Основная цель второй части — это детально исследовать феномен массового рисования (выдумывания) результатов голосования на конкретных примерах.
Как и в первой части, все вычисления, визуализации и парсинг данных приведены в Google Colab, который доступен по этой ссылке Google Colab.

Почему важно массово анализировать данные выборов?
Массив из 95 тыс. строк с данными голосования является очень дорогим в прямом и переносном смысле.
Во-первых, стоимость голосования составляет около 14 млрд. рублей.
Во-вторых, минимальные затраты по времени (избирателей и организаторов) для генерации результатов голосования составляют 78 млн. человеко-часов или 8.8 тыс. человеко-лет.
Плюс результаты голосования будут опосредованно влиять на нашу жизнь в течение долгого времени.
Несмотря на важность этих данных, доступ к небольшой части данных в машиночитаемом формате есть лишь на ресурсах RUElectionData и в базе движения "Голос". Извлечь исторические данные голосований с сайта ЦИК без черного пояса по парсингу невозможно. Национальная инфраструктура с открытым кодом для хранения и контроля качества данных выборов всех уровней отсутствует.
Автоматизация процесса видеонаблюдения средствами компьютерного зрения — еще одна из важных, но нерешенных задач. В данное время ассоциации наблюдателей проводят ручной пересчет явки по видео и сверку их с данными ЦИК. Возможно, IT навыки читателей могли бы как-то улучшить ситуацию.
В свое время, проект “Диссернет” привлек внимание к проблеме фальсификаций (плагиата) диссертаций и смог искоренить это явление посредством общественного внимания. Подобное может произойти с массовыми фальсификациями выборов, если анализ данных голосования будет доступен и понятен каждому и риски для рядовых исполнителей окажутся неприемлемыми.
По мотивам действий “Диссернета” была создана комиссия РАН по противодействию фальсификации научных исследований, которая регулярно выпускает отчеты посвященные фальсификациям диссертаций. Комиссии РАН по фальсификации выборов пока еще не создано. Какой из этих двух феноменов несет больший общественный вред, сказать сложно.
Основные результаты:
- Найдены ТИКи, в которых есть большие кластеры одинаковых значений явки или результата. В число аномальных попали 327 ТИКов или 19 тысяч УИКов, на которые приходится 25 млн. зарегистрированных избирателей или 19 млн. проголосовавших.
- Изучен феномен “рисования” результата голосования по заранее заданным процентам. Приведены множество примеров из изучаемого голосования и из международных выборов, таких, например, как выборы президента Сирии в 2014 году и Крымского референдума в 2014 году.
- Приведено сравнение избытка целочисленных результатов по сравнению с президентскими выборами 2000-2018 годов.
Основной целью данной заметки является анализ результатов голосования с целью выявления аномальных случаев голосования используя третью цифру результата или явки. Оказывается, что в сотнях ТИКов проценты после округления до десятых долей процента образуют кластеры идентичных результатов. Вероятность естественного образования таких кластеров в практическом смысле равна нулю. Данный метод отвечает на вопрос как конкретно рисуются результаты.
Графики с аномальными ТИКами сохранены в архиве.
На примерах это выглядит так:
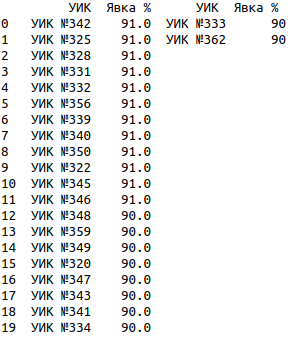
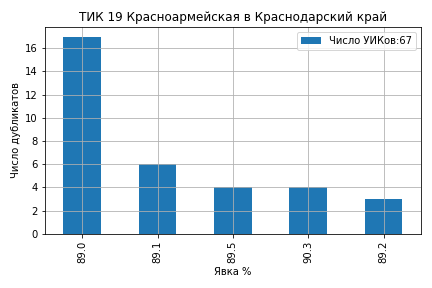
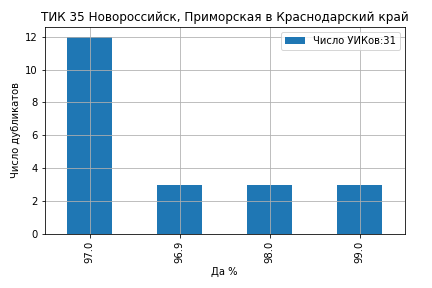
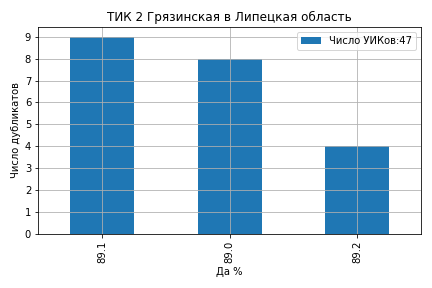
На ТИК 10 Дятьковская из 46 участков на 12 участках явка составила ровно 91.0 и на 10 участках ровно 90.0 (ссылка на страницу ЦИК):
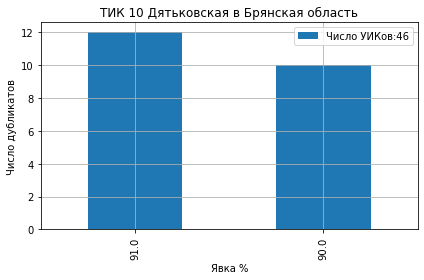
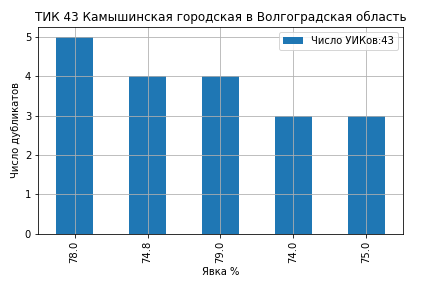
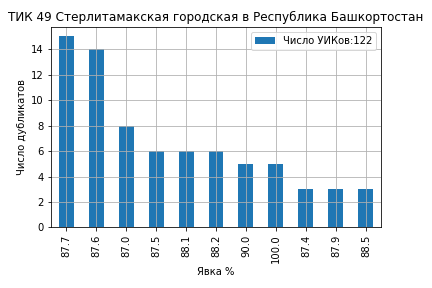
На ТИК 43 Камышинская из 43 участков явка образовала кластеры на значениях 79%, 78%, 75%, 74.8% и 74% (ссылка на страницу ЦИК):

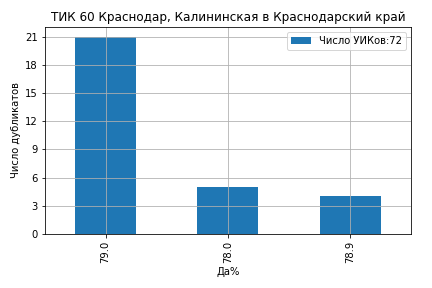
На ТИК 60 Краснодар, Калининская из 72 участков 21 участок проголосовал 'Да' ровно 79.0%, 5 участков ровно 78.0% и 4 участка 78.9% (ссылка на страницу ЦИК):

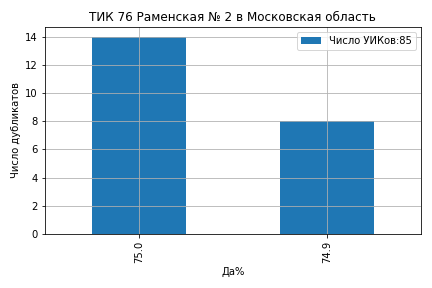
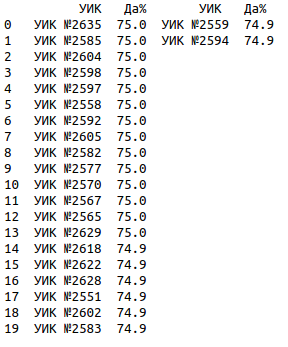
На ТИК 76 Раменская № 2 из 85 участков 14 участков проголосовали 'Да' ровно 75.0% и 8 участков ровно 74.9% (ссылка на страницу ЦИК):
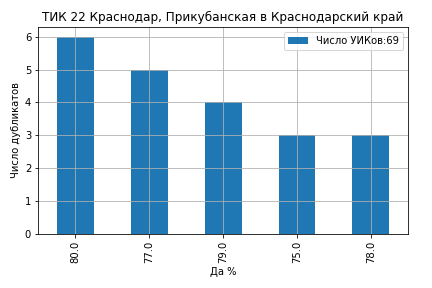
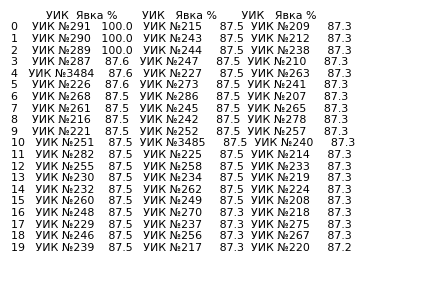
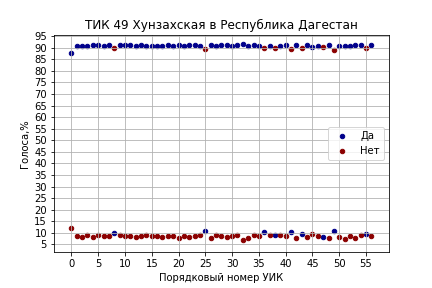
На ТИК 22 Краснодар, Прикубанская все значения кластеров голосов ‘Да’ оказались целыми числами 80%, 79%, 78%, 77% и 75% (ссылка на страницу ЦИК):




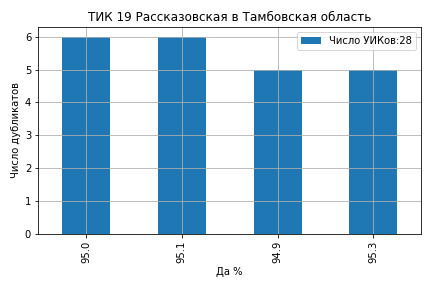

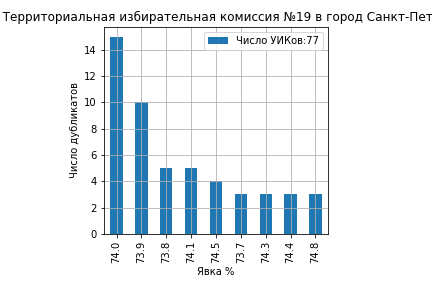
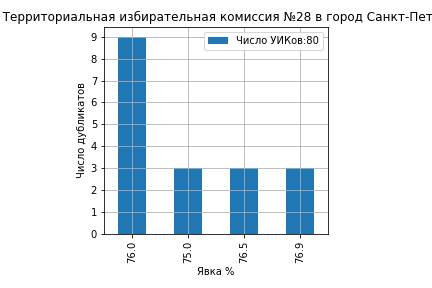
В первой части мы отметили, как сотрудники образовательных учреждений в Клинцах нарисовали явку, которая зависела от четности номера УИКа. Как остроумно заметили в комментариях, не исключено, что это был сигнал SOS посланный будущим исследователям российских выборов.
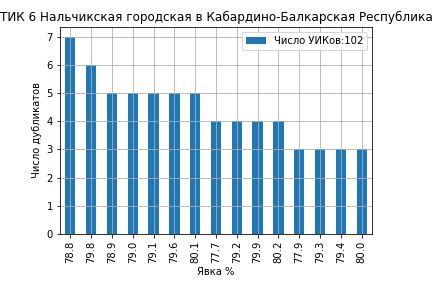
В дополнение приведем еще один интересный случай, где специалисты по квантовой физике в г.Нальчике впервые применили процедуру (вторичного) квантования результатов и что из этого получилось (ссылка на страницу ЦИК):
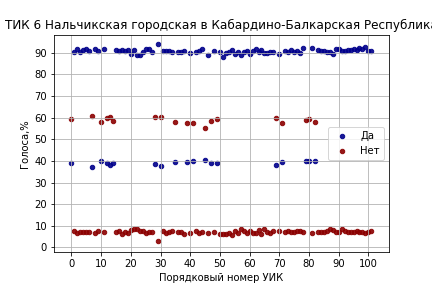
Другие специалисты, по-видимому, перепутали куда писать 'Да' и 'Нет' на части участков (ссылка на страницу ЦИК):
Перейдем теперь к техническим деталям кода.
Детектирование аномальных кластеров
После округления до одной десятой процента, значения явки или результата принимают вид 71.1% или 85.6%. В каждом ТИКе я ищу совпадающие результаты (duplicates) и записываю число совпадений в дата-фрейм ds. Совпадающие элементы учитываются только если их больше или равно параметра min_n_duplicates, который по умолчанию равен трём. Также я вычисляю полное число совпадающих элементов total_duplicates по которому можно будет выделять аномальные ТИКи. Все это делает функция get_duplicates:
def get_duplicates(dq,col_name='yes_pct',min_n_duplicates=3): ds=pd.DataFrame(dq[col_name].values.round(1), columns= [col_name]).groupby(col_name).size().to_frame('size') ds=ds[ds['size']>=min_n_duplicates].sort_values(ascending=False,by='size') total_duplicates=ds['size'].sum() ds.reset_index(level=0, inplace=True) return total_duplicates,ds
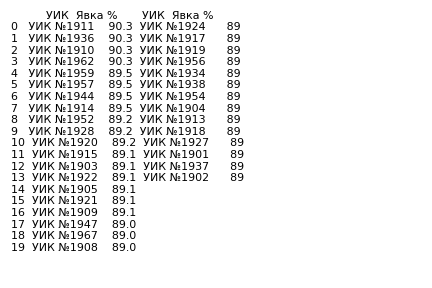
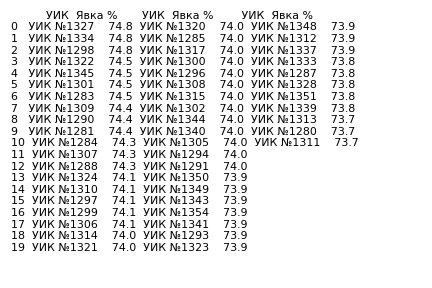
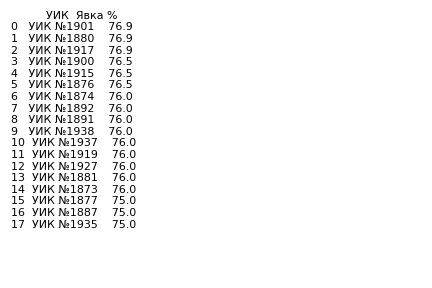
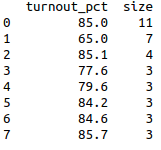
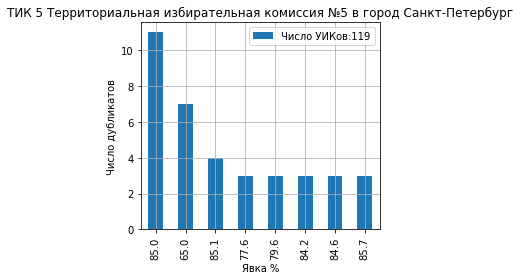
Пример ds для ТИК 5 Территориальная избирательная комиссия №5 в Спб (size число УИКов с одинаковыми результатами явки (дубликатов) в кластере):
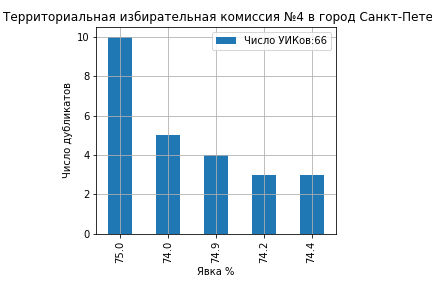
или в графической форме:
Далее я выявляю дубликаты в каждом ТИКе и оставляю только результаты с вероятностью образования не более 0.1%, что приблизительно соответствует ошибке при дактилоскопии. Дата-фрейм dr с результатами можно сортировать по следующим параметрам: полному числу УИКов с совпадающими (хотя бы три раза) результатами total_duplicates, проценту УИКов с дубликатами от полного числа УИК в данном ТИКе pct_duplicates или вероятности возникновения кластеров prob_duplicates.
Модель для оценки вероятности кластеров
Для развития математической интуиции построим простую и, возможно, весьма грубую модель оценки вероятностей появления кластеров совпадающих результатов.
Допустим, каждый УИК внутри одного ТИКа может показывать с равной вероятностью результат внутри интервала 5%. Данное предположение является весьма консервативным, так как среднее стандартное отклонение явки УИКов внутри одного ТИКа на всех данных равно 9%, а среднее стандартное отклонение процента голосов ‘Да’ равно 7%.
После округления до десятых долей процента имеем n_levels=50 значений (10 уровней на один процент). Поэтому если к ТИКу приписано n_stations=40 УИКов и мы наблюдаем, что n_identicals=10 УИКов показывают одинаковый результат, то вероятность данного события можно закодировать следующим образом:
def get_p(n_identicals=10,n_stations=40,n_levels=50): bin_coeff=special.binom(n_stations, n_identicals) prob=bin_coeff*(1/n_levels)**n_identicals* ((n_levels-1)/n_levels)**(n_stations-n_identicals) return prob
Если наблюдаются несколько кластеров, то формула немного усложняется и биномиальные коэффициенты заменяются на мультиномиальные коэффициенты. Так можно посчитать вероятность возникновения произвольного числа кластеров c помощью функции get_prob_duplicates:
from scipy.special import factorial def multinomial_coeff(c): return factorial(c.sum()) / factorial(c).prod() def get_prob_duplicates(duplicates=[10,5],n_stations=40,n_levels=50): n_duplicates=len(duplicates) sum_duplicates=sum(duplicates) coeffs = np.array(duplicates+[n_stations-sum_duplicates]) mc=multinomial_coeff(coeffs) prob=mc*(n_levels-n_duplicates)**(n_stations-sum_duplicates)/ n_levels**n_stations return prob
Подобные задачи хорошо известны в математике игры в покер или кости. Также я провожу несколько численных экспериментов, чтобы подтвердить приведенные формулы.
Оценка по такой схеме работает в среднем, то есть она позволяет довольно хорошо идентифицировать аномальные ТИКи. Я определяю ТИК как аномальный, если модельная вероятность возникновения наблюдаемых кластеров меньше чем 0.1%.
Для каждого конкретного случая можно рассмотреть внимательно и при необходимости изменить параметры, такие как n_levels или n_stations, если значения явки или результата находятся не в одной окрестности, а образуют удаленные друг от друга группы.
Анализ третьей цифры результатов
Методы нулевой дисперсии и аномальных кластеров относятся к прямым доказательствам “рисования” результата выборов.
Теперь рассмотрим косвенные методы выявления аномалий. Методы основанные на анализе распределения частоты значений третьей цифры результатов давно используются и хорошо изучены исследователями выборной статистики.
После округления явки и результата до третьей цифры (numpy.round(1)), она может принимать значения от 0 до 9. Далее применим функцию plot_first_digit которая быстро сделает всю работу за нас и нарисует распределение третей цифры. Так выглядят некоторые результаты:

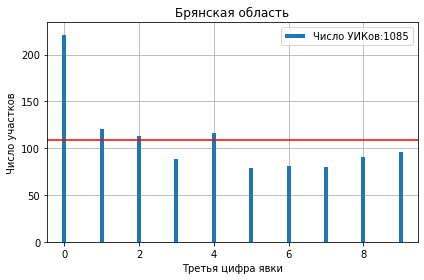
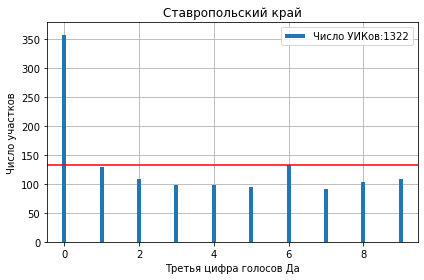
Налицо аномальное количество нулей.
Большинство фальсификаторов по старинке используют калькуляторы и счёты где удобнее оперировать целыми числами.
Эти же аномалии можно изучить еще одним способом.
Выделим дробную часть голосов ‘Да’ или явки с помощью преобразования x-np.floor(x) и построим гистограмму получившегося распределения:
yes_pct.apply(lambda x: x-np.floor(x)).hist(bins=25,grid=True)
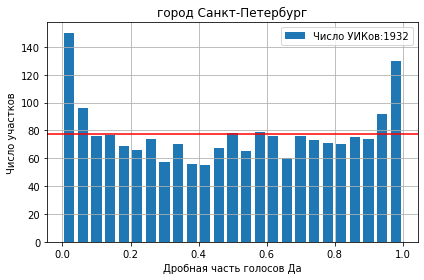
Налицо аномальное число результатов близких к целочисленным процентам.
Можно также применить округление до ближайшего целого с помощью преобразования x-np.round(x) и построить гистограмму получившегося распределения:
yes_pct.apply(lambda x: x-np.round(x)).hist(bins=25,grid=True)
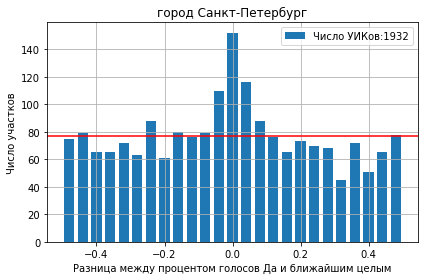
Давайте попытаемся понять, что означают полученные результаты. Видно, что на втором графике хвосты распределения собрались в центре и образовали колоколообразное распределение (не путать с дискуссией о гауссовости распределения явка-результат!). Это чистая ошибка округления результатов выведенных по заранее заданным значениям.
Начав с заранее заданной явки 82.0% (как это теоретически может происходить можно посмотреть на примере соседнего государства с похожим состоянием выборной системы), можно получить число проголосовавших путем умножения явки на число зарегистрированных избирателей N=1021. Получается дробное число 0.82*1021=838.2, которое надо округлить до 838. Поэтому итоговой явкой становится число 838/1021=81.97%.
Каждое такое округление дает погрешность, которая равномерно распределена на интервале ±1/(2N) со средним значением в нуле. Далее, надо усреднить по всем УИКам с разным число избирателей. Число УИКов с небольшим количеством избирателей больше чем очень больших УИКов. Это объясняет форму колоколообразного пика на последнем графике.
Отмечу еще один интересный способ как можно получить данные без аномалий, но с фальсифицированным результатом. Надо лишь провести честное голосование и полученный результат ‘Да’ заменить на 100%-’Да’. Такой способ дешев и прост. В отсутствие института наблюдателей, он не обнаруживается статистическими методами и весьма эффективен для дезориентации оппонентов.
Рисование результатов, основанное на заранее заданных процентных результатах
При нормальном процессе голосования первичными являются цифры пришедших проголосовать и число бюллетеней за того или иного кандидата. После голосования из этих чисел выводятся проценты явки и процент поддержки победителя. В нарисованных результатах все происходит ровно наоборот. Первичным являются заранее заданные или выдуманные проценты и из них выводятся числа голосов.
Таким способом, например, были нарисованы выборы президента Сирии 2014 года, референдумы в ДНР и ЛНР в 2014 году, выборы в ДНР в 2014 и референдум о статусе Крыма, который был проведен 16 марта 2014. Детально все вышеупомянутые случаи разобраны в колабе. Также данный метод применялся в республике Беларусь.
В среде исследователей выборов этот метод получил кодовое название “Калькулятор”.
Чтобы понять, как это работает, рассмотрим идеальный пример результатов президентских выборов в Сирии, которые прошли 3 июня 2014 года. Согласно wikipedia имеем:
Башар аль-Асад: 10 319 723 (88,7%)
Хасан ан-Нури: 500 279 (4,3%)
Махер Хаджар: 372 301 (3,2%)
Зарегистрированные голоса: 15 845 575
Всего проголосовало: 11 634 412
Недействительные голоса: 442 108 (3,8%)
Итак:
Учитывая общее количество избирателей примерно 10 млн, один человек соответствует 0,00001%. Это означает, что результат 88.70000% имеет вероятность ~ 1/10000.
Результат Башара Асада 10 319 723/11 634 412 100=88.70000 %
Результат Махера Хаджара 372 301/11 634 412100=3.10000 %
Количество недействительных голосов 442 108/11 634 412*100=3.80000%
Все три результата имеют вероятность естественного происхождения (1/10000)^3 = 10^(-12).
Рассмотрим теперь данные референдума о статусе Крыма, который был проведен 16 марта 2014 (wikipedia).
Всего зарегистрированных избирателей: 306 258
Всего поданных голосов: 274 101
Выбор «Вступить в Российскую Федерацию»: 262 041
Число избирателей 274 101 из общего числа зарегистрированных избирателей 306 258 — 274101/306258 = 89.500%, а отношение количества «за» 262041 к количеству действительных голосов 274 101 равно 95.600%.
Снова мы видим, что все дробные цифры, начиная со второй цифры ТОЧНО равны нулю.
Учитывая общее количество избирателей ~ 300 000, один человек соответствует менее 0,001%. Это означает, что вероятность получить случайно 89,500% и 95,600% составляет (1/100)^2 = 0.0001, что в 10 раз меньше вероятности ошибки 0.001 при дактилоскопии.
Оценка числа целочисленных аномалий методом Монте-Карло.
Приведем еще один более строгий способ оценки степени нарисованности выборных данных. Для каждого УИКа в значение числителя явки (пришедших проголосовать) или относительное число ‘Да’ (голоса “Да”) вносится небольшое возмущение. Затем методом Монте-Карло вычисляется ожидаемое значение числа УИКов с целочисленными результатами или явкой. Далее это сравнивается с числом целочисленных УИКов в данных голосования. Число аномальных УИКов — это разница между вторым и первым значением.
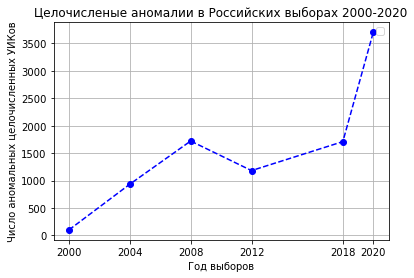
Видно, что аномальность данных находилась на нулевом уровне в 2000 году и аномальность результата 2020 года превзошла 2008 год почти в два раза.
Оценка аномалий по сообщениям наблюдателей
Статистические методы изученные выше могут доказать наличие аномалий в данных выборов. К сожалению, оценка полного числа аномальных голосов возможна только в рамках моделей, которые в свою очередь опираются на предположения. Проверить верность этих предположений не всегда представляется возможным, что приводит к неразрешимым спорам о применимости этих моделей.
Наилучшим методом оценки аномальных голосов является сравнение данных наблюдателей с данными ЦИК. Если посмотреть на исторические данные, то разброс результатов выборов в каждом отдельном регионе невысок. Это говорит о том, что достаточно небольшого количества (добросовестных) наблюдений для установления полной картины. В практическом смысле, при наличии массовых аномалий это лучший метод из всех доступных нам.
Аномальные голоса можно разделить на три типа: вброс голосов, перепись голосов в пользу лидера и чисто придуманные результаты.
Сравнение данных наблюдателей с данными ЦИК традиционно позволяло оценить как величину вброса, так и переписки голосов. При анализе расхождений часть регионов показывала чисто вертикальное смещение в координатах процент лидера-явка, что соответствовало переписыванию голосов от одного кандидата к другому. В других регионах преобладала тенденция диагонального смещения результатов, что соответствовало вбросам.
Из-за растянутости референдума число участков, где наблюдение покрыло как досрочное голосование, так и основной день крайне ограничено. Много детальных отчетов можно почитать у наблюдателей Петербурга или у отдельных наблюдателей из Татарстана.
Мы используем несколько известных случаев, где наблюдение велось все дни голосования для того, чтобы выяснить возможный масштаб отклонений. Если у вас есть дополнительные примеры, вы можете скорректировать сказанное ниже.
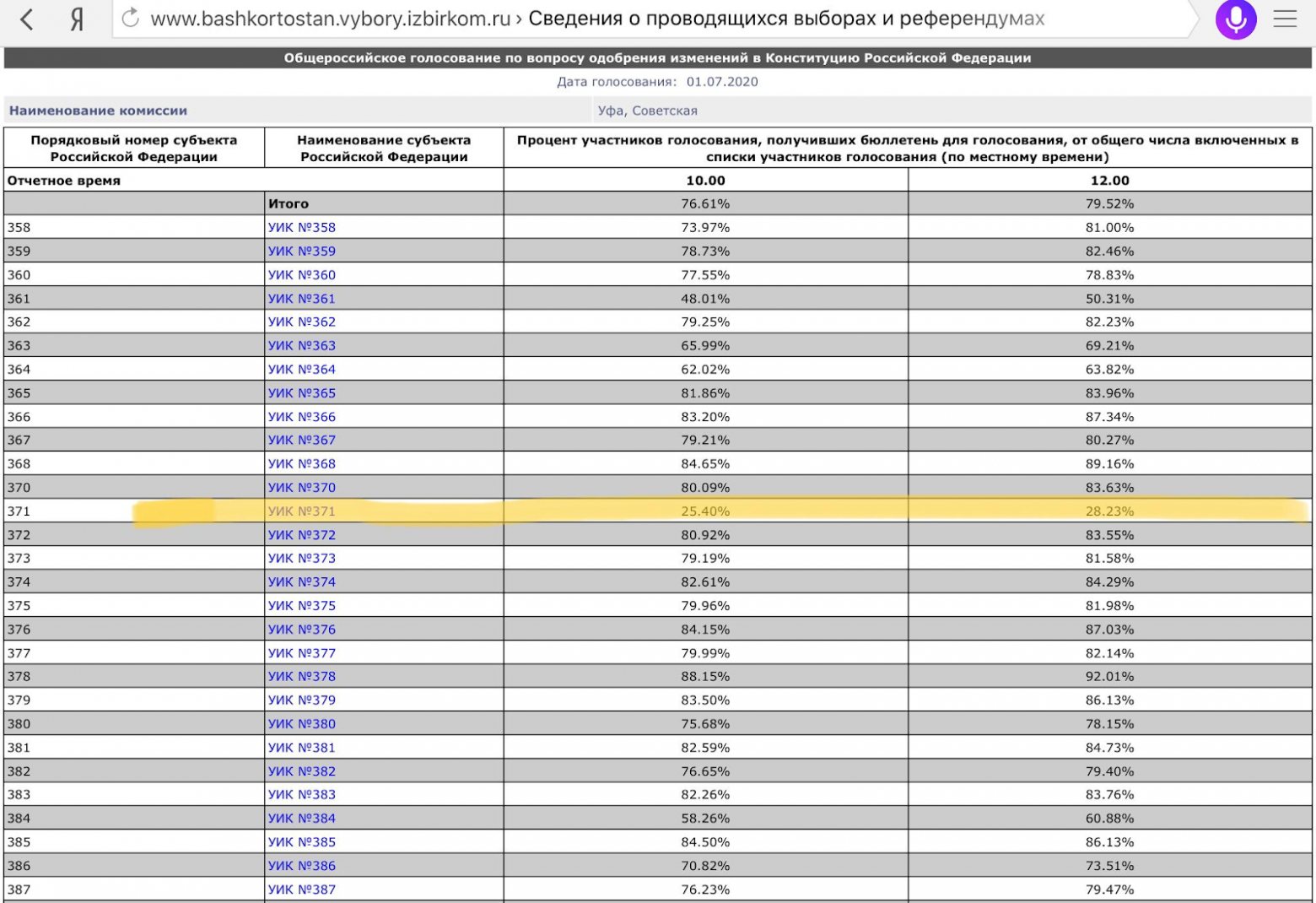
Пример 1: Разница в явке порядка 50% между УИК 371 г. Уфа и соседними участками не покрытыми наблюдателями (cсылка на источник)
Пример 2: УИК 260 из ТИК 33 Казань, Ново-Савиновская (страница ЦИК) был полностью покрыт наблюдателями и нарушений не было. На УИК 259 они были минимальны.
Результаты № 259 (явка 32%, "Да" 50.79%, "Нет" 48.37%),№ 260 (33, 44.48, 55.11 соответственно)
Аномальную явку можно рассчитать как разницу между средним по ТИКу (64.84%) и явкой на УИК 260 (33.5%). Аномальная явка=64.8%-33.5=31%.
Аномально также и то, что на все участки, кроме УИКа 259 и 260 (обведены в круг) проголосовали одинаково и досрочно, а в основной день голосований никто не пришел.

Пример 3: По данным ЦИК, явка на участке Краснодарский край ТИК Гулькевичская УИК 1108 ссылка на страницу ЦИК составила 850/1219=70%.
Согласно видео отчету наблюдателя, явка составила 482/1219=40%. Итого, аномальная явка =70-40=30%. На видео, начиная с 7.36, наблюдатель говорит дословно «Не дали подсчитать. Подсчёт не производился. Цифры были вымышленные».
Приведенные примеры не дают точную картину, но позволяют понять возможный порядок отклонения опубликованных результатов от не наблюдаемой (для нас) истиной явки. Видно, что расхождение с официальными данными явки в 30% или 50% не является чем-то невероятным и при такой разнице поправки на репрезентативность из-за различий город/село, средний доход и других факторов являются величинами второго порядка. Важно отметить, что вброс или переписка голосов на большом количестве УИКов является весьма трудоемкими делом и вряд ли бы приводило к детерминистическим паттернам, которые мы наблюдали ранее.
Интересный вопрос также состоит в том, зачем нужны космические результаты в 80 или 90 процентов и почему победа с 55 процентным результатом воспринимается как слабость и закат системы. На ум приходит фраза из недавнего сериала “Чернобыль”:"Our power comes from the perception of our power".
Технически грамотно к проблеме наблюдения подошли IT специалисты из Беларуси, создавшие две площадки за наблюдением на выборах Зубр и онлайн-платформу Голос. Лозунгом Зубра стал слоган "Важно, как считают".
Исторические примеры также подчеркивают важность контроля над подсчетом голосов: «Не важно, как проголосуют, а важно то, как посчитают» Наполеон III; "Я считаю, что совершенно неважно, кто и как будет в партии голосовать; но вот что чрезвычайно важно, это — кто и как будет считать голоса» Сталин; «Вы выиграли выборы, а я — подсчет голосов» Анастасио Сомоса.
В России существовала аналогичная система СМС-ЦИК.
Заметим, что наблюдатели ранее могли оценивать только явку, но не процент проголосовавших за того или иного кандидата. Оригинальное решение нашли в Беларуси, где пришедшим голосовать за альтернативных кандидатов предлагалось надевать какой-нибудь опознавательный знак (белый браслет), что позволяло наблюдателям оценить также и результат голосования.
Где происходило появление аномальных голосов?
Если быть кратким и руководствоваться логикой и наблюдаемыми фактами, то под подозрение попадает прежде всего досрочное голосование.
Если вы немного приуныли от прочитанного и вам в детстве нравился Ильф и Петров, обязательно посмотрите видео рассказ наблюдателя c УИКа № 2236 Центрального района г. Санкт-Петербурга. Там во время подсчета голосов выяснилось, что 99% бюллетеней из урны с досрочного голосования вне помещения для голосования – с отметкой «Да».
Заключение
С фальсификациями действует та же логика что и с тараканами. Если вы увидели одного таракана, значит их на самом деле много. Предлагаю читателю попытаться построить свою модель и оценить полное число тараканов в доме по количеству наблюдаемых тараканов и перенести полученный результат на изучаемую тему.
То, что мы увидели, используя примитивные методы нулевой дисперсии и кластеров идентичных результатов, это только вершина айсберга. Его основание достоверно известно лишь стороне руководящей процессом подсчета голосов.
Использованные методы можно легко прогнать на массиве исторических данных федеральных выборов в РФ. Вы можете проверить своими руками, что массовое рисование результатов не является феноменом голосования 2020 года, а появилось гораздо раньше.
Возможно, вам удастся найти более интересные паттерны или просто понять, как устроены данные.
Когда данные корректируются руками, неизбежно остаются следы. При наличии открытых данных, простейшие методы математической статистики позволяют найти эти “отпечатки пальцев”. Полное число аномальных голосов можно оценить лишь путем сверки отчетов наблюдателей и официальных результатов.
Важным представляется открытость и доступность данных, а также воспроизводимость результатов анализа. Публикуя две части данной статьи, я преследовал именно эту цель. Если читатель не согласен с выводами или не доверяет математической модели на основе которой интерпретируются данные, то он может построить свою модель, используя приведенные данные и код.

