В последнее время всё чаще появляются статьи о производительности российских процессоров Эльбрус на различных задачах. Тема криптографии пока что остаётся за кадром, хотя в разное время были упоминания то о высоких возможностях Эльбруса (некий ГОСТ лучше в 9 раз на Эльбрус-4С, чем на Intel Core i7-2600), то о плохой оптимизации компилятора и, соответственно, крайне низкой скорости реализованных алгоритмов (Кузнечик в 100 раз медленнее, чем на Intel?). Предлагаю наконец разобраться, что может Эльбрус, на примере двух ГОСТ алгоритмов симметричного шифрования.

Чтобы статья не вышла слишком большой, будем считать, что читатель имеет общее представление об архитектурах процессоров, в том числе знает об Эльбрусе. Если же нет, на сайте разработчика (компании МЦСТ) есть отличное руководство по программированию и книга об архитектуре в целом. Именно с этих материалов и началось моё знакомство с Эльбрусами. Также отмечу, что в современных процессорах очень много различных механизмов и особенностей, так что в статье буду касаться только тех, которые, на мой взгляд, важны при реализации выбранных алгоритмов.
Что может предложить архитектура Эльбрус
Для выполнения арифметических операций у Эльбруса есть 6 АЛУ (арифметико-логических устройств), способных выполнять операции параллельно. Начиная с версии 5 архитектуры, появилась поддержка упакованных (SIMD) инструкций над 128-битными регистрами.
Для хранения промежуточных результатов присутствует большой регистровый файл: суммарно в процедуре можно использовать более 200 (64-битных) регистров общего назначения. Для SIMD вычислений используются те же самые регистры, а не отдельные, как это часто бывает. Соответственно, с 5 версии архитектуры все регистры стали 128-битными.
Задачу симметричного шифрования можно отнести к потоковой обработке массива данных. Для таких ситуаций в Эльбрусе есть механизм асинхронной подкачки данных из памяти — APB (Array Prefetch Buffer). Использование этого механизма позволяет вовремя подгружать данные из памяти, не теряя время на кэш-промахи.
Выбор реализаций
Хорошим подходом было бы взять несколько известных реализаций, оптимизировать их под Эльбрус и посмотреть на результаты. Но, с другой стороны, мы говорим о процессоре общего назначения, поэтому можно сэкономить силы и время, предположив, что лучшие результаты можно ожидать от подходов, которые являются самыми быстрыми на других архитектурах.
Правда, о производительности ГОСТ алгоритмов обычно говорят только в контексте семейства x86-64, другие архитектуры мало кого интересуют. Но это не беда: мне показалось, что при знании команд ассемблера x86-64 ознакомиться с набором целочисленных и логических инструкций Эльбруса проще, чем, скажем, с ARM-овым. То есть прослеживаются определённые параллели, особенно, в области SIMD инструкций, и даже прямые аналоги. В остальном, конечно, у них нет ничего общего.
Итак, для Магмы известна эффективная реализация режимов, допускающих параллельную обработку блоков, то есть когда несколько блоков могут шифроваться независимо друг от друга. Это, например, режимы ECB, CTR, MGM. При этом скорость конкурирует с AES, для которого на x86-64 есть аппаратная поддержка. Реализация заточена именно под параллельную обработку, в случае последовательной (режимы с зацеплением) используются другие подходы. Мне интересно добиться максимальной скорости, поэтому я ограничился только случаем параллельной обработки.
С Кузнечиком немного проще: лучшие результаты что при последовательной, что при параллельной обработке даёт одна и та же реализация — её и берём.
Тестовые машины
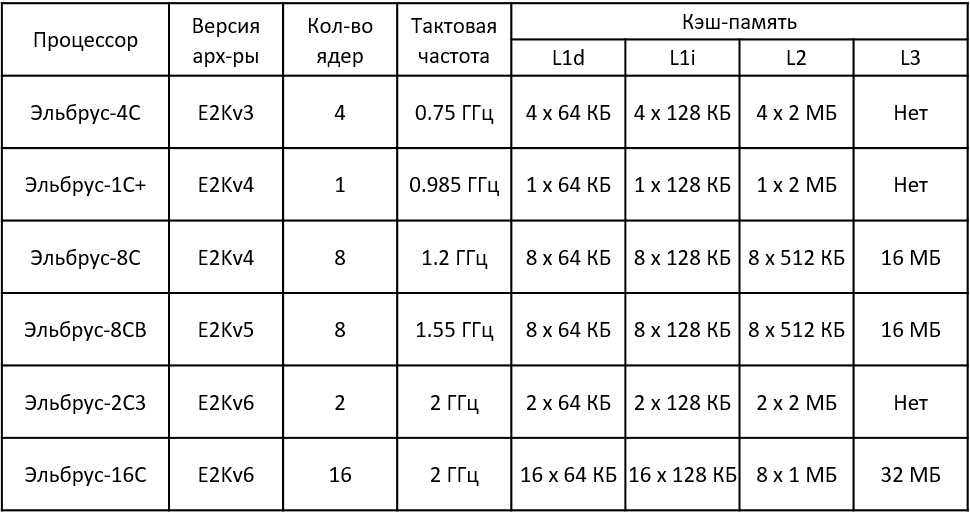
То же самое в текстовом виде
Процессор | Версия арх-ры | Кол-во ядер | Тактовая частота | L1d | L1i | L2 | L3 |
Эльбрус-4С | E2Kv3 | 4 | 0.75 ГГц | 4 x 64 КБ | 4 x 128 КБ | 4 x 2 МБ | Нет |
Эльбрус-1С+ | E2Kv4 | 1 | 0.985 ГГц | 1 x 64 КБ | 1 x 128 КБ | 1 x 2 МБ | Нет |
Эльбрус-8С | E2Kv4 | 8 | 1.2 ГГц | 8 x 64 КБ | 8 x 128 КБ | 8 x 512 КБ | 16 МБ |
Эльбрус-8СВ | E2Kv5 | 8 | 1.55 ГГц | 8 x 64 КБ | 8 x 128 КБ | 8 x 512 КБ | 16 МБ |
Эльбрус-2С3 | E2Kv6 | 2 | 2 ГГц | 2 x 64 КБ | 2 x 128 КБ | 2 x 2 МБ | Нет |
Эльбрус-16С | E2Kv6 | 16 | 2 ГГц | 16 x 64 КБ | 16 x 128 КБ | 8 x 1 МБ | 32 МБ |
Магма
В случае x86-64 быстрая реализация Магмы опирается на использование расширений AVX и AVX2. При этом учитывается наличие в процессоре нескольких АЛУ и возможность параллельного исполнения до 3 векторных инструкций за один такт. Естественно, планирование параллельного исполнения остаётся на откуп процессора.
В случае же Эльбруса есть возможность явно распланировать параллельное исполнение. Опуская некоторые детали, можно считать, что на 3 и 4 поколении возможно исполнить 6 целочисленных векторных операций над 64-битными регистрами, а начиная с 5 поколения — 4 векторных операции уже над 128-битными регистрами.
Для Эльбруса я написал собственную реализацию Магмы. Она использует те же идеи, что и исходная под x86-64, но при этом адаптирована под другой набор инструкций. Рассматривал перспективу написания на ассемблере и даже пробовал, но довольно быстро осознал, что ассемблер у Эльбруса достаточно сложный в плане программирования на нём (например, есть много нюансов по размерам задержек и зависимостям инструкций, которые тяжело учесть вручную). При этом оптимизирующий компилятор делает свою работу действительно хорошо: переставляет инструкции в рамках большого окна и при подборе опций компиляции выдаёт плотность кода, которая не отличается от теоретических оценок на количество инструкций и тактов. Так что я остановился на реализации на языке Си с использованием intrinsic функций для доступа к некоторым инструкциям процессора.
Для измерения скорости был выбран режим ECB. Обычно именно он (или даже его упрощения) используется при сравнении производительности, а скорость других режимов можно оценить на базе полученных результатов, отличия несущественны. Речь идёт о реализации базового алгоритма шифрования, поэтому накладные расходы от смены ключа также не учитываются. Объём данных для замера — порядка 1 ГБ. Естественно, шифрование на одном ядре. Для многоядерной машины можно умножить результат на количество ядер и получить близкую к реальности оценку скорости. По крайней мере, во всех сравнениях я видел именно такую зависимость. Полученные результаты в таблице ниже:

То же самое в текстовом виде
Процессор | Скорость на невыровненных данных | Скорость на выровненных данных | Производительность |
Эльбрус-4С | 116 МБ/с | 137 МБ/с | 5.2 такт/байт |
Эльбрус-1С+ | 151 МБ/с | 179 МБ/с | 5.2 такт/байт |
Эльбрус-8С | 185 МБ/с | 220 МБ/с | 5.2 такт/байт |
Эльбрус-8СВ | 402 МБ/с | 520 МБ/с | 2.8 такт/байт |
Эльбрус-2С3 | 669 МБ/с | 670 МБ/с | 2.8 такт/байт |
Эльбрус-16С | 671 МБ/с | 672 МБ/с | 2.8 такт/байт |
Здесь под выровненными данными подразумевается выравнивание по границе 8 байтов для E2Kv3/E2Kv4 и 16 байтов для E2Kv5/E2Kv6. При наличии такого выравнивания (на версиях до 6) работает механизм APB и данные для шифрования эффективно подкачиваются из памяти. При этом с версии 6 APB уже не требует выравнивания данных, поэтому при любом расположении данных достигается максимальная скорость. Для невыровненных данных на предыдущих версиях архитектуры я не провёл достаточно исследований, так что значения в этом столбце таблицы можно считать нижней границей.
Для сравнения приведу результаты из статьи с описанием базовой реализации на Intel Core i3-7100 @ 3.9 ГГц. При использовании AVX — 458 МБ/с, 8.1 такт/байт; AVX2 — 1030 МБ/с, 3.6 такт/байт. Так что по абсолютной скорости Эльбрус достаточно близок к современным процессорам Intel (это при значительной разнице в тактовой частоте!) и превосходит x86-64 с AVX в тактах более чем в 1.5 раза (для 3 и 4 поколения), а x86-64 с AVX2 — в 1.3 раза (для 5 поколения).
Кузнечик
По сравнению с Магмой, структура Кузнечика является более сложной. Несмотря на то, что удалось декомпозировать нелинейное преобразование S, техники реализации, основанные на широком использовании SIMD-инструкций, пока что отстают от "классической" реализации со склеенным LS (линейным и нелинейным) преобразованием и таблицей предвычислений размером 64 КБ (упоминается в статье под именами с LS или более простое описание на Хабре).
В случае x86-64 Кузнечик эффективнее всего реализуется с использованием AVX-инструкций (удобно работать со 128-битными регистрами, так как длина блока и размер значений в таблице равны в точности 128 битам). При этом для вычислений адресов в таблице не удаётся воспользоваться эффективной адресацией Scale-Index-Base-Displacement (именование из статьи), так как в качестве Scale нужно значение 16, а максимально возможное — 8. На Эльбрусе можно ожидать конкурирующих результатов за счёт большого кэша L1d (64 КБ) и наличия 4 АЛУ, обеспечивающих произвольный доступ к памяти (насколько мне известно, у абсолютного большинства процессоров x86-64 2 порта для загрузки данных).
Как и в случае с Магмой, для Кузнечика я написал отдельную реализацию на Си под Эльбрус, чтобы добиться максимальных результатов. Начиная с 5 версии архитектуры, я явным образом использовал тип __v2di (см. e2kintrin.h в составе компилятора), чтобы быть уверенным, что получится использовать регистры как 128-битные.
Техника замера скорости полностью совпадает с уже описанным случаем Магмы, так что повторяться не буду. Только напомню, на всякий случай, что речь идёт о скорости на одном ядре. Почему-то у многих это вызывало вопросы и ещё чаще удивление.
Итак, в случае строго последовательной обработки данных:
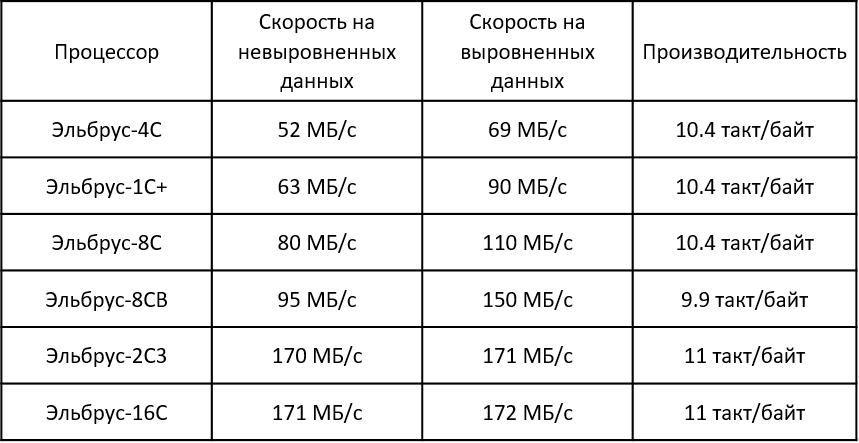
То же самое в текстовом виде
Процессор | Скорость на невыровненных данных | Скорость на выровненных данных | Производительность |
Эльбрус-4С | 52 МБ/с | 69 МБ/с | 10.4 такт/байт |
Эльбрус-1С+ | 63 МБ/с | 90 МБ/с | 10.4 такт/байт |
Эльбрус-8С | 80 МБ/с | 110 МБ/с | 10.4 такт/байт |
Эльбрус-8СВ | 95 МБ/с | 150 МБ/с | 9.9 такт/байт |
Эльбрус-2С3 | 170 МБ/с | 171 МБ/с | 11 такт/байт |
Эльбрус-16С | 171 МБ/с | 172 МБ/с | 11 такт/байт |
Для сравнения результаты из статьи (лучшие из опубликованных) на Intel Core i7-6700 @ 4 ГГц — 170МБ/с, 22.4 такт/байт. В отличие от Магмы, можно говорить о сопоставимой абсолютной скорости и преимуществе в тактах более чем в 2 раза.
В таблице заметен интересный момент: результаты ощутимо колеблются среди последних 3 версий Эльбруса. Такое поведение я заметил буквально недавно и начал обсуждение с коллегами из МЦСТ, так что есть надежда, что результаты удастся немного улучшить при доработке компилятора.
С параллельной обработкой ситуация намного интереснее:

То же самое в текстовом виде
Процессор | Скорость на невыровненных данных | Скорость на выровненных данных | Производительность |
Эльбрус-4С | 78 МБ/с | 83 МБ/с | 8.6 такт/байт |
Эльбрус-1С+ | 102 МБ/с | 108 МБ/с | 8.7 такт/байт |
Эльбрус-8С | 126 МБ/с | 133 МБ/с | 8.6 такт/байт |
Эльбрус-8СВ | 248 МБ/с | 291 МБ/с | 5.1 такт/байт |
Эльбрус-2С3 | 453 МБ/с | 454 МБ/с | 4.2 такт/байт |
Эльбрус-16С | 454 МБ/с | 455 МБ/с | 4.2 такт/байт |
И традиционное сравнение с Intel Core i7-6700 @ 4 ГГц: на нём достигается 360 МБ/с, 10.6 такт/байт. В отличие от случая последовательной обработки, у E2Kv3 и E2Kv4 преимущество Эльбруса не такое большое, предположительно из-за того, что реализация обработки нескольких блоков вместе обладает более высокой степенью параллельности и планировщику на x86-64 легче справиться с выявлением независимых операций. А вот появление у 5 поколения Эльбруса 128-битных регистров и загрузок из памяти позволяет ему сохранить преимущество в тактах более чем в 2 раза.
Сравнивать E2Kv6 с i7-6700 оказалось несолидно, поэтому я взял ассемблерную реализацию режима ECB и провёл собственный замер. В статье с описанием результатов на i7-6700 данные шифруются «на месте», без работы с памятью, поэтому у честного режима ECB результат чуточку хуже: на самом мощном из доступных мне процессоров — Intel Core i7-9700K @ 4.7 ГГц — вышло 411 МБ/с, 10.9 такт/байт. Эльбрус оказался быстрее, обеспечивая преимущество в тактах в 2.5 раза.
Заключение
На основании полученных результатов я делаю вывод, что Эльбрус обладает отличными возможностями для высокопроизводительной реализации шифрования данных, несмотря на отсутствие в выпущенных версиях архитектуры какой-либо аппаратной поддержки криптографических операций.
За время изучения архитектуры Эльбруса у меня сложилось впечатление, что многие полезные инструкции исторически добавлялись для обеспечения работы двоичного транслятора, но ситуация изменилась с 5 версии: Эльбрус начал больше развиваться собственным путём. Эту положительную динамику невозможно не отметить.
С другой стороны, сложившаяся похожесть ряда инструкций упрощает разработку и оптимизацию под Эльбрус. Можно сказать, что эта статья предлагает простой способ портирования и оптимизации алгоритмов под Эльбрус: достаточно взять хорошо зарекомендовавший себя на Intel/AMD алгоритм и немного адаптировать его под Эльбрус. Я искренне верю, что в результате практически любой алгоритм должен работать по крайней мере не хуже, чем в разницу тактовых частот.
Если немного поразбираться и осторожно писать код на Си, компилятор прекрасно справляется с задачей оптимизации и не оставляет человеку шансов написать на ассемблере более эффективный код.
P.S.
Эта статья написана по мотивам моего устного доклада на конференции РусКрипто. По ссылке можно найти презентацию, которая является краткой выжимкой с основными результатами на тот момент. К моменту же написания статьи удалось улучшить некоторые результаты, а также проверить реализации на новом поколении процессоров.
Несмотря на то, что для получения описанных результатов мне удалось разобраться с Эльбрусом на основании только открытой информации и документации к компилятору, я хочу выразить благодарность сотрудникам МЦСТ, в особенности, Александру Трушу, за ответы на периодически возникавшие у меня вопросы и, конечно, за предоставление удалённого доступа к новым процессорам.

