
Профилактика – наше всё. Грамотная защита от утечек данных поможет предупредить негативные последствия, которые могут повлечь за собой многомиллионные потери. В современном мире каждая из организаций обрабатывает и хранит конфиденциальную информацию. Если речь идёт о крупных организациях, то объёмы конфиденциальной информации огромны. Состояние «безопасности» компьютера – это концептуальный идеал, достигаемый при соблюдении каждым пользователем всех правил информационной безопасности.
Находясь в офисе, любой сотрудник время от времени отлучается от своего компьютера, и тогда включённый компьютер оказывается без присмотра, зачастую с открытыми для доступа папками и файлами, поскольку многие сотрудники попросту забывают блокировать свой ПК, либо же не делают это намеренно, руководствуясь подобной фразой – «отошёл на пять метров, что его блокировать-то!?» К сожалению, такими моментами могут воспользоваться заинтересованные в материалах другие сотрудники.

Как же обеспечить безопасность данных в подобных ситуациях? Одним из способов может быть использование технологий биометрической аутентификации, позволяющих распознавать пользователей по лицу.
Распознавание лиц – понятие далеко не новое, и в настоящее время существует множество инструментов для осуществления данной задачи. Если вы не особо разбираетесь в методах и инструментах для распознавания лиц, то использование библиотеки компьютерного зрения OpenCV (Open source computer vision library) и языка программирования Python станет отличным решением, которое позволит добиться своей цели максимально быстро.

С программными средствами определились, необходимо ещё одно аппаратное – web-камера. Как же теперь настроить распознавание лиц? Для начала лицо на кадре нужно обнаружить. Одним из способов обнаружения лиц является метод Виолы-Джонса (Viola-Jones), который был описан аж в 2001 году. Поскольку нас больше интересует практика, не будем вдаваться в теоретические подробности, упомянем лишь, что в основе метода лежат такие основные принципы, как преобразование изображения в интегральное представление, метод сканирующего окна и использование признаков Хаара. Ознакомиться с описанием метода и посмотреть информацию об установке OpenCV можно на официальном сайте. Ниже представим код на Python, который позволит нам обнаруживать лица с видеопотока web-камеры:
import cv2 as cv import numpy as np face_cascade = 'haarcascade_frontalface_default.xml' cam = 1 classifier = cv.CascadeClassifier(face_cascade) video_stream = cv.VideoCapture(cam) while True: retval, frame = video_stream.read() gray_frame = cv.cvtColor(frame, cv.COLOR_BGR2GRAY) found_faces = classifier.detectMultiScale(gray_frame, 1.2, 5, minSize=(197, 197)) for x, y, w, h in found_faces: cv.rectangle(frame, (x, y), (x + w, y + h), (255, 0, 0), 2) cv.namedWindow('Stream', cv.WINDOW_NORMAL) cv.imshow('Stream', frame) k = cv.waitKey(30) & 0xFF if k == 27: break video_stream.release() cv.destroyAllWindows()
В коде выше сначала импортируем два модуля, необходимые для работы: cv2 (компьютерное зрение) и numpy (работа с матрицами). В переменной face_cascade сохраняем путь до xml-файла с каскадами Хаара. Этот файл, а также другие, например, для обнаружения глаз можно найти на странице github.
В переменную cam записываем номер web-камеры, если их подключено несколько, номер единственной подключённой камеры по умолчанию 0. Далее создаётся объект классификатора с помощью метода CascadeClassifier и подключение к камере – cv.VideoCapture(cam). Затем в цикле покадрово считываем изображения в переменную frame с помощью метода read(). Классификатор обрабатывает изображение в оттенках серого, поэтому с помощью метода cvtColor преобразуем изображение в нужный вид. Метод detectMultiScale возвращает список с параметрами всех обнаруженных лиц, которые представляет собой прямоугольник – координата вершины (x, y) и ширина и высота прямоугольника (w, h). Следующие строки необязательны для работы программы, но полезны для отладки – метод rectangle добавляет на исходный кадр рамку в месте обнаруженного лица, а imshow – выводит окно с видеопотоком.
Здесь всё довольно просто, а вот дальше интереснее. Теперь нам необходимо распознать лицо. Как это сделать? OpenCV содержит в себе несколько методов по распознаванию лиц, среди которых есть метод LBPH (Local Binary Patterns Histograms). Здесь остановимся поподробнее и немного разберёмся в том, как он работает.
В общем случае берутся значения яркости пикселя изображения и ещё восьми пикселей, окружающих исходный. Получается таблица 3х3 со значениями яркости пикселей. Затем в такую же таблицу записываются 0 или 1. Если значение яркости крайнего пикселя превышает значение яркости центрального, ставится 1, в противном случае – 0. Затем полученный код считывается по часовой стрелке с левой верхней ячейки, переводится в десятичное число, а это число записывается в матрицу, имеющую размеры изображения, в соответствующую позицию. И так для каждого пикселя.
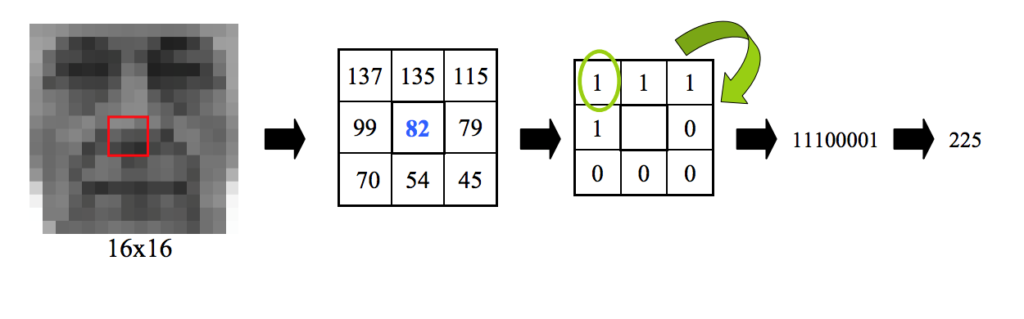
Матрица делится на определённое количество сегментов (по умолчанию это сетка 8×8), для каждого сегмента строится гистограмма, и в конце путём конкатенации гистограмм получается результирующая, характеризующая всё изображение. При распознавании для исследуемого изображения строится такая же гистограмма, которая затем сравнивается с тренировочными данными.
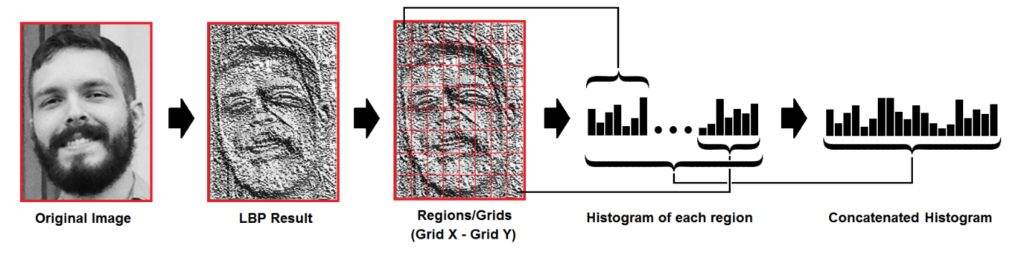
Мы будем использовать именно этот метод, но для начала требуется проделать ещё один важный шаг – создать базу с лицами. Структура базы в общем случае выглядит следующим образом:
--Storage\\ --Person_1\\ --img_1.jpg --img_2.jpg … --img_n.jpg … --Person_m\\ --img_1.jpg --img_2.jpg … --img_n.jpg
Хорошо, база с изображениями лиц у нас есть. Теперь нужно как-то обработать базу для обучения или тренировки алгоритма. Обработка сводится к тому, чтобы сформировать список всех изображений и список id или меток каждого человека. Простейший код для этого действия может выглядеть следующим образом:
storage = 'storage' images = [] labels = [] names = {} id = 0 for subdir in os.scandir(storage): names[id] = subdir.name subdir_path = os.path.join(storage, subdir.name) for file in os.scandir(subdir_path): if file.name.split('.')[-1].lower() not in ['png', 'bmp', 'jpeg', 'gif']: continue file_path = os.path.join(subdir_path, file.name) image = cv.imread(file_path, 0) label = id images.append(image) labels.append(label) id += 1
Здесь тоже всё довольно просто. В переменной storage хранится путь к папке, содержащей папки с изображениями лиц отдельных людей, далее список для изображений, список для меток и словарь с именами. Как это работает: в список изображений добавляются все изображения из папки определённого человека, например, их 15. Если это первая папка из хранилища, то метка будет равна 0, таким образом, в список меток добавляется 0 целых 15 раз, в то же время в словаре имён создаётся запись, в которой ключом является метка, а значением – имя человека (название папки с изображениями конкретного человека). И так для всего хранилища. В выше приведённом коде стоит обратить внимание на строку с методом imread – здесь происходит чтение изображения и представление его в виде матрицы яркостей пикселей, и запись в переменную image.
Теперь самое интересное – тренировка алгоритма:
recognizer = cv.face.LBPHFaceRecognizer_create(1, 8, 8, 8, 130) recognizer.train(images, np.array(labels))
В первой строчке кода мы инициализируем алгоритм с помощью метода LBPHFaceRecognizer_create. Ещё помните описание алгоритма LBPH? Параметры упомянутой функции как раз содержат то, о чём мы говорили: радиус, по границе которого будут браться пиксели, вокруг искомого, количество пикселей из «окружности», образованной радиусом, количество сегментов по горизонтали и вертикали и порог, который влияет на решение о распознавании лица, то есть, чем жёстче требования, тем ниже порог. Далее вызываем метод train для тренировки, передавая в качестве аргументов списки изображений и меток. Теперь алгоритм запомнил лица из базы и сможет распознавать. Дело за малым, осталось добавить несколько строк в первый фрагмент кода в цикл (for x, y, w, h in found_faces): после обнаружения лица нам нужно распознать его, и если лицо не распознано, или распознан другой человек, то немедленно заблокировать компьютер!
roi = gray_frame[y:y+h, x:x+w] name, dist = recognizer.predict(roi) cv.putText(frame, '%s - %.0f' % (names[name], dist), (x, y), cv.FONT_HERSHEY_DUPLEX, 1, (0, 255, 0), 3) if names[name] != "Ivan Petrov": ctypes.windll.user32.LockWorkStation()
В первой строчке roi (от region of interest) – переменная, в которую записываем фрагмент изображения, содержащий обнаруженное лицо. В следующей строке происходит непосредственно распознавание лица при вызове метода predict. Данный метод возвращает метку, соответствующую лицу, которое было распознано и значение, характеризующее степень расхождения обнаруженного лица и распознанного (чем оно меньше, тем выше степень уверенности, что было распознано нужное лицо). Далее, опять же в целях отладки, добавляем в кадр текст с именем распознанного человека с помощью метода putText. И, наконец, проверяем простейшее условие: если был распознан не владелец ПК (здесь-то и понадобился словарь с именами), то заблокировать компьютер. За блокировку, как видно, отвечает строка ctypes.windll.user32.LockWorkStation(). Чтобы она сработала, потребуется импортировать модуль ctypes, помимо cv2 и numpy.
В результате ПК блокируется, как только было распознано лицо другого человека, либо оно не было распознано в принципе. После разблокировки ПК программа продолжает работать. Можно также добавить блокировку ПК по событию ухода сотрудника со своего рабочего места. Не надо долго думать, чтобы понять, что здесь есть довольно много нюансов. Например, что, если на заднем плане будет распознано другое лицо? В этой ситуации можно установить минимальный размер объекта, похожего на лицо, тогда лица на заднем плане будут игнорироваться (для этого в методе detectMultiScale есть параметр minSize). В других ситуациях при желании тоже можно найти хорошие решения.
Один из самых важных факторов корректной работы блокировки – качество изображений в базе фото. Во-первых, желательно, чтобы для конкретного человека их было много, с разыми ракурсами и выражениями лица. Во-вторых, освещение вносит свои коррективы, поэтому стоит учитывать этот момент и использовать изображения, взятые при разном освещении. И в-третьих, следует записывать изображения именно с той web-камеры, которая находится на рабочем месте сотрудника, для сохранения изображений в OpenCV также есть метод. Что касается кода, наверняка он будет расширяться, будет добавляться дополнительный функционал, поэтому его можно «обернуть» в функции, использовать классы. Ведь нет предела совершенству! Главное, запомнить порядок действий программы: обработка базы с фотографиями, тренировка, обнаружение, распознавание.
На вебинаре 03.09.2020 10-00 мск спикеры представит практический метод обучения нейронной сети для детекции объектов с приведением исходного кода и указанием используемых технологий, а также ответят на ваши вопросы. Зарегистрироваться можно по ссылке: newtechaudit.ru/vebinar-computer-vision


