Вступление
Анализ тональности — это метод обработки естественного языка (NLP), используемый для определения того, являются ли данные(текст) положительными, отрицательными или нейтральными.
Анализ тональности имеет фундаментальное значение, поскольку помогает понять эмоциональные оттенки языка. Это, в свою очередь, помогает автоматически сортировать мнения, стоящие за отзывами, обсуждениями в социальных сетях, комментариями и т. д.
Хотя сентиментальный анализ стал чрезвычайно популярным в последнее время, работы над ним продолжаются с начала 2000-х годов. Традиционные методы машинного обучения, такие как наивный байесовский метод, логистическая регрессия и машины опорных векторов (SVM), широко используются для больших объемов, поскольку они хорошо масштабируются. На практике доказано, что методы глубокого обучения (DL) обеспечивают лучшую точность для различных задач NLP, включая анализ тональности; однако они, как правило, медленнее и дороже в обучении и использовании.

В этой статье я хочу предложить малоизвестную альтернативу, сочетающую скорость и качество. Для сравнительных оценок и выводов нужна базовая модель. Я выбрал проверенный временем и популярный BERT.
Данные
Социальные сети — это источник, который производит огромное количество данных, которые можно использовать для тестирования идей. Набор данных, который я буду использовать для этой статьи— это собранные твиты с коронавирусной тематикой.
Видно, что данных для модели не так много, и на первый взгляд кажется, что без предварительно обученной модели не обойтись.
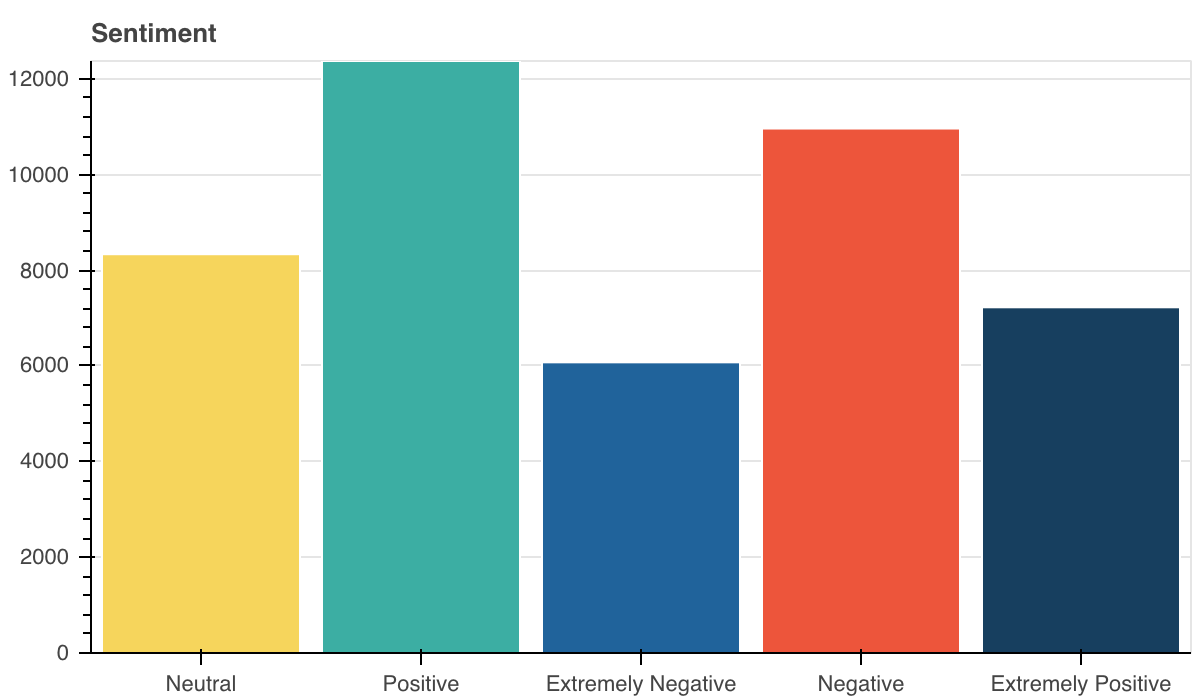
Из-за небольшого количества примеров для обучения мы сокращаем количество классов до 3, комбинируя их.
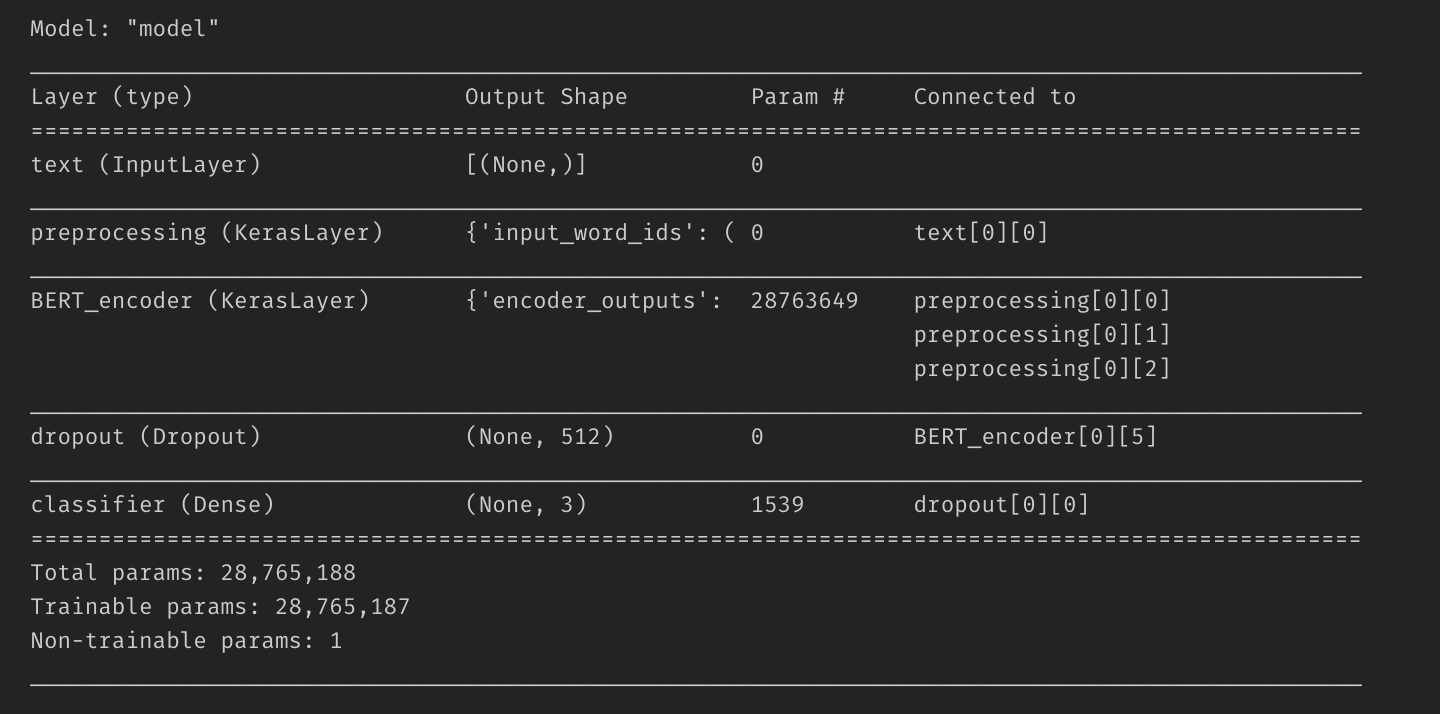
Базовая модель BERT
Давайте использовать TensorFlow Hub. TensorFlow Hub — это репозиторий обученных моделей, готовых к тонкой настройке и развертываемых где угодно. Уже предобученные модели, такие как BERT и Faster R-CNN, можно использовать с помощью всего нескольких строк кода.
!pip install tensorflow_hub !pip install tensorflow_text
small_bert/bert_en_uncased_L-4_H-512_A-8 — это одна из самых маленьких моделей BERT, на которые ссылаются в книге « Well-Read Students Learn Better: On the Importance of Pre-training Compact Models». Такие модели BERT предназначены для сред с ограниченными вычислительными ресурсами. Их можно настроить так же, как и оригинальные модели BERT. Однако они наиболее эффективны в контексте извлечения знаний, когда более крупный и точные модели хороши для точной разметки текста.
bert_en_uncased_preprocess — предварительная обработка текста для BERT. В этой модели используется словарь английского языка, взятый из Википедии и BooksCorpus. Текст был нормализован «без регистра», что означает, что текст был переведен в нижний регистр перед разметкой, а все маркеры ударения были удалены.
tfhub_handle_encoder = \ "https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-4_H-512_A-8/1" tfhub_handle_preprocess = \ "https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3"
Подбор параметров и оптимизацию делать не буду, чтобы не усложнять код. Все-таки это базовая модель, а не SOTA(State-of-the-Art).
def build_classifier_model(): text_input = tf.keras.layers.Input( shape=(), dtype=tf.string, name='text') preprocessing_layer = hub.KerasLayer( tfhub_handle_preprocess, name='preprocessing') encoder_inputs = preprocessing_layer(text_input) encoder = hub.KerasLayer( tfhub_handle_encoder, trainable=True, name='BERT_encoder') outputs = encoder(encoder_inputs) net = outputs['pooled_output'] net = tf.keras.layers.Dropout(0.1)(net) net = tf.keras.layers.Dense( 3, activation='softmax', name='classifier')(net) model = tf.keras.Model(text_input, net) loss = tf.keras.losses.CategoricalCrossentropy(from_logits=True) metric = tf.metrics.CategoricalAccuracy('accuracy') optimizer = Adam( learning_rate=5e-05, epsilon=1e-08, decay=0.01, clipnorm=1.0) model.compile( optimizer=optimizer, loss=loss, metrics=metric) model.summary() return model
Я выделил 30% данных для валидационного датасета.
train, valid = train_test_split( df_train, train_size=0.7, random_state=0, stratify=df_train['Sentiment'])y_train, X_train = \ train['Sentiment'], train.drop(['Sentiment'], axis=1) y_valid, X_valid = \ valid['Sentiment'], valid.drop(['Sentiment'], axis=1)y_train_c = tf.keras.utils.to_categorical( y_train.astype('category').cat.codes.values, num_classes=3) y_valid_c = tf.keras.utils.to_categorical( y_valid.astype('category').cat.codes.values, num_classes=3)
Количество эпох было выбрано интуитивно — можно подобрать другой гиперпараметр.
history = classifier_model.fit( x=X_train['Tweet'].values, y=y_train_c, validation_data=(X_valid['Tweet'].values, y_valid_c), epochs=5)
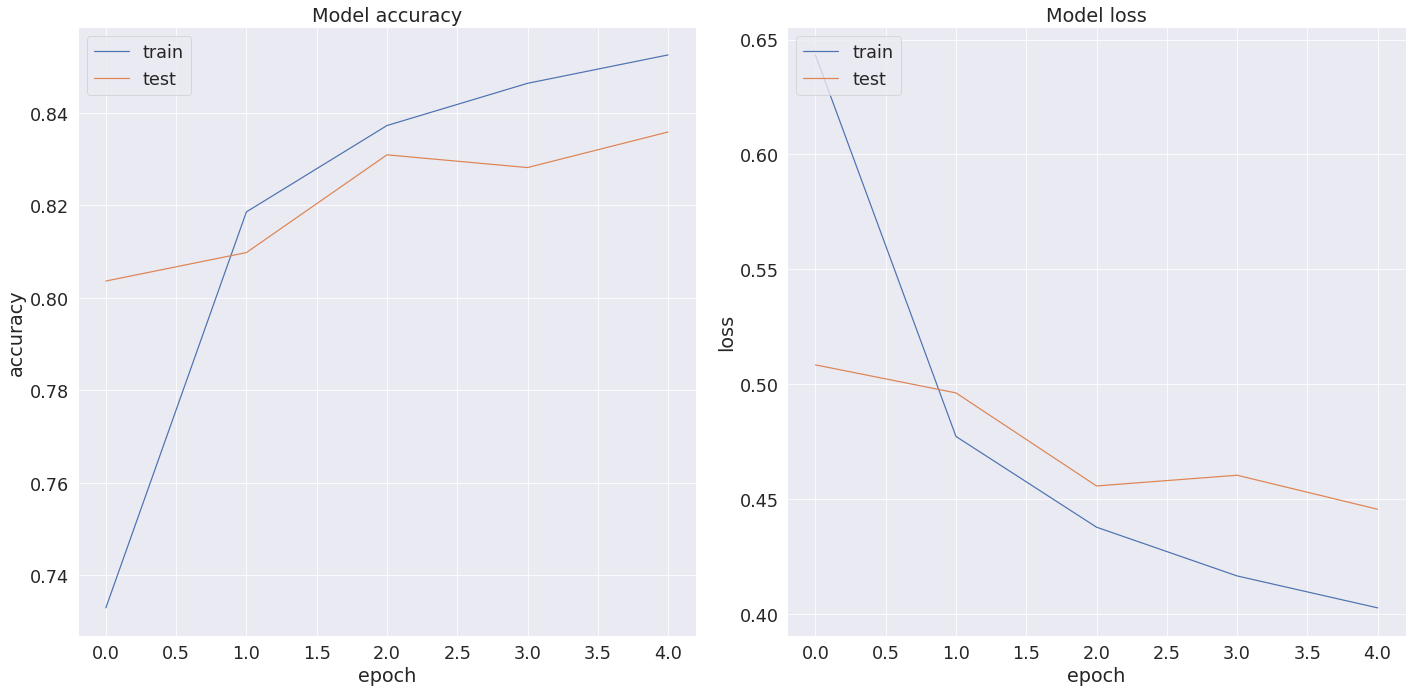
BERT Accuracy: 0.833859920501709
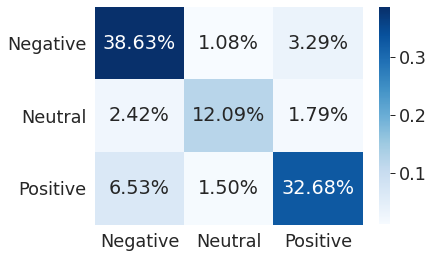
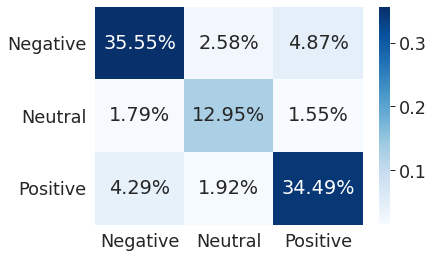
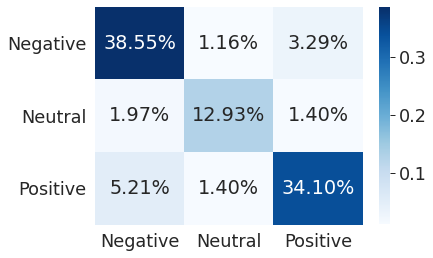
Матрица ошибок (Confusion Matrix) — это таблица, которая позволяет визуализировать качество алгоритма классификации, сравнивая прогнозируемое значение целевой переменной с ее фактическим значением. Столбцы матрицы представляют случаи в прогнозируемом классе, а строки представляют случаи в фактическом классе (или наоборот). Для наглядности, я использую проценты.
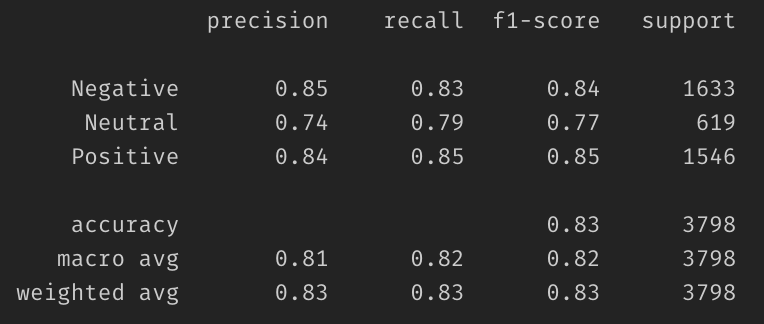
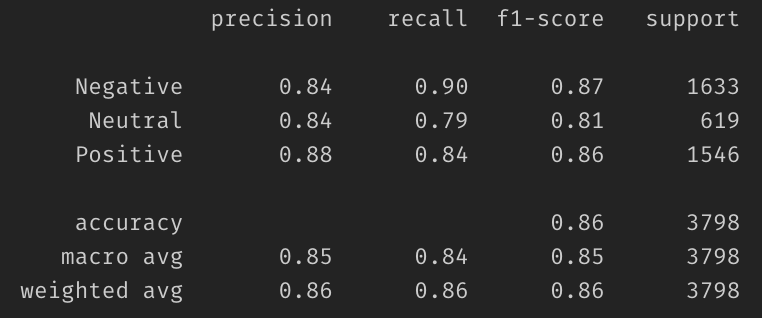
Classification Report — текстовый отчет, показывающий основные показатели классификации.

Теперь есть базовая модель. Очевидно, что эта модель может быть улучшена, но оставим эту задачу в качестве домашнего задания.
CatBoost модель
CatBoost — это высокопроизводительная библиотека с открытым исходным кодом для градиентного бустинга. Начиная с версии 0.19.1, она поддерживает текстовые фичи прямо из коробки.
Основным преимуществом является то, что CatBoost может использовать категориальные и текстовые фичи без дополнительной предварительной обработки. Для тех, кто ценит скорость — прогнозы CatBoost в 20–40 раз быстрее, чем у других библиотек бустинга с открытым исходным кодом, и это делает CatBoost полезным для задач, критичным к скорости инференса. Но надо помнить, что само обуч��ние может быть не таким быстрым, как у аналогов.
!pip install catboost
Я не буду подбирать оптимальные параметры; пусть это будет очередным домашним заданием. Напишем функцию для инициализации и обучения модели.
def fit_model(train_pool, test_pool, **kwargs): model = CatBoostClassifier( task_type='GPU', iterations=5000, eval_metric='Accuracy', od_type='Iter', od_wait=500, **kwargs )return model.fit( train_pool, eval_set=test_pool, verbose=100, plot=True, use_best_model=True)
При работе с CatBoost я рекомендую использовать Pool. Pool — это удобная оболочка, объединяющая функции, метки и другие метаданные, такие как категориальные и текстовые фичи.
text_features — одномерный массив индексов текстовых столбцов (заданных как целые числа) или имен (заданных как строки). Используйте только в том случае, если параметр данных представляет собой двумерную матрицу фичей (имеет один из следующих типов: list, numpy.ndarray, pandas.DataFrame, pandas.Series). Если какие-либо элементы в этом массиве указаны как имена, а не индексы, должны быть указаны имена для всех столбцов. Для этого используется либо параметр feature_names этого конструктора, чтобы явно указать их, либо pandas.DataFrame с именами столбцов, указанными в параметрах.
Поддерживаемые параметры:
tokenizers — токенизаторы используются для предварительной обработки фичей текстового типа перед созданием словаря.
dictionaries — словари, используемые для предварительной обработки фичей текстового типа.
feature_calcers — вычислители функций, используемые для расчета новых фичей на основе предварительно обработанных фичей текстового типа.
Все параметры выбираю интуитивно; их настройка снова станет вашим домашним заданием.
model = fit_model( train_pool, valid_pool, learning_rate=0.35, tokenizers=[ { 'tokenizer_id': 'Sense', 'separator_type': 'BySense', 'lowercasing': 'True', 'token_types':['Word', 'Number', 'SentenceBreak'], 'sub_tokens_policy':'SeveralTokens' } ], dictionaries = [ { 'dictionary_id': 'Word', 'max_dictionary_size': '50000' } ], feature_calcers = [ 'BoW:top_tokens_count=10000' ] )


CatBoost model accuracy: 0.8299104791995787
Бонус
Я получил две модели с очень похожими результатами. Может ли это дать нам еще что-нибудь полезное? Обе модели имеют мало общего по своей сути, а это значит, что их сочетание должно давать синергетический эффект. Самый простой способ проверить это — усреднить результаты и посмотреть, что произойдет.
y_proba_avg = np.argmax((y_proba_cb + y_proba_bert)/2, axis=1)
Прирост впечатляет.
Average accuracy: 0.855713533438652
Итоги
В статье:
создана базовая BERT модель;
создана модель с помощью CatBoost, используя встроенные возможности по обработке текста;
посмотрели, что будет, если усреднить результат обеих моделей.
На мой взгляд, сложных и медленных SOTA-решений можно избежать в большинстве случаев, особенно если скорость является критической необходимостью.
CatBoost обеспечивает отличные возможности анализа тональности текста прямо из коробки. Для любителей соревнований, таких как Kaggle, DrivenData и т. д., CatBoost может предоставить хорошую модель как в качестве базового решения, так и как часть ансамбля моделей.
Код из статьи можно посмотреть здесь.

