
Хабр Курсы для всех
РЕКЛАМА
Практикум, Хекслет, SkyPro, авторские курсы — собрали всех и попросили скидки. Осталось выбрать!
для облегчения понимания материала не-сетевиками. :D
Следовательно, на магистралях вырос зарубежный трафик, к которому все оказались не готовы — в итоге, CDNы, раздающие куски сайтов, раздавали очень медленно.
Так как в России не производится коммутационное оборудование
Для начала, телекоммуникационного оборудование в России производится, как на базе импортных компонентов, так и на ПЛИС и отечественных аналогов западных чипов.
Провайдеры получают хорошие льготы при использовании отечественного оборудования и не очень хорошие при использовании чисто импортного оборудования.
Тот же Ростелеком во всю пользуется отечественным оборудованием на магистральных сетях.
К сожалению для вас я работаю в фирме, которая с середины 90-х годов прошлого века занимается разработкой и производством оборудования для телекома, причём начиная от абонентского оборудования и заканчивая транспортом.
Полный цикл от разработки до производства, включая софт.
ооо. да, пиринговые войны это тот еще ад.

Схема сети начинает выглядеть так
К слову, как (и кем) оплачивается трафик у транзитных провайдеров (как работает этот механизм)?
А на самом верху сидят Tier-1 операторы
Не ошибаетесь. Цоды сертифицируются от тир1 к тир4, по возрастанию качества. Провайдеры от тир3 к тир1 по иерархии.
И да, у цодов это конкретные требования по архитектуре и резервированию инженерки, у провайдеров — лишь условное обозначение
Провайдеры от тир3 к тир1 по иерархии
только к тир1 операторам (которых всего менее 10 штук),
А вот AS1, поскольку у него есть бесплатный пиринг с AS20 де-юре является тир2 оператором.
По объему данных
RIB и FIB
Именно поэтому микротикам, на которых некоторые умельцы даже умудряются принять пару фулвью от аплинков, становится очень плохо при флапе сессий. Да, процы в микротах слабоваты (
Зато в тысячи раз дешевле n9k/asr
3.5 террабайта памяти.
Выводы:
Провайдеры заботятся в основном о собстевнной выгоде, а что там с пользователем — дело десятое.
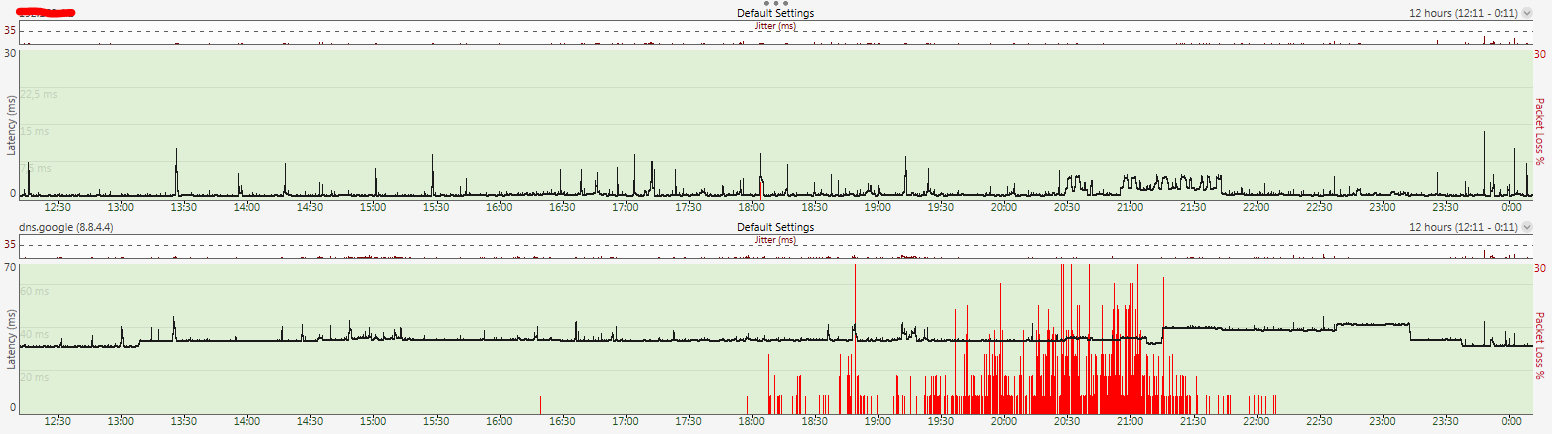
Когда все массово грузят тяжелый контент и перегружают канал — интернет хуже.
Но ведь в килобайте 1000 байт
Как находить проблемы с интернетом и кто виноват ч.1 — inception