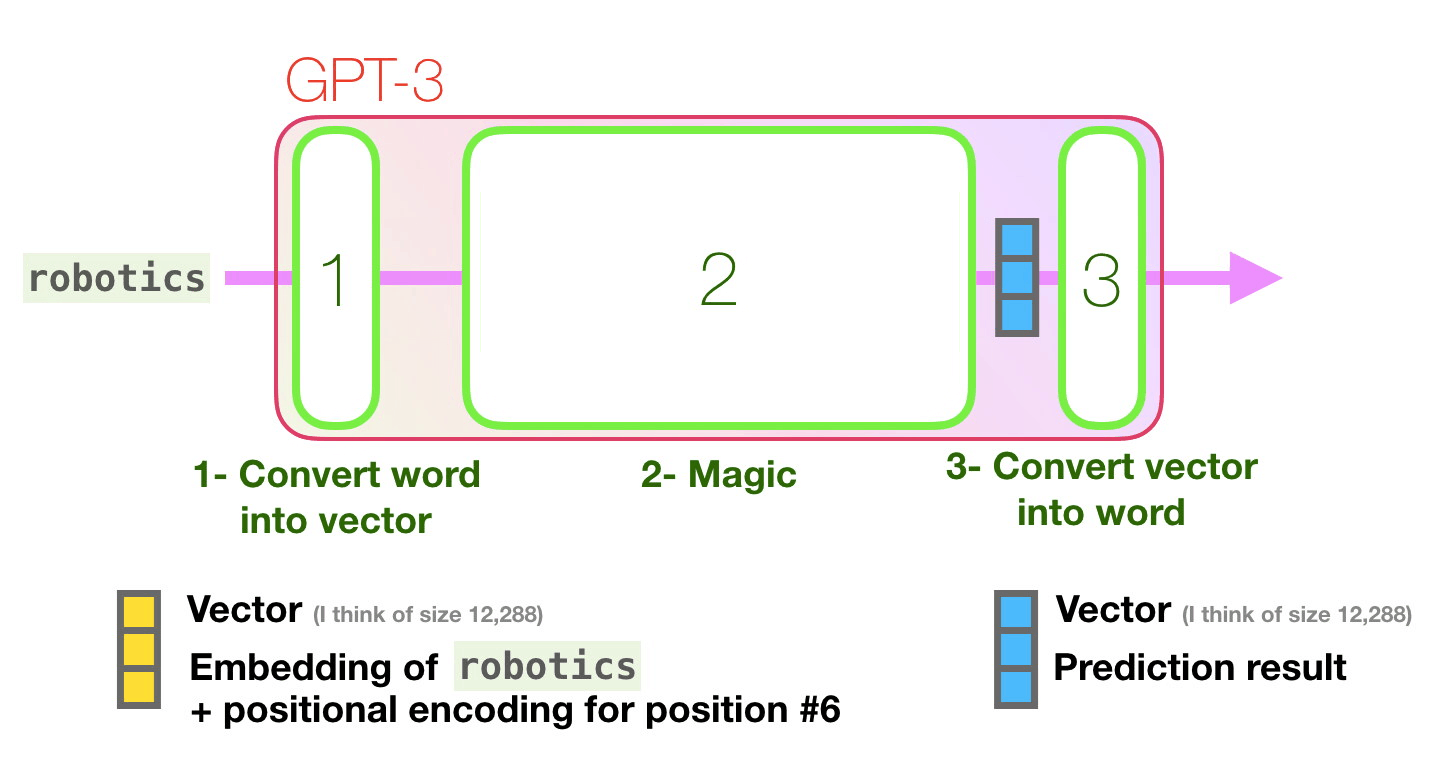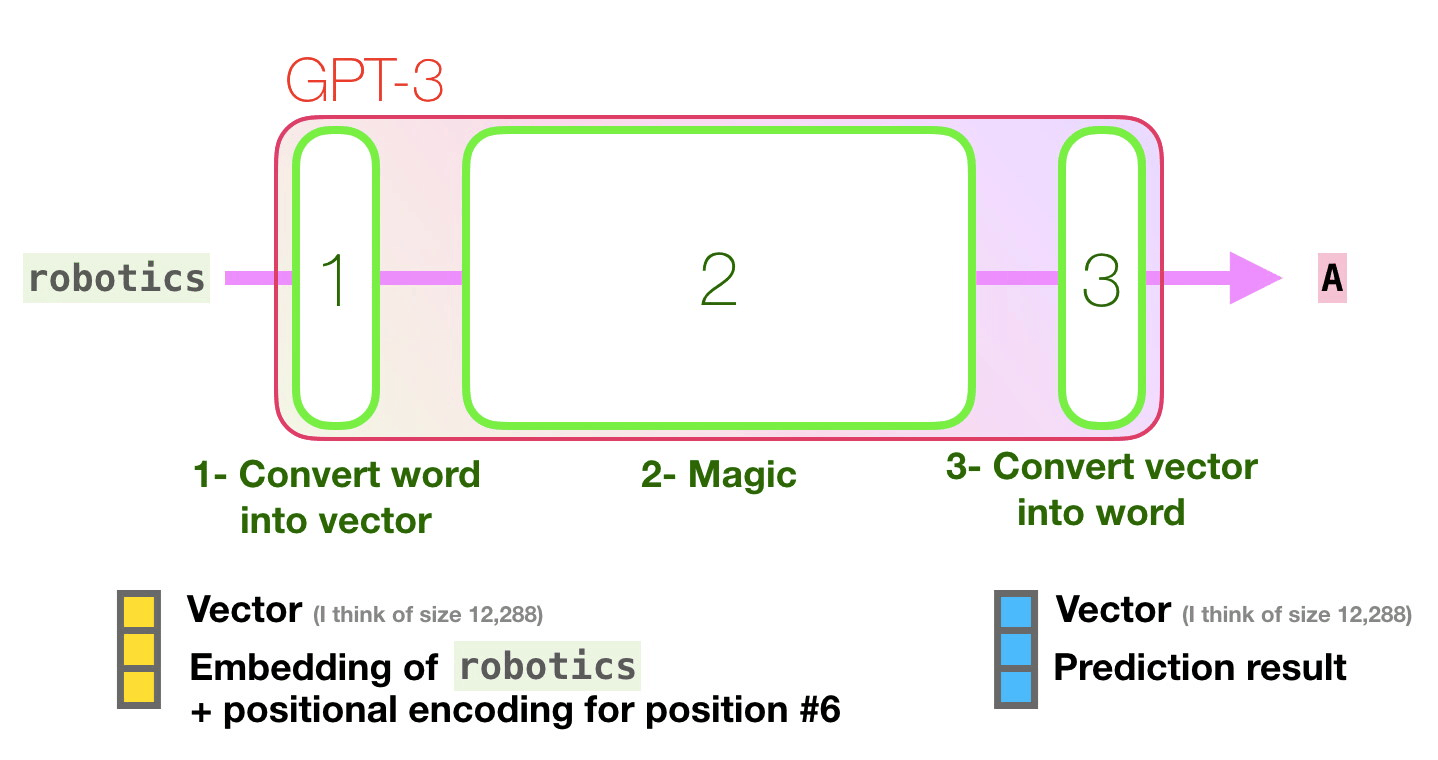
Важные вычисления GPT-3 происходят внутри стека из 96 слоев декодера Трансформера.
Видите все эти слои? Это и есть та самая «глубина» «глубокого обучения» (deep learning).
У каждого слоя есть свои 1.8 миллиардов параметров для вычислений. Здесь и происходит вся «магия». Верхнеуровнево этот процесс можно изобразить следующим образом:
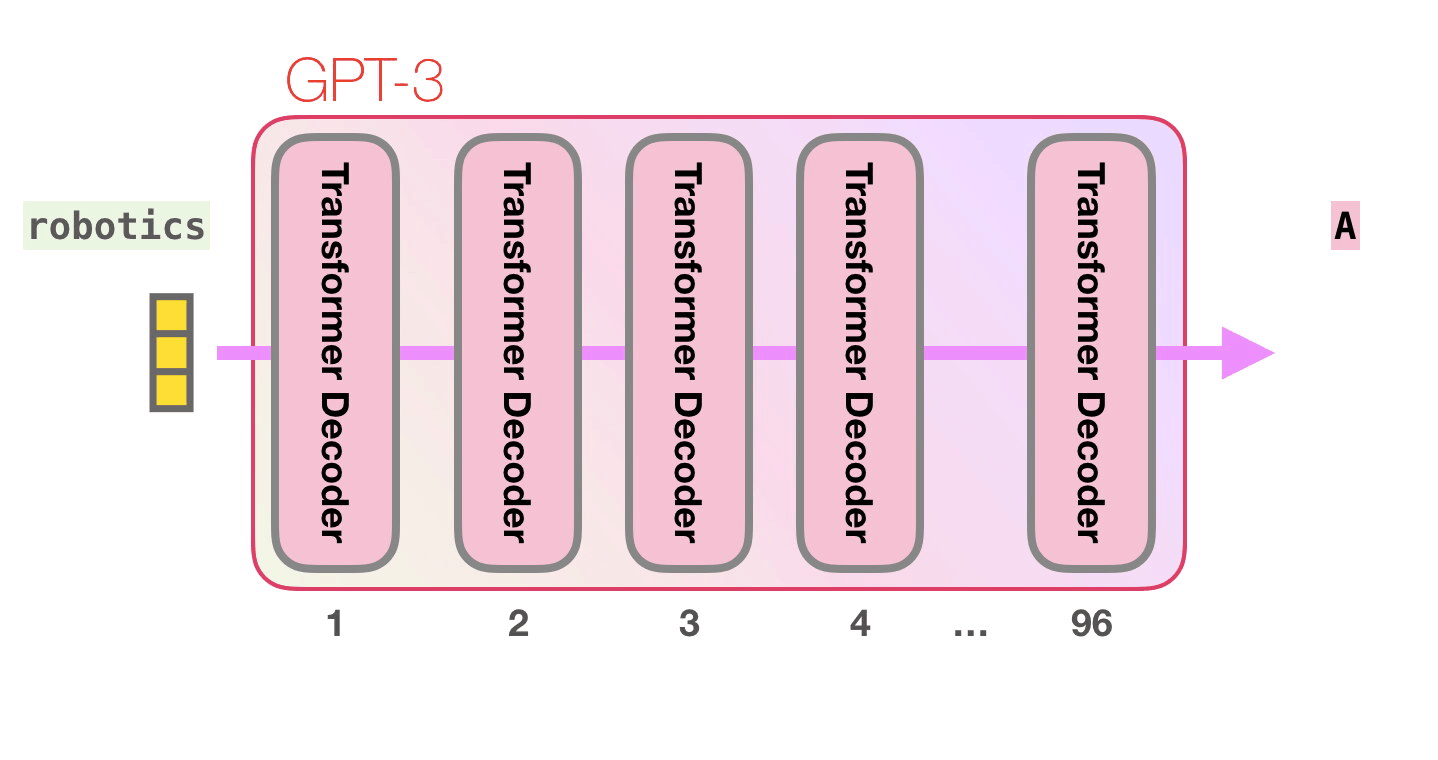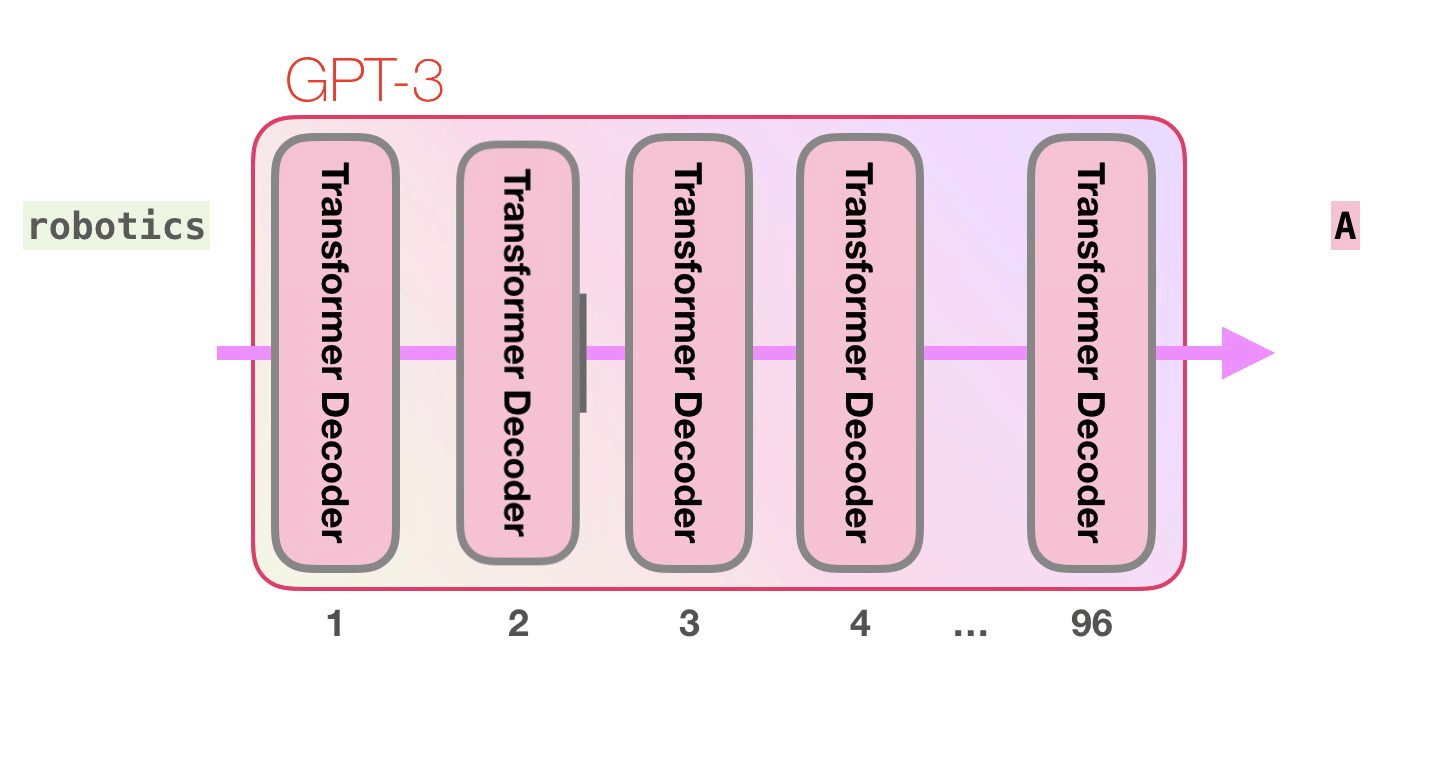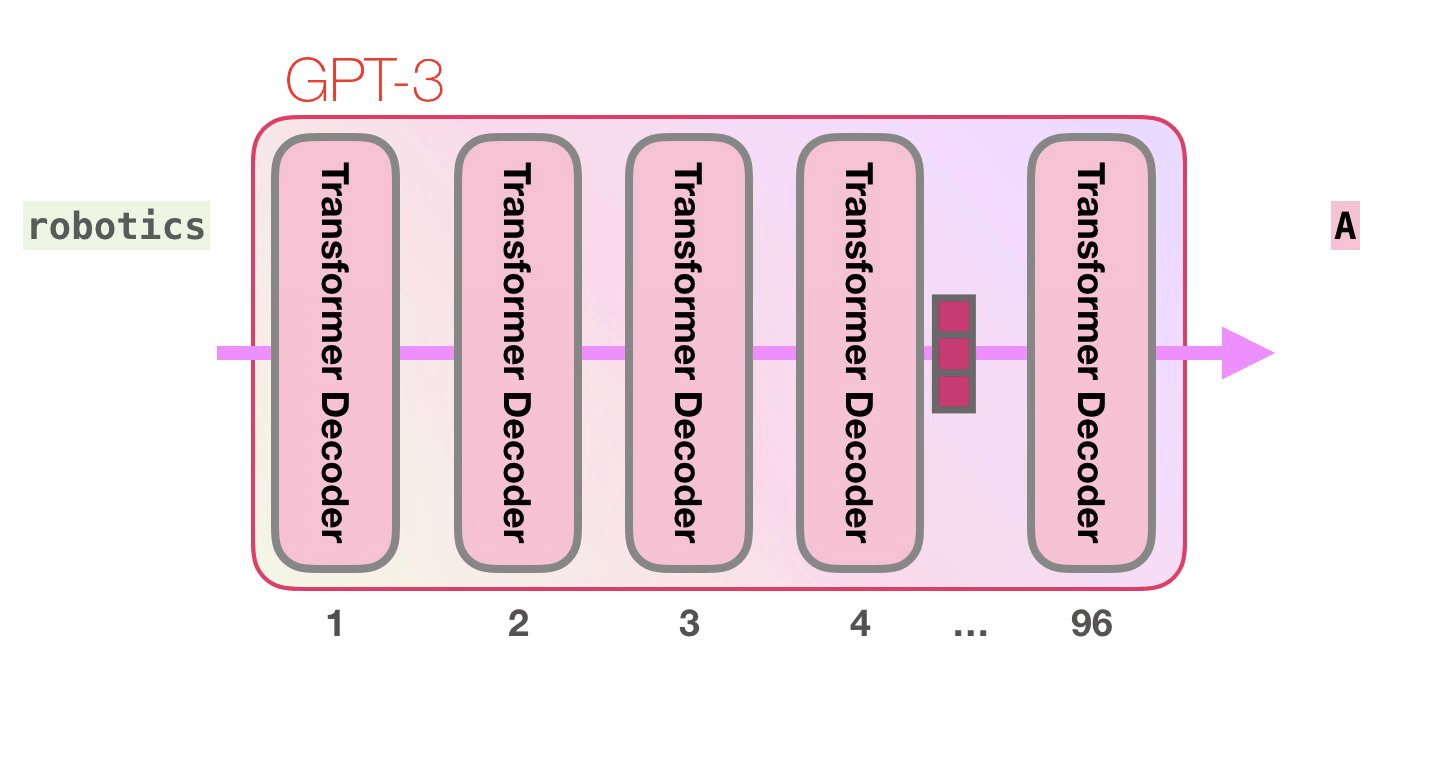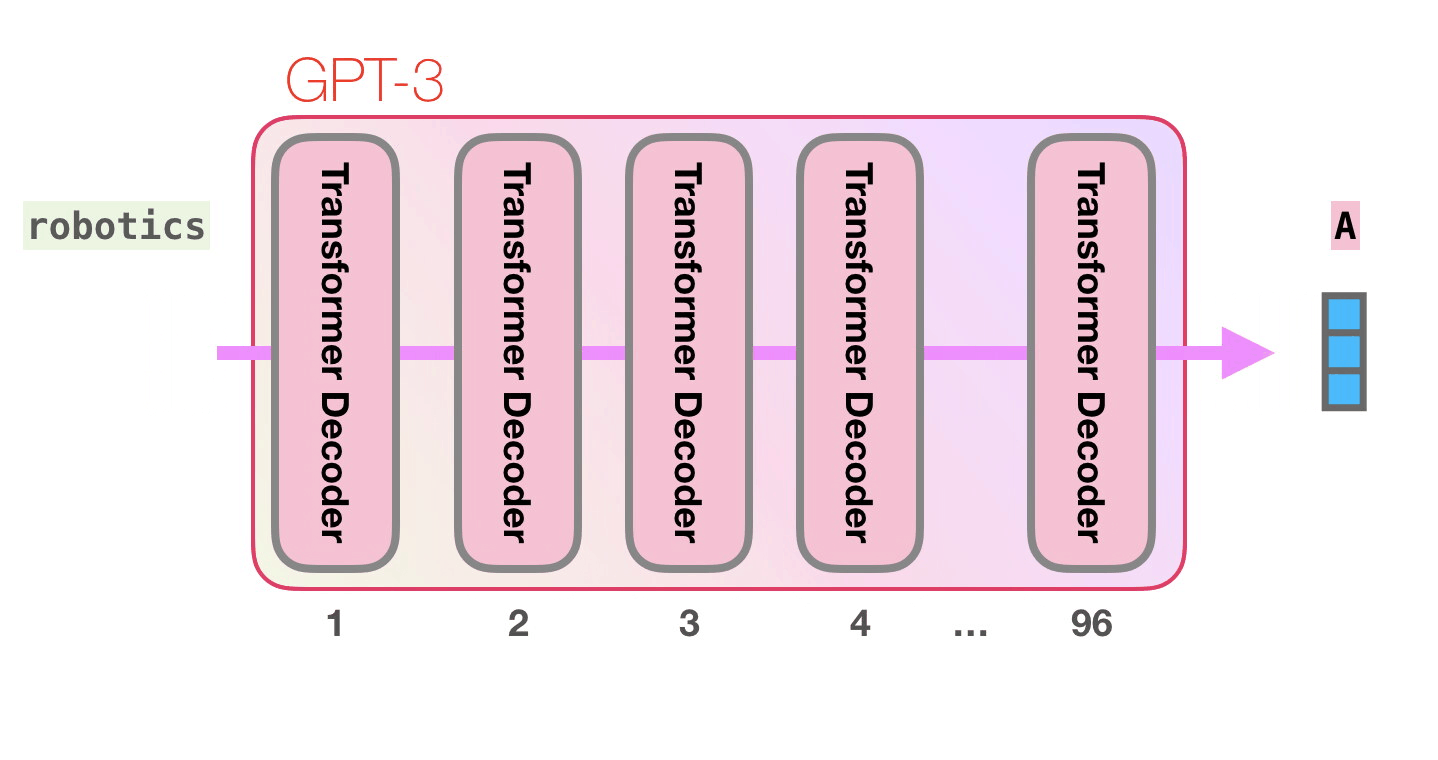
Вы можете увидеть детальное описание всего, что происходит внутри декодера, в статье GTP-2 в картинках.
Отличие GPT-3 состоит в изменении плотных (dense) и разреженных (sparse) слоев внутреннего внимания (self-attention).
Рассмотрим подробнее пример ввода предложения и вывода ответа «Okay human» внутри GPT-3. Обратите внимание, как каждый токен проходит через все слои стека. Нам не важен выход для первых слов: он начинает иметь значение, только когда ввод окончен. Далее мы отправляем слова выхода обратно в модель.
В примере генерации React кода на вход подается описание (выделено зеленым), по всей видимости, в дополнение к нескольким примерам вида описание => код. Затем код React генерируется точно так же, как и розовые токены здесь, один за другим.
Можно предположить, что начальные примеры и описания были добавлены на вход модели вместе со специальными токенами, отделяющими примеры от результата.

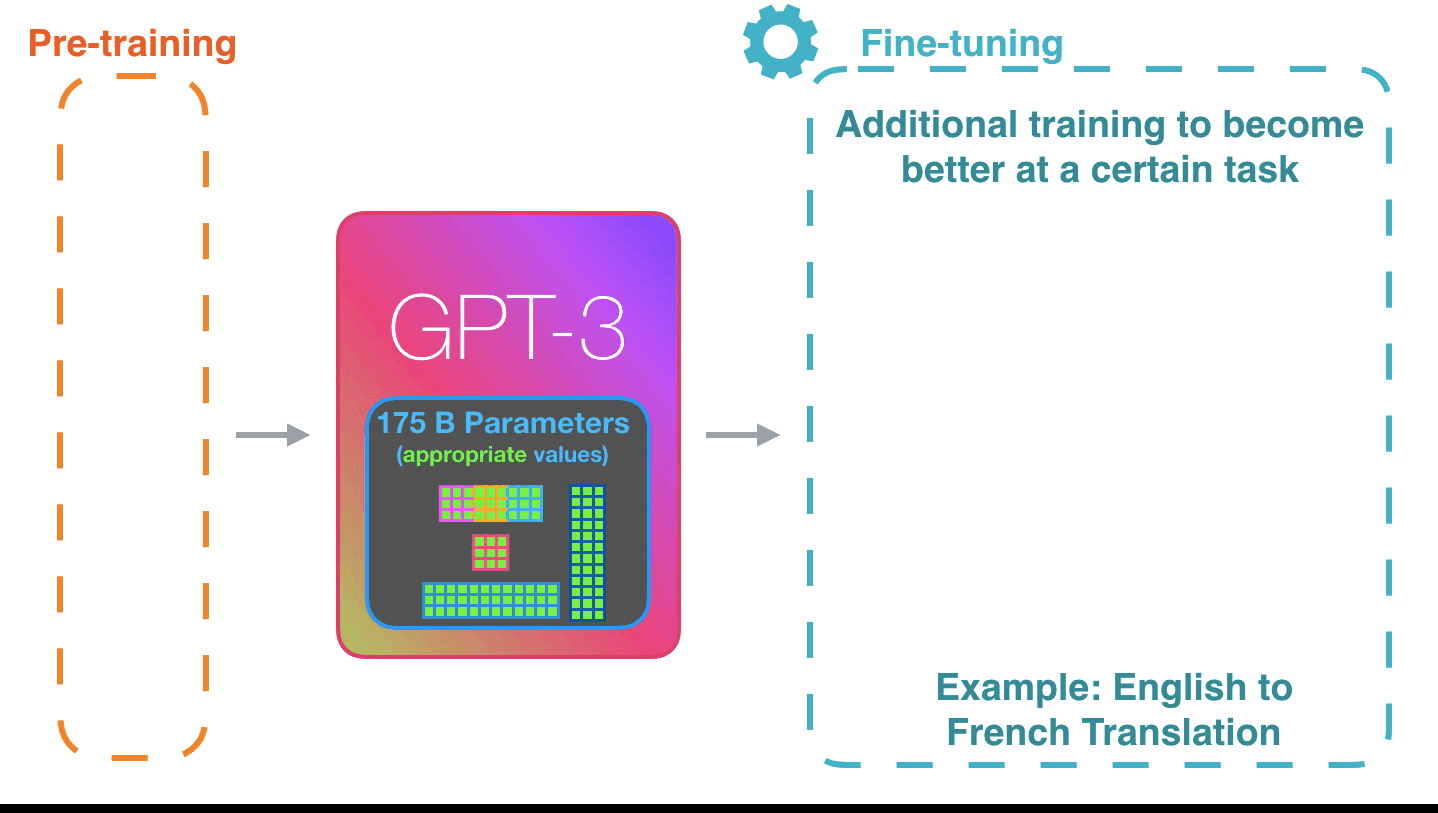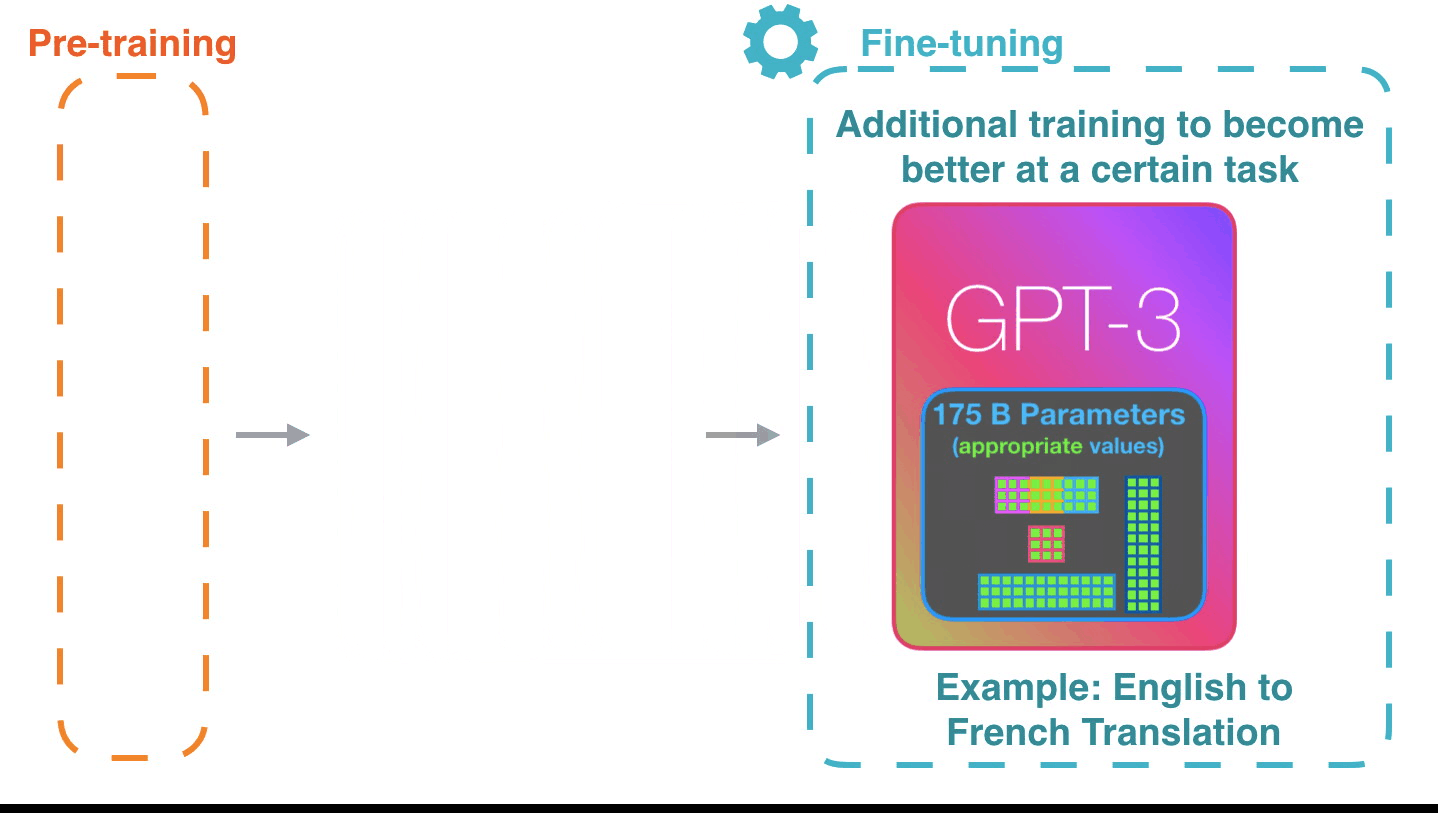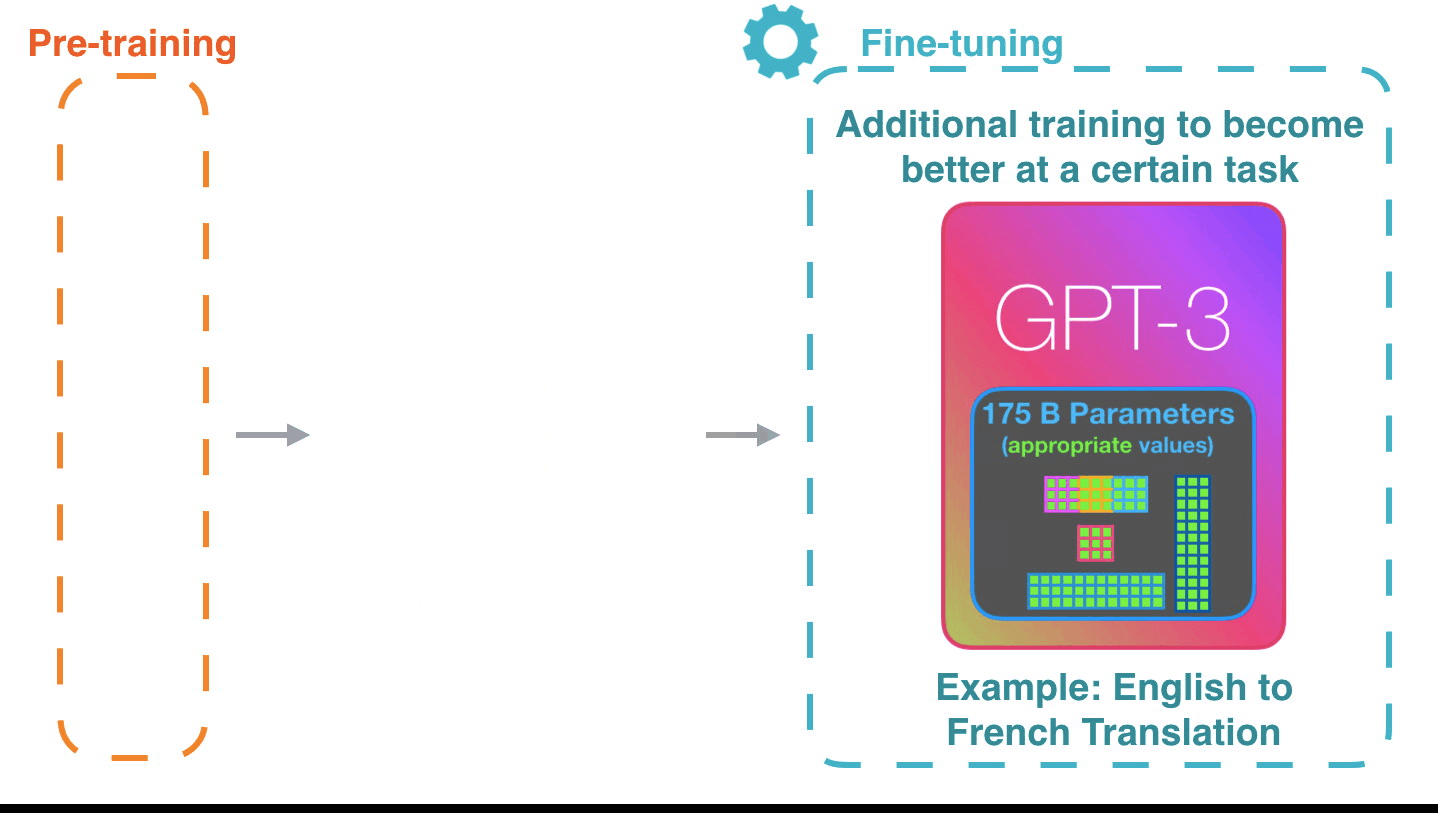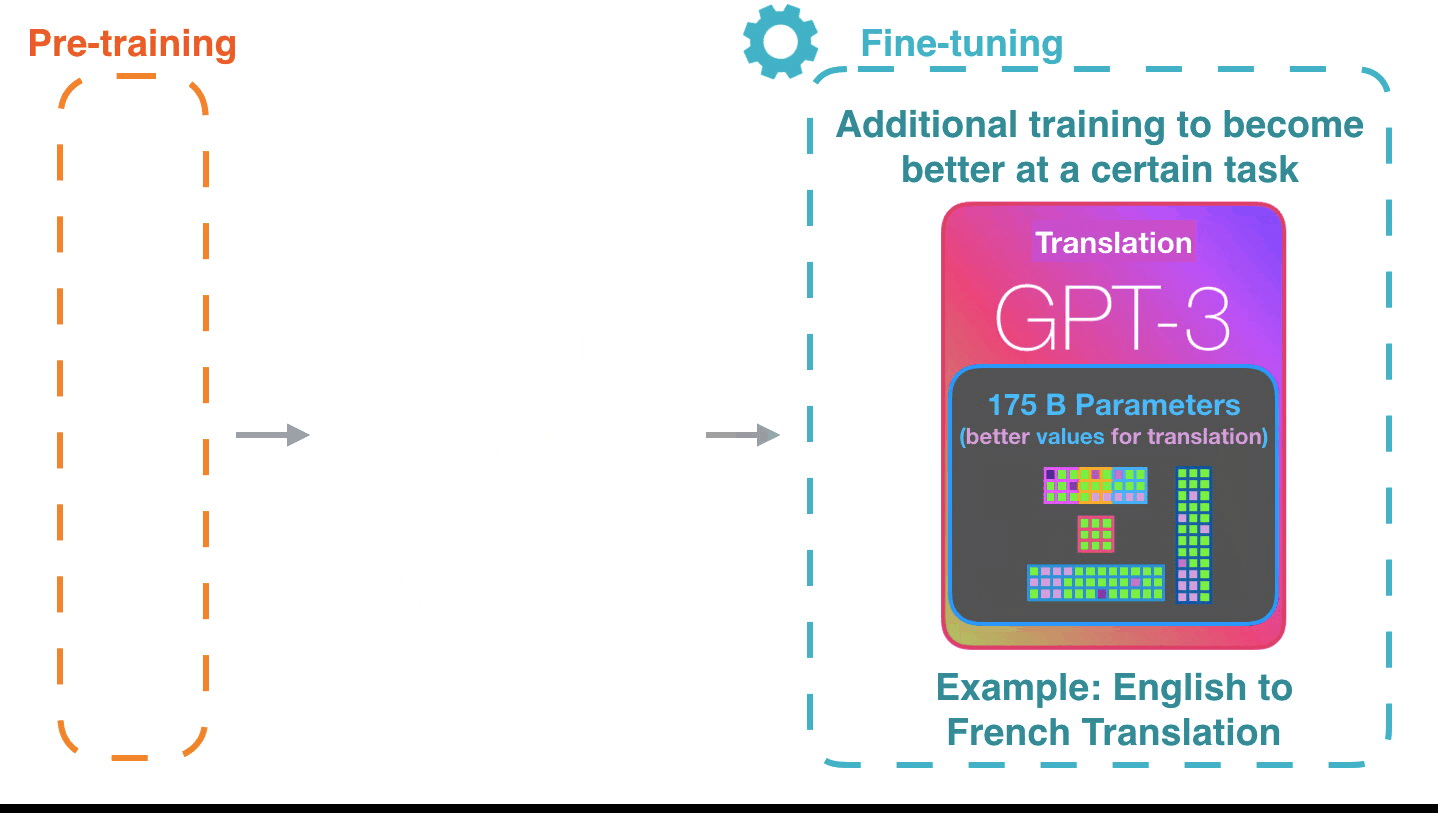
То, как это работает, впечатляет. Вам просто нужно подождать, пока завершится тонкая настройка (fine-tuning) GPT-3. И возможности буду еще более потрясающими.
Тонкая настройка просто обновляет веса модели для того, чтобы улучшить ее результат для конкретной задачи.
Авторы
- Автор оригинала – Jay Alammar
- Перевод – Смирнова Екатерина
- Редактирование и вёрстка – Шкарин Сергей

