Мы давно уже живем в мире многоядерных процессоров и многозадачных приложений и знаем, что наиболее очевидным способом увеличения производительности является распараллеливание выполняемых задач на несколько потоков или процессов. Точнее настолько насколько позволяют, в первую очередь, ресурсы процессора. Однако, неискушенный или даже опытный разработчик может столкнуться с рядом подводных камней в, казалось бы, очевидной ситуации. В данной статье автор взял простейший код, замерил его производительность в одном потоке, распараллелил его, справедливо ожидая улучшения результатов, но что-то пошло не так…
Ниже мы напишем простейшее приложение на java (автор использовал java 14, но и java 8 подойдет вполне), замерим его производительность, используя счетчики внутри приложения, и попробуем улучшить результат, выполняя код в несколько потоков. Все что потребуется для воспроизведения примера — любая среда разработки на java или просто jdk и утилита visualvm, которая поможет нам выполнить диагностику возникших проблем. В примере намеренно не используются различные бенчмарки для замера производительности и прочие продвинутые средства — в данном случае они излишни. Тестовый пример запускался под Windows на процессоре Intel Core i7 с 4-мя физическими и с 8 логическими ядрами.
Итак, создадим простое приложение, которое в цикле будет выполнять нагружающую процессор вычислительную задачу, а именно, вычисление факториала. Причем каждая задача тоже в цикле будет вычислять факториал числа, лежащего в диапазоне от 1 до 25. Плавающий диапазон взят, чтобы больше приблизить пример к реальности. Ниже приведен код функции work():
Функция получает на вход количество циклов вычисления факториала, задаваемых константой:
После выполнения определенного количества задач, указанных в переменной
Логируется количество выполненных задач и общее время их выполнения
Функция work() также использует:
Нужно отметить, что разовое выполнение функции work() в один поток занимает примерно 20 мс, поэтому синхронизированное обращение к общей переменной counter в конце, которое могло бы являться узким местом, не создает проблем, так как происходит для каждого потока не чаще чем раз 20 мс, что существенно превышает время выполнения counter.incrementAndGet(). Другими словами, конкуренция между потоками, связанная с обращением к синхронизированному счетчику, не должна оказать существенного влияния на результаты эксперимента и ей можно пренебречь.
Давайте запустим в один поток следующий код и посмотрим на результат:
В консоли мы видим следующий вывод:
10 Задач выполнено за 0 секунд
…
100 Задач выполнено за 2 секунд
…
500 Задач выполнено за 10 секунд
Итак, в один поток мы получили производительность равную 50 задачам в секунду или 20 мс на задачу.
Если в один поток мы получили производительность X, то на 4 процессорах, при отсутствии дополнительной нагрузки, можно ожидать, что производительность составит примерно 4*X, то есть увеличится в 4 раза. Это кажется вполне логичным. Что ж попробуем!
Вводим простой пул с фиксированным числом потоков:
Константу:
Мы будем менять в диапазоне от 1 до 16 и фиксировать результат.
Переделываем код запуска:
По-умолчанию, размер очереди задач в пуле потоков составляет Integer.MAX_VALUE, мы добавляем в пул потоков не более Integer.MAX_VALUE задач, поэтому очередь задач переполниться не должна.
Для начала установим константу POOL_SIZE в 8 потоков:
запустим приложение и посмотрим на консоль:
10 Задач выполнено за 3 секунд
20 Задач выполнено за 6 секунд
30 Задач выполнено за 8 секунд
40 Задач выполнено за 10 секунд
50 Задач выполнено за 14 секунд
60 Задач выполнено за 16 секунд
70 Задач выполнено за 19 секунд
80 Задач выполнено за 20 секунд
90 Задач выполнено за 23 секунд
100 Задач выполнено за 24 секунд
110 Задач выполнено за 26 секунд
120 Задач выполнено за 28 секунд
130 Задач выполнено за 29 секунд
140 Задач выполнено за 31 секунд
150 Задач выполнено за 33 секунд
160 Задач выполнено за 36 секунд
170 Задач выполнено за 46 секунд
Что же мы видим? Вместо ожидаемого увеличения производительности она упала более чем в 10 раз с 20 мс на задачу до 270 мс. Но и это еще не все! Сообщение про 170 выполненных задач последнее в логе. Дальше приложение, как будто, остановилось совсем.
Прежде чем разбираться с причинами такого странного поведения программы, давайте поймем динамику и снимем лог последовательно для 4-х и 16 потоков, установив константу POOL_SIZE в соответствующие значения.
Лог для 4-х потоков:
10 Задач выполнено за 2 секунд
20 Задач выполнено за 4 секунд
30 Задач выполнено за 6 секунд
40 Задач выполнено за 8 секунд
50 Задач выполнено за 10 секунд
60 Задач выполнено за 13 секунд
70 Задач выполнено за 15 секунд
80 Задач выполнено за 18 секунд
90 Задач выполнено за 21 секунд
100 Задач выполнено за 33 секунд
Первый 90 задач завершились примерно за такое же время как и для 8 потоков, потом еще 12 секунд потребовалось на выполнение еще 10 задач и приложение зависло.
Лог для 16 потоков:
10 Задач выполнено за 2 секунд
20 Задач выполнено за 3 секунд
30 Задач выполнено за 6 секунд
40 Задач выполнено за 8 секунд
…
290 Задач выполнено за 51 секунд
300 Задач выполнено за 52 секунд
310 Задач выполнено за 63 секунд
После выполнения 310 задач приложение зависло и, как и в предыдущих случаях, последние 10 задач выполнялись более чем за 10 секунд.
Подведем итоги:
Распараллеливание выполнения задач приводит к деградации производительности в 10 и более раз
Во всех случаях приложение зависает и чем меньше потоков тем зависает быстрее (к этому факту мы еще вернемся)
Очевидно, что с нашим кодом что-то не то. Но как найти причину? Для этого воспользуемся утилитой visualvm. Причем запустим ее до выполнения нашего приложения, а запустив приложение переключимся на нужный java-процесс в интерфейсе visualvm. Приложение можно запускать прямо из среды разработки. Конечно, это в общем случае неправильно, но в нашем примере не окажет влияния на результат.
Первым делом смотрим на вкладку Monitor и видим, что с памятью происходит творится что-то неладное.
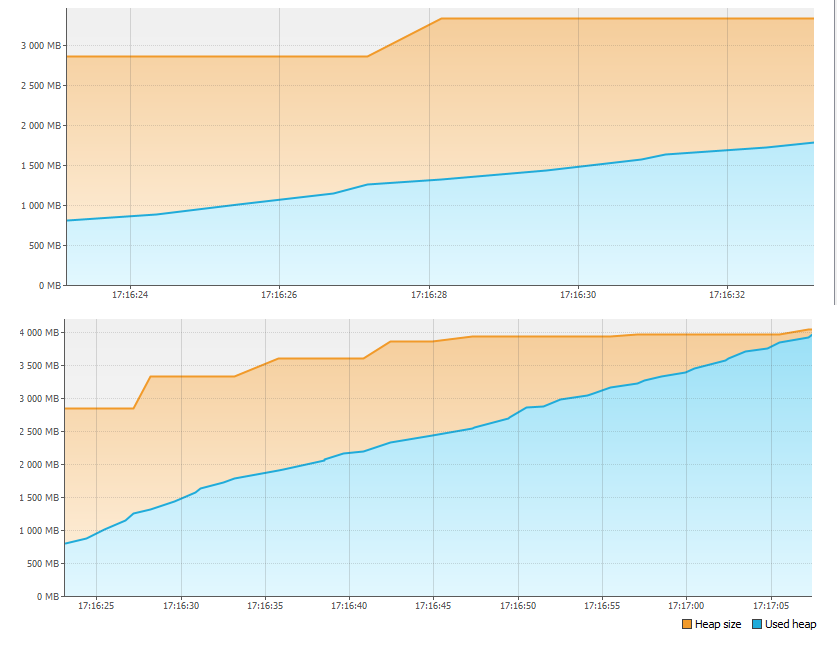
Меньше чем за минуту 4Гб памяти просто закончились! Поэтому приложение и встало. Но куда ушла память?
Повторно запускаем приложение и нажимаем кнопку Heap Dump на вкладке Monitor. После снятия и открытия дампа памяти видим:
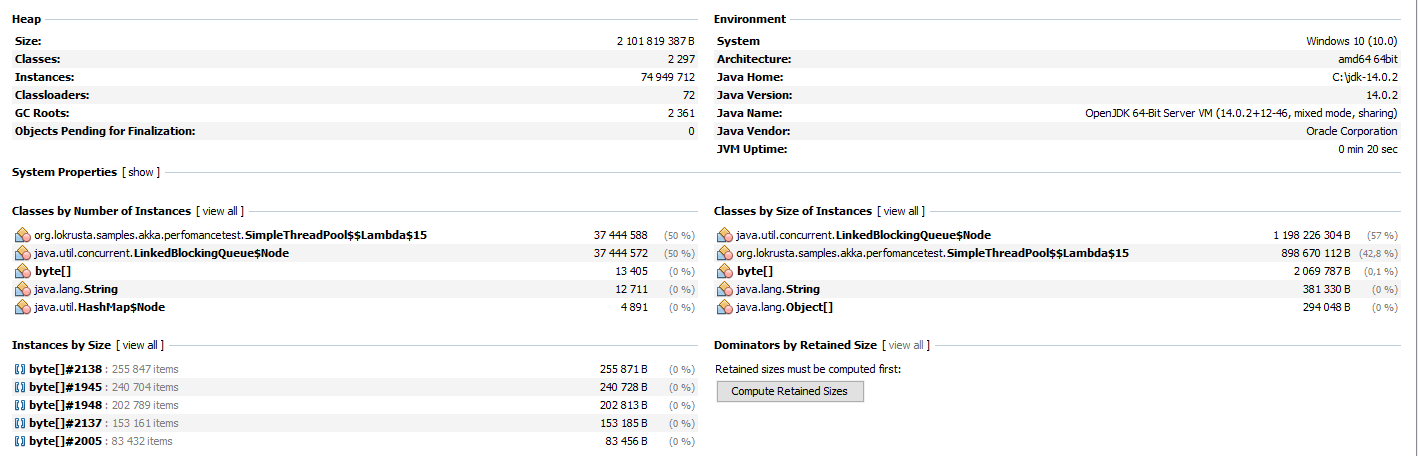
В разделе Classes by Size of Instances более 1 Гб занимает класс LinkedBlockingQueue$Node. Это не что иное как одна вершина очереди задач пула потоков. Второй по размеру класс — это сама задача добавляемая в пул потоков. В подтверждение этому в разделе Classes By Number of Instances видим соответствие количества экземпляров первого и второго классов (соответствие не совсем точное, видимо, из-за того, что сначала создается задача, а потом только новая вершина очереди, и из-за разницы во времени умноженной на количество потоков имеем небольшое несоответствие количества экземпляров).
А теперь посчитаем. Мы создаем в цикле примерно 2 млрд задач (Integer.MAX_VALUE), то есть примерно 2Гб задач. Задачи выполняются медленнее чем создаются, поэтому размер очереди все время растет. Даже если на каждую задачу потребовалось бы всего 8 байт памяти, то максимальный размер очереди составил бы:
8 * 2Гб = 16 Гб
При общем размере кучи в 4 Гб неудивительно, что памяти не хватило. На самом деле, если не прерывать выполнение приложения, лог которого остановился, через некоторое время мы увидели бы знаменитую OutOfMemoryError и даже без visualvm, просто посмотрев на код, могли бы догадаться куда уходит память.
Давайте вспомним, что чем меньшим количеством потоков выполнялись задачи, тем быстрее приложение останавливалось. Теперь мы можем попытаться это объяснить. Чем меньше количество потоков, тем быстрее работает приложение (почему — нам это еще предстоит выяснить) и тем быстрее заполняется очередь задач и переполняется память.
Что ж устранить проблему с переполнением памяти очень просто. Давайте вместо Integer.MaxValue заведем константу:
И изменим код следующим образом:
Теперь остается запустить приложение и убедиться, что с памятью все в порядке:

Снова запускаем наше приложение последовательно увеличивая количество потоков и фиксируем результат.
1 поток — 500 Задач за 10 секунд
2 потока — 500 задач за 21 секунду
4 потока — 500 Задач за 37 секунд
8 потоков — 500 Задач за 49 секунд
16 потоков — 500 Задач за 57 секунд
Как мы видим, время выполнения 500 задач при увеличении числа потоков не уменьшается, а увеличивается, при этом, скорость выполнения каждой порции из 10 задач равномерная и потоки теперь не зависают.
Еще раз воспользуемся утилитой visualvm и снимем дамп потоков в процессе выполнения приложения. Для наиболее точной картины дамп лучше снять при работе на 16 потоках. Для анализа дампов потоков есть разные утилиты, но в нашем случае можно просто в интерфейсе visualvm пролистать все потоки с названиями «pool-1-thread-1», «pool-1-thread-2» и.т.д и увидеть следующее:

Большинство потоков в момент снятия дампа выполняют генерацию очередного случайного числа для вычисления факториала. Выходит, это наиболее затратная по времени функция. Почему же? Чтобы разобраться, залезем в исходный код Random.next() и увидим следующее:
Все потоки используют один экземпляр переменной seed, доступ к которой синхронизирован за счет использования класса AtomicLong. Это значит, что при генерации каждого случайного числа потоки выстраиваются в очередь за доступом к этой переменной, а не выполняются параллельно. Поэтому производительность и не растет. Но почему она падает? Ответ прост. При распараллеливании выполнения дополнительные ресурсы тратятся на поддержку параллельной обработки, в частности, на переключение контекста процессора между потоками. Получается, дополнительные затраты появились, а потоки все равно не работают параллельно, так как конкурируют за доступ к значению переменной seed и выстраиваются в очередь при вызове seed.compareAndSet(). Конкуренция между потоками за ограниченный ресурс, пожалуй, самая частая причина деградации производительности при распараллеливании вычислений.
Изменим код функции work() следующим образом:
и снова проверим производительность на разном количестве потоков:
1 поток — 1000 задач за 17 секунд
2 потока — 1000 задач за 10 секунд
4 потока — 1000 задач за 5 секунд
8 потоков — 1000 задач за 4 секунд
16 потоков — 1000 задач за 4 секунд
Теперь результат близок к нашим ожиданиям. Производительность на 4 потоках увеличилась примерно в 4 раза. Далее рост производительности практически прекратился поскольку распараллеливание ограничено ресурсами процессора. Взглянем на графики нагрузки процессора, снятые через visualvm при работе на 4-х и 8 потоках.

Как видно из графиков, при 4-х потоках свободно более 50% процессорных ресурсов, а при 8 потоках процессор используется почти на 100%. Это значит, что в данном примере, 8 потоков это предел, дальше производительность будет только падать. В нашем примере рост производительности прекратился уже на 4-х потоках, но если бы потоки вместо вычисления факториала выполняли бы синхронный ввод-вывод, то, скорее всего, предел распараллеливания, при котором оно дает выигрыш в производительности, можно было бы существенно повысить. Проверить это читатели могут самостоятельно и написать результат в комментариях к статье
Если говорить о практике, то можно отметить два важных момента:
Обычно распараллеливание эффективно, когда число потоков до 2-х раз превышает число ядер процессора (разумеется, при отсутствии другой нагрузки на процессор)
Утилизация CPU на практике не должна превышать 80% для обеспечения отказоустойчивости
Увлекшись разговорами о производительности, мы забыли одну существенную вещь. Поменяв в коде вызов RandomUtils.nextInt() на константу, мы изменили бизнес логику нашего приложения. Давайте, вернемся к прежнему алгоритму, избежав при этом проблемы с производительностью. Мы выяснили, что вызов RandomUtils.nextInt() приводит к тому, что каждый из потоков использует одну и ту же переменную seed для генерации случайного числа, а, между тем, делать это совершенно необязательно. Использование в нашем примере вместо
класса ThreadLocalRandom:
решит проблему с конкуренцией. Теперь каждый поток будет использовать свою собственный экземпляр внутренней переменной, необходимой для генерации очередного случайного числа.
Использование отдельной переменной для каждого потока, вместо синхронизированного доступа к единственному экземпляру класса, разделяемому между потоками, распространенный прием для улучшения производительности за счет уменьшения конкуренции между потоками. Для хранения значений переменных в разрезе потока можно использовать класс java.lang.ThreadLocal, хотя есть и более продвинутые средства, например, Mapped Diagnostic Context.
В заключении хотелось бы отметить, что снижение конкуренции между потоками это не только техническая, но и логическая задача. В нашем примере, каждый поток без проблем может использовать свой экземпляр переменной, но что если нам нужен один экземпляр на всех, например, общий счетчик? В этом случае, пришлось бы провести рефакторинг самого алгоритма. Например, хранить счетчик в разрезе каждого потока и периодически или по запросу рассчитывать значение общего счетчика на основании значений счетчиков для каждого потока.
Итак, можно выделить 3 пункта, которые влияют на производительность параллельной обработки:
Начинаем пример
Ниже мы напишем простейшее приложение на java (автор использовал java 14, но и java 8 подойдет вполне), замерим его производительность, используя счетчики внутри приложения, и попробуем улучшить результат, выполняя код в несколько потоков. Все что потребуется для воспроизведения примера — любая среда разработки на java или просто jdk и утилита visualvm, которая поможет нам выполнить диагностику возникших проблем. В примере намеренно не используются различные бенчмарки для замера производительности и прочие продвинутые средства — в данном случае они излишни. Тестовый пример запускался под Windows на процессоре Intel Core i7 с 4-мя физическими и с 8 логическими ядрами.
Итак, создадим простое приложение, которое в цикле будет выполнять нагружающую процессор вычислительную задачу, а именно, вычисление факториала. Причем каждая задача тоже в цикле будет вычислять факториал числа, лежащего в диапазоне от 1 до 25. Плавающий диапазон взят, чтобы больше приблизить пример к реальности. Ниже приведен код функции work():
void work(int power) { for (int i = 0; i < power; i++) { long result = factorial(RandomUtils.nextInt(1, 25)); } if (counter.incrementAndGet() % LOG_STEP == 0) { System.out.printf("%d Задач выполнено за %d секунд%n", counter.longValue(), (long) ((System.currentTimeMillis() - startTime) / 1000)); } }
Функция получает на вход количество циклов вычисления факториала, задаваемых константой:
private static final int POWER_BASE = 1000000;
После выполнения определенного количества задач, указанных в переменной
private static final int LOG_STEP = 10;
Логируется количество выполненных задач и общее время их выполнения
Функция work() также использует:
// начальное время в мс private long startTime; // счетчик количества выполненных задач private AtomicLong counter = new AtomicLong(); // функция вычисления факториала числа private long factorial(int power) { if (power == 1) return power; else return power * factorial(power - 1); }
Нужно отметить, что разовое выполнение функции work() в один поток занимает примерно 20 мс, поэтому синхронизированное обращение к общей переменной counter в конце, которое могло бы являться узким местом, не создает проблем, так как происходит для каждого потока не чаще чем раз 20 мс, что существенно превышает время выполнения counter.incrementAndGet(). Другими словами, конкуренция между потоками, связанная с обращением к синхронизированному счетчику, не должна оказать существенного влияния на результаты эксперимента и ей можно пренебречь.
Давайте запустим в один поток следующий код и посмотрим на результат:
startTime = System.currentTimeMillis(); for (int i = 0; i < Integer.MAX_VALUE; i++) { work(POWER_BASE); }
В консоли мы видим следующий вывод:
10 Задач выполнено за 0 секунд
…
100 Задач выполнено за 2 секунд
…
500 Задач выполнено за 10 секунд
Итак, в один поток мы получили производительность равную 50 задачам в секунду или 20 мс на задачу.
Распараллеливание кода
Если в один поток мы получили производительность X, то на 4 процессорах, при отсутствии дополнительной нагрузки, можно ожидать, что производительность составит примерно 4*X, то есть увеличится в 4 раза. Это кажется вполне логичным. Что ж попробуем!
Вводим простой пул с фиксированным числом потоков:
private ExecutorService executorService = Executors.newFixedThreadPool(POOL_SIZE);
Константу:
private static final int POOL_SIZE = 1;
Мы будем менять в диапазоне от 1 до 16 и фиксировать результат.
Переделываем код запуска:
startTime = System.currentTimeMillis(); for (int i = 0; i < Integer.MAX_VALUE; i++) { executorService.execute(() -> work(POWER_BASE)); }
По-умолчанию, размер очереди задач в пуле потоков составляет Integer.MAX_VALUE, мы добавляем в пул потоков не более Integer.MAX_VALUE задач, поэтому очередь задач переполниться не должна.
Поехали!
Для начала установим константу POOL_SIZE в 8 потоков:
private static final int POOL_SIZE = 8;
запустим приложение и посмотрим на консоль:
10 Задач выполнено за 3 секунд
20 Задач выполнено за 6 секунд
30 Задач выполнено за 8 секунд
40 Задач выполнено за 10 секунд
50 Задач выполнено за 14 секунд
60 Задач выполнено за 16 секунд
70 Задач выполнено за 19 секунд
80 Задач выполнено за 20 секунд
90 Задач выполнено за 23 секунд
100 Задач выполнено за 24 секунд
110 Задач выполнено за 26 секунд
120 Задач выполнено за 28 секунд
130 Задач выполнено за 29 секунд
140 Задач выполнено за 31 секунд
150 Задач выполнено за 33 секунд
160 Задач выполнено за 36 секунд
170 Задач выполнено за 46 секунд
Что же мы видим? Вместо ожидаемого увеличения производительности она упала более чем в 10 раз с 20 мс на задачу до 270 мс. Но и это еще не все! Сообщение про 170 выполненных задач последнее в логе. Дальше приложение, как будто, остановилось совсем.
Прежде чем разбираться с причинами такого странного поведения программы, давайте поймем динамику и снимем лог последовательно для 4-х и 16 потоков, установив константу POOL_SIZE в соответствующие значения.
Лог для 4-х потоков:
10 Задач выполнено за 2 секунд
20 Задач выполнено за 4 секунд
30 Задач выполнено за 6 секунд
40 Задач выполнено за 8 секунд
50 Задач выполнено за 10 секунд
60 Задач выполнено за 13 секунд
70 Задач выполнено за 15 секунд
80 Задач выполнено за 18 секунд
90 Задач выполнено за 21 секунд
100 Задач выполнено за 33 секунд
Первый 90 задач завершились примерно за такое же время как и для 8 потоков, потом еще 12 секунд потребовалось на выполнение еще 10 задач и приложение зависло.
Лог для 16 потоков:
10 Задач выполнено за 2 секунд
20 Задач выполнено за 3 секунд
30 Задач выполнено за 6 секунд
40 Задач выполнено за 8 секунд
…
290 Задач выполнено за 51 секунд
300 Задач выполнено за 52 секунд
310 Задач выполнено за 63 секунд
После выполнения 310 задач приложение зависло и, как и в предыдущих случаях, последние 10 задач выполнялись более чем за 10 секунд.
Подведем итоги:
Распараллеливание выполнения задач приводит к деградации производительности в 10 и более раз
Во всех случаях приложение зависает и чем меньше потоков тем зависает быстрее (к этому факту мы еще вернемся)
Поиск проблем
Очевидно, что с нашим кодом что-то не то. Но как найти причину? Для этого воспользуемся утилитой visualvm. Причем запустим ее до выполнения нашего приложения, а запустив приложение переключимся на нужный java-процесс в интерфейсе visualvm. Приложение можно запускать прямо из среды разработки. Конечно, это в общем случае неправильно, но в нашем примере не окажет влияния на результат.
Первым делом смотрим на вкладку Monitor и видим, что с памятью происходит творится что-то неладное.
Меньше чем за минуту 4Гб памяти просто закончились! Поэтому приложение и встало. Но куда ушла память?
Повторно запускаем приложение и нажимаем кнопку Heap Dump на вкладке Monitor. После снятия и открытия дампа памяти видим:
В разделе Classes by Size of Instances более 1 Гб занимает класс LinkedBlockingQueue$Node. Это не что иное как одна вершина очереди задач пула потоков. Второй по размеру класс — это сама задача добавляемая в пул потоков. В подтверждение этому в разделе Classes By Number of Instances видим соответствие количества экземпляров первого и второго классов (соответствие не совсем точное, видимо, из-за того, что сначала создается задача, а потом только новая вершина очереди, и из-за разницы во времени умноженной на количество потоков имеем небольшое несоответствие количества экземпляров).
А теперь посчитаем. Мы создаем в цикле примерно 2 млрд задач (Integer.MAX_VALUE), то есть примерно 2Гб задач. Задачи выполняются медленнее чем создаются, поэтому размер очереди все время растет. Даже если на каждую задачу потребовалось бы всего 8 байт памяти, то максимальный размер очереди составил бы:
8 * 2Гб = 16 Гб
При общем размере кучи в 4 Гб неудивительно, что памяти не хватило. На самом деле, если не прерывать выполнение приложения, лог которого остановился, через некоторое время мы увидели бы знаменитую OutOfMemoryError и даже без visualvm, просто посмотрев на код, могли бы догадаться куда уходит память.
Давайте вспомним, что чем меньшим количеством потоков выполнялись задачи, тем быстрее приложение останавливалось. Теперь мы можем попытаться это объяснить. Чем меньше количество потоков, тем быстрее работает приложение (почему — нам это еще предстоит выяснить) и тем быстрее заполняется очередь задач и переполняется память.
Что ж устранить проблему с переполнением памяти очень просто. Давайте вместо Integer.MaxValue заведем константу:
private static final int MAX_TASKS = 1024 * 1024;
И изменим код следующим образом:
startTime = System.currentTimeMillis(); for (int i = 0; i < MAX_TASKS; i++) { executorService.execute(() -> work(POWER_BASE)); }
Теперь остается запустить приложение и убедиться, что с памятью все в порядке:
Продолжаем анализ
Снова запускаем наше приложение последовательно увеличивая количество потоков и фиксируем результат.
1 поток — 500 Задач за 10 секунд
2 потока — 500 задач за 21 секунду
4 потока — 500 Задач за 37 секунд
8 потоков — 500 Задач за 49 секунд
16 потоков — 500 Задач за 57 секунд
Как мы видим, время выполнения 500 задач при увеличении числа потоков не уменьшается, а увеличивается, при этом, скорость выполнения каждой порции из 10 задач равномерная и потоки теперь не зависают.
Еще раз воспользуемся утилитой visualvm и снимем дамп потоков в процессе выполнения приложения. Для наиболее точной картины дамп лучше снять при работе на 16 потоках. Для анализа дампов потоков есть разные утилиты, но в нашем случае можно просто в интерфейсе visualvm пролистать все потоки с названиями «pool-1-thread-1», «pool-1-thread-2» и.т.д и увидеть следующее:
Большинство потоков в момент снятия дампа выполняют генерацию очередного случайного числа для вычисления факториала. Выходит, это наиболее затратная по времени функция. Почему же? Чтобы разобраться, залезем в исходный код Random.next() и увидим следующее:
private final AtomicLong seed; protected int next(int bits) { long oldseed, nextseed; AtomicLong seed = this.seed; do { oldseed = seed.get(); nextseed = (oldseed * multiplier + addend) & mask; } while (!seed.compareAndSet(oldseed, nextseed)); return (int)(nextseed >>> (48 - bits)); }
Все потоки используют один экземпляр переменной seed, доступ к которой синхронизирован за счет использования класса AtomicLong. Это значит, что при генерации каждого случайного числа потоки выстраиваются в очередь за доступом к этой переменной, а не выполняются параллельно. Поэтому производительность и не растет. Но почему она падает? Ответ прост. При распараллеливании выполнения дополнительные ресурсы тратятся на поддержку параллельной обработки, в частности, на переключение контекста процессора между потоками. Получается, дополнительные затраты появились, а потоки все равно не работают параллельно, так как конкурируют за доступ к значению переменной seed и выстраиваются в очередь при вызове seed.compareAndSet(). Конкуренция между потоками за ограниченный ресурс, пожалуй, самая частая причина деградации производительности при распараллеливании вычислений.
Изменим код функции work() следующим образом:
void work(int power) { for (int i = 0; i < power; i++) { long result = factorial(20); } if (counter.incrementAndGet() % LOG_STEP == 0) { System.out.printf("%d Задач выполнено за %d секунд%n", counter.longValue(), (long) ((System.currentTimeMillis() - startTime) / 1000)); } }
и снова проверим производительность на разном количестве потоков:
1 поток — 1000 задач за 17 секунд
2 потока — 1000 задач за 10 секунд
4 потока — 1000 задач за 5 секунд
8 потоков — 1000 задач за 4 секунд
16 потоков — 1000 задач за 4 секунд
Теперь результат близок к нашим ожиданиям. Производительность на 4 потоках увеличилась примерно в 4 раза. Далее рост производительности практически прекратился поскольку распараллеливание ограничено ресурсами процессора. Взглянем на графики нагрузки процессора, снятые через visualvm при работе на 4-х и 8 потоках.
Как видно из графиков, при 4-х потоках свободно более 50% процессорных ресурсов, а при 8 потоках процессор используется почти на 100%. Это значит, что в данном примере, 8 потоков это предел, дальше производительность будет только падать. В нашем примере рост производительности прекратился уже на 4-х потоках, но если бы потоки вместо вычисления факториала выполняли бы синхронный ввод-вывод, то, скорее всего, предел распараллеливания, при котором оно дает выигрыш в производительности, можно было бы существенно повысить. Проверить это читатели могут самостоятельно и написать результат в комментариях к статье
Если говорить о практике, то можно отметить два важных момента:
Обычно распараллеливание эффективно, когда число потоков до 2-х раз превышает число ядер процессора (разумеется, при отсутствии другой нагрузки на процессор)
Утилизация CPU на практике не должна превышать 80% для обеспечения отказоустойчивости
Уменьшение конкуренции между потоками
Увлекшись разговорами о производительности, мы забыли одну существенную вещь. Поменяв в коде вызов RandomUtils.nextInt() на константу, мы изменили бизнес логику нашего приложения. Давайте, вернемся к прежнему алгоритму, избежав при этом проблемы с производительностью. Мы выяснили, что вызов RandomUtils.nextInt() приводит к тому, что каждый из потоков использует одну и ту же переменную seed для генерации случайного числа, а, между тем, делать это совершенно необязательно. Использование в нашем примере вместо
RandomUtils.nextInt(1, 25)
класса ThreadLocalRandom:
ThreadLocalRandom.current().nextInt(1, 25)
решит проблему с конкуренцией. Теперь каждый поток будет использовать свою собственный экземпляр внутренней переменной, необходимой для генерации очередного случайного числа.
Использование отдельной переменной для каждого потока, вместо синхронизированного доступа к единственному экземпляру класса, разделяемому между потоками, распространенный прием для улучшения производительности за счет уменьшения конкуренции между потоками. Для хранения значений переменных в разрезе потока можно использовать класс java.lang.ThreadLocal, хотя есть и более продвинутые средства, например, Mapped Diagnostic Context.
В заключении хотелось бы отметить, что снижение конкуренции между потоками это не только техническая, но и логическая задача. В нашем примере, каждый поток без проблем может использовать свой экземпляр переменной, но что если нам нужен один экземпляр на всех, например, общий счетчик? В этом случае, пришлось бы провести рефакторинг самого алгоритма. Например, хранить счетчик в разрезе каждого потока и периодически или по запросу рассчитывать значение общего счетчика на основании значений счетчиков для каждого потока.
Заключение
Итак, можно выделить 3 пункта, которые влияют на производительность параллельной обработки:
- Ресурсы процессора
- Конкуренция между потоками
- Прочие факторы, оказывающие косвенное влияние на общий результат

