Когда пришло приглашение поучаствовать в хакатоне с заданием, для реализации которого необходима оригинальная/ смешная/ креативная гипотеза, мы сразу согласились.
Для участия в хакатоне мы использовали данные шуточного психологического теста.
Суть которого сводится к выявлению сексуальности игрока на подсознательном уровне.
Степень сексуальности выявлялась по описанному игроком образу воды.
Для тех кто не любит читать многА БУКВ, мы сделали минутный ролик, о том что и как было сделано без технических подробностей. Можете посмотреть его:
Остальным изложим детально и пошагово.
Машинное обучение было реализовано для:
Данные были взяты из телеграм каналов, которые наполняет игровое приложение.

В Dataset вошло 2 файла в формате JSON объёмом 61 133 и 41 118 строк соответственно.
Основная гипотеза состояла в том, что негативные отзывы об игре оставляют так называемый «брёвна» в постели.
Блок схема проделанной работы указана на рисунке:

Для начала были импортированы данные в Pyton, используя библиотеки codecs, json и pandas, затем отфильтрованы средствами Pandas, добавлены поля для анализа и выгружен полученный результат:
Приложение голосовое и многие пользователи общаются с ним как с человеком, поэтому был выбран ручной ввод примеров правильных ответов.
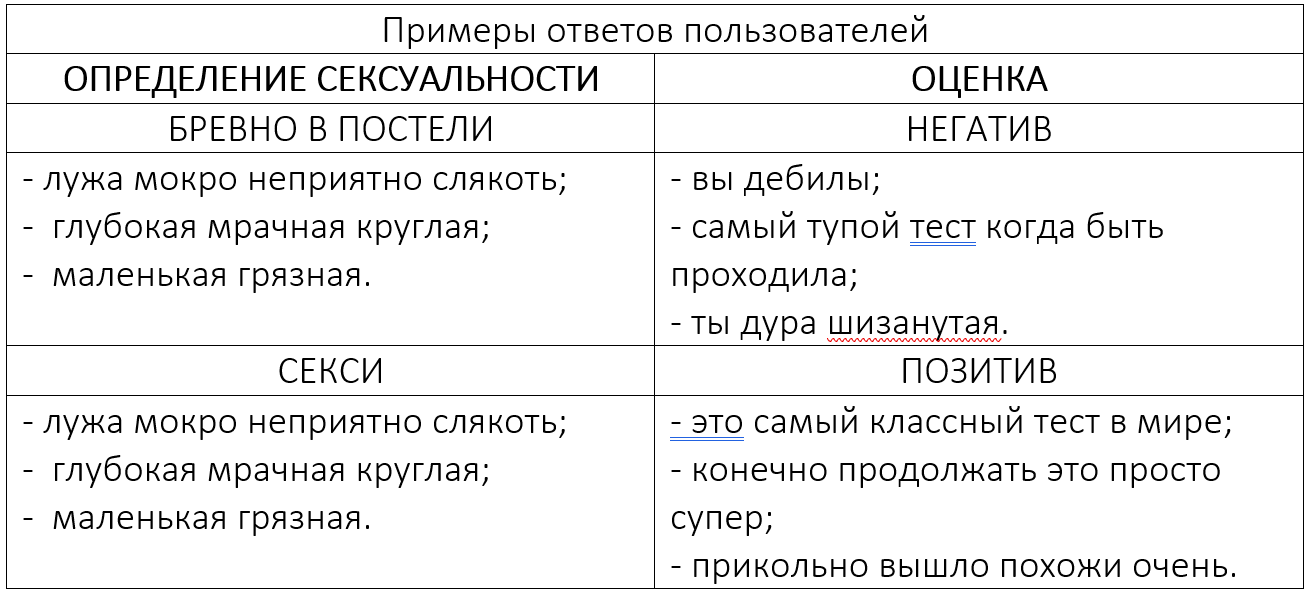
Было выбрано более 1 000 вариантов примеров для каждой базы.
Для определения оптимального порога для машинного обучения было проанализировано количество слов, произнесённых игроками в каждом сообщении.

Используя библиотеку глубокого машинного обучения Keras сделали следующее:

потом

Фактически было произведено следующее: Создана база всех слов, затем каждому слову присвоен свой номер, определён вес каждого слова, создан массив высказываний одинаковой длинны, где недостающие слова были заполнены значением – «0».
Затем создана модель нейронной сети, запущено обучение и проверка, как она обучилась. Получен результат, показанный на рисунке 4.
На обучении достигли 99,5% на проверочной выборке 61.9%.

Для улучшения показателей необходимо было расширить тестовую выборку, но по правилам хакатона точность не имеет ключевого значения, поэтому остановились на этом результате.
Были сопоставлены оценки приложения с сексуальностью игроков, в итоге мы получили следующую картину:

В результате наша гипотеза не подтвердилась. Отсутствует какая-либо зависимость вида отзыва от степени сексуальности игрока.
Для финальной визуализации мы объединили количество отзывов от «секси» и «обычных» и представили их в процентном выражении. Формат визулизации — видео с инфографикой в формате 3:4 (требования организаторов)
К сожалению организаторы не смогли прикрутить видео на сайте голосования, но надеюсь что скоро это исправят.
Просьба проголосовать за наш проект:
https://hackathon.digitalleader.org/contest-photo/10/
Для участия в хакатоне мы использовали данные шуточного психологического теста.
Суть которого сводится к выявлению сексуальности игрока на подсознательном уровне.
Степень сексуальности выявлялась по описанному игроком образу воды.
Для тех кто не любит читать многА БУКВ, мы сделали минутный ролик, о том что и как было сделано без технических подробностей. Можете посмотреть его:
Остальным изложим детально и пошагово.
Машинное обучение было реализовано для:
- определения степени сексуальности игрока, методом классификации описанных игроками образов воды.
- классификации оценок игроков, продиктованных голосом в произвольном формате.
Данные были взяты из телеграм каналов, которые наполняет игровое приложение.
В Dataset вошло 2 файла в формате JSON объёмом 61 133 и 41 118 строк соответственно.
Основная гипотеза состояла в том, что негативные отзывы об игре оставляют так называемый «брёвна» в постели.
Блок схема проделанной работы указана на рисунке:
Для начала были импортированы данные в Pyton, используя библиотеки codecs, json и pandas, затем отфильтрованы средствами Pandas, добавлены поля для анализа и выгружен полученный результат:
import codecs import json import pandas as answer dataset = [] data = answer.read_json("result.json") answer = answer.DataFrame(data) total = int(answer.index.stop) number = 1 position = 6 while number < total: datatipe = answer["messages"][number]["type"] datalen = len(answer["messages"][number]["text"]) if datatipe == "message" and datalen == 9: dataposition = answer["messages"][number]["text"][position] datatime = answer["messages"][number]["date"] dataset.append([dataposition]) data[datatime] = data[datatime].astype(float) ##print(number,"|",datatime,"|", dataposition) number += 1 #Оставляем два поля и добавяем поля секси dataset += [{'time' :datatime, 'text' :dataposition, 'sex' :"3", }] # записываем в файл что получилось with open('total_result.json','w', encoding='utf-8',) as f: json.dump(dataset, f,indent=2, ensure_ascii=False, sort_keys=True)
Была создана выборка для маши��ного обучения
Приложение голосовое и многие пользователи общаются с ним как с человеком, поэтому был выбран ручной ввод примеров правильных ответов.
Было выбрано более 1 000 вариантов примеров для каждой базы.
Выбор оптимальных параметров
Для определения оптимального порога для машинного обучения было проанализировано количество слов, произнесённых игроками в каждом сообщении.
Машинное обучение
Используя библиотеку глубокого машинного обучения Keras сделали следующее:
потом
Фактически было произведено следующее: Создана база всех слов, затем каждому слову присвоен свой номер, определён вес каждого слова, создан массив высказываний одинаковой длинны, где недостающие слова были заполнены значением – «0».
Затем создана модель нейронной сети, запущено обучение и проверка, как она обучилась. Получен результат, показанный на рисунке 4.
На обучении достигли 99,5% на проверочной выборке 61.9%.
Для улучшения показателей необходимо было расширить тестовую выборку, но по правилам хакатона точность не имеет ключевого значения, поэтому остановились на этом результате.
Анализ данных и визуализация
Были сопоставлены оценки приложения с сексуальностью игроков, в итоге мы получили следующую картину:
В результате наша гипотеза не подтвердилась. Отсутствует какая-либо зависимость вида отзыва от степени сексуальности игрока.
Для финальной визуализации мы объединили количество отзывов от «секси» и «обычных» и представили их в процентном выражении. Формат визулизации — видео с инфографикой в формате 3:4 (требования организаторов)
К сожалению организаторы не смогли прикрутить видео на сайте голосования, но надеюсь что скоро это исправят.
Просьба проголосовать за наш проект:
https://hackathon.digitalleader.org/contest-photo/10/

