Хочу поделиться своим опытом реализации микросервисной архитектуры поверх actor-model фреймоворков, таких как AKKA и Microsoft Orleans.
Моя гипотеза: если использовать один стек для реализации микросервисов, то можно:
- Существенно снизить сложность разработки и объем кода
- Упростить отладку и поиск ошибок
- Упростить деплой
- Упростить задачу определения границ сервисов
- Избавится от ограничения применения stateful-сервисов
- Упростит работу с распределенными транзакциями.
О… Похоже на «серебряную пулю»! Давайте разберемся, так ли это.
Зачем это нужно?
Всем знакомы ключевые преимущества микросервисной архитектуры:
- сервисы можно легко заменить в любое время: акцент на простоту, независимость развёртывания и обновления каждого из микросервисов;
- сервисы организованы вокруг функций: микросервис по возможности выполняет только одну достаточно элементарную функцию;
- сервисы могут быть реализованы с использованием различных языков программирования, фреймворков, связующего программного обеспечения и пр.;
- архитектура симметричная, а не иерархическая: зависимости между микросервисами одноранговые
Не являются секретом и сложности при использование этого подхода:
- Возросшая сложность разработки: сложность работы над задачей, затрагивающей множество сервисов, сложности отладки.
- Возросшая сложность эксплуатации и DevOps: чем больше сервисов, больше способов их взаимодействия и больше возможностей для потенциальных проблем.
- Реальные системы обычно не имеют чётко определённых границ: сложно провести границы между сервисами, определить зависимости между ними, необходимость одновременного выката множества версий множества сервисов при деплое фичи.
- Ограничения реализации stateful-сервисов: реализация stateful-сервисов существенно усложняет деплой.
- Распределенные транзакции и итоговая согласованность: распределённых системы требуют механизма распределенных транзакций.
Анализируя плюсы и минусы, появилась идея: а что, если избавиться о части проблем за счет сокращения некоторых невостребованных преимуществ?
На практике, во всех проектах стараются избежать «зоопарка технологий» и стек на котором происходит разработка сервисов практически всегда один. Так что, достаточно часто можно пожертвовать таким преимуществом как «сервисы могут быть реализованы с использованием различных языков программирования, фреймворков, связующего программного обеспечения и пр.». Если мы можем использовать один стек для разработки сервисов, то это открывает нам новые возможности!
Единый стек для сервисов
Возьмём за основу DDD подход, который рекомендует нам разбивать предметную область на ограниченные контексты (Bounded context).
Ограниченный контекст – это явная граница, внутри которой существует модель предметной области, которая отображает единый язык в модель программного обеспечения. Очевидно, что ограниченный контекст это и есть микросервис со своей моделью данных.
В рамках каждого ограниченного контекста, в соответствии с DDD, свой набор сущностей (entities), состоящих из других сущностей и объектов-значений (value-objects). Сущности объединены в агрегаты (aggregation roots). Доступ к сущностям возможен только через агрегаты, которые имеют уникальный идентификатор агрегата (aggregate identity) в рамках системы.
Вся логика, которая относится к конкретным сущностям/агрегатам должна быть определена в них. Логика, затрагивающая несколько агрегатов, должна быть реализована в рамках доменных сервисов (domain services).
Агрегат может оповещать другие агрегаты об изменении своего состояния через единую шину событий (event bus), выбрасывая доменные события (domain events).
Добавим к этомy походу CQRS – как «протокол» для общения с агрегатами:
- Команды (commands) – это примитивы для вызова методов агрегата.
- Запросы (queries) – это примитивы для получения состояния агрегатов или даже группы агрегатов. Согласно CQRS обработка запросов должна быть реализована вне агрегатов в рамках отдельных сущностей – обработчиков запросов (command handlers).
Нам нужны будут шина команд (command bus) и шина запросов (query bus) для доставки этих примитивов агрегатам и обработчикам и получения результатов вызова.
Таким образом, любой наш сервис строится из следующих компонентов:
- объекты-значений (value-objects)
- сущности (entities)
- агрегаты (aggregation roots)
- доменные сервисы (domain services)
- идентификаторы агрегата (aggregate identity)
- доменные события (domain events)
- команды (commands)
- запросы (queries)
- обработчики запросов (command handlers).
Теперь можно взаимодействовать с любым микросервисом по стандартному «протоколу»:
- Посылать команды агрегатам миросервиса для изменения их состояния
- Подписываться и получать события, как результат изменения состояния агрегата
- Отправлять запросы и получать в ответ данные о состоянии групп агрегатов
Ну и нельзя забывать о логике уровня приложения, которая оперирует агрегатами различных сервисов (оркеструет их работу), управляет распределенными транзакциями. Это саги (saga) –конечные автоматы с состоянием, которые подписываются на доменные события и вызывают команды различных агрегатов, реализуя логику уровня приложения.
Stateful против Stateless
Пришло время поговорить о модели акторов (actor model). Акторы — альтернативный подход к организации параллельных вычислений и распределенных систем.
В упрощенном виде актор (actor) – это, обычно, stateful сущность, которая принимает сообщения, производит вычисления на основе этих сообщений и изменяет свое состояние. Акторы изолированы друг от друга и их внутреннее состояние не может быть изменено извне. Актор получает сообщения асинхронно. Но обрабатывает их по очереди (синхронно, в рамках одного потока).
Существуют фреймворки, которые упрощают разработку акторов:
- АККА (АККА.Net) – модель акторов для Java и Scala (C#)
- Microsoft Orleans – модель виртуальных акторов для .NET Core (C#)
Все эти фреймворки позволяют создавать акторы, управлять их жизненным циклом, доставкой и обменом сообщении. Они позволяют элегантно решить задачу создания stateful-сервисов и обеспечивают их отказоустойчивую работу в кластере.
Очевидно, что акторы в нашем подходе очень хорошо лежаться на реализацию stateful-объектов: агрегатов и саг. Их так же можно использовать для кэширования результатов выполнения запросов.
Ох, но Stateful – это плохо! Или нет?
Понятно, что нет универсального ответа на это вопрос. Также очевидно, что тенденции последних лет были направлены в сторону разработки stateless-сервисов, обеспечивающих хорошее горизонтальное масштабирование.
Но при настоящем highload становится очевидным, что stateless-сервисы – это не панацея. Они либо дают серьёзную нагрузку на базу, которую становится сложно решить или приводят к проблемам с кэшированием (когда обновлять кэш?).
Модель акторов, которая позволяет хранить состояние сервиса в памяти кластера и обращаться к нему без восстановления состояния из базы или кэша – это более продуктивное решение, чем stateless-сервис. Причем, фреймворк модели акторов берет на себя задачу выгрузки из памяти неиспользуемых объектов, а также задачи отказоустойчивости.
Именно такой поход мы применим для работы с нашими агрегатами и сагами.
Также, стоит отметить, что фреймворки модели акторов «из коробки» дают нам реактивные потоки (reactive streams), которые идеально подходят для реализации шин событий, команд и запросов. Это позволяет нашим сервисам взаимодействовать друг с другом единым, универсальным образом через реактивные потоки.
А как же взаимодействие с микросервисов с клиентскими приложениями?
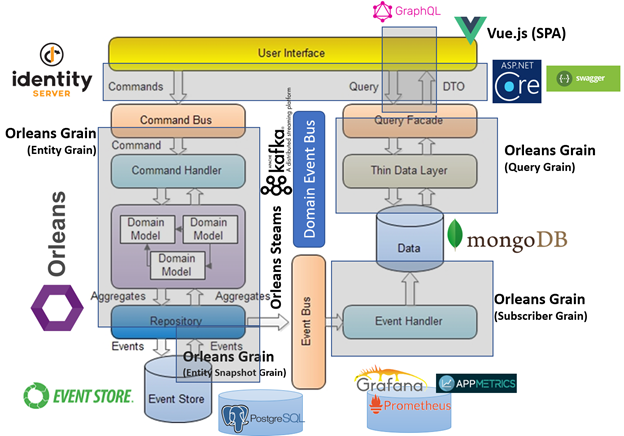
Универсальный API-proxy
Очевидно, что если все взаимодействие с микросервисами строится с помощью команд, событий и запросов, то мы можем сделать универсальный API-proxy, который будет строиться автоматически на основании семантики этих примитивов.
В свои проектах я реализовывал такой подход для автоматической генерации «налету» WebAPI для вызова команд и запросов, swagger документации к этим вызовам, graphql для вызова запросов, signalR подписку и получение любых доменных событий.
Среда исполнения
В описываемом подходе акторы (агрегаты, саги, обработчики запросов) материализуются в кластере под управлением фреймворка акторов – это наша единая среди исполнения всех микросервисов.
Это позволяет гибко управлять структурой кластера, запуском микросервисов в нем. Например, мы можем поднять все сервисы на одном сервере в рамках одного процесса, что очень удобно для отладки. Или в режиме реального времени добавлять новые серверы в кластер, на которых поднимать интересующие нас сервисы. У нас есть возможность управлять правилами материализации акторов в кластере, что позволяет нам поднимать связанные сущности в одном процессе, чтобы существенно сократить затраты на взаимодействие между ними.
Имея такой универсальный набор компонентов для создания сервисов и единую среду для их исполнения, мы можем создать свой единый фреймворк, на основе которого будем строить все наши микросервисы.
Единый фреймворк
Я на практике использовал для реализации описанного выше подхода АККА.Net и Microsoft Orleans. По моему мнению Microsoft Orleans лучше подходит для решения этой задачи, т.к. виртуальная модель акторов существенно упрощает управление жизненным циклом акторов и обработку исключений.
Как устроен единый фреймворк:
- Сборка с примитивами Framework.Primitives
Содержит базовые классы для создания публичных примитивов миросервисов, таких как:
- объекты-значений (value-objects)
- идентификаторы агрегата (aggregate identity)
- доменные события (domain events)
- команды (commands)
- запросы (queries)
- Сборка с базовыми объектами компонентами миросервиса Framework.Domain
Содержит базовые классы для создания приватных объектов миросервисов, таких как:
- сущности (entities)
- агрегаты (aggregation roots)
- доменные сервисы (domain services)
- обработчики запросов (command handlers)
- Сборка Framework.Application содержит базовые классы для саг.
- Сборка Framework.Infrastructure содержит базовые классы для сохранения состояния агрегатов и саг в различные базы данных
- Сборка Framework.Host содержит реализацию хоста, среды исполнения микросервисов, построения и управления кластером, работой с конфигурацией.
Как с помощью единого фреймворка создается микросервис:
- Определяется набор сущностей, объектов значений и агрегатов. Определяется модель состояния каждого агрегата.
- Создаются классы для хранения состояния агрегатов и классы сущностей, объектов значений и агрегатов.
- Определяется набор команд, меняющих состояние агрегатов и события, информирующие об изменении состояния агрегата.
- Создаются классы команд и обработчики этих команд в агрегате, меняющие состояние и выбрасывающие события. При необходимости создаются доменные сервисы (stateless-сервисы), содержащие логику, которая выходит за рамки одного агрегата.
- Создаются провайдеры для чтения и сохранения состояния агрегатов в базы данных.
Таким образом, каждый микросервис, обычно сдержит следующие сборки:
- Service1.Primitives – публичные примитивы (события, команды, идентификаторы агрегатов)
- Service1.Domain – приватная реализация доменной логики (сущности, агрегаты, доменные сервисы)
- Service1.Infrastructure – провайдеры чтения и сохранения состояния агрегатов в базы данных
В отдельных сборках уровня приложения (Application) создаются саги и обработчики запросов.
Для примера, добавлю немного кода, а то "многобукв" получилось :)
Ниже пример реализации агрегата, как видно код простой и очевидный.
public class UserId : Identity<UserId> { public UserId(System.String value) : base(value) { } } [Validator(typeof(BirthValidator))] public class Birth : SingleValueObject<DateTime> { public Birth(DateTime value) : base(value) { } } public class BirthValidator : AbstractValidator<Birth> { public BirthValidator() { RuleFor(p => p.Value).NotNull(); RuleFor(p => p.Value).LessThan(DateTime.Now); } } [Description("Создание нового пользователя")] [HasPermissions(DemoContext.CreateUser, DemoContext.ChangeUser)] [Validator(typeof(CreateUserCommandValidator))] public class CreateUserCommand : Command<UserId> { public LocalizedString UserName { get; } public Birth Birth { get; } public CreateUserCommand(UserId aggregateId, LocalizedString userName, Birth birth) : base(aggregateId) { UserName = userName; Birth = birth; } } public class CreateUserCommandValidator : AbstractValidator<CreateUserCommand> { public CreateUserCommandValidator(IServiceProvider sp) { RuleFor(p => p.AggregateId).NotNull(); RuleFor(p => p.UserName).SetValidator(new UserNameValidator()); RuleFor(p => p.Birth).ApplyRegisteredValidators(sp); } } [Validator(typeof(BirthValidator))] public class Birth : SingleValueObject<DateTime> { public Birth(DateTime value) : base(value) { } } public class BirthValidator : AbstractValidator<Birth> { public BirthValidator() { RuleFor(p => p.Value).NotNull(); RuleFor(p => p.Value).LessThan(DateTime.Now); } } public class UserState : AggregateState<UserState, UserId>, IApply<UserCreatedEvent>, IApply<UserRenamedEvent>, IApply<UserNotesChangedEvent>, IApply<UserTouchedEvent>, IApply<ProjectCreatedEvent>, IApply<ProjectDeletedEvent> { public LocalizedString Name { get; private set; } public Birth Birth { get; private set; } public System.String Notes { get; private set; } = System.String.Empty; public IEnumerable<Entities.Project> Projects => _projects; public void Apply(UserCreatedEvent e) { (Name, Birth) = (e.Name, e.Birth); } public void Apply(UserRenamedEvent e) { Name = e.NewName; } public void Apply(UserNotesChangedEvent e) { Notes = e.NewValue; } public void Apply(UserTouchedEvent _) { } public void Apply(ProjectCreatedEvent e) { _projects.Add(new Entities.Project(e.ProjectId, e.Name)); } public void Apply(ProjectDeletedEvent aggregateEvent) { var projectToRemove = _projects.FirstOrDefault(i => i.Id == aggregateEvent.ProjectId); if (projectToRemove != null) _projects.Remove(projectToRemove); } private readonly ICollection<Entities.Project> _projects = new List<Entities.Project>(); } public class UserAggregate : EventDrivenAggregateRoot<UserAggregate, UserId, UserState>, IExecute<CreateUserCommand, UserId>, IExecute<ChangeUserNotesCommand, UserId>, IExecute<TrackUserTouchingCommand, UserId> { public UserAggregate(UserId id) : base(id) { Command<RenameUserCommand>(); Command<CreateProjectCommand>(); Command<DeleteProjectCommand>(); } internal async Task CreateProject(ProjectId projectId, ProjectName projectName) { await Emit(new ProjectCreatedEvent(Id, projectId, projectName)); } internal async Task DeleteProject(ProjectId projectId) { await Emit(new ProjectDeletedEvent(Id, projectId)); } public async Task<IExecutionResult> Execute(CreateUserCommand cmd) { //SecurityContext.Authorized(); //SecurityContext.HasPermissions(cmd.AggregateId, DemoContext.TestUserPermission); await Emit(new UserCreatedEvent(cmd.UserName, cmd.Birth)); return ExecutionResult.Success(); } public async Task<IExecutionResult> Execute(ChangeUserNotesCommand cmd) { await Emit(new UserNotesChangedEvent(Id, State.Notes, cmd.NewValue)); return ExecutionResult.Success(); } public async Task<IExecutionResult> Execute(TrackUserTouchingCommand cmd) { await Emit(new UserTouchedEvent()); return ExecutionResult.Success(); } public async Task Rename(UserName newName) { await Emit(new UserRenamedEvent(newName)); } }
Что этот дает?
Что дает этот единый фреймворк для разработки микросервисов:
Существенно снизить сложность разработки и объем кода
Основной объем кода сервиса – это прикладная бизнес-логики. Разработчики определяют объекты-значений, сущности и агрегаты, и их логику, доменные сервисы. Одновременно формализуя интерфейс работы с микросервисом, определяя команды, запросы и события.
Код существенно упрощается, т.к. вся логика работы агрегата исполняется в одном потоке (нет многопоточных проблем), не нужно создавать контроллеры для обработки API, все берет на себя фреймворк. Весь код разнесен по слоям с четкой односторонней зависимостью между слоями.
Вызов других микросервисов прост и строго типизирован, для этого используются публичные сборки с примитивами (команды, события, идентификаторы, запросы).
Упростить отладку и поиск ошибок
Можно подключить и поднять рамках одного процесса откладки (одной IDE) нужное количество сервисов и легко их отладить.
Упростить деплой
При небольших объемах можно поднять систему на одном сервере ("как монолит"). Есть возможность гибко управлять структурой кластера.
Упростить задачу определения границ сервисов
Применение DDD и Event Storming при проектировании системы позволяет корректно решить задачу разбивки системы на сервисы.
Избавится от ограничения применения stateful-сервисов
Можно использовать как stateful, так и stateless подход без ограничений. Stateful поход реализован максимально просто для разработчика, при это обеспечивает беспрецедентную производительности, масштабируемость и отказоустойчивость.
Упростить работу с распределенными транзакциями
Stateful cаги «из коробки» позволяют создавать распределенные транзакции
Некоторые пример реализации можно посмотреть здесь.

