
Первая ассоциация, которая приходит на ум при упоминании serverless-решений, — это облачные сервисы вроде AWS Lambda, Azure Functions или Google Functions, а на российском рынке — Yandex Cloud Functions. У них имеются определённые бесплатные лимиты, и это подкупает. В случаях когда вы уже используете в работе K8s, смысла выносить отдельные части вашего приложения за кластер нет. Если вам интересно познакомиться с возможностями использования функций и с вариантами serverless-решений на bare-metal Kubernetes, а также узнать, как и где можно бесплатно развернуть своё PoC-решение на облачной виртуальной машине, то приглашаю под кат.
Зачем вам FaaS, если у вас K8s
Ссылки на авторитетные источники принято оставлять по поводу и без, поэтому в качестве примера возможной микросервисной архитектуры я приведу иллюстрацию, взятую со странички Serverless Architectures Мартина Фаулера:

Вместо монолитного API у нас две функции.
Монолиты определенно не в тренде, но сложно категорично сказать, что они уже отжили свой век; зато очевидно, что FaaS-решения (function-as-a-service) обладают определёнными плюсами:
Более низкая стоимость.
Более высокая скорость разработки. Возможность разрабатывать сервисы различными командами одновременно.
Повышенная отказоустойчивость и, как правило, лучшая масштабируемость.
Меньший и, следовательно, более понятный объём кода. Вы не привязаны к одному языку программирования: каждую функцию можно писать на своём языке. Если захотите, то сможете переписать любую функцию в относительно короткие сроки.
Основным минусом я бы назвал то, что функции гораздо сложнее тестировать. С монолитными приложениями таких трудностей не возникает. Кроме того, взаимосвязи между функциями (если они есть) в FaaS-решениях не всегда очевидны. Этого недостатка монолиты также лишены.
Облачные функции обладают «болячкой» в виде лимитов на использование памяти, времени выполнения, размера payload. Ну и, конечно же, у них имеется ограничение на количество бесплатных запусков. За деньги все ограничения снимаются и даже появляются возможности масштабирования облачных решений в соответствии с планируемой загрузкой.
Serverless-решения довольно хорошо вписываются в микросервисную архитектуру. Есть определённые кейсы, когда они лучше подходят под планируемое решение, чем Docker-контейнеры, содержащие в себе ОС и приложение. Например, если кодовая база довольно невелика, то смысла разворачивать отдельный контейнер с операционной системой нет. Это расточительно с точки зрения использования ресурсов Kubernetes. Разумеется, в таком случае проще использовать определённую функцию — особенно если какая-то операция выполняется раз в сутки или реже. Иногда функции используются как временные вспомогательные службы, либо как сервисы, применяемые для тестовой среды.
Два самых популярных способа запустить функцию — это HTTP- и CronJob-триггеры. Первые требуют конфигурации ingress и выполняют функцию после запроса, отправленного на определённый URL. Вторые же, как следует из названия, будут запускать функцию по расписанию. Кроме них есть и другие виды триггеров: различные webhooks; триггеры очереди; какие-либо триггеры, срабатывающие при загрузке файла. Иногда функции объединяют в цепочку. В таком случае одна функция по завершении своей работы вызывает другую.
Как выбрать serverless-фреймворк под себя
Если у вас уже имеется свой созданный кластер Kubernetes, то вы можете развернуть среду для написания безлимитных и бессерверных функций — Kubernetes-based installable serverless platform. Таких платформ-фреймворков несколько, и вы можете выбрать подходящую под свои нужды.
На что следует обратить внимание при выборе serverless-фреймворка, так это на поддержку языков программирования. Не всё и не везде поддерживается. JS доступен практически везде. Python и Go также пользуются довольно широкой поддержкой. Очень часто имеется возможность использовать Ruby, Java или C#.
Отличное сравнение самостоятельно устанавливаемых serverless-платформ, основанных на Kubernetes, содержится в следующем артикуле на сайте Cisco: Examining the FaaS on K8S Market. Я даже приведу изображение из этого артикула для большей наглядности (по скриншоту сразу становится понятно, что оно взято «с блога Сisco» :), но первоначального источника я не нашёл):
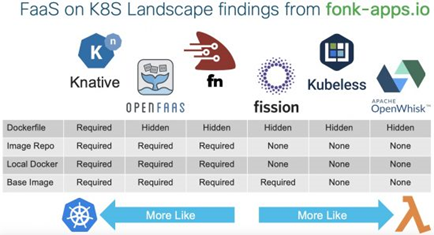
От себя добавлю, что Knative — это уже скорее CaaS (container-as-a-service), а не FaaS.
Чем интересен Kubeless
Kubeless большей частью написан на Go. Хочется верить, что проект, рождённый в стенах Google Go, будет ближе других к изначально их же Kubernetes.
К минусам Kubeless относят отсутствие поддержки scale-to-zero. Данный функционал удаляет все реплики, если в них нет необходимости. Эти возможности есть, например, у OpenFaaS. Зато у Kubeless имеется функция автоматического масштабирования с помощью кубернетовского Horizontal Pod Autoscaler.
Почитать об этих возможностях можно здесь: Autoscaling function deployment in Kubeless.
Начиная с версии Kubernetes 1.16, доступна возможность использовать фичу под названием HPAScaleToZero. На момент написания статьи она находится в стадии Alpha.
Как потрогать Kubernetes своими руками
Для этого хорошо бы обзавестись собственной нодой Kubernetes. Если вы под Linux, то это для вас совсем не проблема. Если же вы под Windows, то можете не выходя из системы установить Docker с WSL и добавить интеграцию Kubernetes. Docker on Mac, кстати, тоже содержит в настройках возможность включить single-node кластер Kubernetes.
В Сети есть несколько сервисов, предоставляющих Kubernetes на бесплатной основе для создания PoC. Для меня открытием оказался Kubernautic. Он предоставляет Alpine Linux с уже установленным Kubernetes, но, как оказалось, с определёнными ограничениями, и у меня банально не хватило прав для того, чтобы установить на нём Kubeless. Примерно такие же впечатления остались от сервиса под названием Krucible.
Помимо Kubernautic, есть чуть более известный сервис Okteto. Его бесплатный тариф позволяет пользоваться сервисом через день. Это, конечно, не очень удобно с точки зрения разработки проектов, но для PoC иногда годится.
Оставлю ссылку на англоязычный мануал: Serverless Development with Kubeless and Okteto.
Мой тест в облаке
Так как FaaS всё-таки относится больше к облакам, я предпочитаю работать в них. Поэтому для демо решено было завести виртуальную машину у одного из крупных провайдеров. И где бы вы думали я её завел? В Oracle Cloud. Дело в том, что AWS и Azure предлагают виртуалки бесплатно только в первый год пользования аккаунтом, а Oracle — на постоянной основе. Справедливости ради упомяну, что и в Google Cloud также можно «взять погонять» виртуалку бесплатно на постоянной основе, но с 2016 года в России регистрация доступна только для юридических лиц.
Характеристики оракловской виртуалочки следующие:
1 core OCPU, 1 GB memory, 0.48 Gbps network bandwidth.
Существует несколько способов установить Kubernetes локально на одну машину и устроить себе learning environment для тестов и разработки. Один из самых популярных — это, пожалуй, Minikube. Он разворачивает кластер внутри виртуальной машины. Его основным плюсом, помимо популярности, является универсальность: развернуть его можно практически на любой ОС. Но Minikube первой же проверкой сузил мне круг выбора. Команда:
grep -E --color 'vmx|svm' /proc/cpuinfo
не возвратила ничего. Виртуализация не поддерживается моей виртуальной машиной.
У Minikube есть масса конкурентов:
Microk8s от разработчиков Ubuntu. Он работает без VM и устанавливается с помощью Snap.
Заманчивый и очень лёгкий (менее 100 МБ) K3s. Хорошо подходит для IoT.
Милый kind (Kubernetes IN Docker) — self-contained Linux-приложение, которое скачивается и записывается в PATH.
Просто обязан упомянуть OpenShift’овские CodeReady Containers и Minishift.
В результате я остановился на K3s. Кластер «завёлся» с одной команды, ну или точнее, с одного скрипта:
curl -sfL https://get.k3s.io | sh -
Для того чтобы всё заработало на Oracle Linux, мне пришлось отключить файрвол командой:
sudo systemctl stop firewalld
Добавить права на файл конфигурации:
sudo chmod 644 /etc/rancher/k3s/k3s.yaml
И установить значение переменной среды KUBECONFIG:
export KUBECONFIG=/etc/rancher/k3s/k3s.yaml
Скрипт автоматически установил и утилиту kubectl. Убедиться, что с нодой всё в порядке, можно следующей командой:
kubectl get nodes
А ещё лучше проверить, что все поды работают:
kubectl get pods --all-namespaces
Если что-то пойдёт не так, то рестартануть K3s можно с помощью systemctl:
sudo systemctl restart k3s
Установка Kubeless
Теперь приступим к установке Kubeless. Для этого нам необходимо скачать и установить CLI. Этот процесс немного автоматизирован, и номер актуальной версии подтягивается с GitHub автоматически с помощью следующей команды:
export RELEASE=$(curl -s https://api.github.com/repos/kubeless/kubeless/releases/latest | grep tag_name | cut -d '"' -f 4)
Теперь мы можем использовать $RELEASE в командах для скачивания и установки Kubeless:
export OS=$(uname -s| tr '[:upper:]' '[:lower:]') curl -OL https://github.com/kubeless/kubeless/releases/download/$RELEASE/kubeless_$OS-amd64.zip && \ unzip kubeless_$OS-amd64.zip && \ sudo mv bundles/kubeless_$OS-amd64/kubeless /usr/local/bin/
Далее мы создаём namespace, в котором будут содержаться все наши объекты, относящиеся к Kubeless:
kubectl create ns kubeless
И наконец, устанавливаем сам Kubeless:
kubectl create -f https://github.com/kubeless/kubeless/releases/download/$RELEASE/kubeless-$RELEASE.yaml
Я использую команду для RBAC (role-based access control), так как он более прост и популярен по сравнению с ABAC (attribute-based access control).
Прежде чем приступить к следующему шагу, убедитесь, что контейнер запустился:
kubectl get pods -n kubeless
Работа с функциями
Теперь мы можем перейти к написанию функций. Примеры Kubeless-функций для различных платформ можно найти тут. Я взял пример .NET Core.
Воспользуемся vi для создания первой функции.
Создаём файл:
vi testfunction.cs
using System; using Kubeless.Functions; public class module { public string handler(Event k8Event, Context k8Context) { return "Hello world"; } }
Не буду приводить список всех команд vi. Достаточно будет только двух.
Чтобы сохранить, нажимаем Esc, а затем :w! Enter.
Чтобы выйти — Esc, а затем :q! Enter.
Деплоим функцию так:
kubeless function deploy hello --runtime dotnetcore2.2 \ --from-file testfunction.cs \ --handler module.handler
В этой команде первый параметр “hello” — это имя функции.
Далее идёт используемый runtime. Чтобы получить список поддерживаемых runtime, можно выполнить команду:
kubeless get-server-config
Ну и наконец, имя файла и handler, описывающий путь к запускаемому методу (имя класса и имя метода, разделённые точкой).
Проверить, задеплоена ли уже функция, можно командой:
kubeless function ls hello
Удалить — с помощью:
kubeless function delete hello
Если необходимо вывести список всех функций:
kubectl get functions
Проверить состояние пода:
kubectl get pods -l function=hello
Теперь создадим простой Cron-триггер:
kubeless trigger cronjob create \ cron-test-hello \ --function hello \ --schedule "*/0 * * * *"
Он должен будет выполнять нашу функцию каждые 10 минут. Для каждого выполнения будет создан новый под — это то, что называется cold start. Следует учитывать, что cold start занимает какое-то время и ваша функция будет выполнена не ровно через 10 минут.
CronJob может мониторить какой-нибудь health-сервис и отправлять сообщения в случае «падения». Также он может проверять наличие новых данных и производить их обработку — получится что-то вроде ETL (extract, transform and load). Можно разбить какую-нибудь долгую операцию на несколько небольших batch job’ов и выполнять их по таймеру CronJob.
Очень часто возникает необходимость вызвать триггер из Сети. Для этого можно создать HTTP-триггер. Чтобы получить доступ к функции, вашему кластеру необходим ingress. В K3s уже установлен по умолчанию Traefik, и HTTP-триггер можно создать сразу командой:
kubeless trigger http create helloingress --function-name hello
Проверить, что ingress был создан, можно командой:
kubectl get ing или kubectl get ingress
Удалить можно так:
kubeless trigger http delete helloingress
У меня этот способ не сработал, поэтому пришлось создавать ingress вручную. Для этого мне потребовалось название сервиса функции и её порт. Получить эти данные можно, выполнив команду:
kubectl get svc
Мне она выдала такой результат:

Ну и теперь можно создавать ingress:
vi ingress.yaml
apiVersion: networking.k8s.io/v1 kind: Ingress metadata: name: minimal-ingress-v1 spec: rules: - http: paths: - path: /hello pathType: Prefix backend: service: name: hello port: number: 8080
На всякий случай лишний раз предупреждаю: пробелы довольно важны в YAML-файлах. Создаём ingress командой:
kubectl create -f ingress.yaml
Для того чтобы он начал работать и перенаправлять запросы на сервис hello, необходимо разрешить виртуальной машине доступ извне по протоколу TCP.
На странице Instance виртуальной машины заходите в Primary VNIC и кликайте на вашу Subnet. Со страницы Subnet заходите в Security Lists (у вас будет один security list, созданный по умолчанию). Теперь вам нужно разрешить доступ с вашего IP-адреса по TCP-протоколу, добавив Ingress Rule. Чтобы указать единственный IP в виде CIDR, достаточно добавить к нему /32.
Теперь с помощью curl вы можете активировать триггер (IP адрес — это адрес вашей виртуальной машины):
curl http://140.238.222.93:80/hello
А вот убедиться, что функция отработала, в нашем простом случае можно только проверив логи (указав при этом начало интервала времени, чтобы отсечь старые записи):
kubectl logs hello-5b5cf4b6d4-28tgl --since-time=2021-05-14T17:31:00.000000000Z
В этой команде hello-5b5cf4b6d4-28tgl — это имя пода.
Заключение
Надеюсь, что на этом примере вы разобрались, как создать бессерверное решение на Kubeless и как с ним можно работать. Если у вас имеется Kubernetes-кластер, то, учитывая, что его ресурсы не бесконечны, вы можете перенести какую-то логику на serverless. Экономия ресурсов — это далеко не единственный кейс. Редко выполняемые операции; задания, выполняемые по таймеру; stateless-операции, требующие создания отдельного экземпляра; обработка файлов и видео, — все эти кейсы довольно благоприятно вписываются в архитектуру в качестве serverless-решений.

